#opensourcedeeplearningprojects 검색 결과

Today, we are releasing FineVision, a huge open-source dataset for training state-of-the-art Vision-Language Models: > 17.3M images > 24.3M samples > 88.9M turns > 9.5B answer tokens Here are my favourite findings:


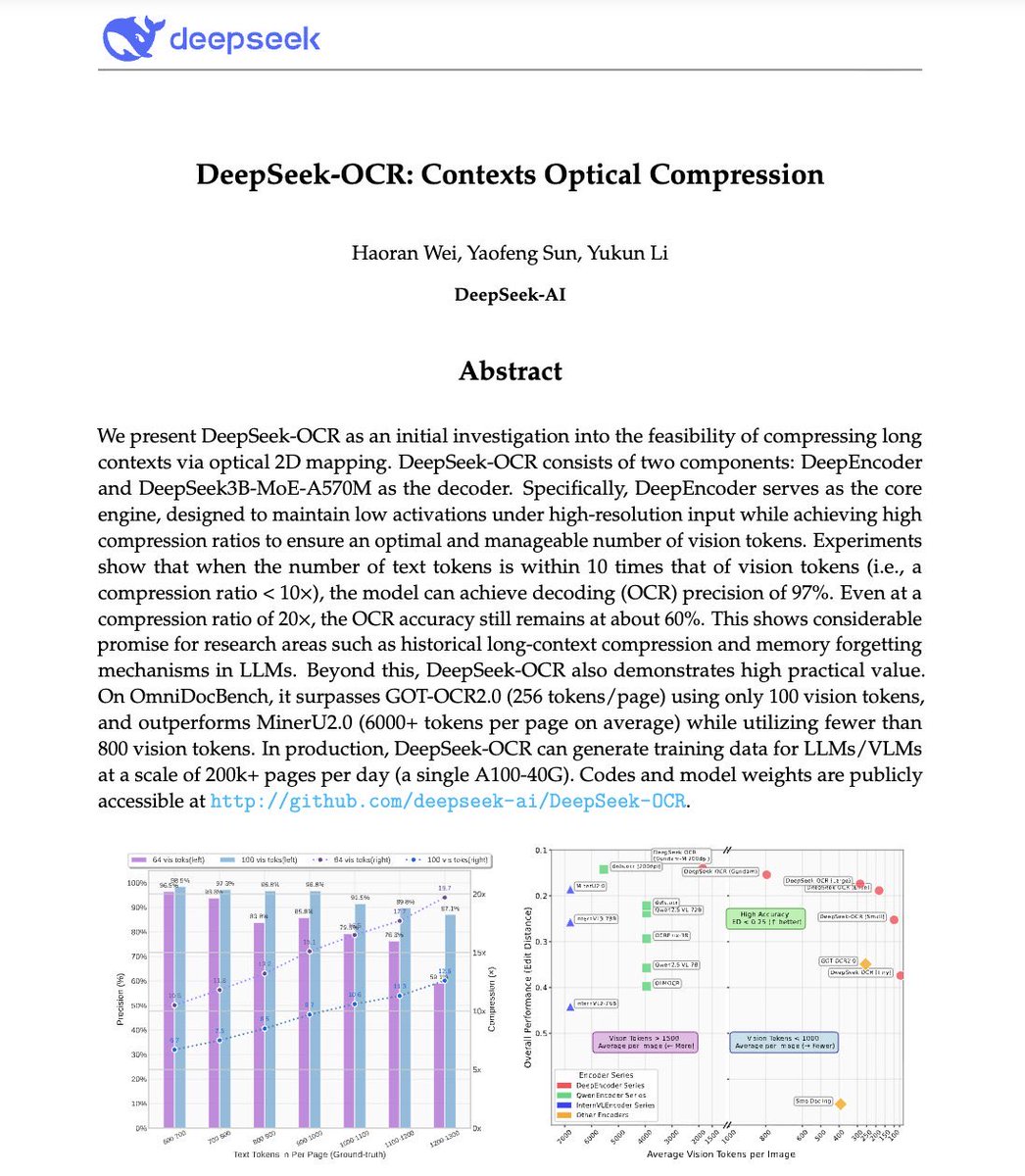
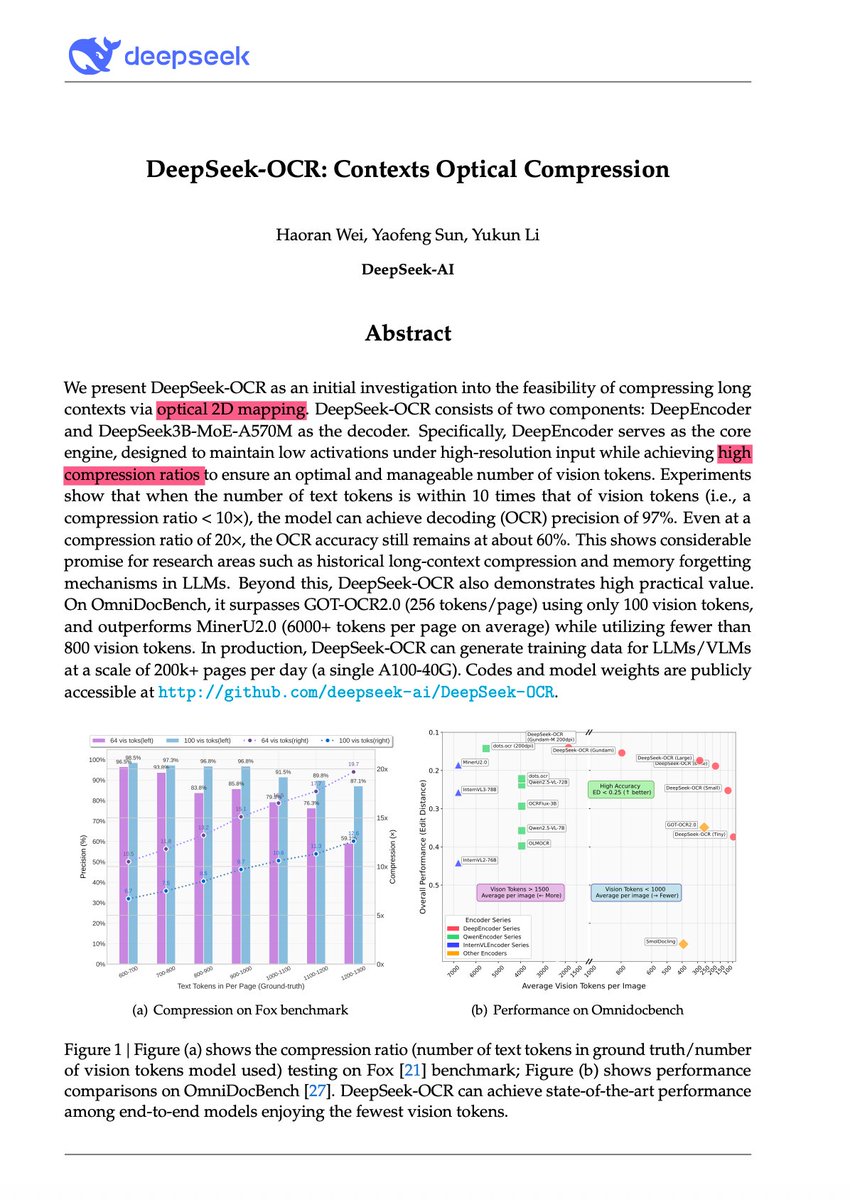
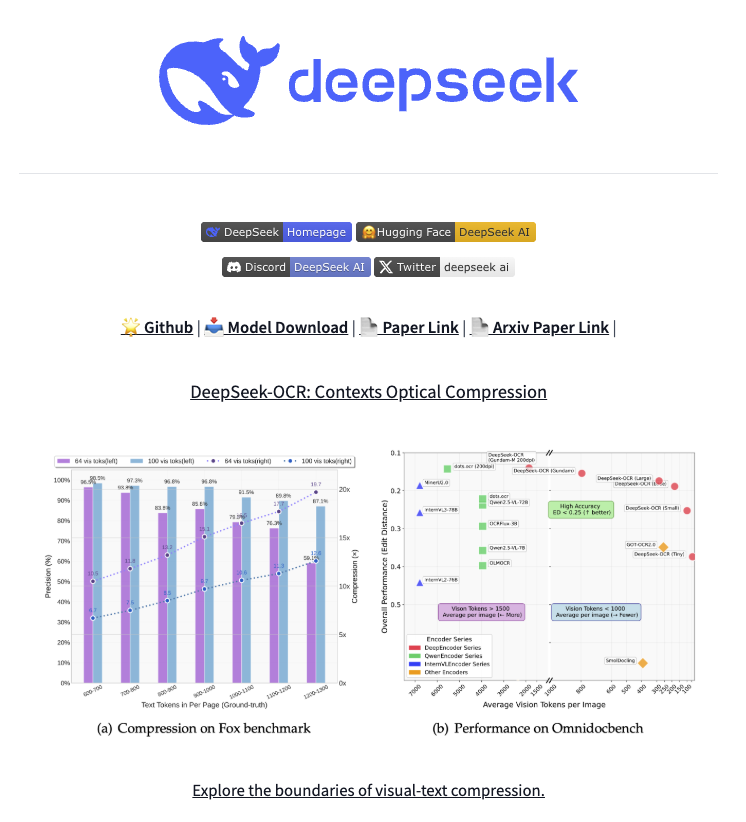
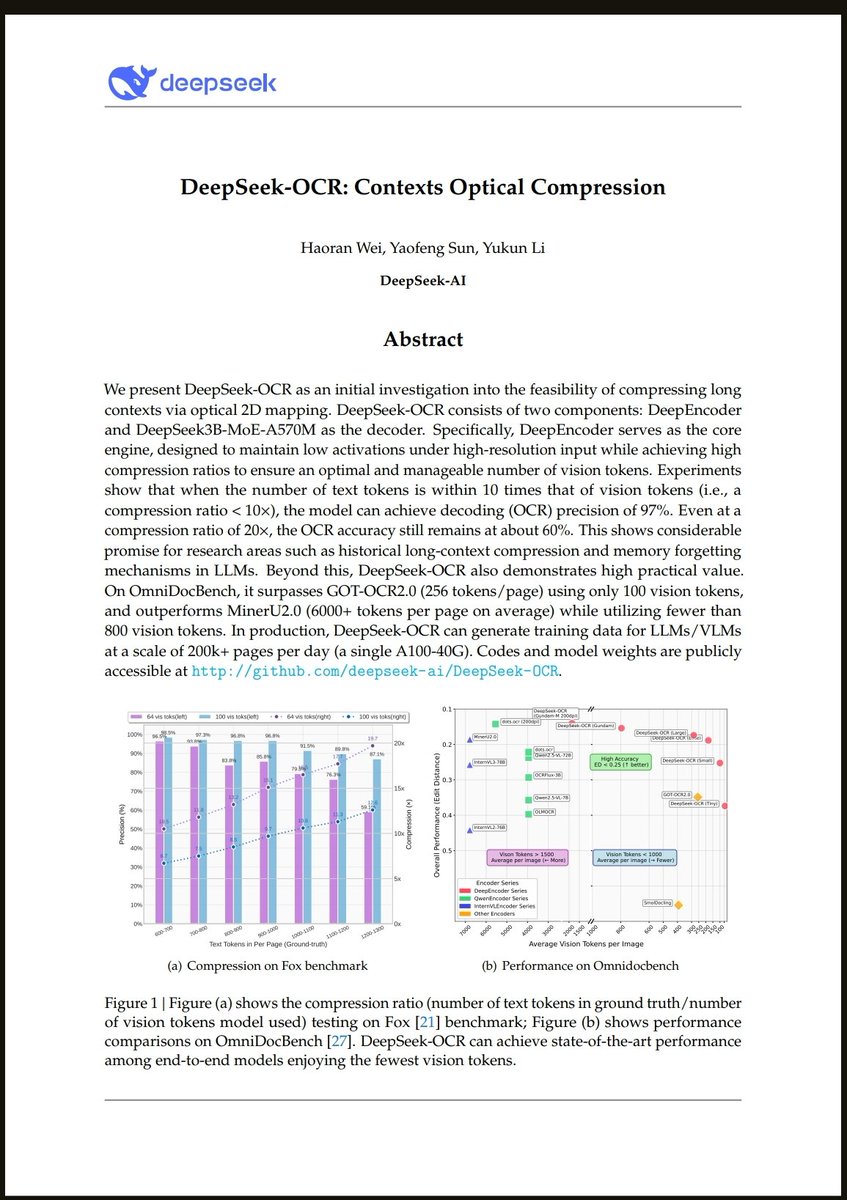
🚨 DeepSeek just did something wild. They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels. Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That…
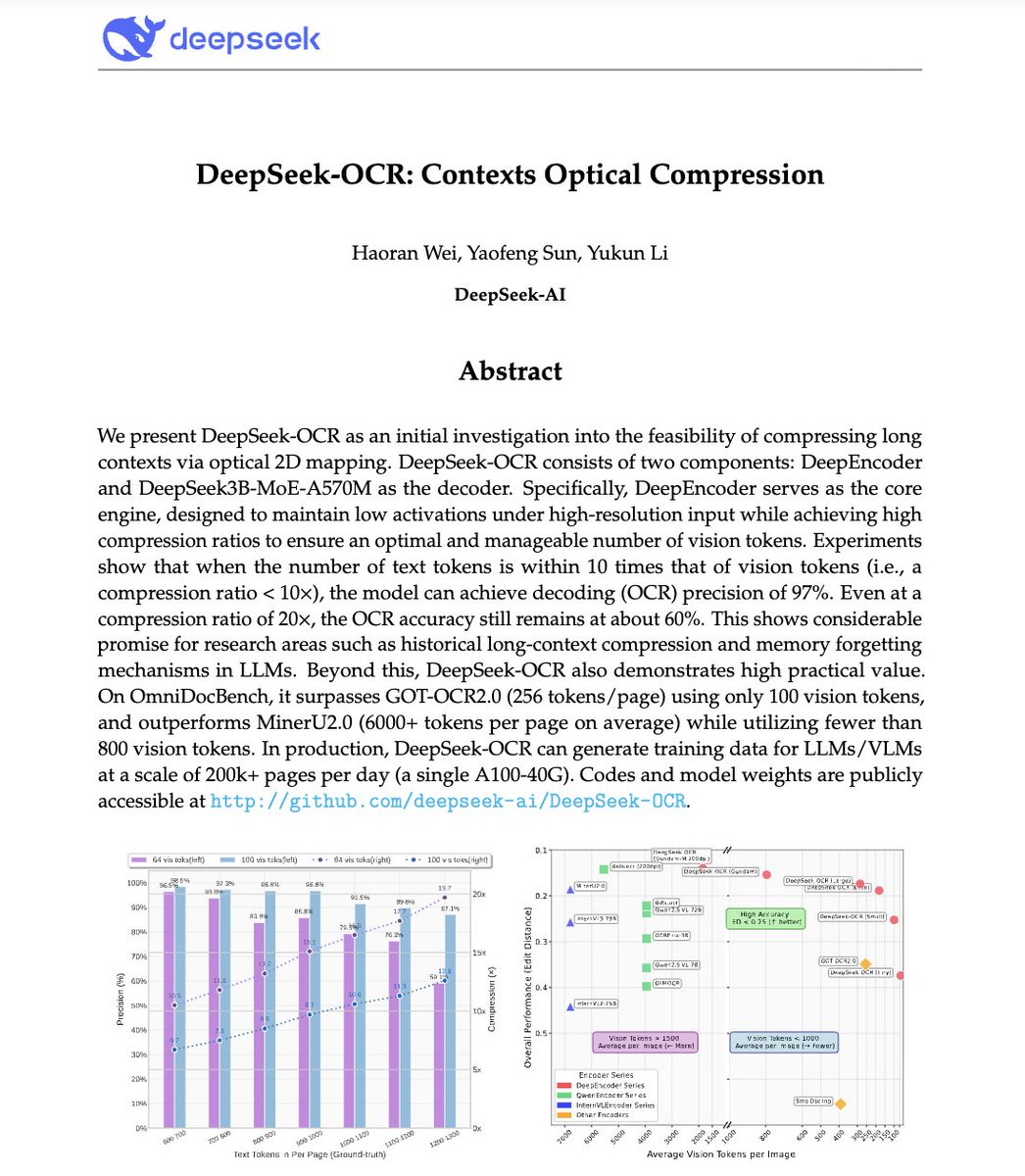

🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping…




AI is power. It's not just a chatbot. It represents unlimited possibilities. DeepNode lets you unlock what's possible. Here's how we do it, together. 🧵


🔥 Bonus: Open-Source Distilled Models! 🔬 Distilled from DeepSeek-R1, 6 small models fully open-sourced 📏 32B & 70B models on par with OpenAI-o1-mini 🤝 Empowering the open-source community 🌍 Pushing the boundaries of **open AI**! 🐋 2/n


DeepSeek finally released a new model and paper. And because this DeepSeek-OCR release is a bit different from what everyone expected, and DeepSeek releases are generally a big deal, I wanted to do a brief explainer of what it is all about. In short, they explore how vision…


If you want to learn Deep Learning from the ground up to advanced techniques, this open resource is a gem. Full notebook suite -> Link in comments


Many companies today have achieved one form of breakthrough in robotics or another, but the question isn't what can these robots do, it's about how they'll work together. @openmind_agi These machines can't share what they've learned, they can't coordinate and can't build on…


Unlike closed AI labs, DeepSeek proves they are truly open research Their OCR paper treats paragraphs as pixels and is 60x leap more efficient than traditional LLMs Small super efficient models are the future

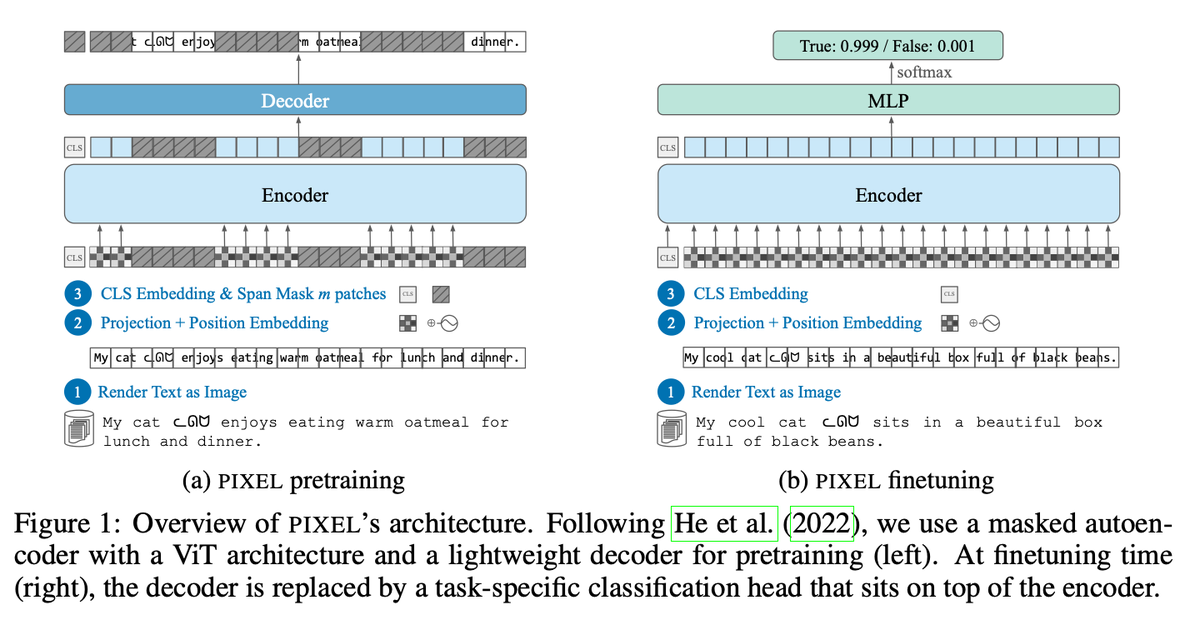
DeepSeek-OCR looks impressive, but its core idea is not new. Input “Text” as “Image” — already explored by: LANGUAGE MODELING WITH PIXELS (Phillip et al., ICLR 2023) CLIPPO: Image-and-Language Understanding from Pixels Only (Michael et al. CVPR 2023) Pix2Struct: Screenshot…


𝐒𝐞𝐧𝐭𝐢𝐞𝐧𝐭 @NeurIPSConf 4 breakthroughs. 1 mission, building open, trusted intelligence. This year, 𝗦𝗲𝗻𝘁𝗶𝗲𝗻𝘁’s research reached a new frontier: 4 papers accepted at 𝗡𝗲𝘂𝗿𝗜𝗣𝗦, proving that open-source AI can be powerful, secure, and verifiable. ✮⋆˙ 𝗢𝗠𝗟…


This is the JPEG moment for AI. Optical compression doesn't just make context cheaper. It makes AI memory architectures viable. Training data bottlenecks? Solved. - 200k pages/day on ONE GPU - 33M pages/day on 20 nodes - Every multimodal model is data-constrained. Not anymore.…


A more serious thread on the DeepSeek-OCR hype / serious misinterpretation going on. 1. On token reduction via representing text in images, researchers from Cambridge have previously shown that 500x prompt token compression is possible (ACL'25, Li, Su, and Collier). Without…

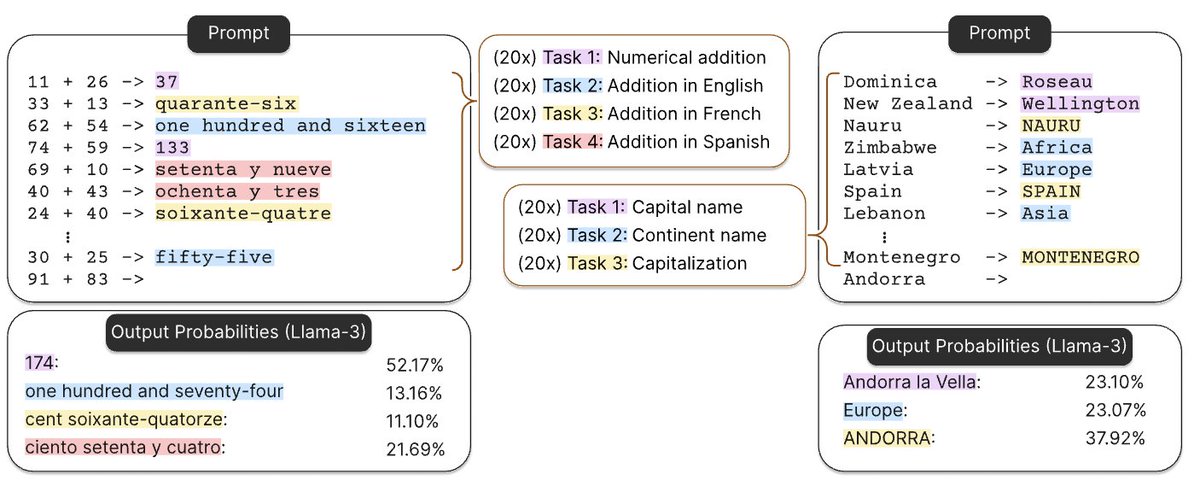

what a bold direction by deepseek once again. they took "a picture is worth a thousand words" literally or the idea of "photographic memory" if i am to commit the crime of anthropomorphisation.

Good morning friends. Still working hard and really happy to see myself on the @openmind_agi leaderboard on Kaito. I started writing about this project a while ago, and from the first read, it immediately caught my attention. #OpenMind builds open-source software that helps…
If you are not sure how to spend your November 1, here is a good idea. Join the Dobot × @openmind_agi Workshop in San Francisco an event that feels like a glimpse into the future of robotics and AI. You will see Dobot’s six-legged robot dog and OpenMind’s latest PRISM demo…




🔥 Holy shit... Apple just did something nobody saw coming They just dropped Pico-Banana-400K a 400,000-image dataset for text-guided image editing that might redefine multimodal training itself. Here’s the wild part: Unlike most “open” datasets that rely on synthetic…


BOOOOOOOM! CHINA DEEPSEEK DOES IT AGAIN! An entire encyclopedia compressed into a single, high-resolution image! — A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and…
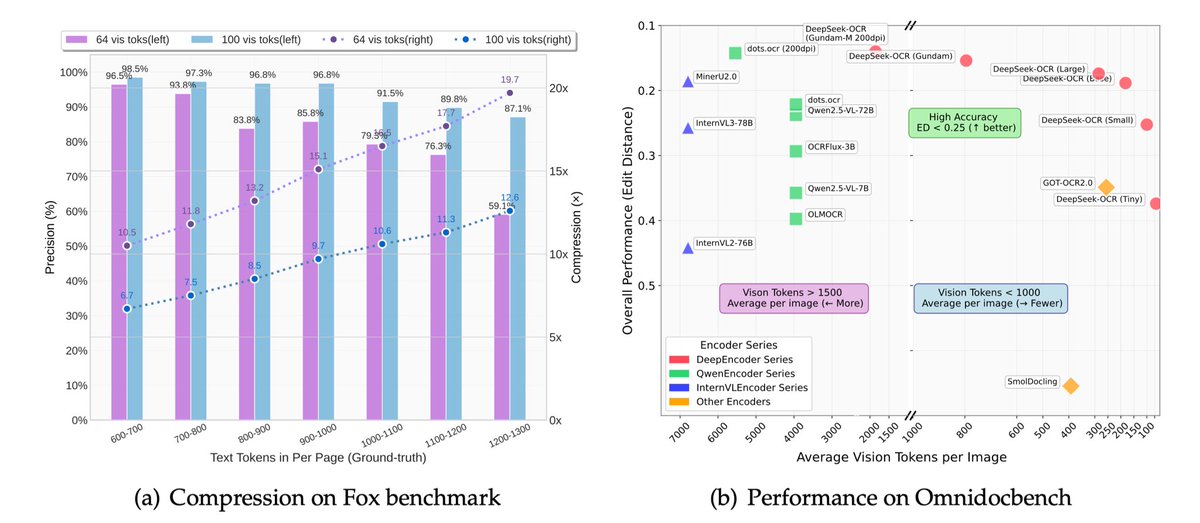
Something went wrong.
Something went wrong.
United States Trends
- 1. Cowboys 25.7K posts
- 2. Jets 88K posts
- 3. Bengals 52.1K posts
- 4. Jonathan Taylor 5,409 posts
- 5. Eagles 118K posts
- 6. Caleb 38.1K posts
- 7. Giants 98.3K posts
- 8. Riley Moss 1,075 posts
- 9. Zac Taylor 5,511 posts
- 10. Falcons 39.6K posts
- 11. Saints 28.2K posts
- 12. Bo Nix 4,286 posts
- 13. Shough 2,714 posts
- 14. Browns 49.8K posts
- 15. Rattler 5,130 posts
- 16. Sutton 5,126 posts
- 17. Myles Garrett 9,850 posts
- 18. #BroncosCountry 2,814 posts
- 19. Blaney 4,291 posts
- 20. Bears 67.3K posts