
personally I feel like the inflection point was early 2022. The sweet spot where clip-guided diffusion was just taking off, forcing unconditional models to be conditional through strange patchwork of CLIP evaluating slices of the canvas at a time. It was like improv, always…





Image synthesis used to look so good. These are from 2021. I feel like this was an inflection point, and the space has metastasized into something abhorrent today (Grok, etc). Even with no legible representational forms, there was so much possibility in these images.




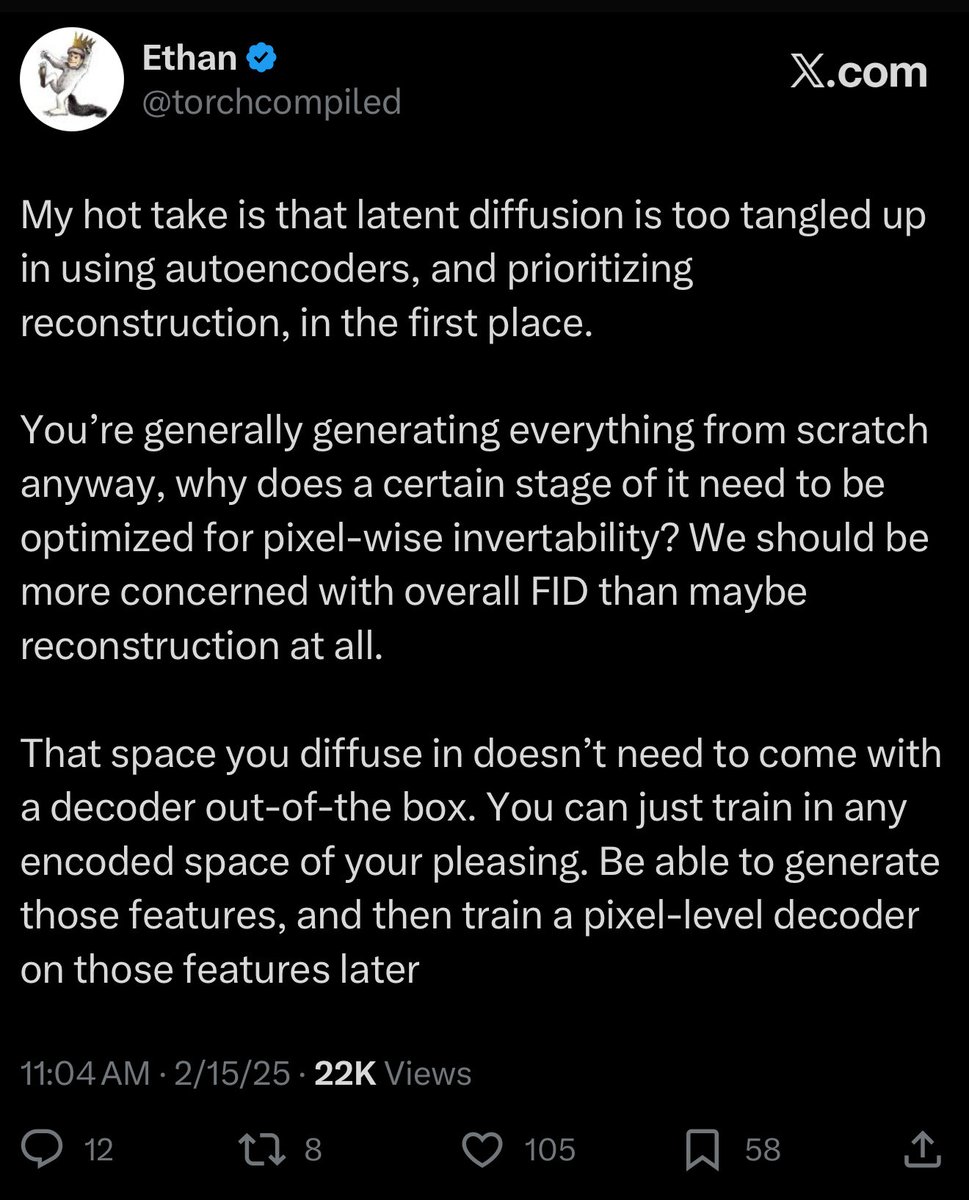
I think this aged well. There’s been quite a bit on training VAEs to have favorable representations, aligning them with embedding models. Why not just use the embedding models themself as the latent space?

three years ago, DiT replaced the legacy unet with a transformer-based denoising backbone. we knew the bulky VAEs would be the next to go -- we just waited until we could do it right. today, we introduce Representation Autoencoders (RAE). >> Retire VAEs. Use RAEs. 👇(1/n)

In getting the outcomes we want from models, it all comes down to search. There’s two strategies here - reducing size of search space - searching efficiently Finetuning, RL, and prompt engineering all tighten the generative distribution around the outputs we want. Searching…
New post! As opposed to building reward models over human ratings and using them for RL, can a model develop its own reward function? Humans seem to develop their own aesthetic preferences through exploration and socializing. How can we mimic this for generative models?

2 raised solutions here: 1 captures the social aspect while leaving out the difficulty of exploration: That one's taste develops by learning about other's tastes, we could imagine training a generative model trained over a dataset of many reward models, and sample new plausible…


New post! As opposed to building reward models over human ratings and using them for RL, can a model develop its own reward function? Humans seem to develop their own aesthetic preferences through exploration and socializing. How can we mimic this for generative models?
New post! I believe we can think of ourselves in two different lenses: an exact point of experience and the history of our patterns of behavior. Though the two are deeply interconnected.































































































































United States 趨勢
- 1. Rickey 2,291 posts
- 2. Big Balls 22.4K posts
- 3. #BeyondTheGates 5,472 posts
- 4. Waddle 3,382 posts
- 5. Argentina 496K posts
- 6. Kings 156K posts
- 7. Westbrook 16.7K posts
- 8. Olave 2,949 posts
- 9. $HIMS 3,872 posts
- 10. Voting Rights Act 25.8K posts
- 11. Maybe in California N/A
- 12. #TrumpsShutdownDragsOn 5,819 posts
- 13. Hayley 5,158 posts
- 14. #ClockTower1Year N/A
- 15. Justice Jackson 18K posts
- 16. Meyers 2,348 posts
- 17. Veo 3.1 5,680 posts
- 18. Aphrodite 4,331 posts
- 19. annabeth 2,334 posts
- 20. Capitol Police 26.1K posts
Something went wrong.
Something went wrong.