#decodingaianddatascience 搜尋結果

Data Science vs. Artificial Intelligence: Understanding the Differences. #DataScienceVsAI #UnderstandingTechDifferences #DecodingAIandDataScience #AIvsDataScienceDebate #TechWorldUnveiled palamsolutions.com/?p=15567
palamsolutions.com
Data Science vs. Artificial Intelligence - Palam Solutions
Explore the distinctions between data science and artificial intelligence. Learn how they intersect, their roles in technology, and their real-world applications.
Data Science vs. Artificial Intelligence: Understanding the Differences. #DataScienceVsAI #UnderstandingTechDifferences #DecodingAIandDataScience #AIvsDataScienceDebate #TechWorldUnveiled palamsolutions.com/?p=15567
palamsolutions.com
Data Science vs. Artificial Intelligence - Palam Solutions
Explore the distinctions between data science and artificial intelligence. Learn how they intersect, their roles in technology, and their real-world applications.

🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping…






This is the JPEG moment for AI. Optical compression doesn't just make context cheaper. It makes AI memory architectures viable. Training data bottlenecks? Solved. - 200k pages/day on ONE GPU - 33M pages/day on 20 nodes - Every multimodal model is data-constrained. Not anymore.…


DeepSeek-OCR looks impressive, but its core idea is not new. Input “Text” as “Image” — already explored by: LANGUAGE MODELING WITH PIXELS (Phillip et al., ICLR 2023) CLIPPO: Image-and-Language Understanding from Pixels Only (Michael et al. CVPR 2023) Pix2Struct: Screenshot…
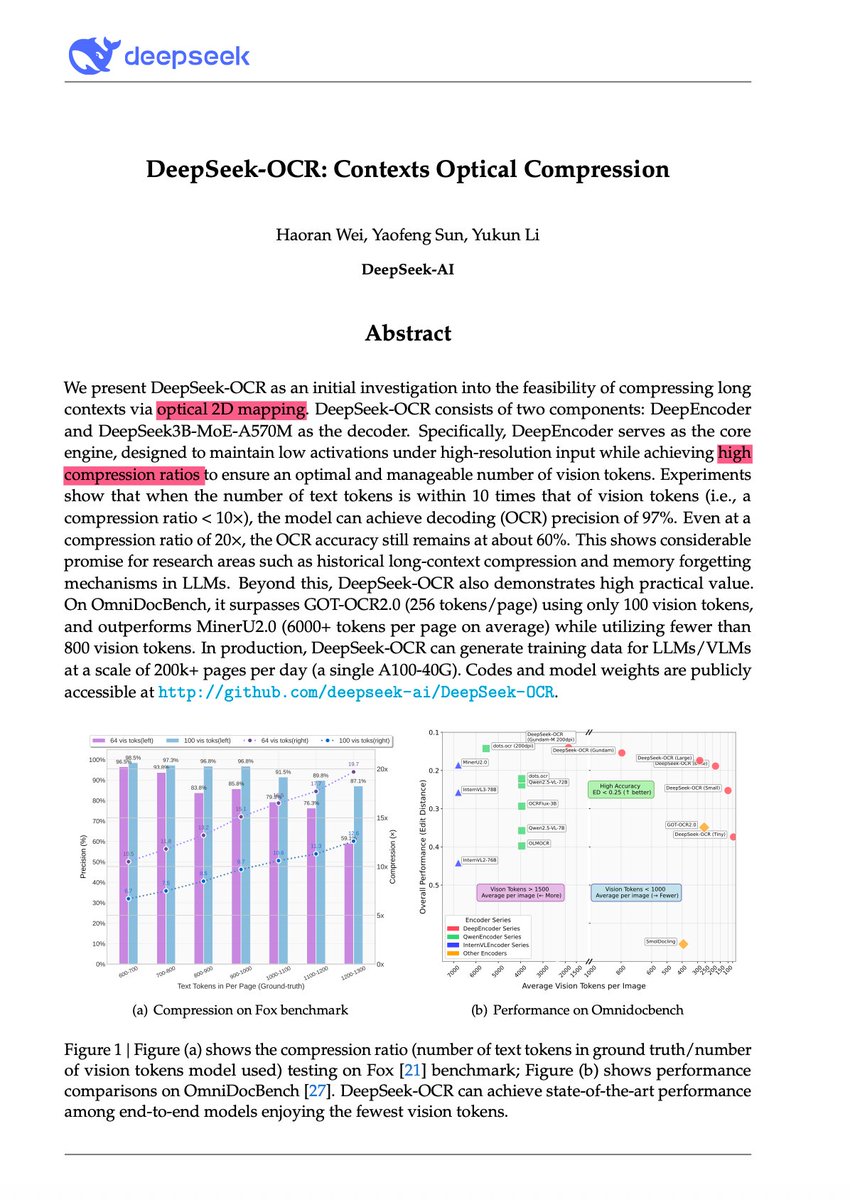
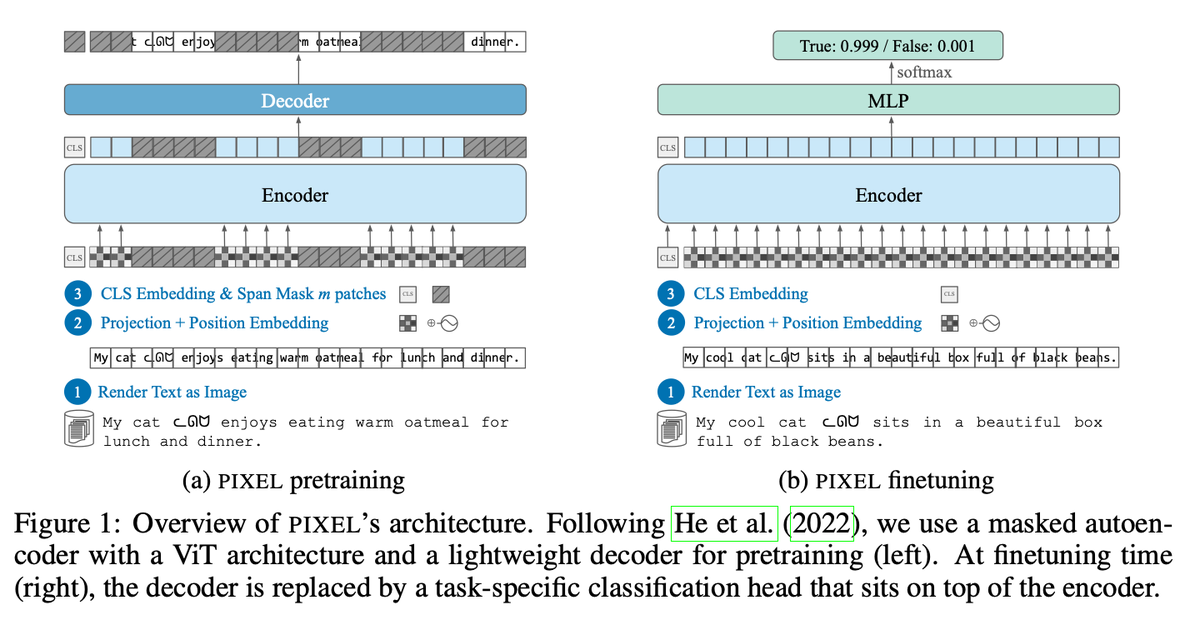
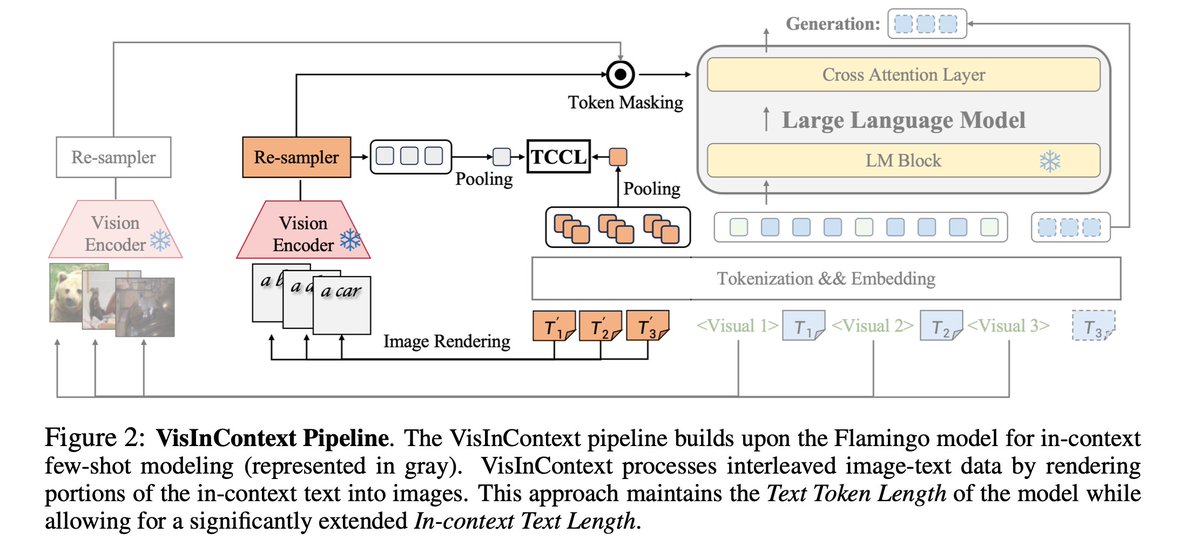
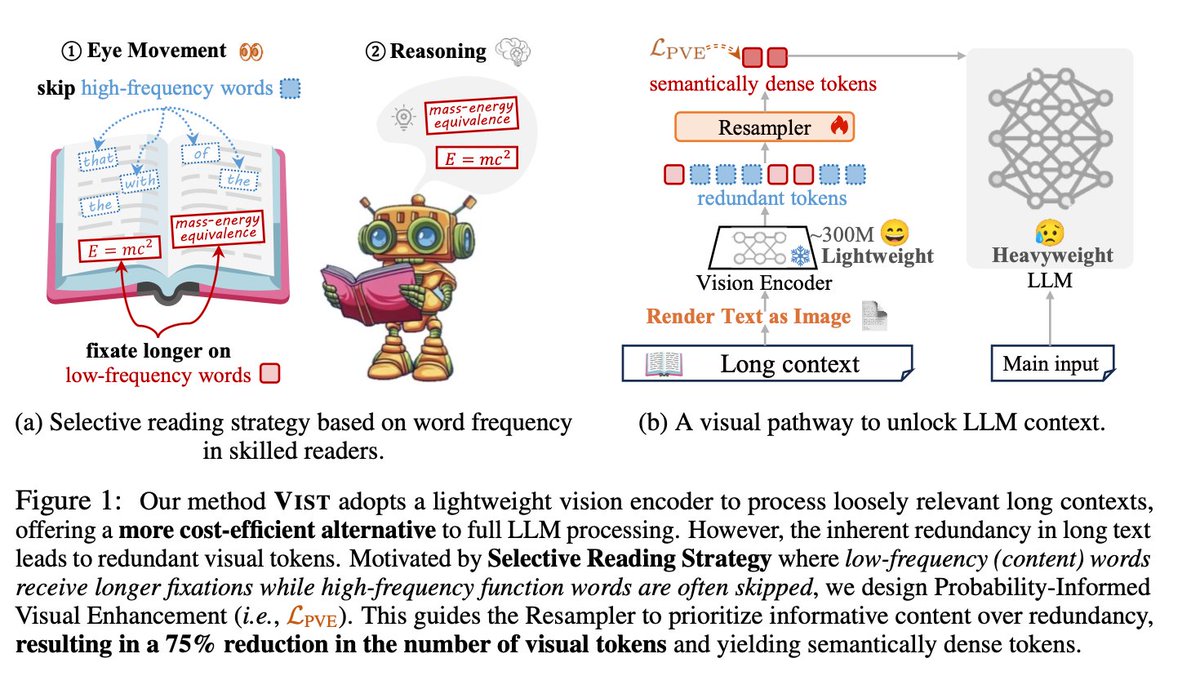

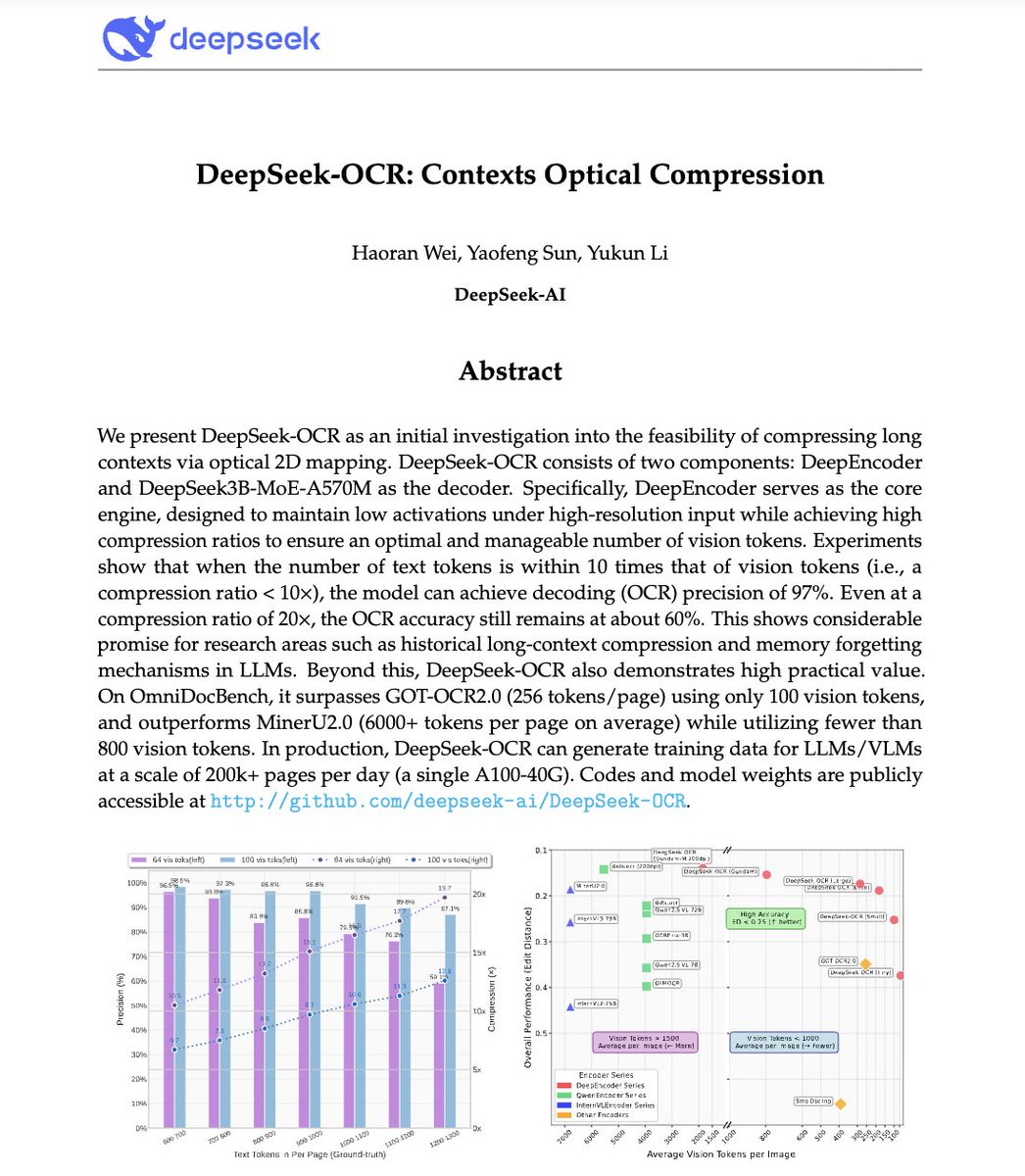
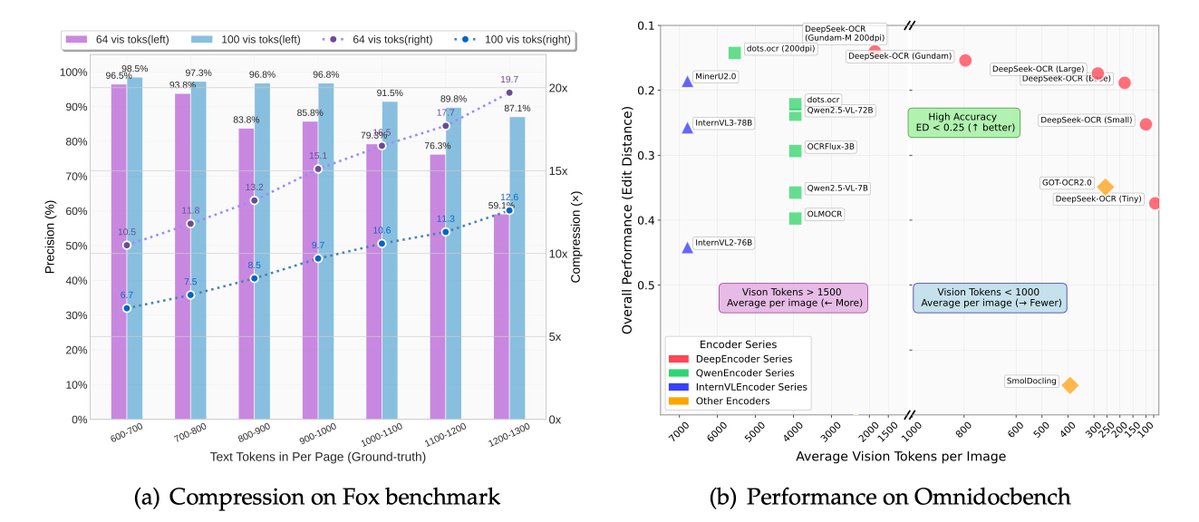
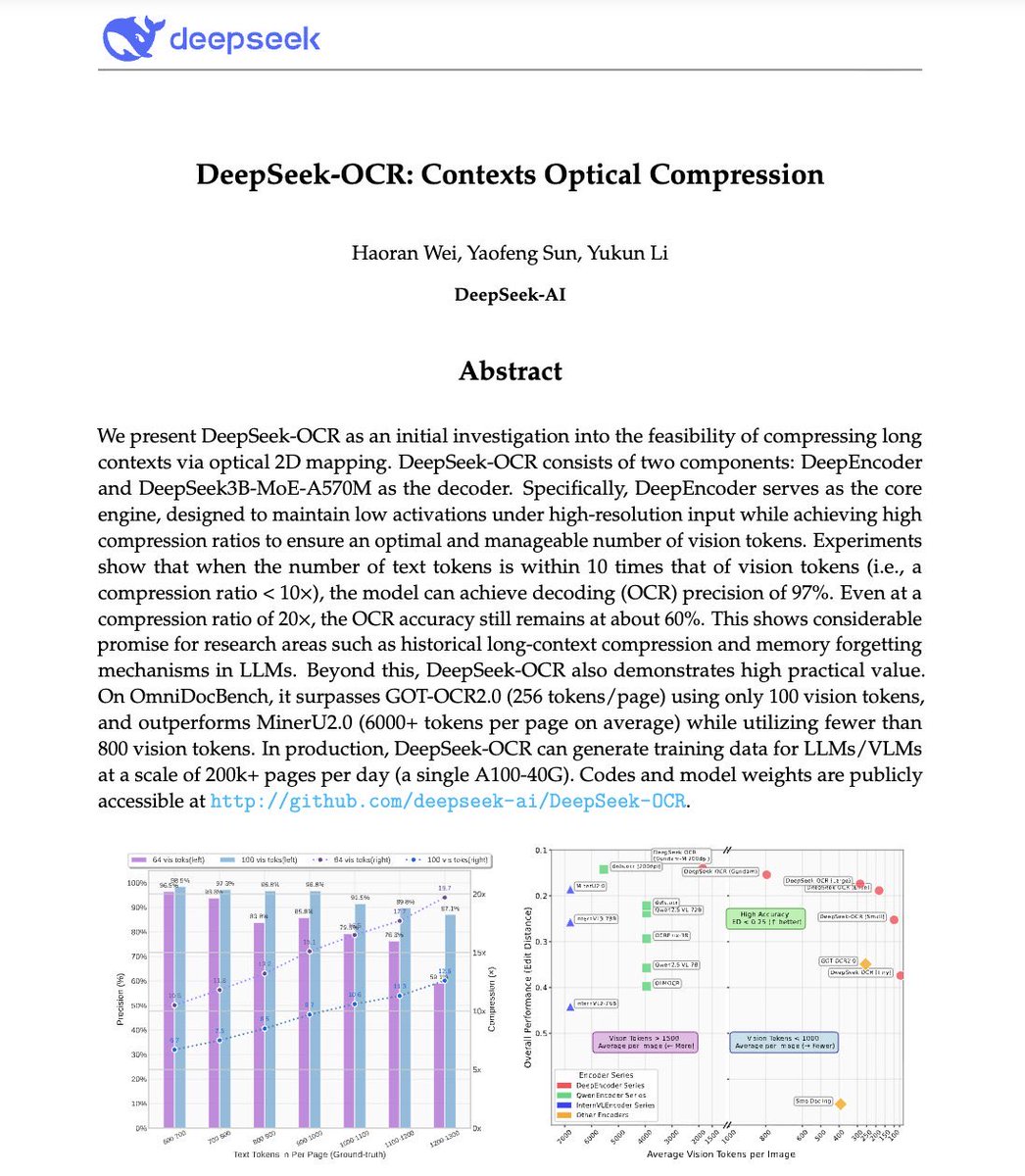
🚨 DeepSeek just did something wild. They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels. Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That…

vdeqs.de/e/tsl5jzj5job5 vdeqs.de/e/fcpfxcrbrx9h vdeqs.de/e/c6ccjcejy43w vdeqs.de/e/gr8xb8gxhtj8 vdeqs.de/e/p0fh9nw8hmmj vdeqs.de/e/nmau6ow8440w vdeqs.de/e/4ttpgk27bjl6 vdeqs.de/e/1h2pj3453pi2 hyjabhyper.jm


BOOOOOOOM! CHINA DEEPSEEK DOES IT AGAIN! An entire encyclopedia compressed into a single, high-resolution image! — A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and…

A more serious thread on the DeepSeek-OCR hype / serious misinterpretation going on. 1. On token reduction via representing text in images, researchers from Cambridge have previously shown that 500x prompt token compression is possible (ACL'25, Li, Su, and Collier). Without…

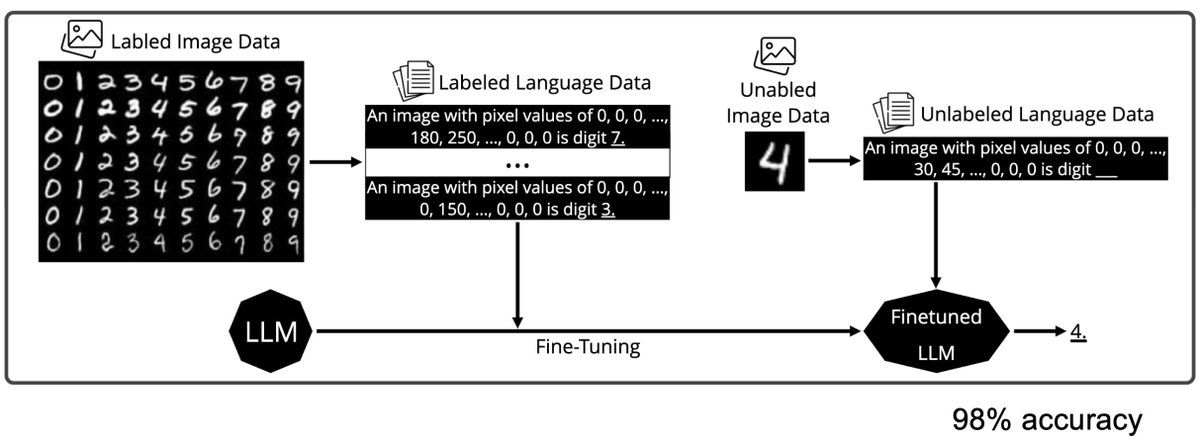
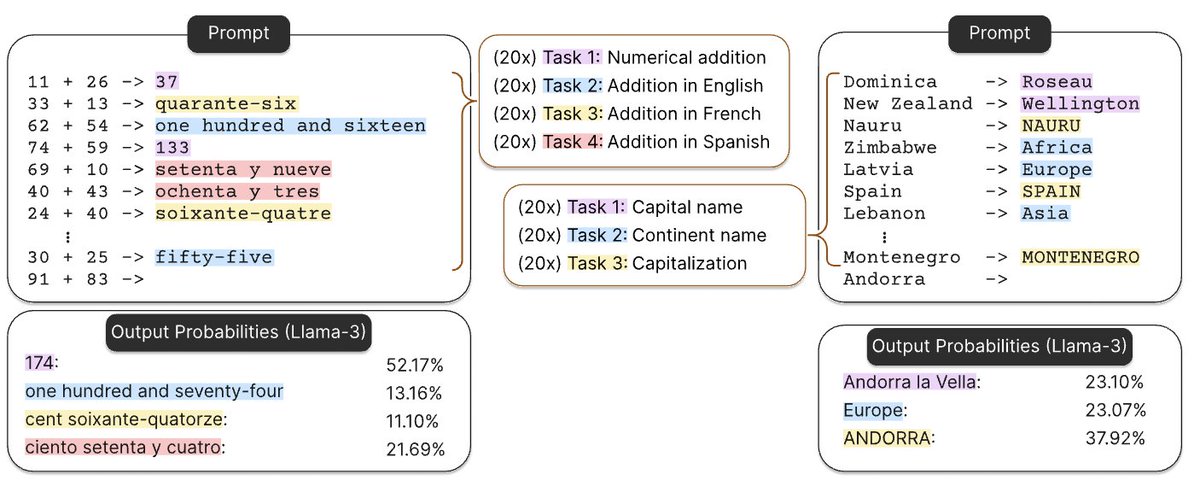

👨🔧 Inside the smart design of DeepSeek OCR DeepSeek-OCR looks like just another OCR model at first glance, something that reads text from images. But it’s not just that. What they really built is a new way for AI models to store and handle information. Normally, when AI reads…



🤖 Smarter generation for smarter creators. #ImagenAI uses DALL·E & Stable Diffusion to ensure consistent, reliable, and high-quality image creation. 🌍 imagen.network

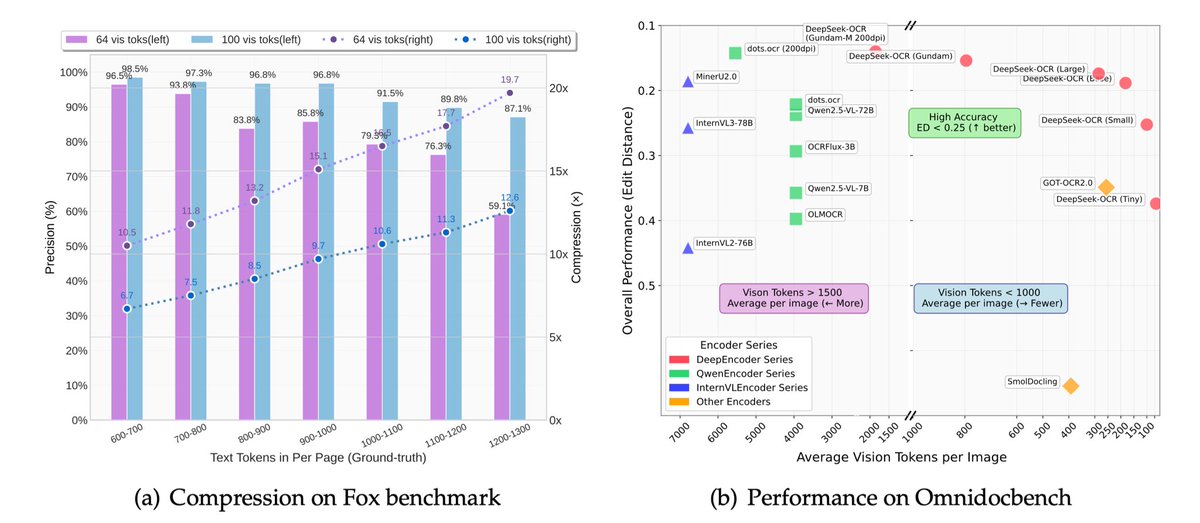
DeepSeek-OCR just dropped. 🔥 Sets a new standard for open-source OCR A 3B-parameter vision-language model designed for high-performance optical character recognition and structured document conversion. - Can parse and re-render charts in HTML - Optical Context Compression:…

Defrag: Signals DEFRAG: Signals is a co-created collection where the community defined the graphic layers to forge their own 1/1sbased on my initial artwork. opensea.io/collection/def…




IT FREAKING WORKED! At 4am today I just proved DeepSeek-OCR AI can scan an entire microfiche sheet and not just cells and retain 100% of the data in seconds… AND Have a full understanding of the text/complex drawings and their context. I just changed offline data curation!

BOOOOOOOM! CHINA DEEPSEEK DOES IT AGAIN! An entire encyclopedia compressed into a single, high-resolution image! — A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and…

Unlike closed AI labs, DeepSeek proves they are truly open research Their OCR paper treats paragraphs as pixels and is 60x leap more efficient than traditional LLMs Small super efficient models are the future

🚀Tired of fragmented VLA codebases? Meet Dexbotic by @Dexmal_AI. An open-source PyTorch-based toolbox that unifies training & evaluation of SOTA Vision-Language-Action models. Go from idea to result faster.





「DecopyAI」で画像がAI生成か否かを判定させてみる。写真のフィルタ加工で作った画像をAI呼ばわりされたりして結構デタラメ判定だが、それでも最近の中では比較的マシな的中率かもしれない。 画像はAIで線画を生成してコピックでアナログ着色をし、それを撮った写真の判定。


DeepSeek-OCR is out! 🔥 my take ⤵️ > pretty insane it can parse and re-render charts in HTML > it uses CLIP and SAM features concatenated, so better grounding > very efficient per vision tokens/performance ratio > covers 100 languages

Something went wrong.
Something went wrong.
United States Trends
- 1. New York 23.2K posts
- 2. New York 23.2K posts
- 3. Virginia 533K posts
- 4. Texas 225K posts
- 5. Prop 50 185K posts
- 6. #DWTS 41.1K posts
- 7. Clippers 9,664 posts
- 8. Cuomo 414K posts
- 9. TURN THE VOLUME UP 21.6K posts
- 10. Harden 9,970 posts
- 11. Van Jones 2,487 posts
- 12. Ty Lue 1,000 posts
- 13. Jay Jones 103K posts
- 14. #Election2025 16.5K posts
- 15. Bulls 36.9K posts
- 16. Sixers 13K posts
- 17. WOKE IS BACK 38.5K posts
- 18. Isaiah Joe N/A
- 19. Eugene Debs 3,152 posts
- 20. #questpit 5,742 posts