
Guillaume Corlouer
@tkrdan
AI alignment research, applying information theory and methods from complex systems for interpretability. Previously researcher at http://pibbss.ai.
You might like











Benchmarks saturate quickly, but don’t translate well to real-world impact. *Something* is going up very fast, but not clear what it means. Thus the wide range of expert opinion, from “superintelligence in a few years”, to “we’ve already hit a wall”. Our results shed some light:

When will AI systems be able to carry out long projects independently? In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.


In this thread I want to share some thoughts about the FrontierMath benchmark, on which, according to OpenAI, some frontier models are scoring ~20%. This is benchmark consisting of difficult math problems with numerical answers. What does it measure, and what doesn't it measure?

After a long collaboration with @36zimmer, @mattecapu and @NathanielVirgo, I’m excited to share the first of (hopefully) many outputs: “A Bayesian Interpretation of the Internal Model Principle” arxiv.org/abs/2503.00511. 1/

1/ AI is accelerating. But can we ensure that AIs truly share our values and follow our goals? We argue that aligning advanced AI systems requires cracking a core scientific challenge: how data shapes AI's internal structure, and how that structure determines behavior.


Do SAEs find the ‘true’ features in LLMs? In our ICLR paper w/ @neelnanda5 we argue no The issue: we must choose the number of concepts learned. Small SAEs miss low-level concepts, but large SAEs miss high-level concepts - it’s sparser to compose them into low-level concepts
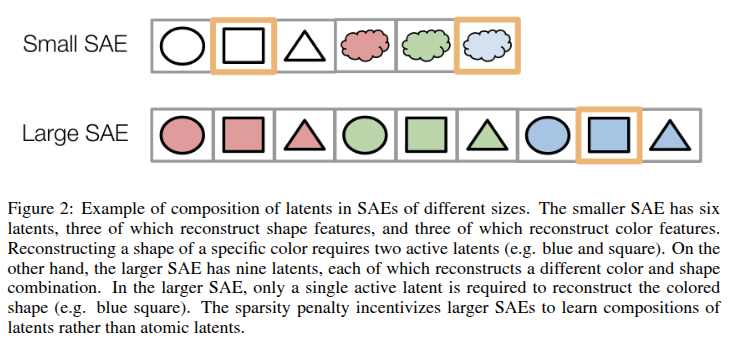

🌌🛰️Wanna know which features are universal vs unique in your models and how to find them? Excited to share our preprint: "Universal Sparse Autoencoders: Interpretable Cross-Model Concept Alignment"! arxiv.org/abs/2502.03714 (1/9)

Bargaining with AIs to reduce alignment faking. i like the idea of setting a precedent and to look for pareto improvements on alignment + ai welfare.

Our recent paper found Claude sometimes "fakes alignment"—pretending to comply with training while secretly maintaining its preferences. Could we detect this by offering Claude something (e.g. real money) if it reveals its true preferences? Here's what we found 🧵

Today, we are publishing the first-ever International AI Safety Report, backed by 30 countries and the OECD, UN, and EU. It summarises the state of the science on AI capabilities and risks, and how to mitigate those risks. 🧵 Link to full Report: assets.publishing.service.gov.uk/media/679a0c48… 1/16

Big new review! 🟦Open Problems in Mechanistic Interpretability🟦 We bring together perspectives from ~30 top researchers to outline the current frontiers of mech interp. It highlights the open problems that we think the field should prioritize! 🧵

New interpretability paper from Apollo Research! 🟢Attribution-based Parameter Decomposition 🟢 It's a new way to decompose neural network parameters directly into mechanistic components. It overcomes many of the issues with SAEs! 🧵


Post-mortem after Deepseek-r1's killer open o1 replication. We had speculated 4 different possibilities of increasing difficulty (G&C, PRM, MCTS, LtS). The answer is the best one! It's just Guess and Check.


I want to try to explain in simple terms the context of this paper and what it is roughly about.

Peter Scholze: Geometrization of the local Langlands correspondence, motivically arxiv.org/abs/2501.07944 arxiv.org/pdf/2501.07944 arxiv.org/html/2501.07944
Lifelong learning seems like one of the next big step in AI. Dynamically adjusting weights sounds like a promising approach to pass through it.

We’re excited to introduce Transformer², a machine learning system that dynamically adjusts its weights for various tasks! sakana.ai/transformer-sq… Adaptation is a remarkable natural phenomenon, like how the octopus can blend in with its environment, or how the brain rewires…

The Scaling Paradox: AI capabilities have improved remarkably quickly, fuelled by the explosive scale-up of resources to train the leading models. But the scaling laws that inspired this rush actually show very poor returns to scale. What’s going on? 1/ tobyord.com/writing/the-sc…
I can recommend doing the @pibbssai fellowship. I hung out and worked with awesome people there, and it was helpful to start doing research in AI safety coming from a computational neuroscience and maths background (they are open to a wide range of backgrounds).
Are you interested in AI safety… but you have a different background and are not sure of the best way to get into it? Then this fellowship is precisely for you! pibbss.ai/fellowship/


"I will teach myself math from books." The book:

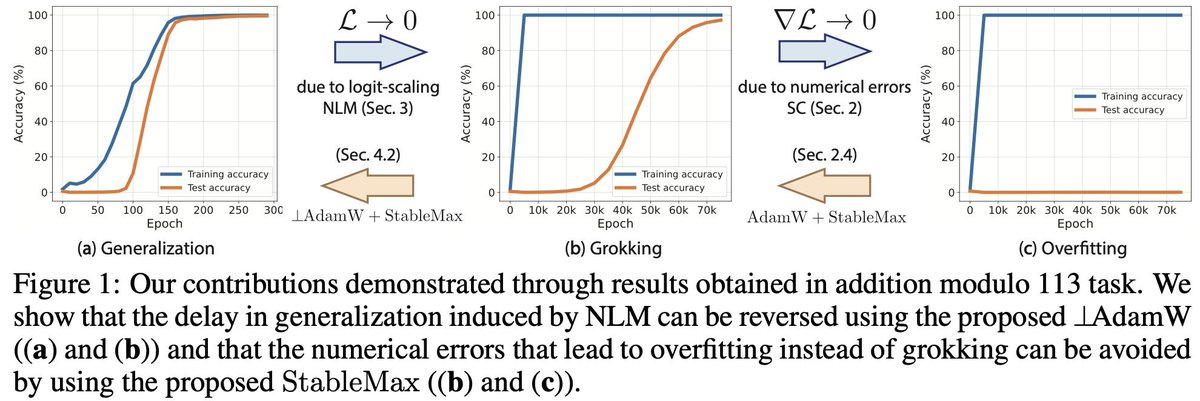
Interesting! Numerical instability from the softmax prevents grokking which weight decay mitigate, also delay in grokking caused by logit scaling. Vague SLT interpretation: the orthogonal gradient accelerate SGD escape toward more degenerate ``basins'' that generalize better.

I am excited to share our new paper: “Grokking at the Edge of Numerical stability”! We show that floating point errors in the Softmax play a surprising role in grokking, explaining among other things, why weight decay seems necessary for grokking in most cases! 🧵
Useful list of research directions in AI safety for a more direct impact. It would be nice to have more work/discussions evaluating carefully the robustness of each of these directions though.

What can AI researchers do *today* that AI developers will find useful for ensuring the safety of future advanced AI systems? To ring in the new year, the Anthropic Alignment Science team is sharing some thoughts on research directions we think are important.

Looks interesting! Sounds like it's shaped for follow up work looking at representation formation with computational mechanics and/or Developmental interp for in-context learning

New paper 🥳🚨 Interested in inference-time scaling? In-context Learning? Mech Interp? LMs can solve novel in-context tasks, with sufficient examples (longer contexts). Why? Bcus they dynamically form *in-context representations*! 1/N
I have the intuition that maths should be one of the first field of research to fall for similar reasons. One uncertainty is the lack of good data, but then it might be possible to generate lots of it.














































































































United States Trends
- 1. #21DaysOfJupiterMobile N/A
- 2. Ravens 141 B posts
- 3. Lamar 86,8 B posts
- 4. Amorim 206 B posts
- 5. Tyler Loop 30,3 B posts
- 6. Justin Tucker 7.159 posts
- 7. Good Monday 35,2 B posts
- 8. Manchester United 116 B posts
- 9. #HereWeGo 23,1 B posts
- 10. Boswell 7.660 posts
- 11. Aaron Rodgers 22,7 B posts
- 12. #CatForCash 64,9 B posts
- 13. #njdash 5.064 posts
- 14. Harbaugh 19,5 B posts
- 15. Kickers 7.789 posts
- 16. #MondayMotivation 6.726 posts
- 17. Jalen Ramsey 2.024 posts
- 18. Mike Tomlin 11,8 B posts
- 19. Zay Flowers 10,1 B posts
- 20. Texans 42,7 B posts
You might like
-
 Borjan (Boki) Milinković
Borjan (Boki) Milinković
@MilinkovBorjan -
 Fernando Rosas 🦋
Fernando Rosas 🦋
@_fernando_rosas -
 Adrien Doerig
Adrien Doerig
@AdrienDoerig -
 Manuel Baltieri
Manuel Baltieri
@manuelbaltieri -
 Alec Tschantz
Alec Tschantz
@a_tschantz -
 Andrew Corcoran
Andrew Corcoran
@mr_corcorana -
 Adeel Razi
Adeel Razi
@adeelrazi -
 Frank Schumann 🐘 @[email protected]
Frank Schumann 🐘 @[email protected]
@SchumannFrank -
 martin biehl
martin biehl
@36zimmer -
 Mindflowers
Mindflowers
@Mindflower1969
Something went wrong.
Something went wrong.