

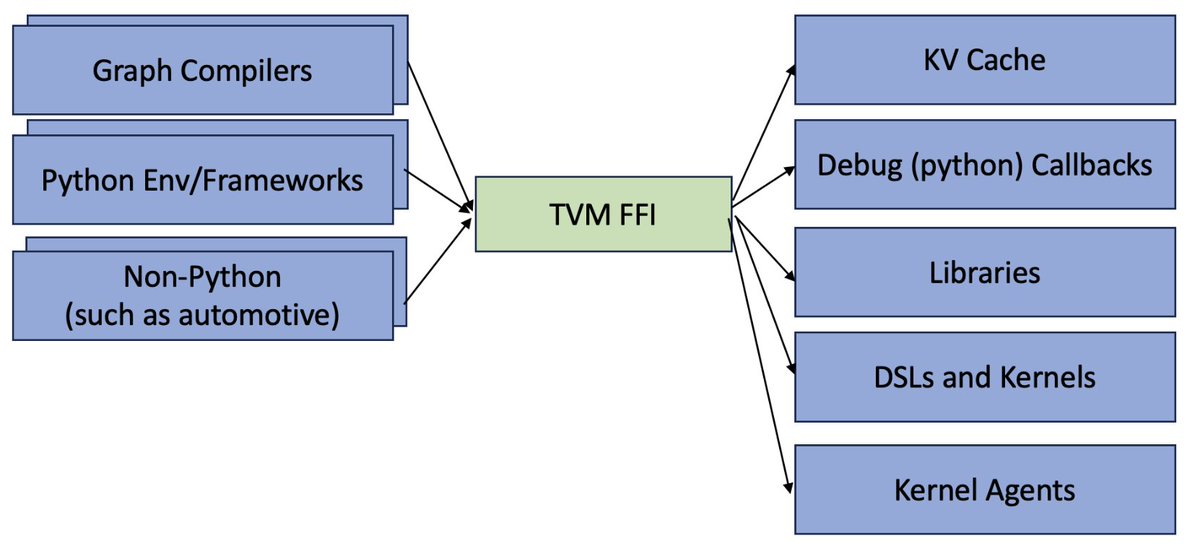
📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust tvm.apache.org/2025/10/21/tvm…

🤔 Can AI optimize the systems it runs on? 🚀 Introducing FlashInfer-Bench, a workflow that makes AI systems self-improving with agents: - Standardized signature for LLM serving kernels - Implement kernels with your preferred language - Benchmark them against real-world serving…


The SGLang team just ran DeepSeek 671B on NVIDIA’s GB200 NVL72, unlocking 7,583 toks/sec/GPU for decoding w/ PD disaggregation + large-scale expert parallelism — 2.7× faster than H100. Don’t miss this work! 🔥 Thanks to Pen Li from NVIDIA who kicked off this collaboration and…


We’re thrilled that FlashInfer won a Best Paper Award at MLSys 2025! 🎉 This wouldn’t have been possible without the community — huge thanks to @lmsysorg’s sglang for deep co-design (which is crtical for inference kernel evolution) and stress-testing over the years, and to…

🎉 Congratulations to the FlashInfer team – their technical paper, "FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving," just won best paper at #MLSys2025. 🏆 🙌 We are excited to share that we are now backing FlashInfer – a supporter and…




































United States Trends
- 1. Grammy 223K posts
- 2. Clipse 13.5K posts
- 3. Kendrick 50.3K posts
- 4. Dizzy 8,357 posts
- 5. olivia dean 11.3K posts
- 6. addison rae 18K posts
- 7. gaga 86.9K posts
- 8. AOTY 16.4K posts
- 9. Leon Thomas 14.3K posts
- 10. Katseye 96.9K posts
- 11. #FanCashDropPromotion 3,355 posts
- 12. Kehlani 29.3K posts
- 13. ravyn lenae 2,359 posts
- 14. lorde 10.5K posts
- 15. Durand 4,225 posts
- 16. Album of the Year 52.5K posts
- 17. Alfredo 2 N/A
- 18. The Weeknd 9,642 posts
- 19. #FridayVibes 6,688 posts
- 20. Luther 21.4K posts
Something went wrong.
Something went wrong.