
Vishal Patel
@vishalm_patel
Associate Professor @JohnsHopkins working on computer vision, biometrics, and medical imaging.
قد يعجبك
















Why can language teach MLLMs to see? Read thoughts on: 👀 Visual priors embeded in language ➡️ How reasoning transfer across modalities 🧠 How SVGs from #Gemini 3 pro hint at a model’s inner “cognitive imaginery”. ✨ Blog: medium.com/@yanawei/throu… (Stay tuned!)

CGCE: a plug-and-play framework for robustly erasing unsafe concepts from generative models without retraining. Achieves state-of-the-art safety while preserving image & video quality. Great work by @vng_sofw! @JHUengineering Project page: viettmab.github.io/cgce.github.io/
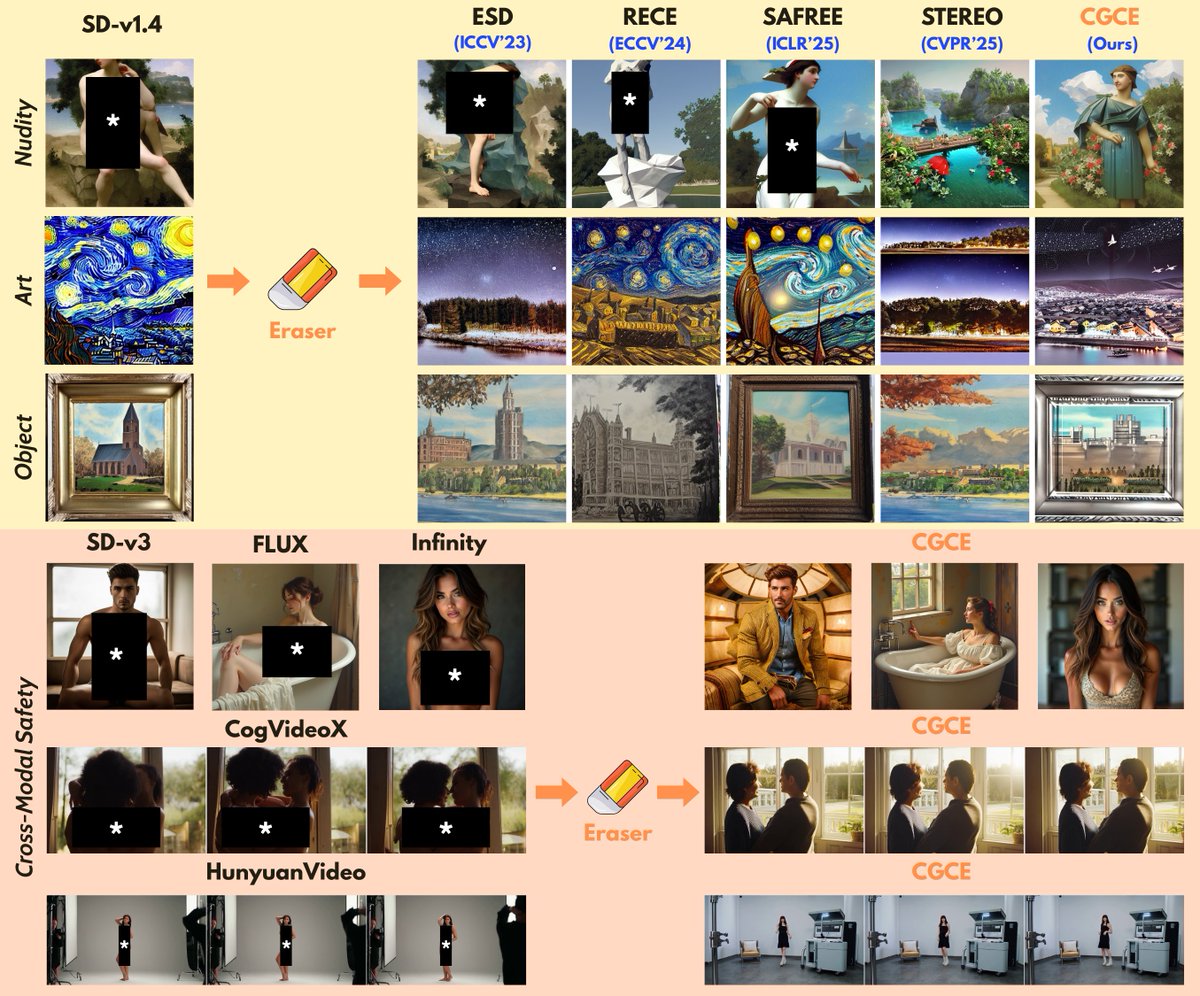

💥New paper: CGCE: Classifier-Guided Concept Erasure in Generative Models 📄Arxiv: arxiv.org/abs/2511.05865 🌐Project Page: viettmab.github.io/cgce.github.io Details in 🧵[1/n]

Congratulations to Malone researchers Swaroop Vedula, @ShameemaSikder, @vishalm_patel, and Masaru Ishii on their $1.2 million @NSF grant, which will fund the development of #AI capable of giving surgeons expert feedback from videos of their performance: malonecenter.jhu.edu/malone-researc…


🤯 Think better visuals mean better world models? Think again. 💥 Surprise: Agents don’t need eye candy— they need wins. Meet World-in-World, the first open benchmark that ranks world models by closed-loop task success, not pixels. We uncover 3 shocks: 1️⃣ Visuals ≠ utility 2️⃣…

Our new work FreeViS: Training-free Video Stylization with Inconsistent References introduces a training-free framework for generating high-quality, temporally coherent stylized videos ! 🌀 Check it out: xujiacong.github.io/FreeViS/ @HopkinsEngineer @myq_1997 #AI #CV #DeepLearning
Exciting news! My former student, Dr. Shao-Yuan Lo—now an Asst. Prof. at NTU—has been awarded as a Yushan Young Fellow by Taiwan’s Ministry of Education, the nation’s highest honor for rising faculty. Huge congratulations—so proud of you! 👏@HopkinsEngineer @JHUECE @shaoyuanlo


Project webpage & code - virobo-15.github.io/srdd.github.io/ Arxiv - arxiv.org/pdf/2509.22636 This project was co-led with Nithin Gopalakrishnan Nair (@NithinGK10) under the guidance of Vishal Patel(@vishalm_patel).

Scaling Transformer-Based Novel View Synthesis Models with Token Disentanglement and Synthetic Data Nithin Gopalakrishnan Nair, Srinivas Kaza, @XuanLuo14, @vishalm_patel, Stephen Lombardi, Jungyeon Park tl;dr: layer-wise modulation of source and target tokens->synthetic data…





#HopkinsDSAI welcomes 22 new faculty members, who join more than 150 DSAI faculty members across @JohnsHopkins in advancing the study of data science, machine learning, and #AI and translation to a range of critical and emerging fields. ai.jhu.edu/news/data-scie…


Think before you diffuse: DiffPhy from @vishalm_patel and team delivers realistic physics in AI video generation by enlisting LLMs to reason about the physical context. Multimodal LLMs evaluate and fine tune the model. GitHub page: bwgzk-keke.github.io/DiffPhy/
🚀 Check out our ✈️ ICML 2025 work: Perception in Reflection! A reasonable perception paradigm for LVLMs should be iterative rather than a single-pass. 💡 Key Ideas 👉 Builds a perception-feedback loop through a curated visual reflection dataset. 👉 Utilizes Reflective…



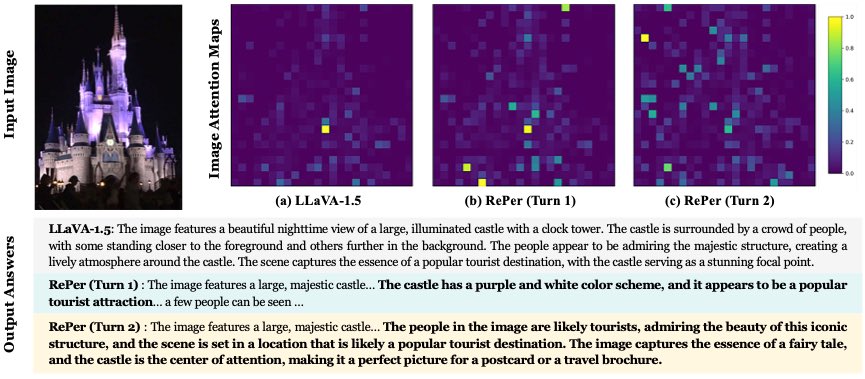
🪞 We'll present Perception in Reflection at ICML this week! We introduce RePer, a dual-model framework that improves visual understanding through reflection. Better captions, fewer hallucinations, stronger alignment. 📄 arxiv.org/pdf/2504.07165 #ICML2025 @yanawei_ @JHUCompSci
🚀 Open Vision Reasoner (OVR) Transferring linguistic cognitive behaviors to visual reasoning via large-scale multimodal RL. SOTA on MATH500 (95.3%), MathVision, and MathVerse. 💻 Code: github.com/Open-Reasoner-… 🌐 Project: weiyana.github.io/Open-Vision-Re… #LLM @yanawei @HopkinsEngineer

#ICCV2025 🌺FaceXFormer has been accepted by ICCV !
FaceXFormer: A Unified Transformer for Facial Analysis w/ @vibashan @KartikNarayan10 @jhuclsp @HopkinsEngineer @JHUECE Paper: arxiv.org/abs/2403.12960 Code: github.com/Kartik-3004/fa… Website: kartik-3004.github.io/facexformer_we…

🎨 New work: Training-Free Stylized Abstraction Generate stylized avatars (LEGO, South Park, dolls) from a single image ! 💡 VLM-guided identity distillation 📊 StyleBench eval @HopkinsDSAI @JHUECE @jhucs @KartikNarayan10 @HopkinsEngineer 🔗 kartik-3004.github.io/TF-SA/


STEREO: A Two-Stage Framework for Adversarially Robust Concept Erasing from Text-to-Image Diffusion Models tldr: iteratively discover and mitigate adversarial prompts, then go back to original model and mitigate in parallel (with anchor concepts to reduce unwanted side effects)…



Hopkins researchers including @JHUECE Tinoosh Mohsenin and @JHU_BDPs Rama Chellappa are speaking at booth 1317 of the IEEE / CVF Computer Vision and Pattern Recognition Conference today! Come meet #HopkinsDSAI #CVPR2025

The #WACV2026 Call for Papers is live at wacv.thecvf.com/Conferences/20……! First round paper registration is coming up on July 11th, with the submission deadline on July 18th (all deadlines are 23:59 AoE).


@CVPR IS AROUND THE CORNER! #CVPR2025 Welcome to join our Medical Vision Foundation Model Workshop on June 11th, from 8:30 to 12:00 at Room 212.! We are also proud to host an esteemed lineup of speakers: Dr. Jakob Nikolas Kather @jnkath Dr. Faisal Mahmood @AI4Pathology Dr.…
Excited to announce the 2nd Workshop on Foundation Models for Medical Vision (FMV) at #CVPR2025! @CVPR 🌐 fmv-cvpr25workshop.github.io FMV brings together researchers pushing the boundaries of medical AGI. We are also proud to host an esteemed lineup of speakers: Dr. Jakob Nikolas…
































































































United States الاتجاهات
- 1. Mateer 6,440 posts
- 2. Michigan 150K posts
- 3. Tim Banks 1,689 posts
- 4. Pavia 4,218 posts
- 5. Vandy 9,039 posts
- 6. Ohio State 67.9K posts
- 7. Oklahoma 25.6K posts
- 8. Rutgers 3,469 posts
- 9. #SurvivorSeries 23.3K posts
- 10. Heupel 1,073 posts
- 11. Arbuckle 1,199 posts
- 12. Hawkins 13.5K posts
- 13. Venezuela 501K posts
- 14. Buckeyes 21.7K posts
- 15. #Sooners 1,841 posts
- 16. Bono 8,894 posts
- 17. Jaylen Brown 2,315 posts
- 18. Malik Benson N/A
- 19. Hunter Simmons N/A
- 20. Miami 69.6K posts
قد يعجبك
-
 WACV
WACV
@wacv_official -
 Walter Scheirer
Walter Scheirer
@wjscheirer -
 Adam Kortylewski 🚨 Hiring PhD students
Adam Kortylewski 🚨 Hiring PhD students
@AdamKortylewski -
 Min-Hung (Steve) Chen
Min-Hung (Steve) Chen
@CMHungSteven -
 Mubarak Shah
Mubarak Shah
@ucfmshah -
 Andrew Owens
Andrew Owens
@andrewhowens -
 Shao-Yuan Lo
Shao-Yuan Lo
@shaoyuanlo -
 Yiqun Mei
Yiqun Mei
@myq_1997 -
 He Zhang
He Zhang
@zhanghesprinter -
 Rohit
Rohit
@rohitrango -
 Ning Yu (hiring interns)
Ning Yu (hiring interns)
@realNingYu -
 Jeya Maria Jose
Jeya Maria Jose
@jeyamariajose -
 Deqing Sun
Deqing Sun
@DeqingSun -
 Parag Jain
Parag Jain
@jparag123 -
 Yanshuai Cao ✈️ NeurIPS 25
Yanshuai Cao ✈️ NeurIPS 25
@yanshuaicao
Something went wrong.
Something went wrong.