
Yu Zhang 🐈🐙
@yzhang_cs
@Kimi_Moonshot; PhD Student @ Soochow University; working on efficient methods for LLMs; disciple of parallel programming; INTP
You might like


Weight Decay and Learning Rate from a EMA View kexue.fm/archives/11459 Derives optimal WD and LR schedules from this perspective.

语言即世界工作室和微博合作了一档全新的节目《未竟之约》。 在变化的时空里,表达与观察是没有起点和终点的,从此刻出发,一起走向未竟的旅程🎧🎧🎧





Hope you enjoyed yesterday’s poster! We were honored to have @SonglinYang4, @Xinyu2ML, @wen_kaiyue, and many other esteemed researchers visit and share their guidance! 🚀

🧐🧐🧐



I will talk about recent developments of linear attention, like GLA, deltanet, GDN, and KDA. The application of linear attention to latest frontier models like Qwen 3 next and kimi linear. It’s strong coherence with test time learning. And the exciting future ahead! Also Looking…

We're super excited to host our fourth NeurIPS reading group with @Yikang_Shen, including lunch sponsored by @StrikerVP! We'll gather 25-30 researchers to discuss Linear Attention and DeltaNet, including their usage in recent models like Qwen3-Next and Kimi Linear, RSVP below!


I will go to NeurIPS 2025@San Diego during Dec. 2-7 for my spotlight paper "Tensor product attention is all you need", and I'm also excited to meet all of you there to discuss anything interesting, exciting and enlightening about AI, LLMs and next trend of innovation.


Details on the trinity architecture that we settled on!





Open source is probably the new or final form of publication for academia.

If Gemini-3 proved continual scaling pretraining, DeepSeek-V3.2-Speciale proves scaling RL with large context. We spent a year pushing DeepSeek-V3 to its limits. The lesson is post-training bottlenecks are solved by refining methods and data, not just waiting for a better base.

🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now. 📄 Tech…
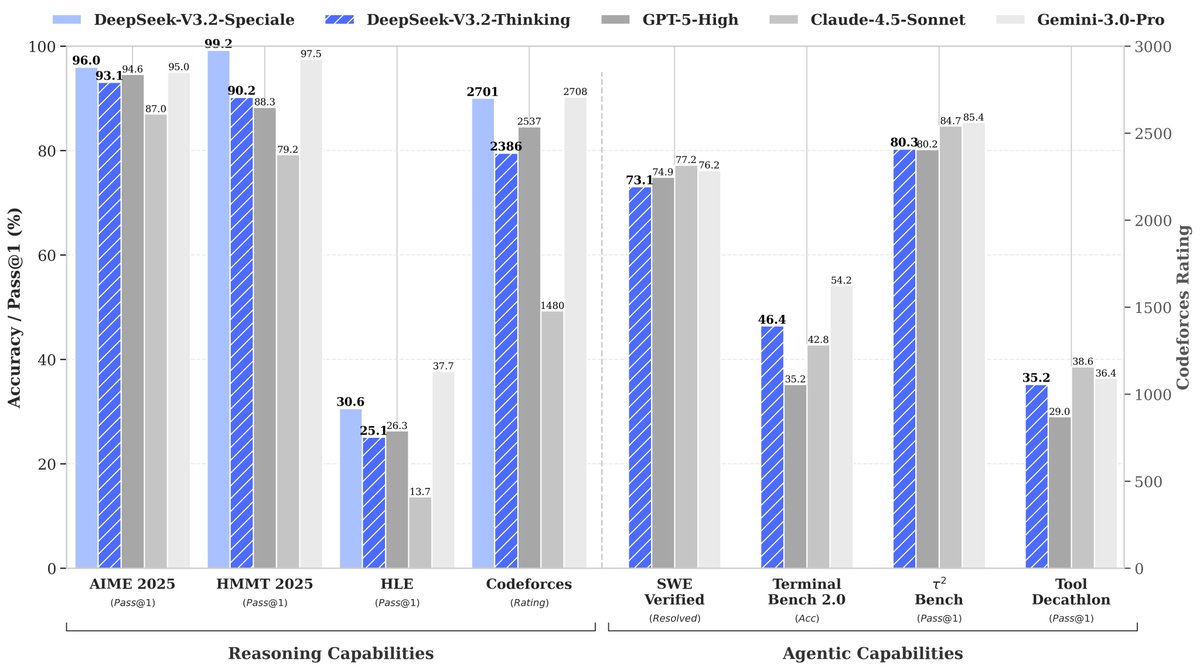
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now. 📄 Tech…



enough preamble. The most important part in every Whale paper, as I've said so many times over these years, is “Conclusion, Limitation, and Future Work”. They say: Frontier has no knowledge advantage. Compute is the only serious differentiator left. Time to get more GPUs.


Congrats to @Alibaba_Qwen! Great to hear that our Attention Sink study 2 years ago leads to strong architecture improvement and more stable model training😀

🏆 We are incredibly honored to announce that our paper, "Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free" has received the NeurIPS 2025 Best Paper Award! A huge congratulations to our dedicated research team for pushing the boundaries…


Tencent YouTu Lab just dropped SSA: Sparse Sparse Attention for efficient LLM processing This new framework for long-context inference achieves state-of-the-art by explicitly encouraging sparser attention distributions, outperforming existing methods in perplexity across huge…

Sleep at 6:00 a.m. 👻
Healthy sleep schedules: Sleep at 8:00PM → Wake up at 3:30AM Sleep at 8:30PM → Wake up at 4:00AM Sleep at 9:00PM → Wake up at 4:30AM Sleep at 9:30PM → Wake up at 5:00AM Sleep at 10:00PM → Wake up at 5:30AM Sleep at 10:30PM → Wake up at 6:00AM Sleep at 11:00PM → Wake up at…

Interested in how we can use ideas from Flash Attention for more efficient linear RNN kernels? I am heading to NeurIPS in San Diego to present our work on Tiled Flash Linear Attention: More Efficient Linear RNN and xLSTM Kernels.


Lol what a shitshow @iclr_conf I'm sure the new ACs will take the rebuttals into account in a meaningful way when they decide to keep the original scores. What a waste of effort for everyone who spent time on rebuttals, and what a stupid reaction to the leak 🤦


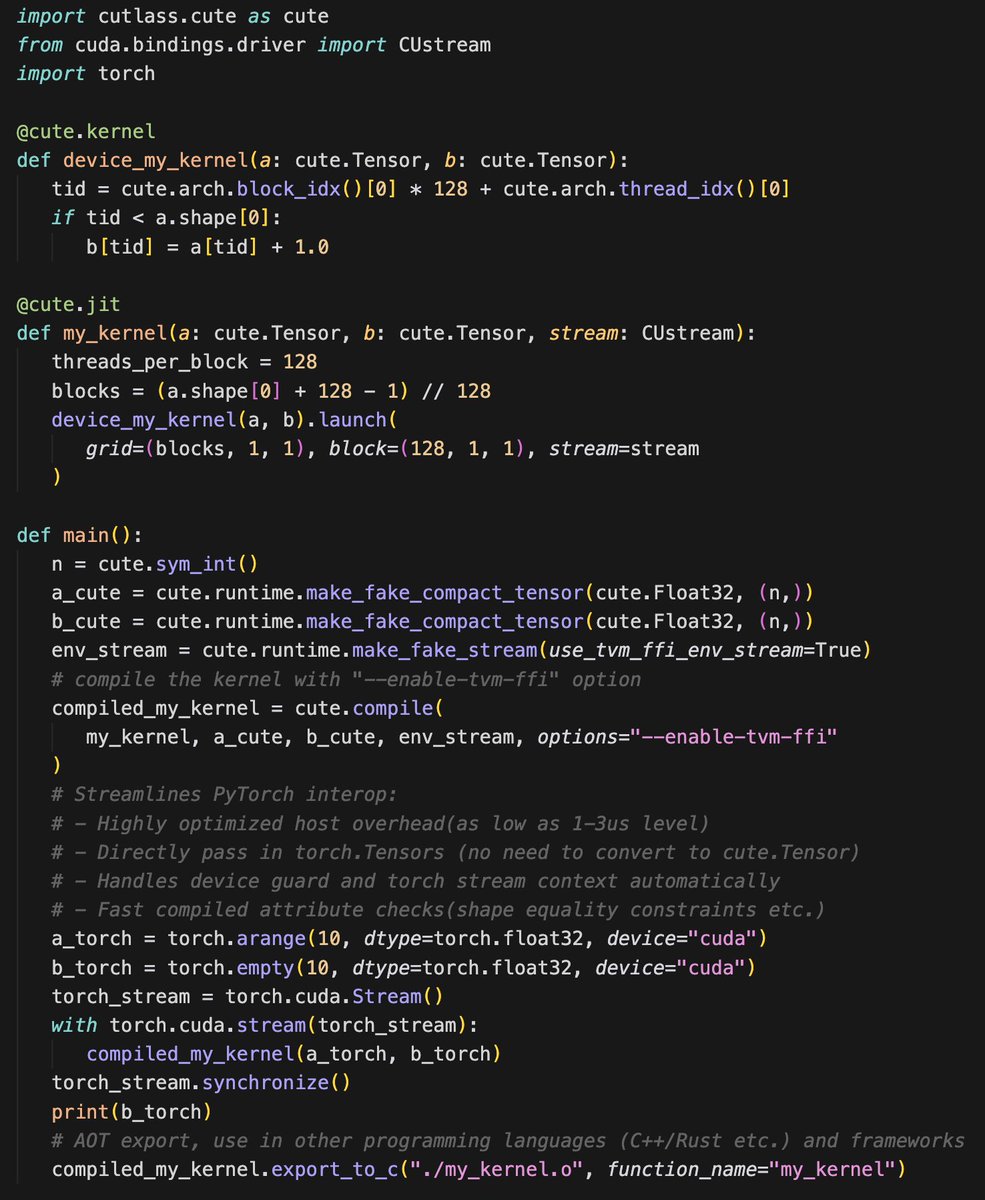
CuteDSL 4.3.1 is here 🚀 Major host overhead optimization (10-40µs down to a 2µs in hot loops_, streamlined PyTorch interop (pass torch.Tensors directly, no more conversions needed) and export and use in more languages and envs. All powered by apache tvm-ffi ABI





























































































United States Trends
- 1. Cloudflare 20.1K posts
- 2. Cowboys 73.9K posts
- 3. #heatedrivalry 27.1K posts
- 4. LeBron 110K posts
- 5. Gibbs 20.5K posts
- 6. Pickens 14.7K posts
- 7. fnaf 2 26.9K posts
- 8. Lions 92.1K posts
- 9. scott hunter 5,799 posts
- 10. Warner Bros 24K posts
- 11. Paramount 20.9K posts
- 12. Shang Tsung 32.2K posts
- 13. #PowerForce N/A
- 14. #OnePride 10.6K posts
- 15. Brandon Aubrey 7,463 posts
- 16. Ferguson 11K posts
- 17. Cary 42.4K posts
- 18. Scott and Kip 3,275 posts
- 19. Eberflus 2,699 posts
- 20. CeeDee 10.7K posts
You might like

Something went wrong.
Something went wrong.