#deltatable 検索結果



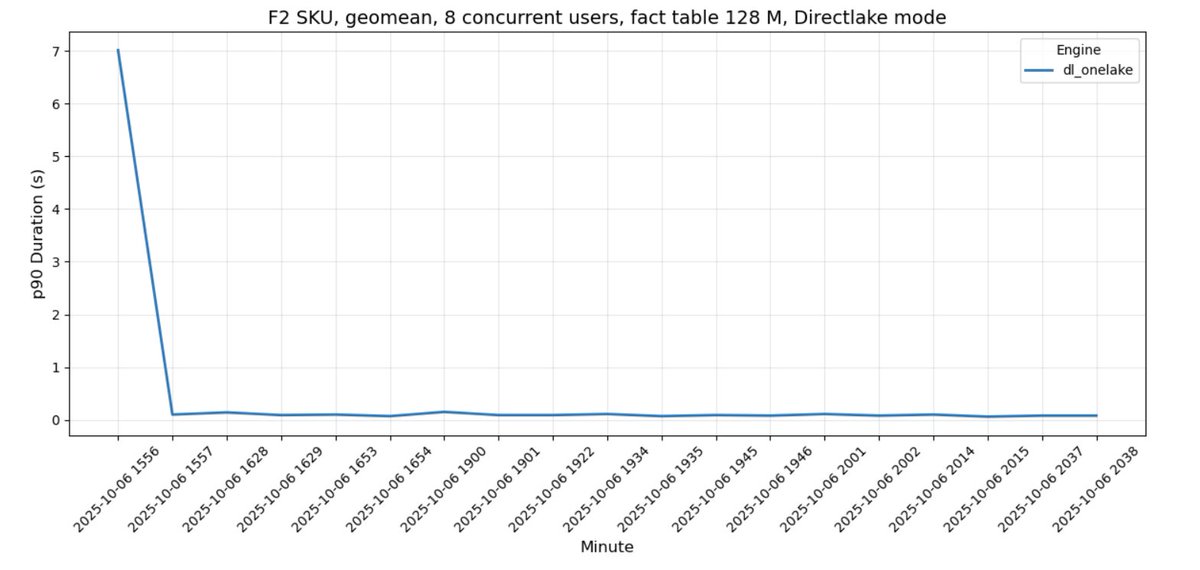
The fastest way to serve #DeltaTable and #ApacheIceberg ? #PowerBI Direct Lake mode from #onelake , no debate there. What’s wild is it stays blazing fast even on the lowest #MicrosoftFabric tier (F2). 🚀 github.com/djouallah/fabr…
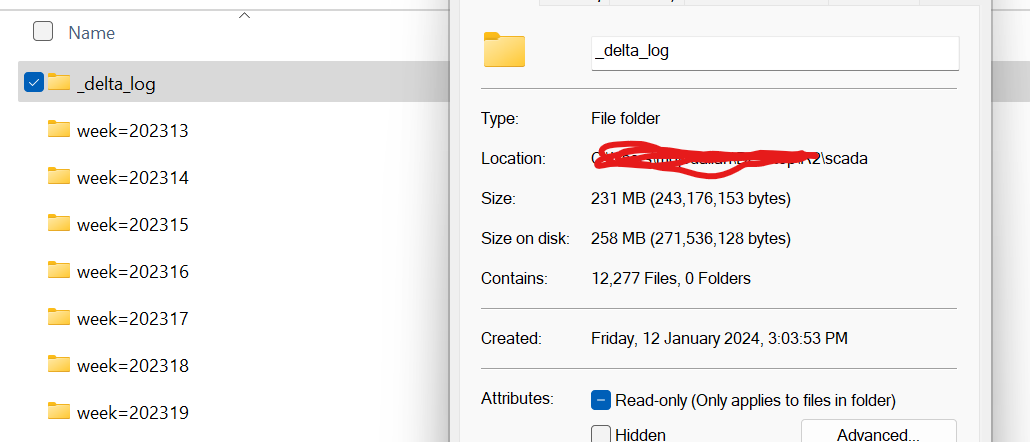
when you ingest a lot of small files into #DeltaTable make sure you alter the delta.logRetentionDuration to a more sensible duration otherwise you end up with a Log bigger than the Data itself :) to be clear only myself to blame here :)
#duckdb is adding checkpoint to their ducklake format, multiple table transactions as pip install , we live in an amazing time !!! then you can expose the data as a #deltatable self promotion 😅 pypi.org/project/duckla…

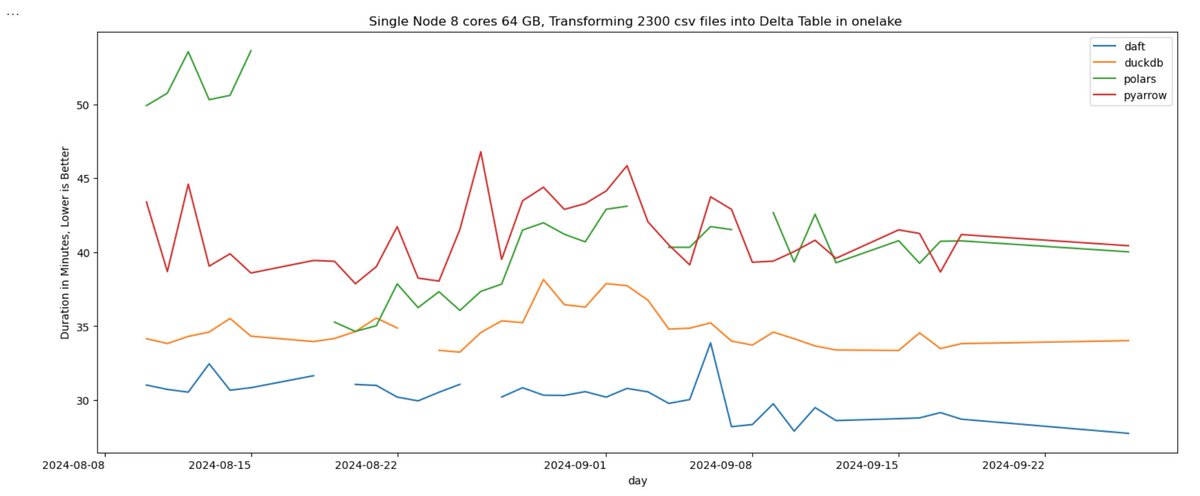
if you are serious about #deltatable, you need your own #parquet writer, with the support of partition, @daft_dataframe is the new winner of my "ETL Benchmarks" based on my own data @duckdb step up your game 😋😅😋
#duckdb ODBC driver now support #deltatable in Direct Query mode, this table is hosted in Cloudflare R2 !!
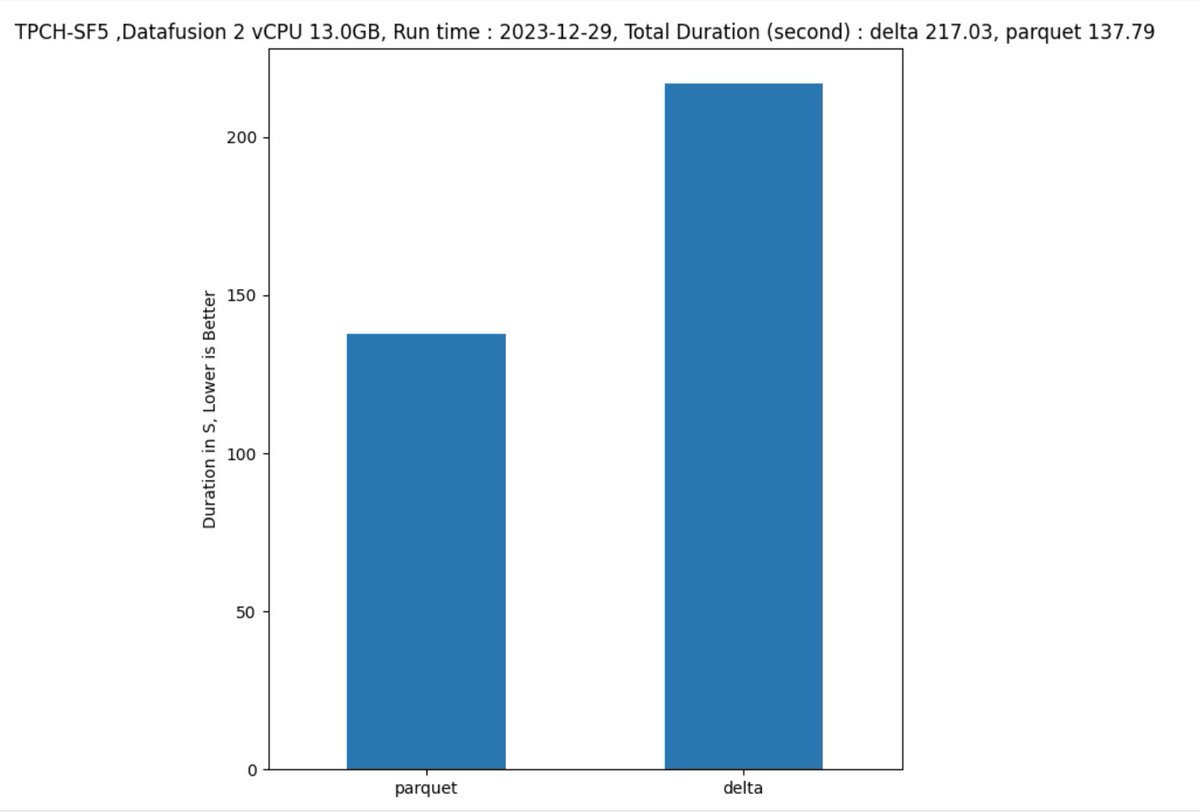
a new release of #datafusion 34, still reading #Deltatable via arrow is suboptimal compared to reading Parquet Directly :( something to do with passing stats to get correct join orders. colab.research.google.com/drive/1sJD7w6l…

How to perform change data capture (CDC) from full table snapshots using Delta Live Tables #DeltaTable #DataBricks #Azure #DataScientists #DataScience #CDC #snapshot databricks.com/blog/how-perfo…
databricks.com
Process streaming in DLT Framework | Databricks Blog
Learn more about processing snapshots using Delta Live Tables and how you can use the new Apply changes from Snapshshot statement in DLT to build SCD Type 1 or SCD Type 2 target tables delivering...

🎉 Exciting updates in @UnstructuredIO v0.10.5! 🎉 ✨ Features: introducing Delta Tables connector✨ Enhancements: added TIFF support & improved OCR mode for PDFs & images. Discover more: github.com/Unstructured-I… #DataAnalytics #DataScience #DeltaTable

How to Read a #DeltaTable with Deletion Vectors and Column Mapping in #Python datamonkeysite.com/2025/03/19/how… #Microsoftfabric #onelake #duckdb #deltatlake

The new `get_add_actions` API for delta-rs uniquely supports inspecting partition values, record counts, and stats of files in your #deltatable. Very useful for deep dives into the affects of re-partitioning or Z-Ordering. A lot of cool tools can be built on top of this feature!

V-Order has an 15% impact on average write times but provides up to 50% more compression #spark #deltatable
using #deltatable Python packages to detect changes downstream, and process data either incrementally or full refresh #Python #MicrosoftFabric #onelake datamonkeysite.com/2024/11/10/sma…
datamonkeysite.com
Smart Data Pipeline Design: Check for Delta Table Changes with Minimal Overhead
Scenario I have a notebook that processes hot data every 5 minutes. Meanwhile, another pipeline processes historical data, and I want to create a summary table that uses the hot data incrementally …

I just published a medium story: Delta Properties and Check Constraints at Scale link.medium.com/TMmmoABl7zb #pyspark #deltatable #dataengineering

apparently this is a legit #deltatable , basically no log replay, just snapshots , spark don't like it, but #PowerBI direct lake read it just fine (the only reader i care about), just export snapshot from #ducklake and you have a proper metadata sync out of thin air !!!

New Post. …stindatacaughtinthetrace.blogspot.com/2023/12/Compar… Comparing the capability of #Deltatable Change Data Feed to #SQLServer Change Data Capture.
#DeltaTable in #AzureSynapse is much improved by the Apache Spark 3.3 updates. Having previously used Fetch XML for a custom app import this is much simpler.

When you choose a #deltatable format a more than 200 MB CSV File will get compressed within 50 MB. Good space saving Instead. #datalakehouse #benifits
The fastest way to serve #DeltaTable and #ApacheIceberg ? #PowerBI Direct Lake mode from #onelake , no debate there. What’s wild is it stays blazing fast even on the lowest #MicrosoftFabric tier (F2). 🚀 github.com/djouallah/fabr…
#duckdb is adding checkpoint to their ducklake format, multiple table transactions as pip install , we live in an amazing time !!! then you can expose the data as a #deltatable self promotion 😅 pypi.org/project/duckla…
#PowerBI will analyze your #deltatable and load only the delta , pun intended :) basically getting the same results using less work , it is like CDC to RAM 😁
first time, I built a python package, it does export #ducklake metadata to #deltatable, test it with #PowerBI and it works, hopefully we get a better solution from #duckdb :) pypi.org/project/duckla…
🚀 #DuckDB is adding support for #ApacheIceberg V3 deletion vectors , which are compatible with #DeltaTable DV! This is a huge step forward. There’s now a real possibility that both ecosystems will converge on a common data format. github.com/duckdb/duckdb-…
apparently this is a legit #deltatable , basically no log replay, just snapshots , spark don't like it, but #PowerBI direct lake read it just fine (the only reader i care about), just export snapshot from #ducklake and you have a proper metadata sync out of thin air !!!
🚀 #DeltaTable v4 has landed , and it marks a big shift! Catalog-managed tables (in preview) are now first-class citizens. the days of using storage to handle transactions are over, Time to mourn… and move on. #ApacheSpark #Lakehouse 👉 github.com/delta-io/delta…
github.com
Release Delta Lake 4.0.0 · delta-io/delta
We are excited to announce the final release of Delta Lake 4.0.0! This release includes several exciting new features. Highlights [Spark] Preview support for catalog-managed tables, a new table fe...
#duckdb ODBC driver now support #deltatable in Direct Query mode, this table is hosted in Cloudflare R2 !!
that's interesting !! a new flag in #deltatable that insure that the data written is compatible with #apacheiceberg , it does not add any metadata but just guarantee that you can do it if you need to. github.com/delta-io/delta…
github.com
[PROTOCOL RFC] IcebergWriterCompatV1 · Issue #4284 · delta-io/delta
Protocol Change Request Description of the protocol change This protocol change introduces a new compatibility flag, which ensures that a delta table can be safely read and written as an Apache Ice...
How to Read a #DeltaTable with Deletion Vectors and Column Mapping in #Python datamonkeysite.com/2025/03/19/how… #Microsoftfabric #onelake #duckdb #deltatlake
This is very big deal, experimental write support for #Deltatable using delta RS kernel, the users here are Query Engines not end users github.com/delta-io/delta…
github.com
Release v0.5.0 · delta-io/delta-kernel-rs
release 0.5.0
Poor's man #deltatable disk cache for #duckdb with #onelake linkedin.com/posts/mimouned…
linkedin.com
#duckdb #microsoftfabric #duckdb #polars #duckdb #dataengineering #onelake #fabricnotebook #perfo...
🚀 Boosting #DuckDB Performance in #MicrosoftFabric Notebooks! This weekend, I built a simple ad hoc disk cache for DuckDB in Fabric Notebooks—and it works brilliantly! 🎉 ✅ Parse queries to find...

@mim_djo, detecting changes downstream with #deltatable sounds like a solid way to keep things fresh. Incremental updates really save time—efficient workflows, indeed
using #deltatable Python packages to detect changes downstream, and process data either incrementally or full refresh #Python #MicrosoftFabric #onelake datamonkeysite.com/2024/11/10/sma…
datamonkeysite.com
Smart Data Pipeline Design: Check for Delta Table Changes with Minimal Overhead
Scenario I have a notebook that processes hot data every 5 minutes. Meanwhile, another pipeline processes historical data, and I want to create a summary table that uses the hot data incrementally …
if you are serious about #deltatable, you need your own #parquet writer, with the support of partition, @daft_dataframe is the new winner of my "ETL Benchmarks" based on my own data @duckdb step up your game 😋😅😋
How to perform change data capture (CDC) from full table snapshots using Delta Live Tables #DeltaTable #DataBricks #Azure #DataScientists #DataScience #CDC #snapshot databricks.com/blog/how-perfo…
databricks.com
Process streaming in DLT Framework | Databricks Blog
Learn more about processing snapshots using Delta Live Tables and how you can use the new Apply changes from Snapshshot statement in DLT to build SCD Type 1 or SCD Type 2 target tables delivering...

Parquet and JSON have transitioned from gold standards in the big data era to feeder formats in the generative AI era. #deltatable #MosaicAI #Databricks : #178 The Evolution of Data Lake Formats: Delta Table and JSONL linkedin.com/pulse/178-evol… via @LinkedIn
linkedin.com
#178 The Evolution of Data Lake Formats: Delta Table and JSONL
Discover how Delta Tables and JSONL are revolutionizing data storage and processing in AI, building upon the foundations of Parquet and JSON to enhance efficien
so google colab just upgraded #duckdb to 10.3 which means you can read #deltatable out of the box !!! meanwhile apache #iceberg still needs a FU@%^&* catalog just to read a table, give us version-hint.txt and stop this madness github.com/apache/iceberg…
github.com
[feat] Ability to read table using `version-hint.txt` · Issue #763 · apache/iceberg-python
Feature Request / Improvement Although not in the official spec, version-hint.txt can be useful to read an iceberg table without a catalog. This is useful when considering an iceberg table as a col...
V-Order has an 15% impact on average write times but provides up to 50% more compression #spark #deltatable
the magic of #Deltatable relative Paths, I moved around my folder and everything keep working just fine
Finally !!! it works, writing data to #Fabric Onelake using #deltatable Rust cc @JoshCaplan1984 ♥️🪅🎉🥳

#duckdb is adding checkpoint to their ducklake format, multiple table transactions as pip install , we live in an amazing time !!! then you can expose the data as a #deltatable self promotion 😅 pypi.org/project/duckla…
The fastest way to serve #DeltaTable and #ApacheIceberg ? #PowerBI Direct Lake mode from #onelake , no debate there. What’s wild is it stays blazing fast even on the lowest #MicrosoftFabric tier (F2). 🚀 github.com/djouallah/fabr…
#duckdb ODBC driver now support #deltatable in Direct Query mode, this table is hosted in Cloudflare R2 !!
a new release of #datafusion 34, still reading #Deltatable via arrow is suboptimal compared to reading Parquet Directly :( something to do with passing stats to get correct join orders. colab.research.google.com/drive/1sJD7w6l…
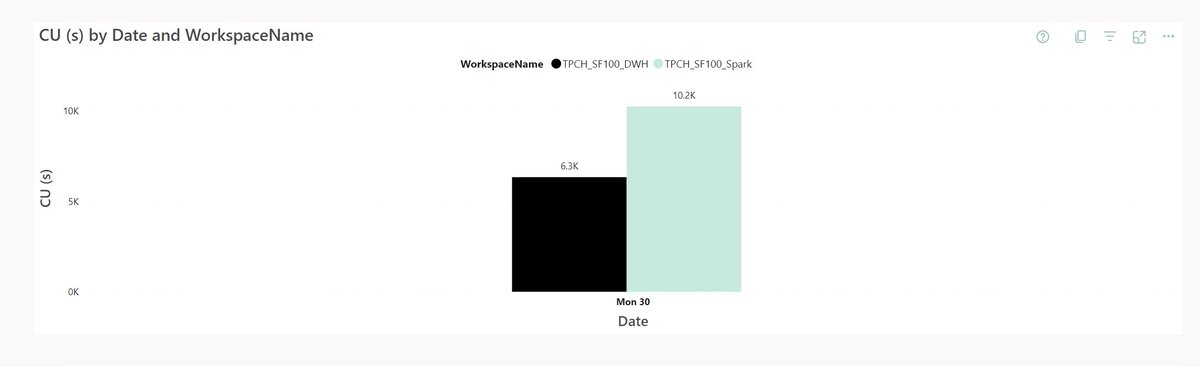
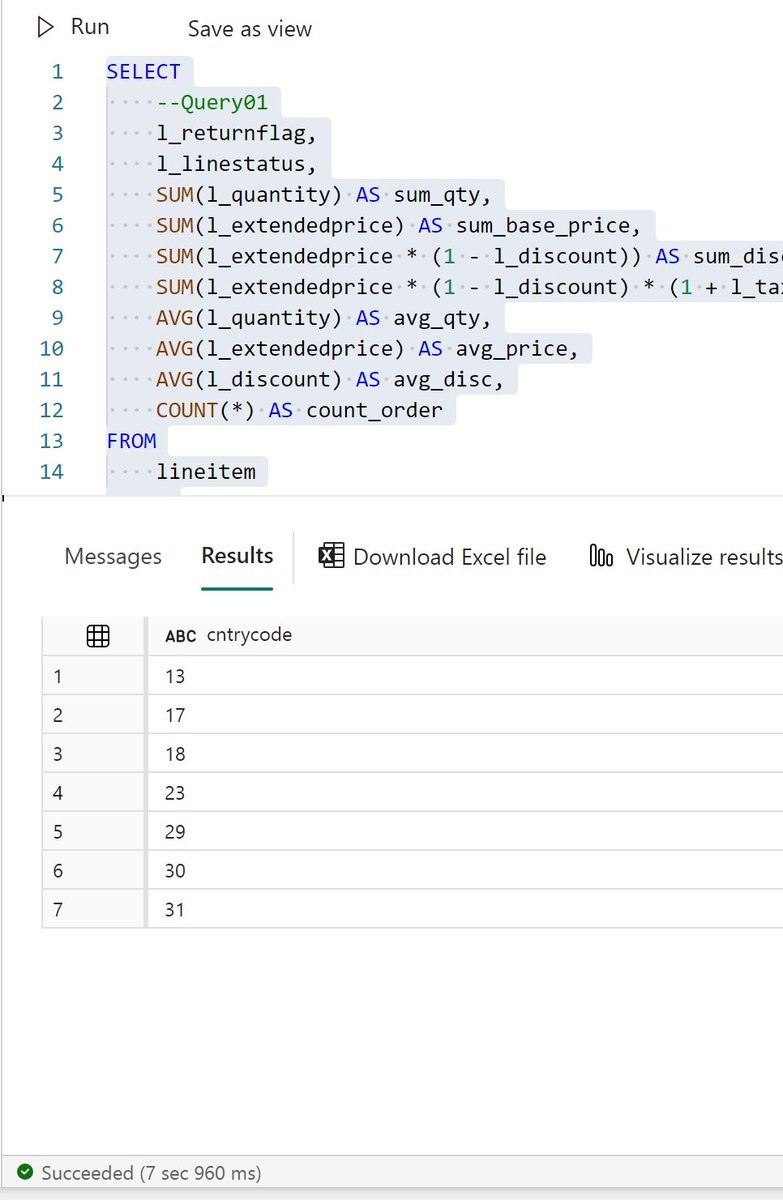
#Fabric DWH is still very fast with Delta Table generated by third party tools, in this example hot run, TPCH_SF10 #Deltatable Rust, 7 second
How to Read a #DeltaTable with Deletion Vectors and Column Mapping in #Python datamonkeysite.com/2025/03/19/how… #Microsoftfabric #onelake #duckdb #deltatlake
if you are serious about #deltatable, you need your own #parquet writer, with the support of partition, @daft_dataframe is the new winner of my "ETL Benchmarks" based on my own data @duckdb step up your game 😋😅😋
I am unreasonably excited about #Glaredb storage decision #deltatable, I would had the same reaction if it was iceberg too or hudi or any freaking standard. life is too short to build your own storage format.

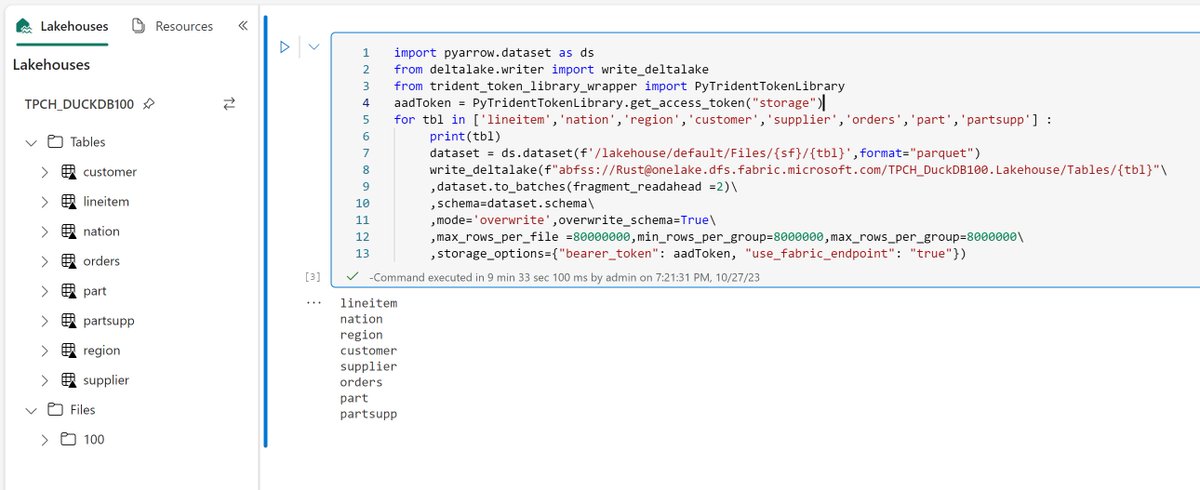
Loaded TPCH_SF100 to #Fabric Lakehouse using pyarrow and #Deltatable Rust, rowgroup=8M and max file 80M for no particular reason 🤪😅 performance is slightly better than the data loaded using Spark :)
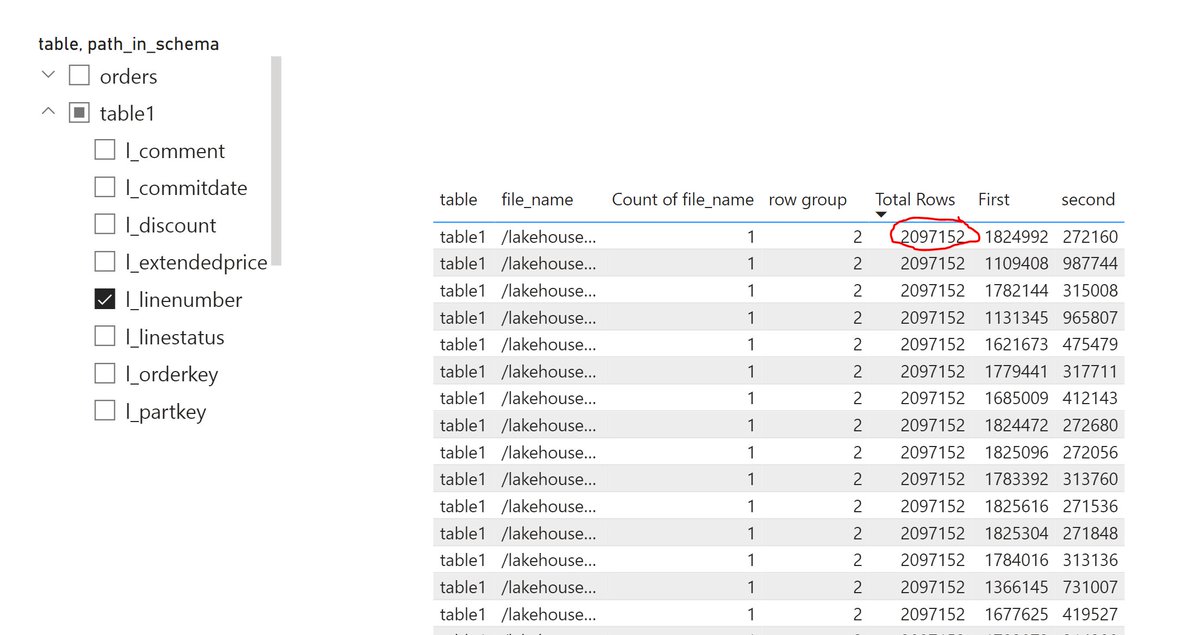
some observation on #DeltaTable generated by #Fabric DWH, 2097152 rows per file, sometimes all in one group, and sometimes split on 2 row groups, probably much more complex than that but anyway, it seems to like very big rowgroups !!!!
I was expecting a cage fight but it did not happen :) joking aside, I like this open project a lot, and hope will bring more interoperability between Open Table Format #OneTable #Iceberg #Deltatable opensourcedatasummit.com/open-data-foun…

when you ingest a lot of small files into #DeltaTable make sure you alter the delta.logRetentionDuration to a more sensible duration otherwise you end up with a Log bigger than the Data itself :) to be clear only myself to blame here :)
Something went wrong.
Something went wrong.
United States Trends
- 1. Cyber Monday 51.2K posts
- 2. Admiral Bradley 3,329 posts
- 3. TOP CALL 11.6K posts
- 4. GreetEat Corp. N/A
- 5. Shakur 6,626 posts
- 6. #GivingTuesday 3,200 posts
- 7. Adam Thielen 2,787 posts
- 8. #Rashmer 19K posts
- 9. MSTR 30.2K posts
- 10. Check Analyze N/A
- 11. Token Signal 3,900 posts
- 12. Alina Habba 37.4K posts
- 13. MRIs 2,289 posts
- 14. Hartline 3,086 posts
- 15. Toosii 1,209 posts
- 16. LA PIJAMADA VIRAL 59.1K posts
- 17. Trump's MRI 12.9K posts
- 18. Marty Supreme 3,791 posts
- 19. Clarie 4,127 posts
- 20. UCLA 7,224 posts