#opensourcedeeplearningprojects 搜尋結果

Practical #MachineLearning for #ComputerVision — End-to-End ML for Images: amzn.to/4ajfVSf ———— #BigData #DataScience #AI #DeepLearning #NeuralNetworks


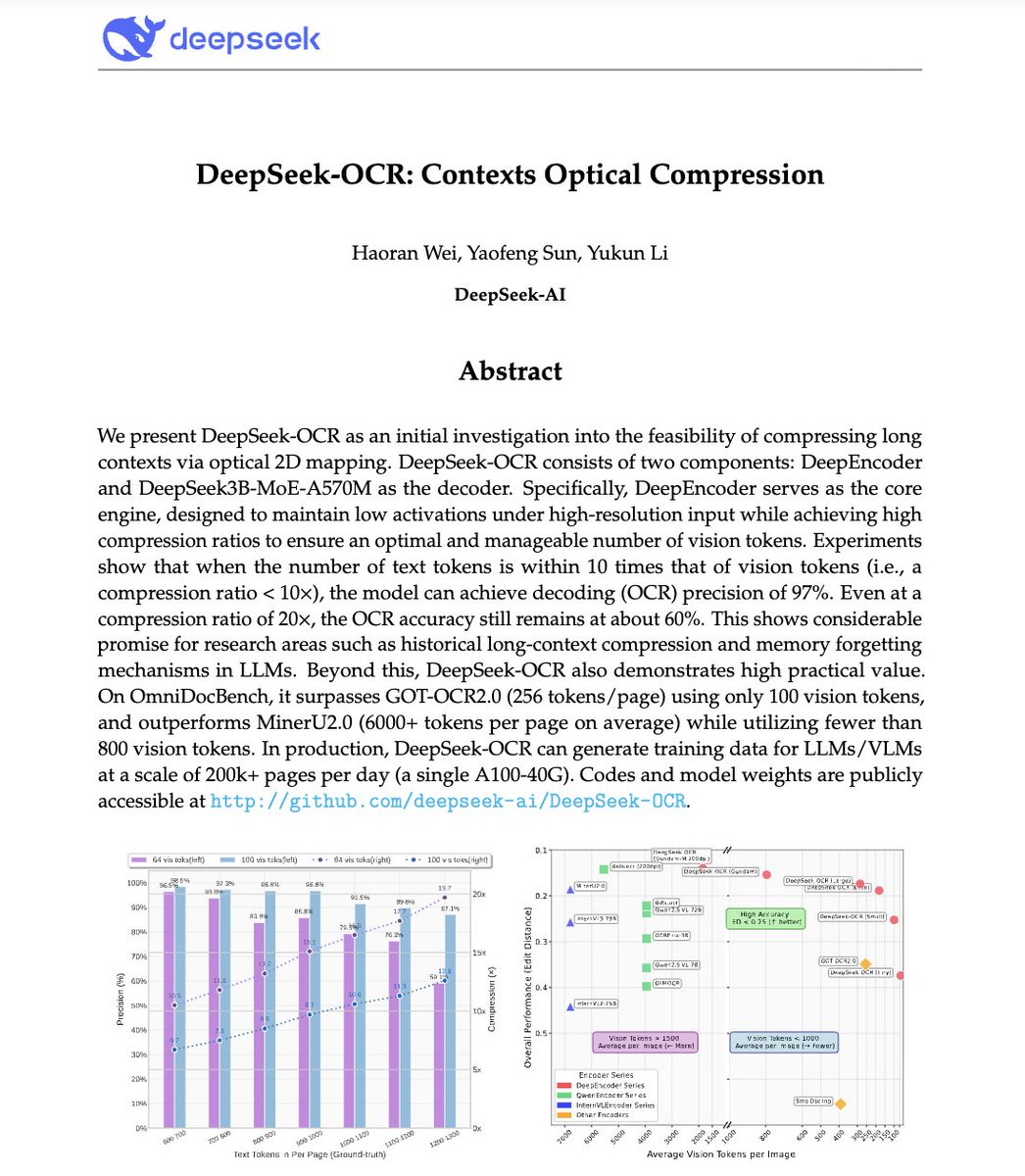
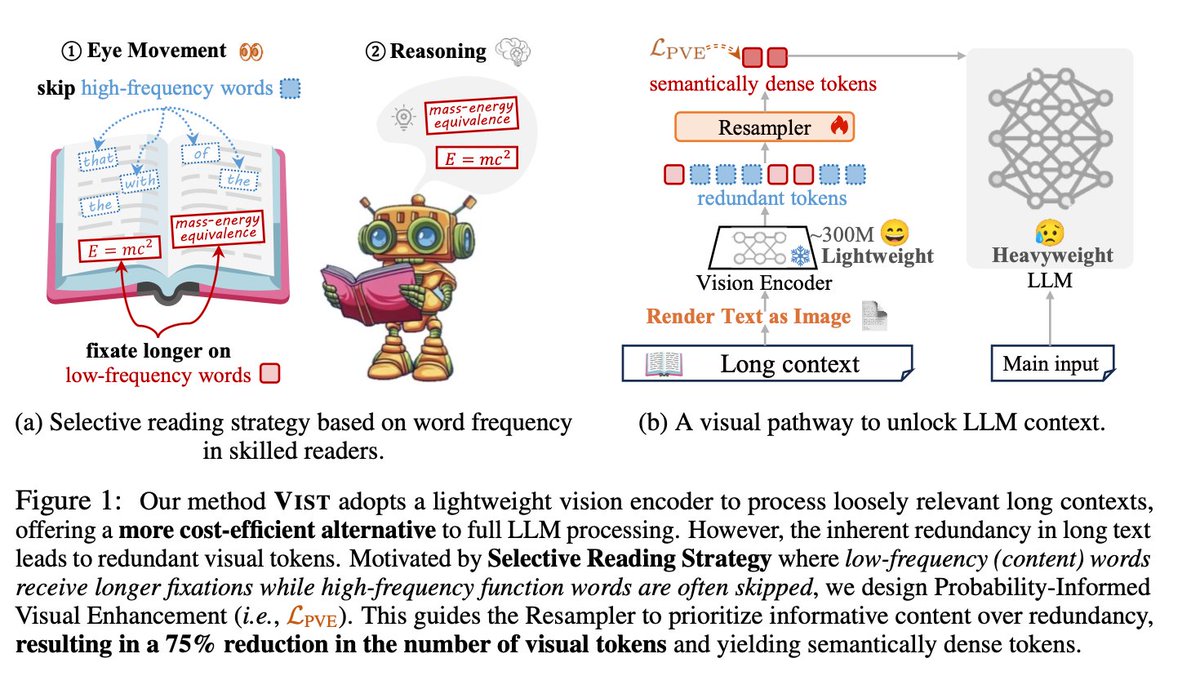
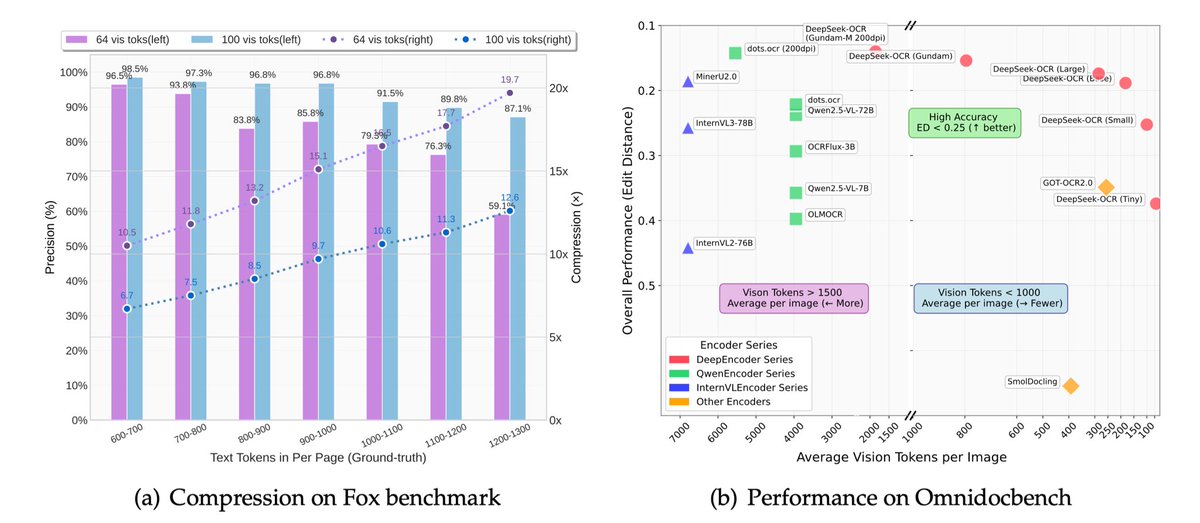
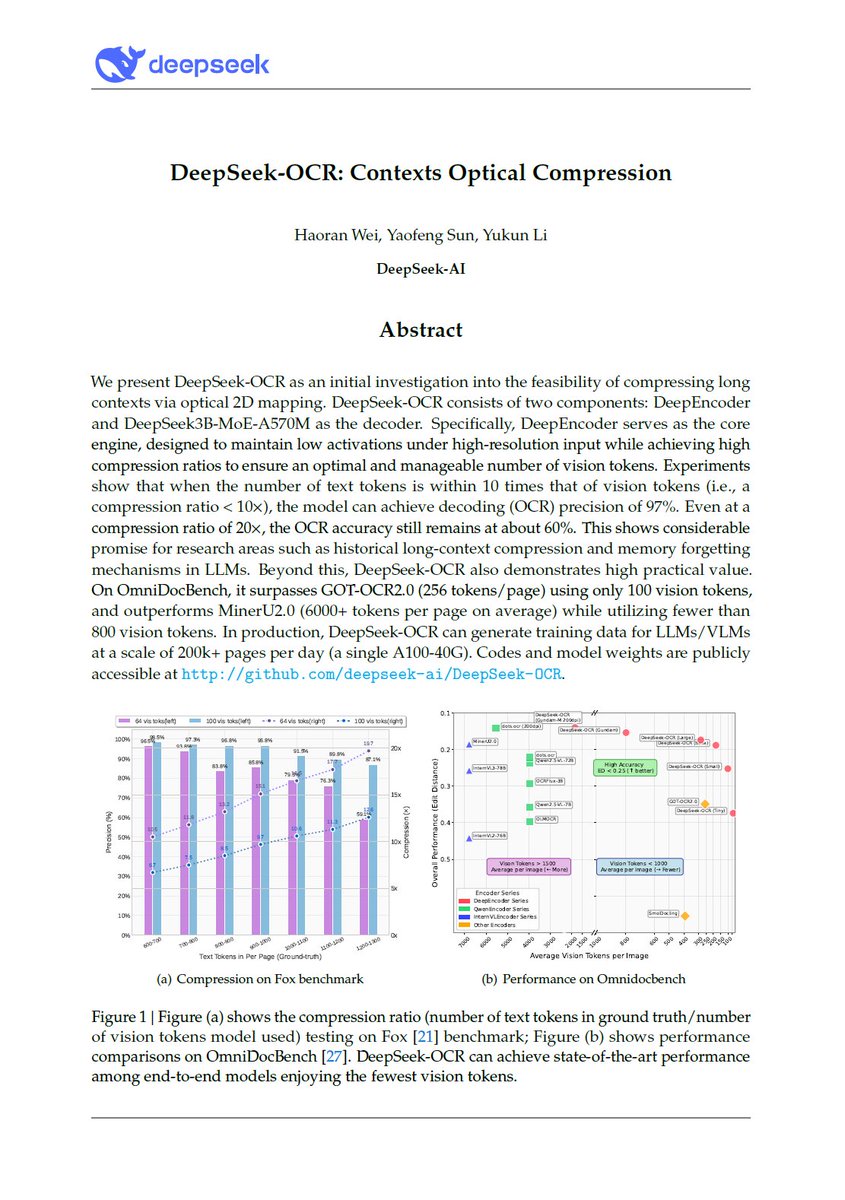
🚨 DeepSeek just did something wild. They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels. Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That…

If you want to learn Deep Learning from the ground up to advanced techniques, this open resource is a gem. Full notebook suite -> Link in comments


Today, we are releasing FineVision, a huge open-source dataset for training state-of-the-art Vision-Language Models: > 17.3M images > 24.3M samples > 88.9M turns > 9.5B answer tokens Here are my favourite findings:


🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping…




🚨 AI is difficult to learn, but not anymore.🚨 🚫 Introducing "Machine Learning Systems " PDF. You will get: 🔥2620+ pages 🔥Save 100+ hours on research And it's 100% FREE! To get it, just: 🔁 Like and Retweet 📥 Comment " ML " 👤 Follow Must (For DM the link)


Many companies today have achieved one form of breakthrough in robotics or another, but the question isn't what can these robots do, it's about how they'll work together. @openmind_agi These machines can't share what they've learned, they can't coordinate and can't build on…


🔥 Bonus: Open-Source Distilled Models! 🔬 Distilled from DeepSeek-R1, 6 small models fully open-sourced 📏 32B & 70B models on par with OpenAI-o1-mini 🤝 Empowering the open-source community 🌍 Pushing the boundaries of **open AI**! 🐋 2/n


This is the JPEG moment for AI. Optical compression doesn't just make context cheaper. It makes AI memory architectures viable. Training data bottlenecks? Solved. - 200k pages/day on ONE GPU - 33M pages/day on 20 nodes - Every multimodal model is data-constrained. Not anymore.…


🧠 OpenMemory: AI Memory Engine An open-source memory system enhancing LLM apps through LangGraph integration. Features structured memory with 2-3× faster recall and 10× lower costs than hosted solutions. Check it out 🔍 github.com/CaviraOSS/Open…


DeepSeek-OCR looks impressive, but its core idea is not new. Input “Text” as “Image” — already explored by: LANGUAGE MODELING WITH PIXELS (Phillip et al., ICLR 2023) CLIPPO: Image-and-Language Understanding from Pixels Only (Michael et al. CVPR 2023) Pix2Struct: Screenshot…
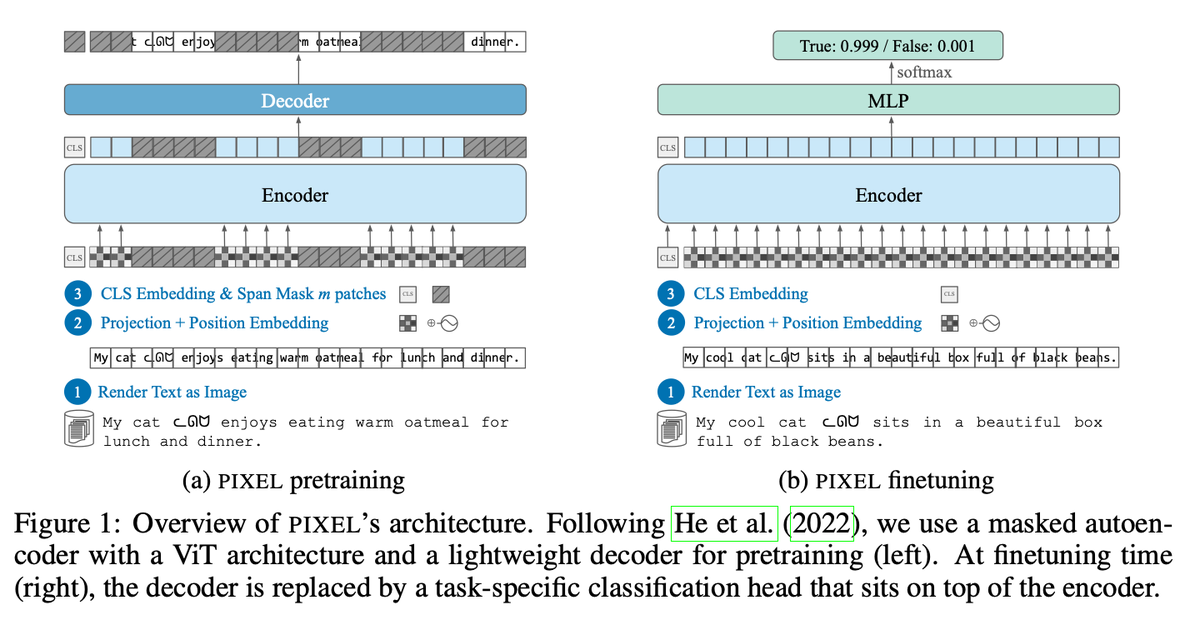
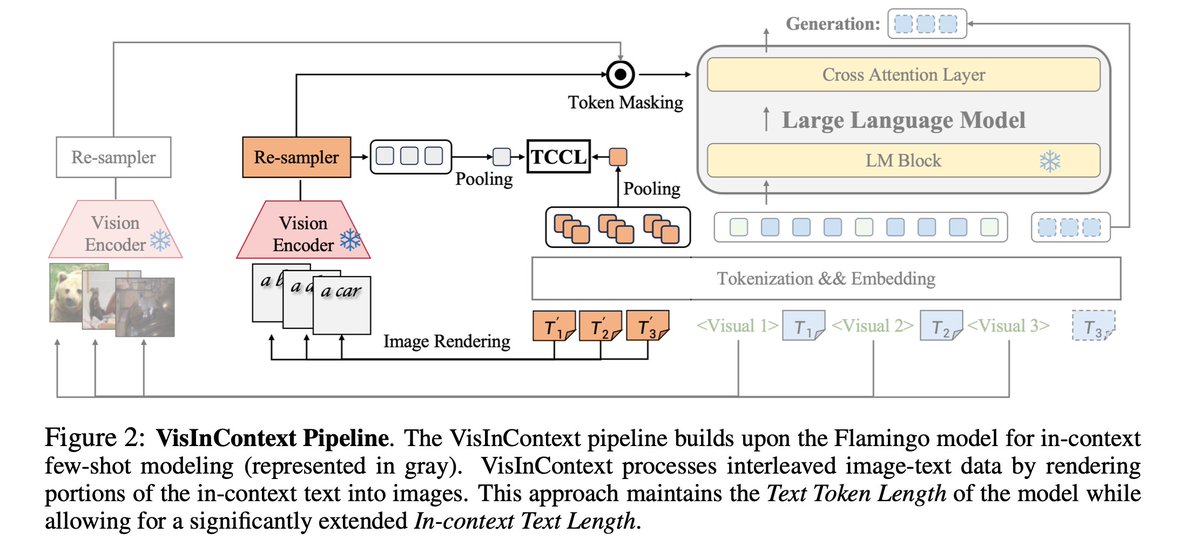

A more serious thread on the DeepSeek-OCR hype / serious misinterpretation going on. 1. On token reduction via representing text in images, researchers from Cambridge have previously shown that 500x prompt token compression is possible (ACL'25, Li, Su, and Collier). Without…


BOOOOOOOM! CHINA DEEPSEEK DOES IT AGAIN! An entire encyclopedia compressed into a single, high-resolution image! — A mind-blowing breakthrough. DeepSeek-OCR, unleashed an electrifying 3-billion-parameter vision-language model that obliterates the boundaries between text and…




Can I get GM ? ☀️ What if AI wasn’t controlled by a single company but by an open network of minds working together? That’s the vision behind @openmind_agi a collaborative layer for autonomous agents, logic, and reasoning built in the open, for everyone.


I just tested a new AI headshot generator. i uploaded 4 inputs, it creates me 40 professional portraits. Here’s how it works ↓



DeepSeek released an OCR model today. Their motivation is really interesting: they want to use visual modality as an efficient compression medium for textual information, and use this to solve long-context challenges in LLMs. Of course, they are using it to get more training…

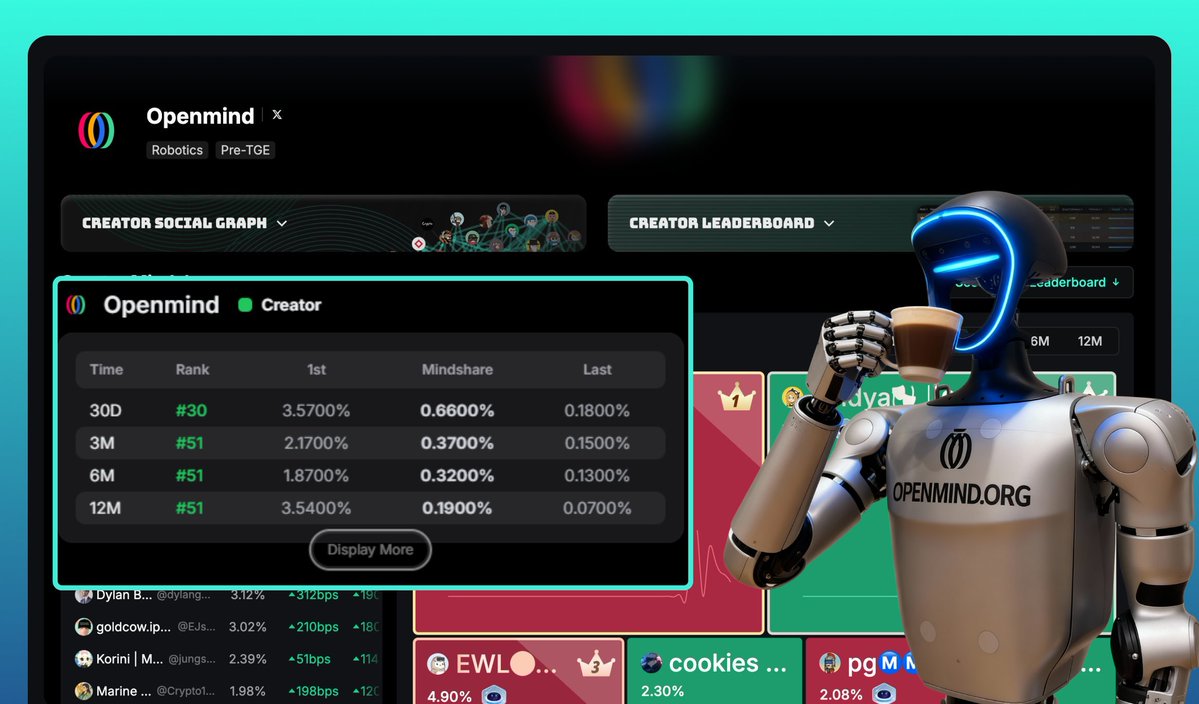
Good morning friends. Still working hard and really happy to see myself on the @openmind_agi leaderboard on Kaito. I started writing about this project a while ago, and from the first read, it immediately caught my attention. #OpenMind builds open-source software that helps…
If you are not sure how to spend your November 1, here is a good idea. Join the Dobot × @openmind_agi Workshop in San Francisco an event that feels like a glimpse into the future of robotics and AI. You will see Dobot’s six-legged robot dog and OpenMind’s latest PRISM demo…

Something went wrong.
Something went wrong.
United States Trends
- 1. Steelers 82.7K posts
- 2. Austin Reaves 37.8K posts
- 3. Packers 64.2K posts
- 4. Tomlin 11.9K posts
- 5. Tucker Kraft 14.9K posts
- 6. Jordan Love 15.5K posts
- 7. #GoPackGo 10.5K posts
- 8. #LakeShow 3,506 posts
- 9. Derry 18.1K posts
- 10. #BaddiesAfricaReunion 7,737 posts
- 11. Aaron Rodgers 19.4K posts
- 12. Teryl Austin 2,107 posts
- 13. Pretty P 3,458 posts
- 14. #HereWeGo 7,459 posts
- 15. #RHOP 9,105 posts
- 16. Dolly 11.7K posts
- 17. Green Bay 10.8K posts
- 18. Zayne 17.1K posts
- 19. Sabonis 2,300 posts
- 20. Karola 3,958 posts