#documentclustering search results

This brilliant group of students have set out to change the traditional method of #documentclustering using Machine Learning. 👏Through #FYPAccelerator2022, these students will receive mentorship & guidance from senior #10Pearls #resources to help them bring their #idea to life



Text Analysis 101; A Basic Understanding for Business Users: Clustering andUnsupervised Methods ow.ly/4nowhq


📂 Document Clustering: Clustering also helps organize documents and articles. Dive into how AI groups similar text documents and its role in information retrieval. 📚🔍 #DocumentClustering #AIinText

Read about 4 #NLProc papers our engineers are publishing in "Findings of the ACL" & in #EMNLP2021 workshops this week, and learn how they're advancing the state-of-the-art as it relates to dialogue state tracking, #documentclustering, & #wordembeddings bloom.bg/3qlsjwx

A Literature Review of Various Techniques for Performing Document Clustering #DocumentClustering, #Stemming, #TermFrequency, #Preprocessing, #ClusteringAlgorithms Read Full Paper and Explore thousands of paper on ijirtExplore

. @soon_svm #SOONISTHEREDPILL For document clustering, soon_svm groups similar documents together effectively. #soon_svm #DocumentClustering

Kernel-based Consensus Clustering for Ontology-embedded Document Repository of Power Substations #powersystemassetmanagement #documentclustering #consensusclustering #ontology #kernelmethod #GA livrepository.liverpool.ac.uk/3003573
. @soon_svm #SOONISTHEREDPILL For document clustering, soon_svm groups similar documents together effectively. #soon_svm #DocumentClustering
📂 Document Clustering: Clustering also helps organize documents and articles. Dive into how AI groups similar text documents and its role in information retrieval. 📚🔍 #DocumentClustering #AIinText
This brilliant group of students have set out to change the traditional method of #documentclustering using Machine Learning. 👏Through #FYPAccelerator2022, these students will receive mentorship & guidance from senior #10Pearls #resources to help them bring their #idea to life
Read about 4 #NLProc papers our engineers are publishing in "Findings of the ACL" & in #EMNLP2021 workshops this week, and learn how they're advancing the state-of-the-art as it relates to dialogue state tracking, #documentclustering, & #wordembeddings bloom.bg/3qlsjwx
A Literature Review of Various Techniques for Performing Document Clustering #DocumentClustering, #Stemming, #TermFrequency, #Preprocessing, #ClusteringAlgorithms Read Full Paper and Explore thousands of paper on ijirtExplore
Kernel-based Consensus Clustering for Ontology-embedded Document Repository of Power Substations #powersystemassetmanagement #documentclustering #consensusclustering #ontology #kernelmethod #GA livrepository.liverpool.ac.uk/3003573
Text Analysis 101; A Basic Understanding for Business Users: Clustering andUnsupervised Methods ow.ly/4nowhq






Uber Eats handles millions of product images every hour. At this scale, duplicate images can burn a hole in your pocket. Storing the same image multiple times is a huge drag on processing and CDN costs. Uber had to build an entire system to deal with duplicate images. Their…





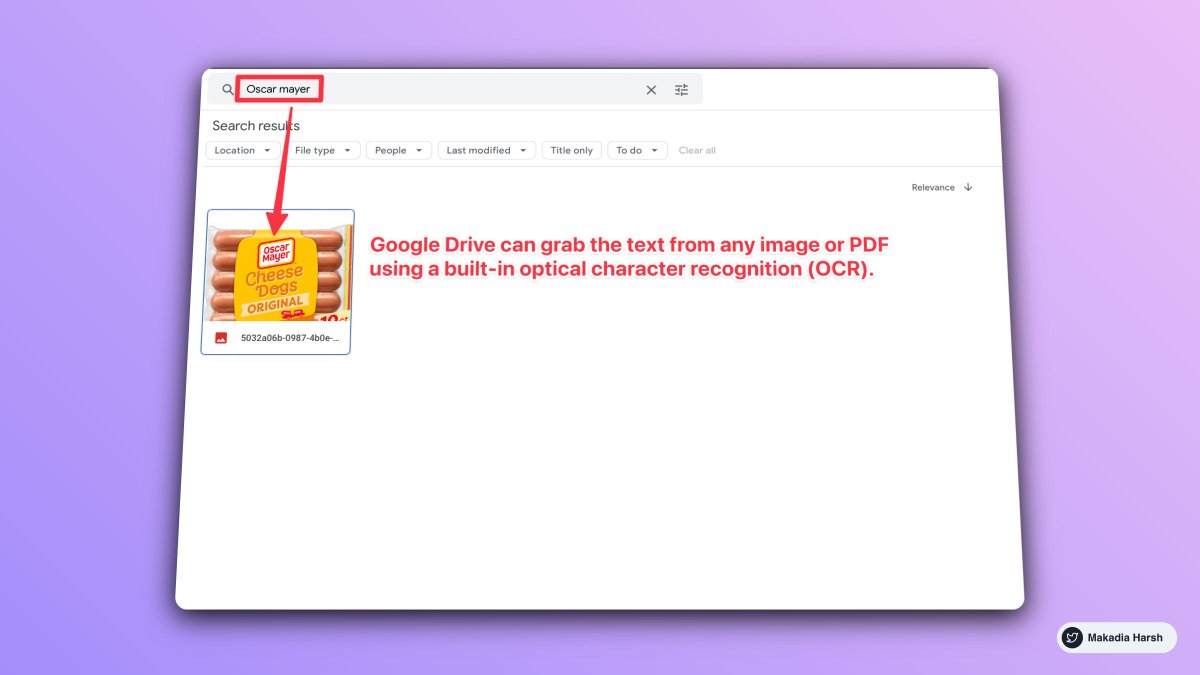
1. Search within images A simple search for word image has, it will fetch you appropriate images. It even recognizes the text in images.

AI tool that splits text, extracts entities, builds knowledge graphs from documents


5.) Without going too much into theory, clusters are basically a group of pixels with the same color. The opposites of clusters are called "strays", which are stray 1x1 or 2x1. If you're not careful, you can have your piece end up looking noisy if you don't use these correctly.


distrm.de/e/ummbpkyazu6u distrm.de/e/4c32rez23b0l distrm.de/e/kg8w1qmaes4j distem.de/e/qpzv1r8hibm5 distrm.de/e/hieomjvf6t6r


After 10+ years of terrible Word-to-PDF doc conversions I think I have found the magical steps to avoid image compression ... Just in time for a big Oct grant sub full of pretty brain pics 😉 Seriously, do this 👇


Now you can identify the differences between the two document photos processed with the same Error Level Analysis. (Left) Source: x.com/UntheeUnti/sta… (Right) Source: x.com/DianSandiU/sta…



Buat yang ributin fotocopy Ijazah Pak @jokowi yang saya upload pada utas. Biar kalian tenang lebarannya; ini saya upload yang asli.


New post: From PDFs to AI-ready structured data 📃✨ A deep dive into document processing, layout analysis and a modular workflow for building end-to-end document understanding and information extraction pipelines using PDFs, Word documents, scans and more.




Images are a huge part of bandwidth size/costs. We're using machine learning to cut 75% bandwidth per image. blog.google/products/googl…



if i'm understanding this correctly, you can use a pure text encoder model to find text that lets you reconstruct an image from the text encoding. basically, the latent space of a text model is expressive enough to serve as a compilation target for images



Something went wrong.
Something went wrong.
United States Trends
- 1. Cam Coleman 3,153 posts
- 2. Vandy 5,059 posts
- 3. Iowa 29K posts
- 4. Auburn 13.7K posts
- 5. Oregon 39.7K posts
- 6. Dante Moore 3,443 posts
- 7. #UFCVegas111 9,838 posts
- 8. Wisconsin 17.3K posts
- 9. Vanderbilt 3,863 posts
- 10. Bauer Sharp N/A
- 11. Indiana 42.6K posts
- 12. #AEWCollision 1,845 posts
- 13. Heisman 11.8K posts
- 14. Penn State 26K posts
- 15. Mendoza 24K posts
- 16. Pavia 2,109 posts
- 17. Badgers 3,587 posts
- 18. Jedd Fisch N/A
- 19. Clark Lea N/A
- 20. #Svengoolie N/A