#decodingaianddatascience arama sonuçları

Data Science vs. Artificial Intelligence: Understanding the Differences. #DataScienceVsAI #UnderstandingTechDifferences #DecodingAIandDataScience #AIvsDataScienceDebate #TechWorldUnveiled palamsolutions.com/?p=15567

Data Science vs. Artificial Intelligence: Understanding the Differences. #DataScienceVsAI #UnderstandingTechDifferences #DecodingAIandDataScience #AIvsDataScienceDebate #TechWorldUnveiled palamsolutions.com/?p=15567

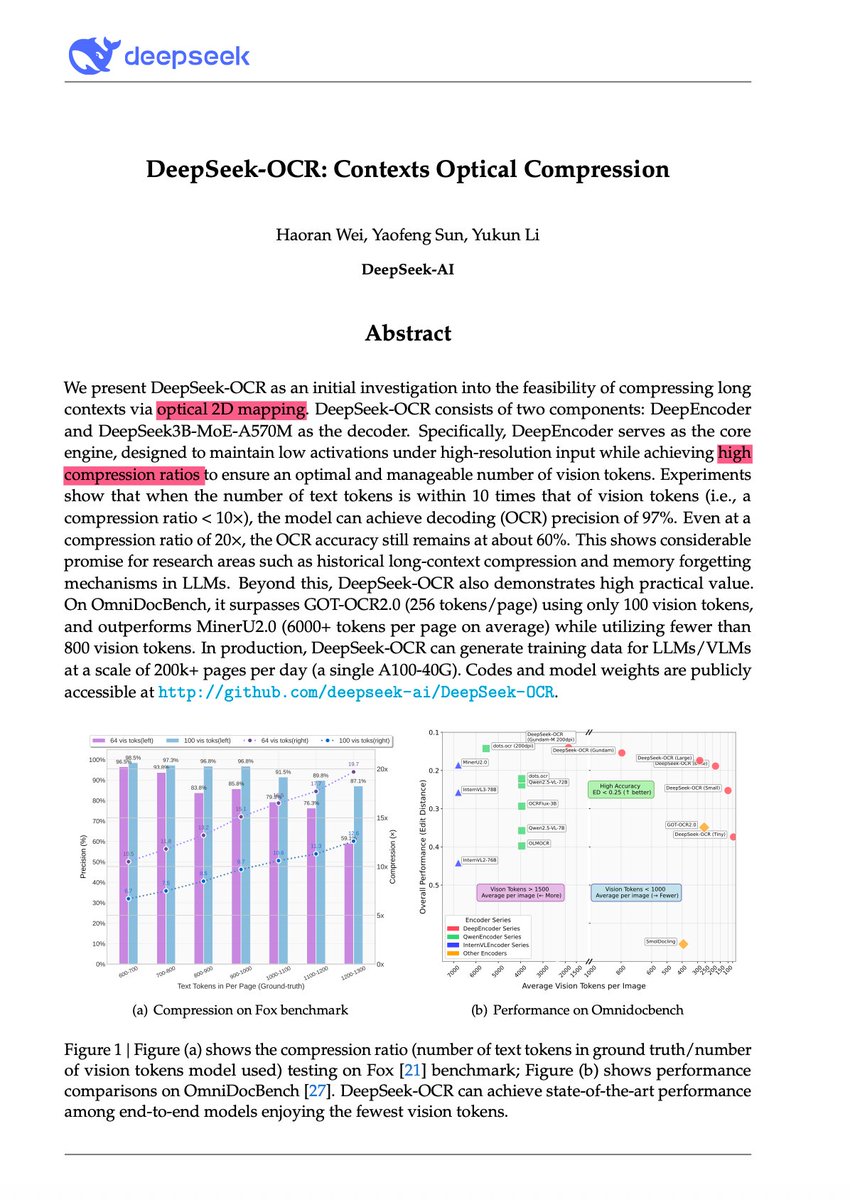
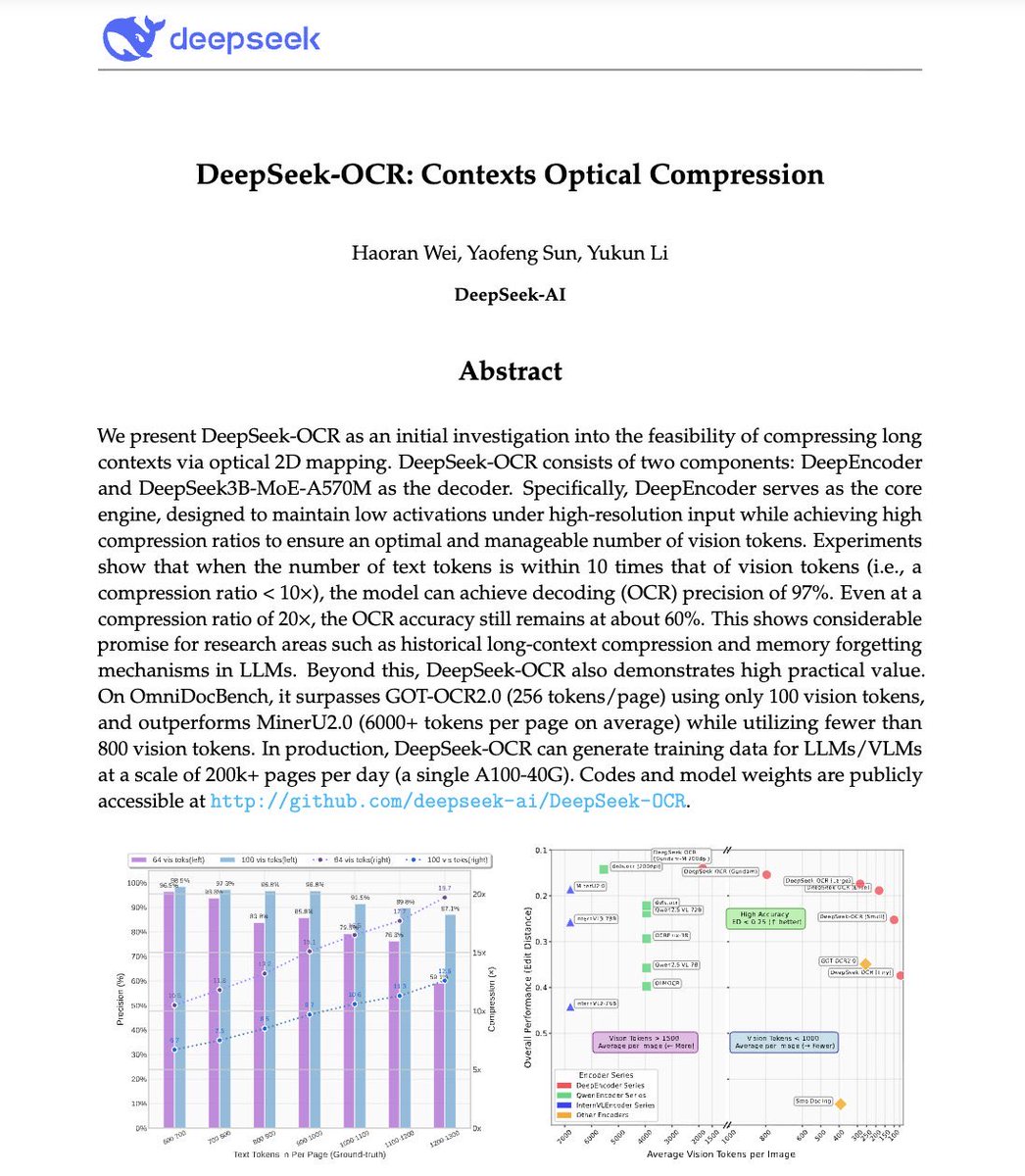
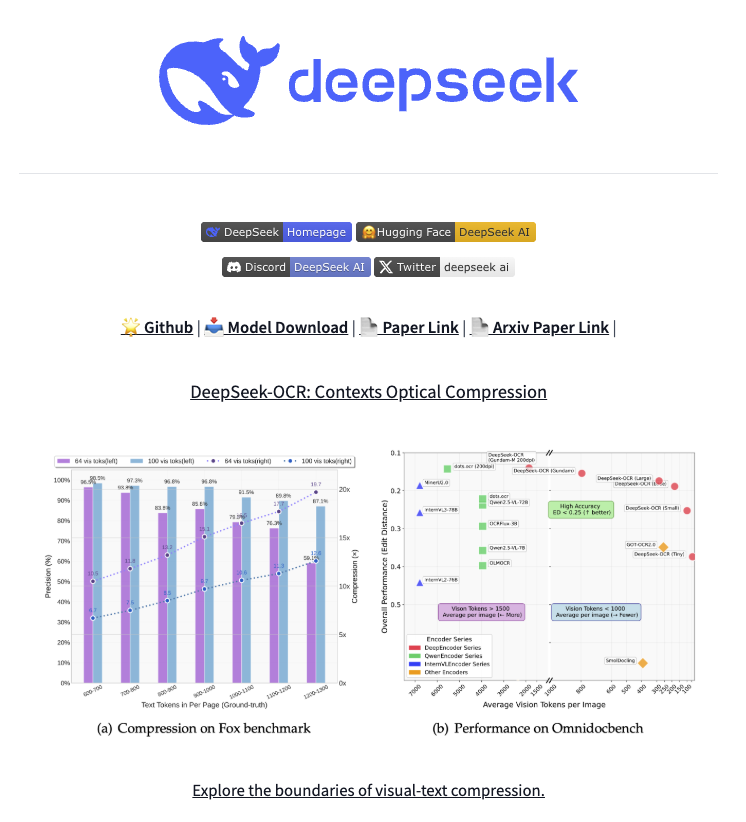
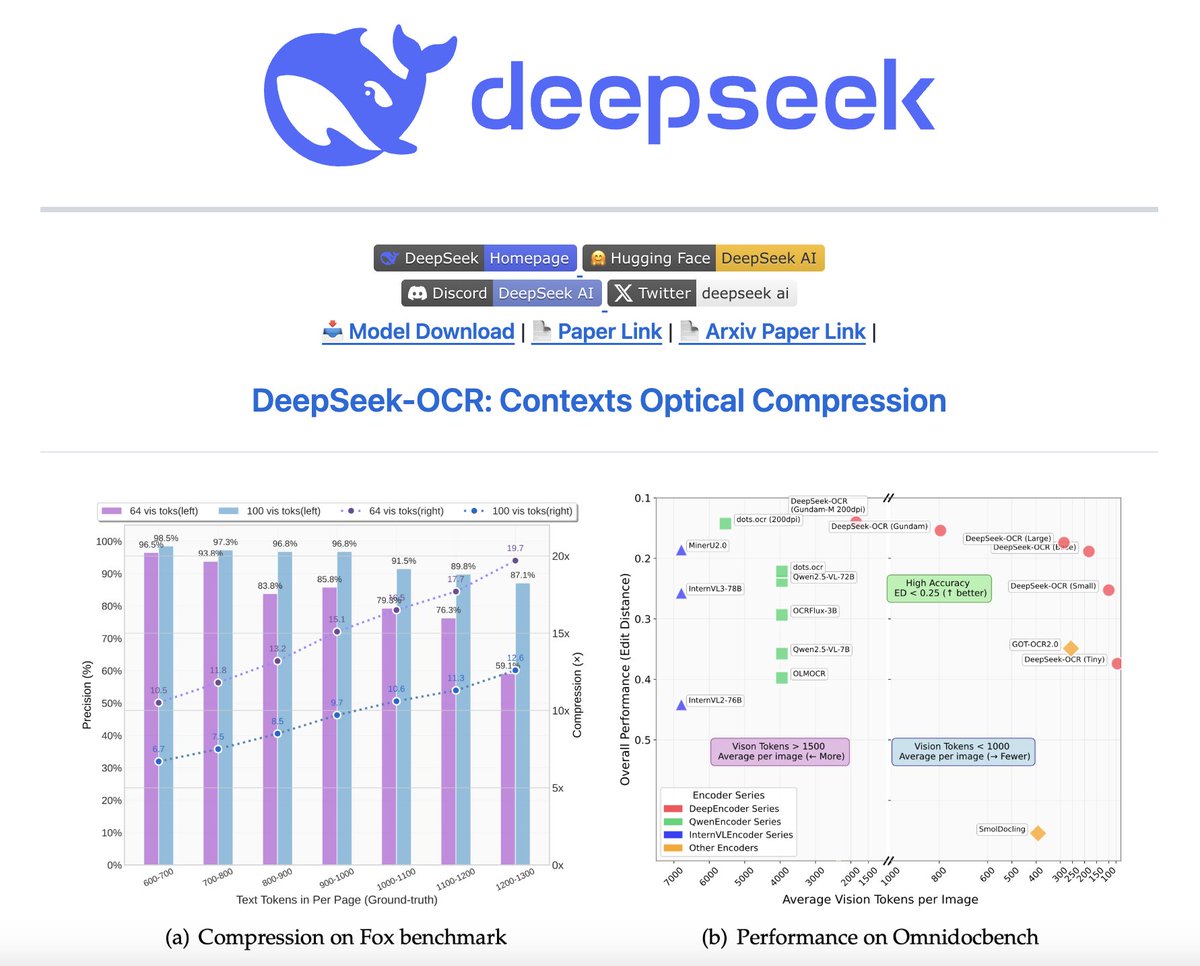
🚨 DeepSeek just did something wild. They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels. Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That…
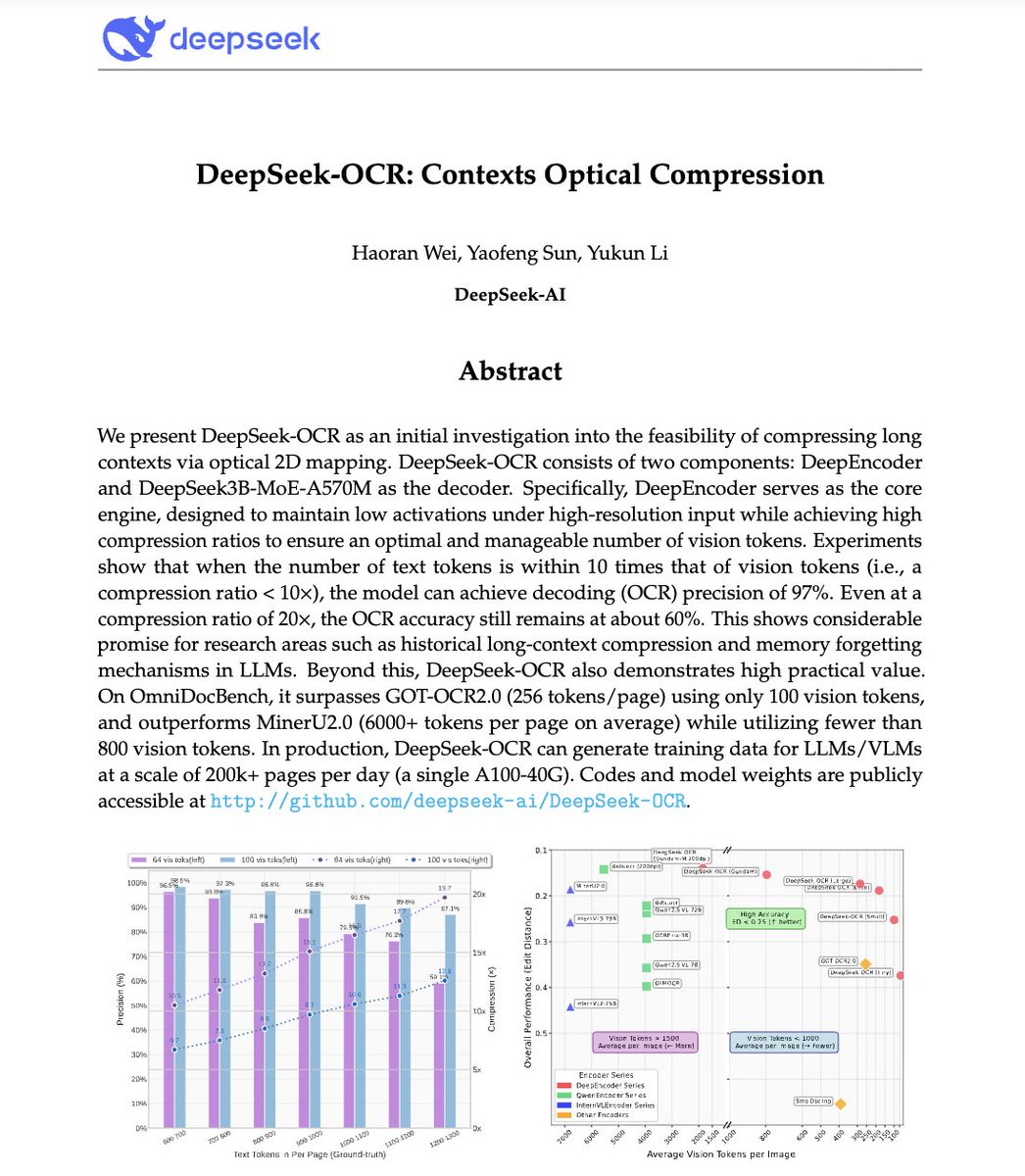

🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping…




IT FREAKING WORKED! At 4am today I just proved DeepSeek-OCR AI can scan an entire microfiche sheet and not just cells and retain 100% of the data in seconds… AND Have a full understanding of the text/complex drawings and their context. I just changed offline data curation!

BOOOOOOOM! CHINA DEEPSEEK DOES IT AGAIN! An entire encyclopedia compressed into a single, high-resolution image! — A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and…

DeepSeek finally released a new model and paper. And because this DeepSeek-OCR release is a bit different from what everyone expected, and DeepSeek releases are generally a big deal, I wanted to do a brief explainer of what it is all about. In short, they explore how vision…

BOOOOOOOM! CHINA DEEPSEEK DOES IT AGAIN! An entire encyclopedia compressed into a single, high-resolution image! — A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and…

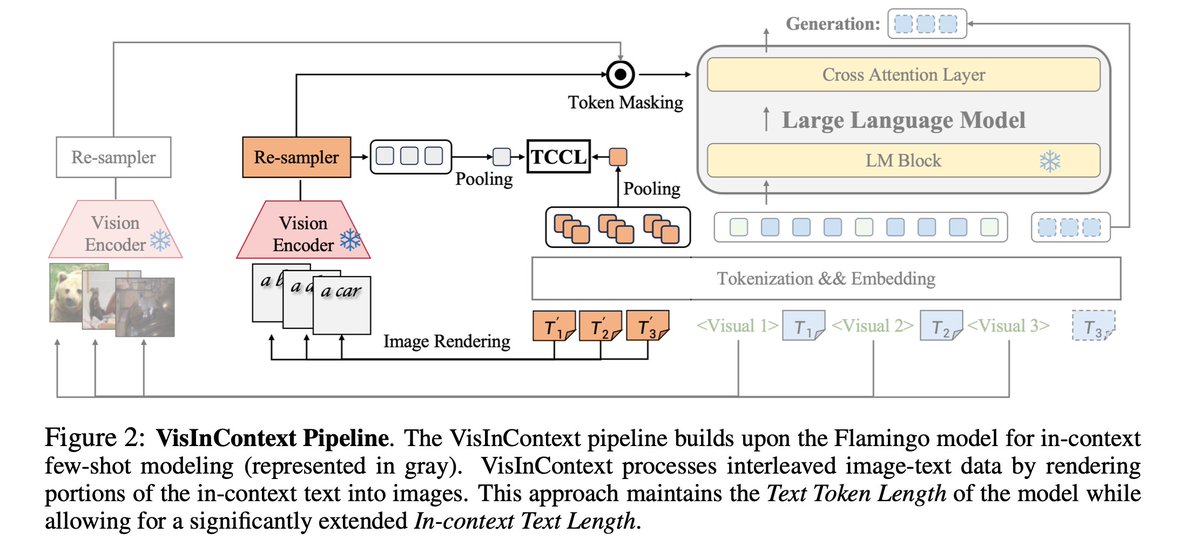
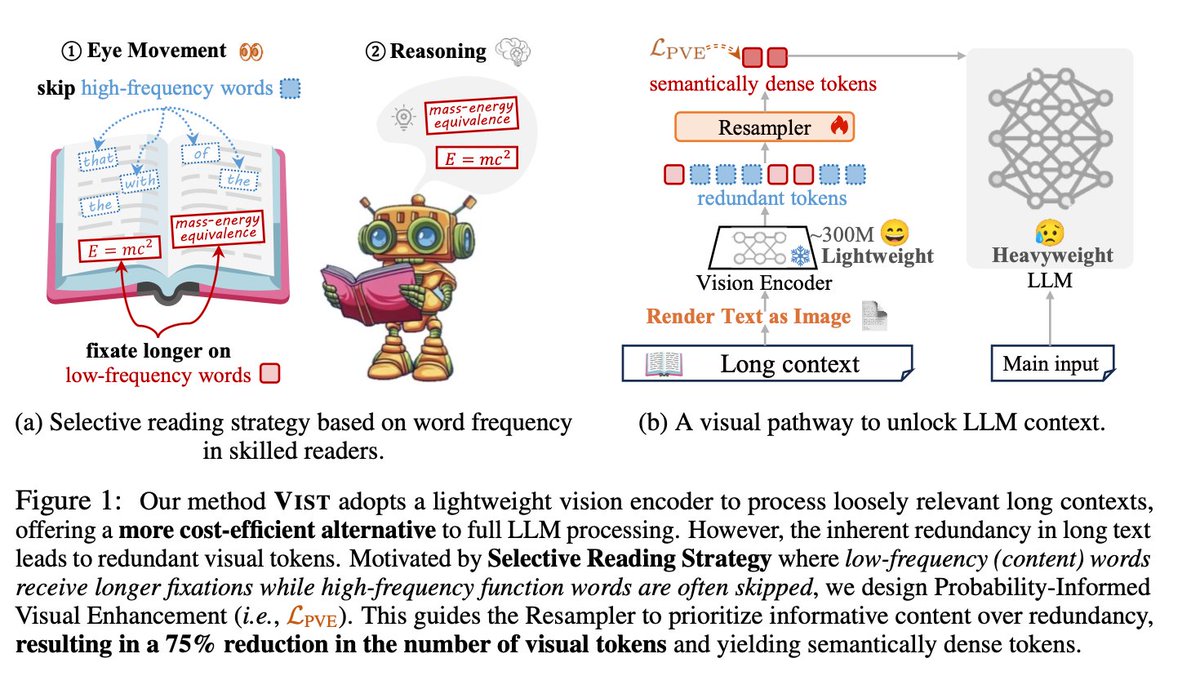
A more serious thread on the DeepSeek-OCR hype / serious misinterpretation going on. 1. On token reduction via representing text in images, researchers from Cambridge have previously shown that 500x prompt token compression is possible (ACL'25, Li, Su, and Collier). Without…


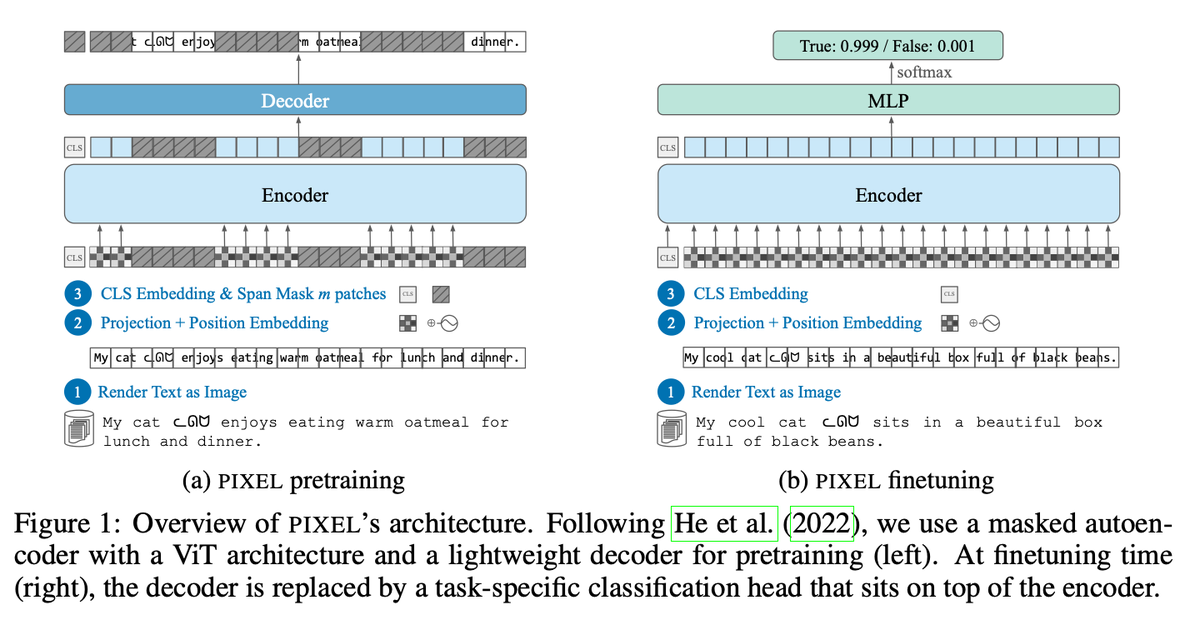
DeepSeek-OCR looks impressive, but its core idea is not new. Input “Text” as “Image” — already explored by: LANGUAGE MODELING WITH PIXELS (Phillip et al., ICLR 2023) CLIPPO: Image-and-Language Understanding from Pixels Only (Michael et al. CVPR 2023) Pix2Struct: Screenshot…



Unlike closed AI labs, DeepSeek proves they are truly open research Their OCR paper treats paragraphs as pixels and is 60x leap more efficient than traditional LLMs Small super efficient models are the future

This is the JPEG moment for AI. Optical compression doesn't just make context cheaper. It makes AI memory architectures viable. Training data bottlenecks? Solved. - 200k pages/day on ONE GPU - 33M pages/day on 20 nodes - Every multimodal model is data-constrained. Not anymore.…




High-resolution satellite images can be insanely expensive to buy. So here's a list of free datasets you can access. These datasets can be used to build foundation models, super-resolution models, or for segmentation.


vdeqs.de/e/tsl5jzj5job5 vdeqs.de/e/fcpfxcrbrx9h vdeqs.de/e/c6ccjcejy43w vdeqs.de/e/gr8xb8gxhtj8 vdeqs.de/e/p0fh9nw8hmmj vdeqs.de/e/nmau6ow8440w vdeqs.de/e/4ttpgk27bjl6 vdeqs.de/e/1h2pj3453pi2 hyjabhyper.jm


DeepSeek-OCR is out! 🔥 my take ⤵️ > pretty insane it can parse and re-render charts in HTML > it uses CLIP and SAM features concatenated, so better grounding > very efficient per vision tokens/performance ratio > covers 100 languages


DeepSeek just dropped a new OCR model! And this isn't about OCR. We've all heard "a picture is worth a thousand words." DeepSeek literally proved it. They've built a breakthrough in AI memory compression that could change how models handle long contexts. The core idea:…

cHiNa cAnNoT iNnOvAtE DeepSeek just revolutionized OCR - how computers read scanned documents. The traditional way is to read each word; and LLM’s create one token for each word. What DeepSeek does is to treat each word as an image. This introduces the concept of compression.…


DeepSeek released an OCR model today. Their motivation is really interesting: they want to use visual modality as an efficient compression medium for textual information, and use this to solve long-context challenges in LLMs. Of course, they are using it to get more training…
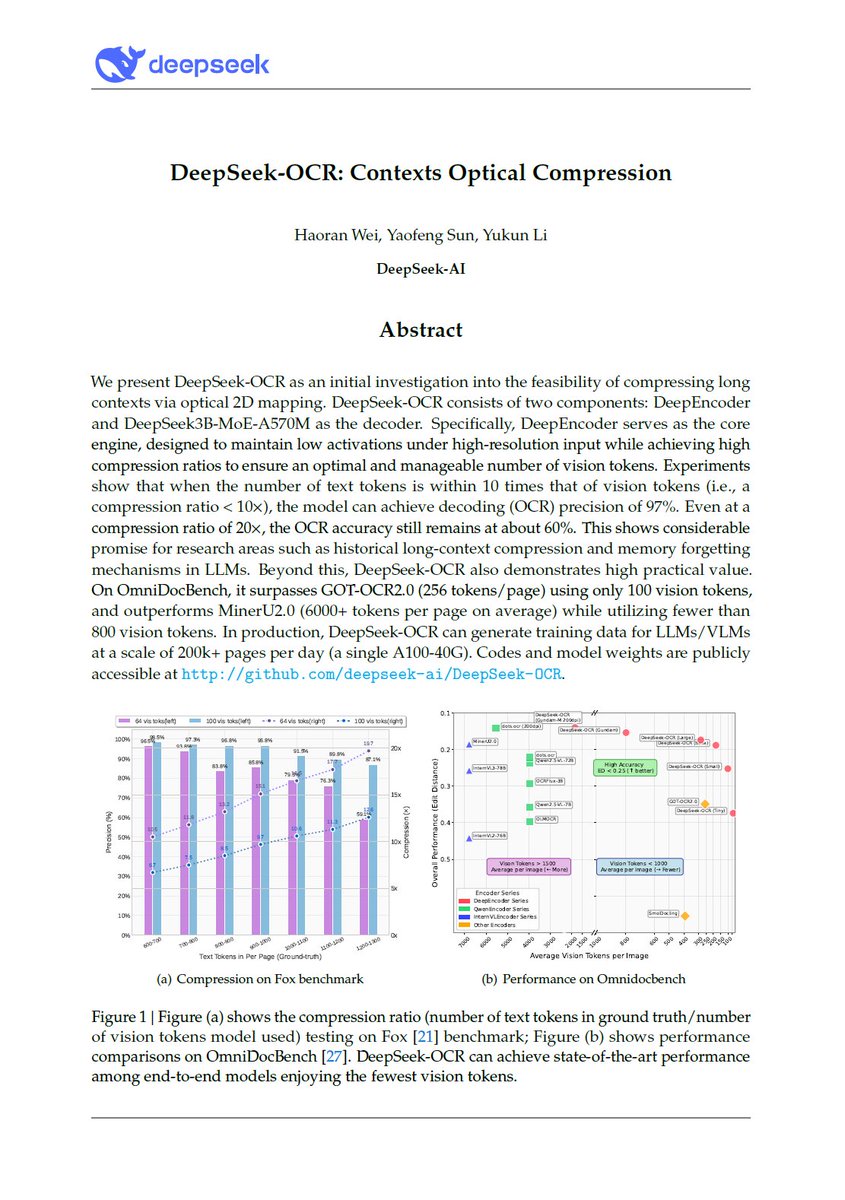

DeepSeek-OCR just dropped. 🔥 Sets a new standard for open-source OCR A 3B-parameter vision-language model designed for high-performance optical character recognition and structured document conversion. - Can parse and re-render charts in HTML - Optical Context Compression:…
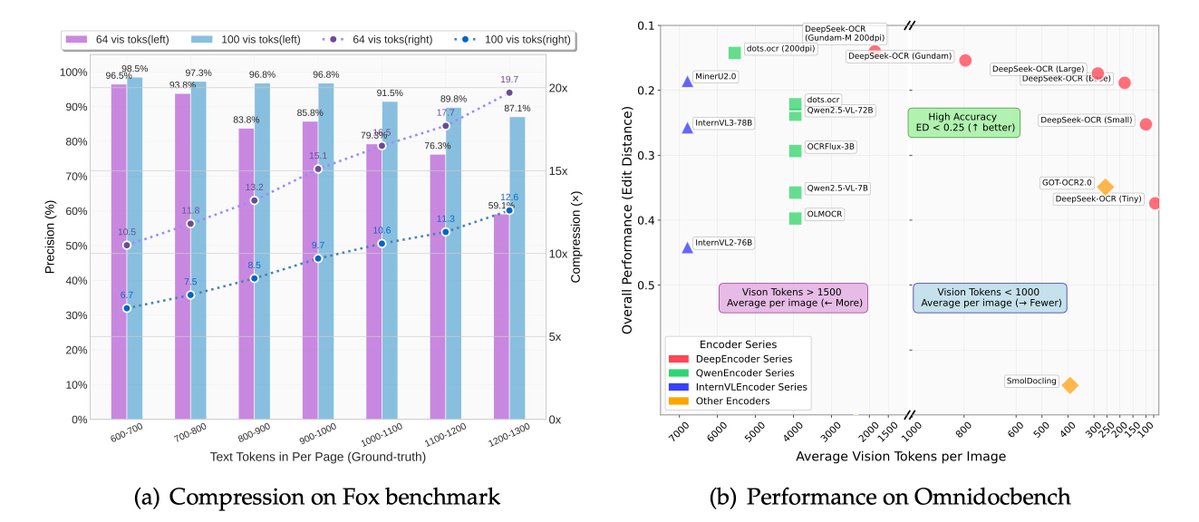

NEW DeepSeek OCR model that outperforms dots ocr while prefilling 3x less tokens
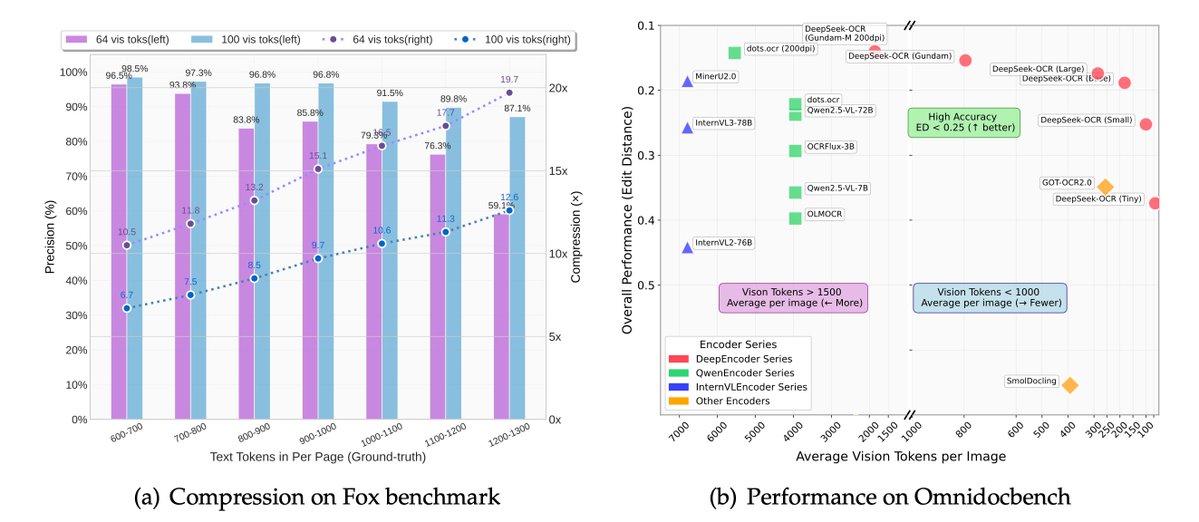
Something went wrong.
Something went wrong.
United States Trends
- 1. Jets 88.7K posts
- 2. Colts 46.6K posts
- 3. Sauce 72.1K posts
- 4. Garrett Wilson 3,082 posts
- 5. Cheney 196K posts
- 6. AD Mitchell 5,470 posts
- 7. Breece 6,669 posts
- 8. Shaheed 14.2K posts
- 9. Jerry 53.5K posts
- 10. Mazi Smith 3,242 posts
- 11. Merino 22.1K posts
- 12. Indy 16.3K posts
- 13. Jermaine Johnson 1,949 posts
- 14. #JetUp 1,242 posts
- 15. Aaron Glenn N/A
- 16. Ballard 3,737 posts
- 17. Election Day 162K posts
- 18. Mougey 1,303 posts
- 19. Minkah 4,238 posts
- 20. Micah 9,232 posts