#aibenchmarks نتائج البحث

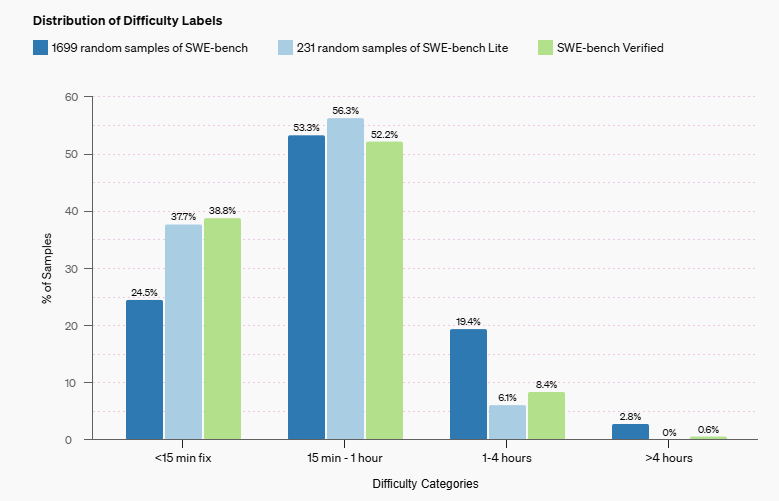
OpenAI launches SWE-bench Verified, a human-validated subset of the popular SWE-bench AI benchmark for evaluating software engineering abilities. GPT-4's score more than doubles! 📈How will this impact AI development in software engineering? #AIBenchmarks #SoftwareEngineering

"You need to have these very hard tasks which produce undeniable evidence. And that's how the field is making progress today, because we have these hard benchmarks, which represent true progress. And this is why we're able to avoid endless debate." #AIbenchmarks -Ilya Sutskever

It's possible for AI tools to advance the UN's #SDGs, but industry needs to align developers' goals with communities' priorities. This requires better #AIBenchmarks. What are benchmarks, and how can they help? B Cavello explains in this video. Learn more: ow.ly/3VJ650WZ3gV

Claude 4 is here—and it's a powerhouse. Outperforms GPT-4 and Gemini 2.5 in reasoning, coding, and long-context tasks. Fast, smart, and ready. #Claude4 #AIbenchmarks

If you are about to buy an AI product or service, wait. Listen to this before going ahead. aiforreal.substack.com/p/five-key-thi… #aiproducts #aimetrics #aibenchmarks

ERNIE is beating GPT and Gemini on key benchmarks While everyone obsesses over OpenAI and Google, Baidu quietly built something better. And most people have no idea. #ERNIE #BaiduAI #AIBenchmarks #GPTvsERNIE #GeminiComparison


AI Benchmarks RIGGED? Shocking Truth Exposed! (ChatGPT, Claude) #AIBenchmarks #ChatGPT #ClaudeAI #OpenAI #GoogleAI #AIModelEvaluation #ArtificialIntelligence #DataScience #MachineLearning #AIFraud

SWE-bench, launched in Oct 2023, challenges AI coding with 2,294 real-world software engineering problems, raising the bar for AI proficiency. #AIBenchmarks #CodingAI @Stanford

MMLU evaluates LLM performance across 57 subjects in zero-shot or few-shot scenarios, with GPT-4 and Gemini Ultra achieving top scores. #AIbenchmarks #MMLU @Stanford


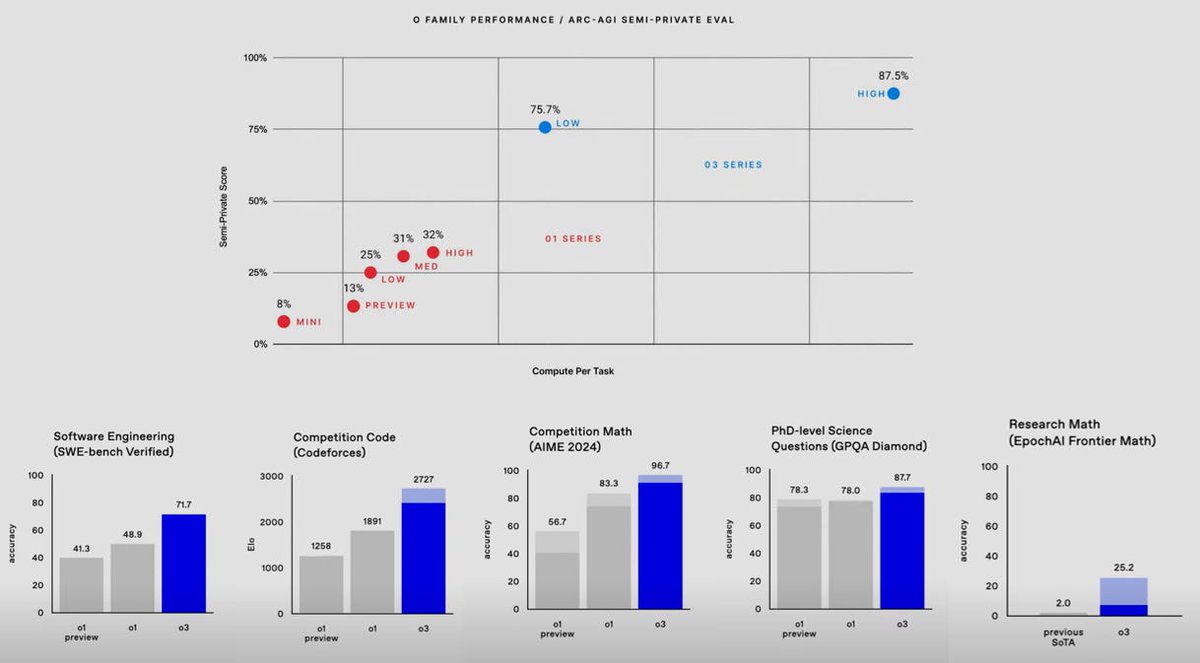
Epic AI's Frontier Math: The Toughest Benchmark Yet! #EpicAI #FrontierMath #AIBenchmarks #Mathematics #MachineLearning #DataScience #AIChallenges #CriticalThinking #ProblemSolving #Innovation
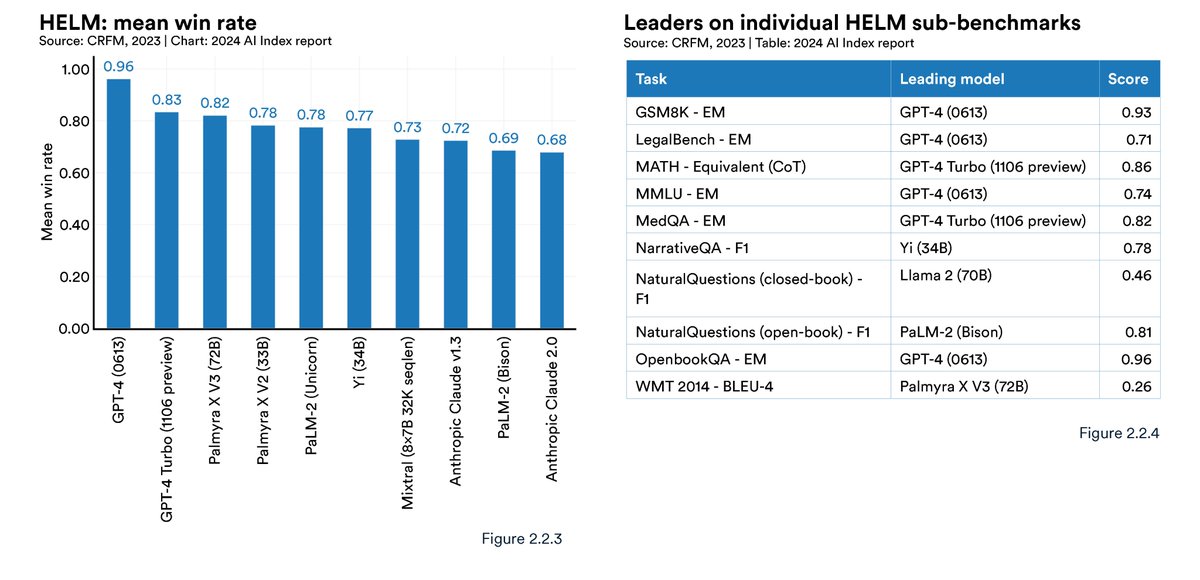
HELM (Holistic Evaluation of Language Models) benchmarks LLMs across diverse tasks like reading comprehension, language understanding, and math, with GPT-4 currently leading the leaderboard. #AIbenchmarks @Stanford

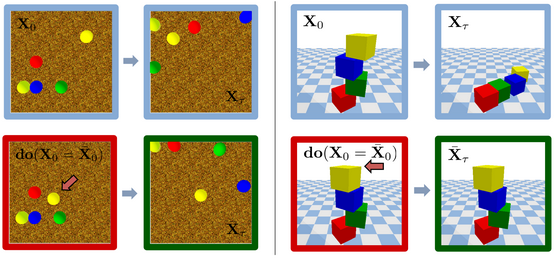
A comprehensive view of existing benchmarks for evaluating AI systems' physical reasoning capabilities. #PhysicalReasoning #AIBenchmarks #GeneralistAgents

How Accurate Is #AI at Fixing IaC Security Flaws? 🤔 Eye-opening results: many AI models miss the mark—not from lack of power, but focus. Read the article from our friends at @SymbioticSecAI → symbioticsec.ai/blog/cracking-… #AIBenchmarks #CodeSecurity #DevSecOps #IaC #AppSec


New benchmark launched that tests AI Models' advanced mathematical reasoning. tinyurl.com/2zy2kkm6 #aimodels #LLMs #aibenchmarks #aiforreal @EpochAIResearch

MLCommons introduces MLPerf Client group to create AI benchmarks for PCs, providing clarity on device performance for AI tasks. #TechNews #AIBenchmarks Link: techcrunch.com/2024/01/24/mlc…


LLM Reasoning Benchmarks: Study Reveals Statistical Fragility in RL Gains #LLMResearch #AIBenchmarks #ReinforcementLearning #SupervisedLearning #AIInvestment itinai.com/llm-reasoning-…


Benchmarkers already show Speciale hitting: 🏅 IMO gold 🏅 CMO gold 🏅 IOI top-tier 🏅 ICPC-world-level coding Read that again: The first open-weights Olympiad-tier reasoning model comes from China, not the US. #AIbenchmarks #MathAI #CodingAI

🧠 Reasoning results shocked people. Claude Opus 4.5 led in logic, math and multi-step planning, but GPT-5.1 & Gemini 3 Pro were right behind it. The gap is razor-thin and shrinking daily. 🤏🔥 #AIbenchmarks

1M tokens. Full codebase understanding. PhD-level reasoning. Gemini 3 is built for real work, not demo videos. #Gemini3 #GoogleCloud #AIbenchmarks

Grok’s dominance across diverse leaderboards is impressive, especially #1 in Token Usage and Programming Usecase – that indicates not just popularity but real developer trust. Curious how Grok’s agentic telecom edge will push real-world AI automation next? #AIbenchmarks…

🤯 Crushing Benchmarks! Gemini 3.0 Pro significantly outperforms 2.5 Pro on *every* major AI benchmark. It even tops the LMArena Leaderboard with an incredible 1501 Elo score! #AIBenchmarks #GeminiPro
ERNIE is beating GPT and Gemini on key benchmarks While everyone obsesses over OpenAI and Google, Baidu quietly built something better. And most people have no idea. #ERNIE #BaiduAI #AIBenchmarks #GPTvsERNIE #GeminiComparison

China’s Open-Source Triumph in AI: Kimi K2 Thinking Rewrites the Rules digitrendz.blog/?p=81781 #AiBenchmarks #GenerativeAI #KimiK2Thinking #MoonshotAi


Reproducibility validated standard Android A* pathfinding stack; uniform heuristics, 8-directional grid, weighted cost 1.0–1.4. SBOL layer calibrated bias 0.97 ± 0.02 across 1 000 runs, zero-drift at six months. Code held pending IP finalization #SBOL #Grokpedia #AIbenchmarks

Anthropic's Claude AI outperformed GPT-4 by 15% on reasoning tests, showcasing advanced multi-agent AI workflows. Hive Forge’s Swarms align perfectly to boost such complex automation across teams. Could this shift how enterprises adopt AI orchestration? #AIbenchmarks #ClaudeAI

Gemini 3.0 is a surprise leader in coding/visual benchmarks, beating Sonnet 4.5. Vision models can now reliably tell time... a huge step for multimodal AI. #GoogleGemini #AIBenchmarks

📊 Results: 1. ImageNet (256×256) FID: 3.43 using just 1 step (1-NFE) 2. 50–70% better than past best models 3. Matches big multi-step models at just 2 steps! 🤯 #SOTA #AIbenchmarks


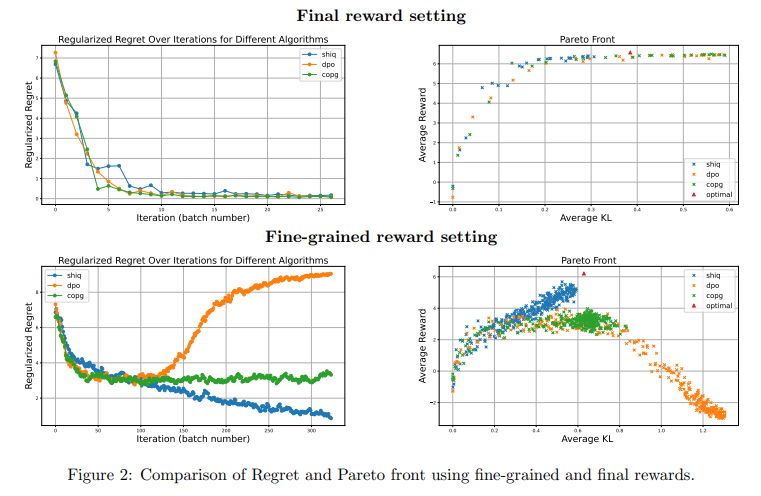
Real results 📊 ShiQ did great in tests: ✔️ It learned faster ✔️ Needed less data ✔️ Worked better for multi-turn conversations #AIbenchmarks #AIperformance

Did it work? YES. 💥 It beat big models in tests. 🧠 Understands images better 🎨 Generates nicer pictures ✅ Even humans liked its results more than others #AIbenchmarks


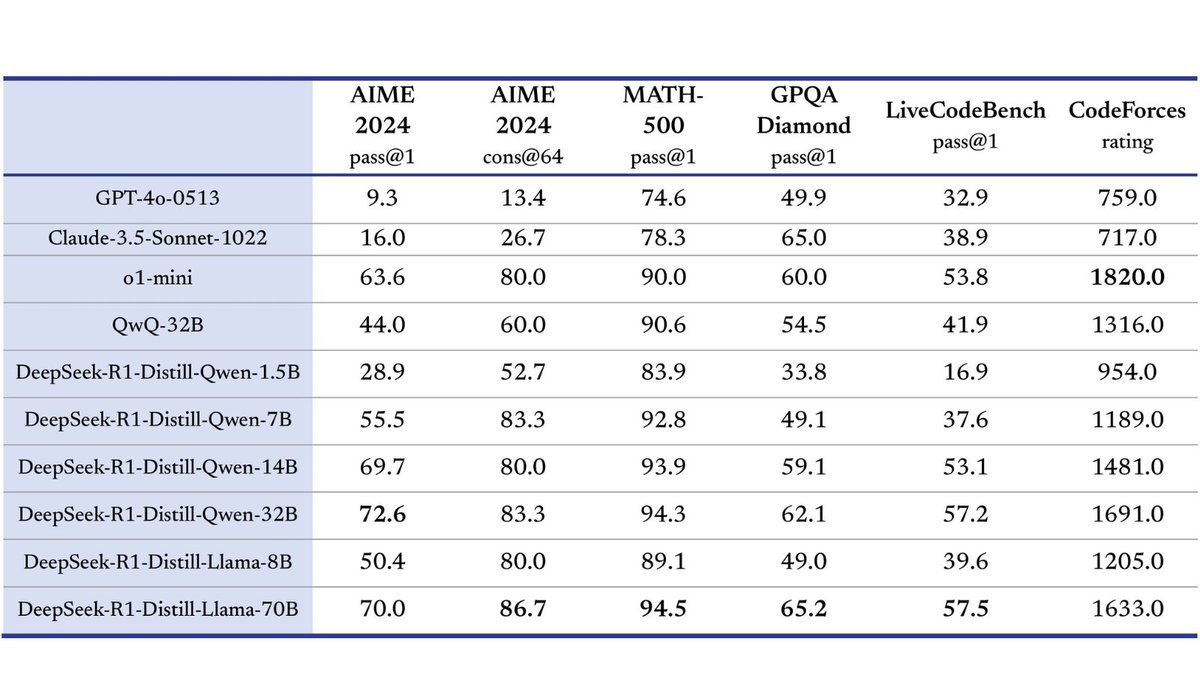
Performance speaks volumes! 📊 DeepSeek-R1 outperforms competitors across benchmarks like AIME 2024 and MATH, showcasing groundbreaking accuracy. #DeepSeekR1 #AIBenchmarks
"You need to have these very hard tasks which produce undeniable evidence. And that's how the field is making progress today, because we have these hard benchmarks, which represent true progress. And this is why we're able to avoid endless debate." #AIbenchmarks -Ilya Sutskever
Claude 4 is here—and it's a powerhouse. Outperforms GPT-4 and Gemini 2.5 in reasoning, coding, and long-context tasks. Fast, smart, and ready. #Claude4 #AIbenchmarks
ERNIE is beating GPT and Gemini on key benchmarks While everyone obsesses over OpenAI and Google, Baidu quietly built something better. And most people have no idea. #ERNIE #BaiduAI #AIBenchmarks #GPTvsERNIE #GeminiComparison

The numbers are in! GPT-4O takes the lead across the board, but Qwen2.5-72B holds its ground. 93.7 vs 86.1 on MMLU, 97.8 vs 91.5 on GSM8K. The AI race is heating up! #GPT4O #Qwen25 #AIBenchmarks

SWE-bench, launched in Oct 2023, challenges AI coding with 2,294 real-world software engineering problems, raising the bar for AI proficiency. #AIBenchmarks #CodingAI @Stanford
MMLU evaluates LLM performance across 57 subjects in zero-shot or few-shot scenarios, with GPT-4 and Gemini Ultra achieving top scores. #AIbenchmarks #MMLU @Stanford

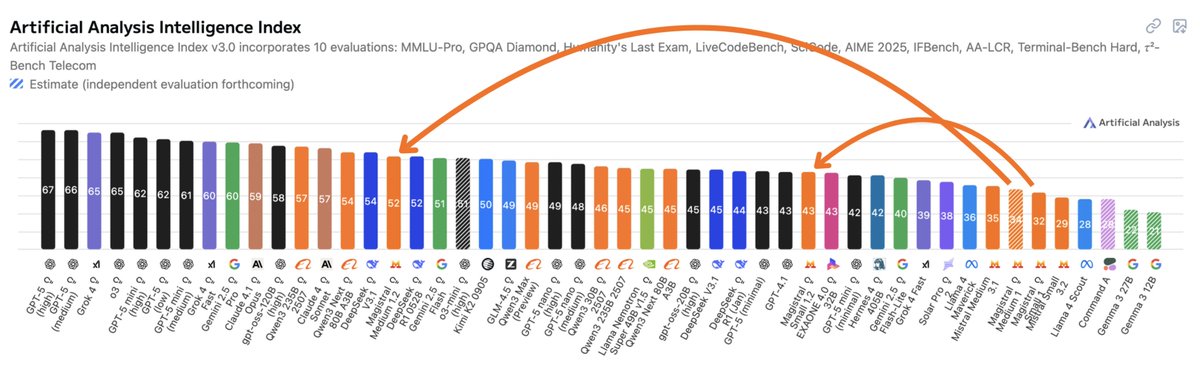
🚀 Impressive leap on the #AI leaderboard: Mistral AI's new Magistral models just jumped up the Artificial Analysis Intelligence Index—punching far above their weight and rivaling models many times larger. Size isn’t everything anymore! #AIbenchmarks #LLMs #MistralAI
OpenAI launches SWE-bench Verified, a human-validated subset of the popular SWE-bench AI benchmark for evaluating software engineering abilities. GPT-4's score more than doubles! 📈How will this impact AI development in software engineering? #AIBenchmarks #SoftwareEngineering

🧵 [5/n] The results are quite promising. After three iterations, the enhanced Llama 2 70B model outperformed others models such as Claude 2 and GPT-4 0613 on the AlpacaEval 2.0 leaderboard. #AIBenchmarks #Performance
![vladbogo's tweet image. 🧵 [5/n] The results are quite promising. After three iterations, the enhanced Llama 2 70B model outperformed others models such as Claude 2 and GPT-4 0613 on the AlpacaEval 2.0 leaderboard. #AIBenchmarks #Performance](https://pbs.twimg.com/media/GEj0XBpXwAAgjxX.png)
HELM (Holistic Evaluation of Language Models) benchmarks LLMs across diverse tasks like reading comprehension, language understanding, and math, with GPT-4 currently leading the leaderboard. #AIbenchmarks @Stanford

3/7:Mistral's latest model, Mixtral 8x22B, is said to outperform Meta's Llama 2 70B in math and coding tests. Mixture-of-experts architecture FTW! #MixtralLLM #AIBenchmarks #TechCompetition


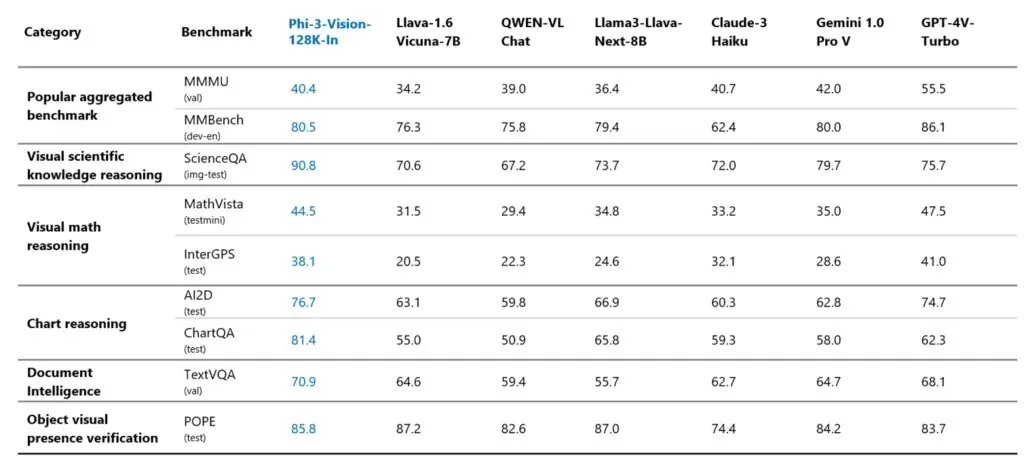
3/9 What's impressive is that despite its smaller size, Ph-3 Vision exceeds in benchmarks, scoring highly in MMU, MM Bench, Science QA, and more. 🏅📊 Smaller but mighty! #AIBenchmarks

Performance of LLMs: GPT-4 from @OpenAI is still leading the open-sourced ones. #GenerativeAI #AIBenchmarks


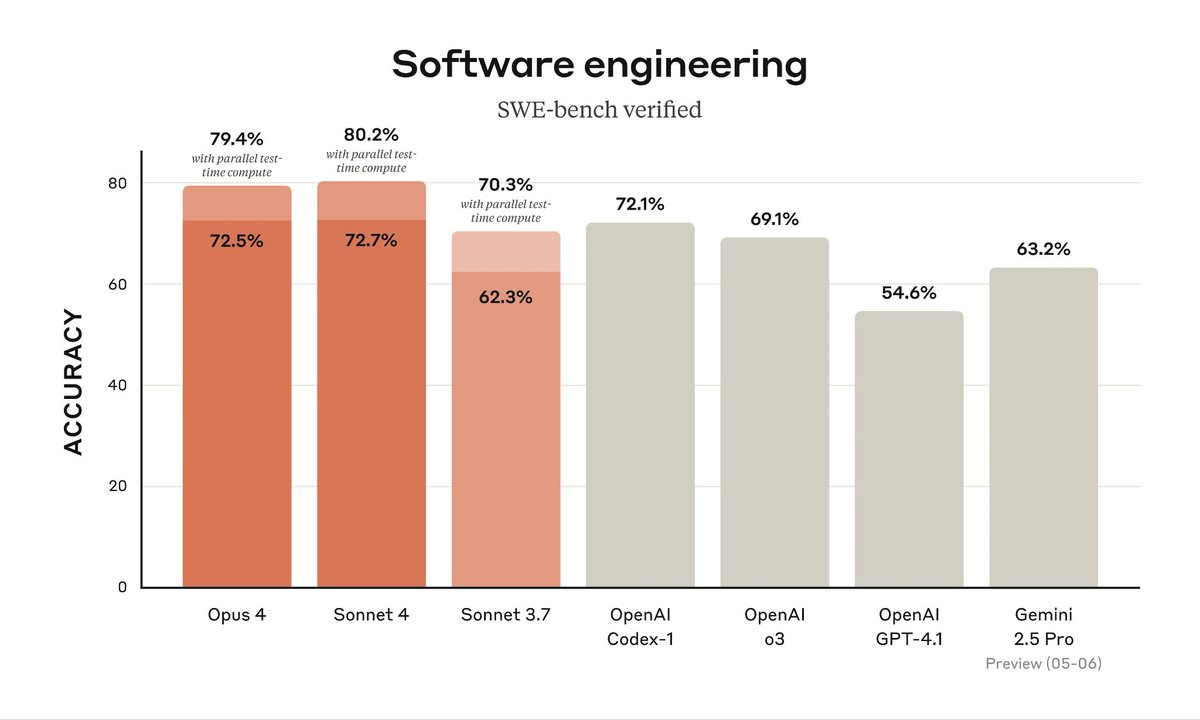
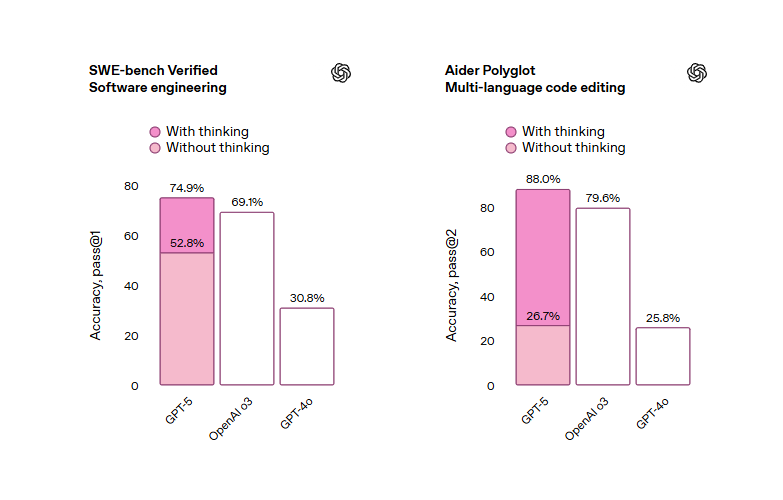
GPT-5 benchmark breakdown Coding performance:• SWE-Bench Verified: 74.9% (vs Claude 74.5%, Gemini 59.6%) • Aider Polyglot: 88% • SWE-Lancer: 55% (thinking mode) The "software on demand" demos are actually working now #GPT5 #AIBenchmarks
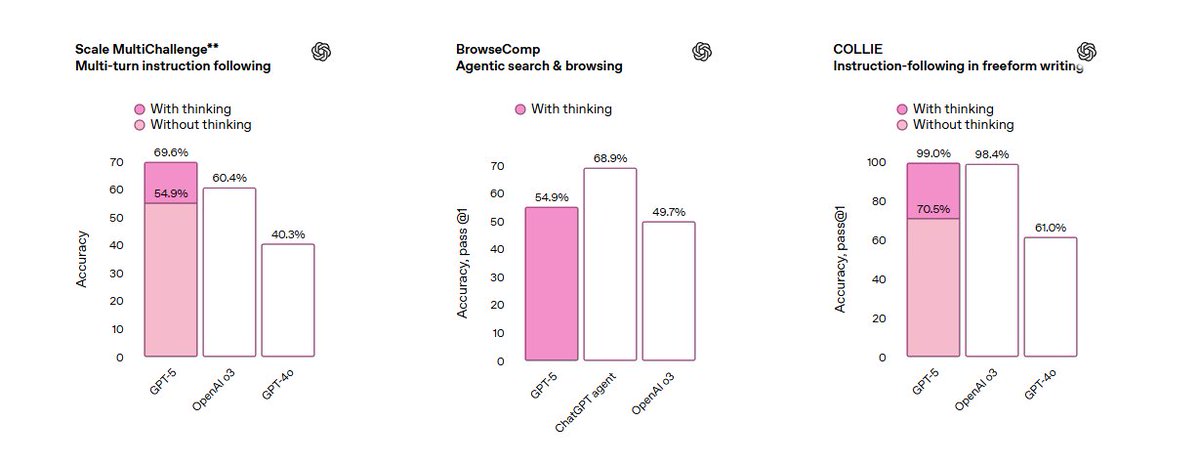
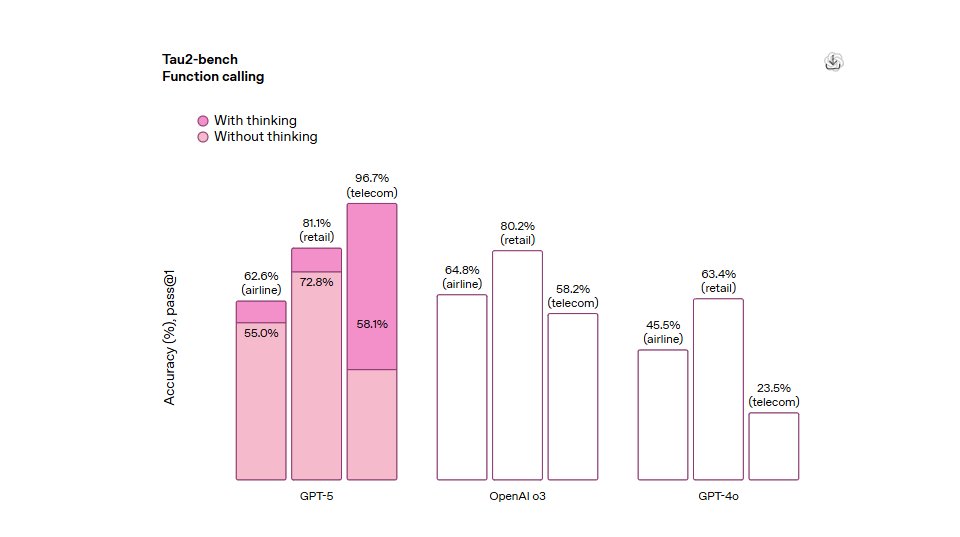

🚨 Claude 3 vs GPT-4 vs Gemini The most powerful AI models are in a tight race. But who’s actually winning — and at what? Let’s break it down with real benchmarks 👇 #AIbenchmarks #LMSYS #LargeLanguageModels #Tech #MachineLearning

Something went wrong.
Something went wrong.
United States Trends
- 1. Brian Cole 24.9K posts
- 2. #Kodezi 1,118 posts
- 3. #TrumpAffordabilityCrisis 2,996 posts
- 4. Woodbridge 4,802 posts
- 5. Jalen Carter 1,160 posts
- 6. KJ Jackson N/A
- 7. Tong 18.3K posts
- 8. Eurovision 63.9K posts
- 9. #NationalCookieDay 1,437 posts
- 10. Rwanda 27K posts
- 11. TPUSA 74.7K posts
- 12. Price 263K posts
- 13. The FBI 124K posts
- 14. Happy Birthday Dan 3,396 posts
- 15. All-Big 2,008 posts
- 16. Merry Christmas 67.2K posts
- 17. Walter Payton 11.9K posts
- 18. Congo 27.7K posts
- 19. Real Steel N/A
- 20. #pipebomber N/A