#sparksql risultati di ricerca

D83 Spark’s Tungsten engine = Better codegen + memory management. It’s why DataFrames are faster than RDDs. #ApacheSpark #BigData #SparkSQL #DataEngineering #DistributedSystems #PerformanceOptimization #JVM #DataFrames

🚀 Need help with PySpark tasks? Get expert PySpark Job Support, PySpark Proxy Job Support, and PySpark Job Support Online for ETL, Spark SQL, Databricks & big data pipelines. DM today! 🔗tinyurl.com/pysparkjobsupp… #PySpark #BigData #SparkSQL #DataEngineering

D69 DataFrames > RDDs for 95% of workloads. But RDDs make you understand Spark. Both matter. #ApacheSpark #BigData #SparkSQL #DataEngineering #ETL #PySpark #DataScience #MachineLearning #CloudComputing #Databricks #DistributedComputing
D52 Spark’s Catalyst Optimizer = SQL on steroids🧠 Rewrites queries→minimizes shuffles→maximizes performance. Invisible magic under the hood. #ApacheSpark #BigData #SparkSQL #DataEngineering #Databricks #ETL #DataPipeline #PerformanceOptimization #DataEngineer #PySpark #Cloud
D45 Spark SQL magic🪄 You can write: df.createOrReplaceTempView("sales") then run pure SQL: SELECT region, SUM(revenue) FROM sales GROUP BY region #SparkSQL #ApacheSpark #BigData #ETL #DataEngineering #Kafka #Streaming #BigData #DataEngineering #PySpark #DataScience #DataPipeline

Day 46 of my #buildinginpublic journey into Data Engineering Learned how to combine SQL + PySpark for large-scale analytics Created RDDs Ran SQL queries on DataFrames Performed complex aggregations Used broadcasting for optimization of joins #PySpark #SparkSQL #BigData
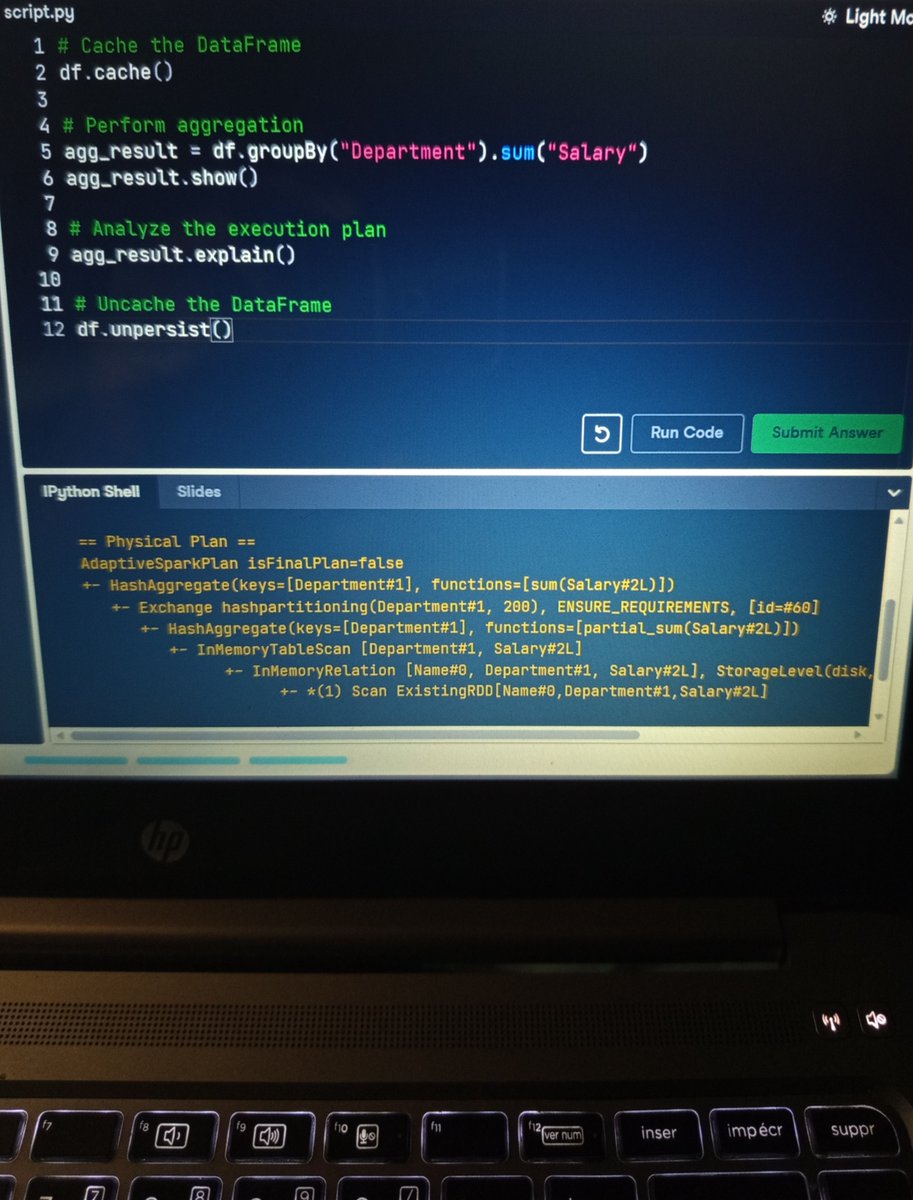


Use regex in Spark SQL for super-powerful string processing! With the RLIKE or REGEXP_EXTRACT functions, you can: Validate formats (e.g., emails, dates). Extract specific data (e.g., codes, values). Filter complex rows. Example: WHERE column RLIKE 'pattern' #SparkSQL
QUALIFY clause in Spark SQL filters the results of window functions (like RANK(), ROW_NUMBER()) without requiring subqueries. It acts like a HAVING clause specifically for window functions,simplifying your queries.QUALIFY RANK() = 1 to get the first record in each group.#SparkSQL

8年前连城大佬把玩SparkSQL的项目 liancheng/spear,克隆后发现sbt版本太老无法构建 😅通过 @cursor_ai 10分钟就把问题解决了!顺手提了个MR:github.com/liancheng/spea… ✅ sbt 0.13.12 → 1.11.6 + JDK 11支持 ✅ 添加了CI/CD pipeline ✅ 集成了代码质量检查 AI辅助开发真的香! #Scala #SparkSQL #AI


🔍 Databricks 結合チューニングのポイント 🔍 Join最適化で処理高速化&コスト削減! 🚀 note.com/mellow_launch/… #Databricks #DeltaLake #SparkSQL #DataEngineering #データエンジニア #ETL #スキュー対策


#ApacheIceberg + #SparkSQL = a solid foundation for building #ML systems that work reliably in production. Time travel, schema evolution & ACID transactions address fundamental data management challenges that have plagued ML infrastructure for years. 🔍 bit.ly/46kCCpQ


💸 Spark SQL costs out of control? Run your dbt transformations for 50% less, with 2–3× better efficiency. No rewrites required. Join Amy Chen (@dbt_labs) & @KyleJWeller (Onehouse) next week to see how. 👉 onehouse.ai/webinar/dbt-on… #dbt #SparkSQL #ETL #DataEngineering


at @yourcreatebase, i was working with large unclaimed music royalty records — to consolidate publisher objects: mapping rights admin relationships to shares, writers, and iswc codes — to make our royalty payout pipeline faster and more accurate #SparkSQL #PySpark #AWS #S3

🧵7/10 Results from TPC-H style workloads: - Joins: 84–95% faster - Filters: 30–50% faster - Aggregations: 20–40% less shuffle All changes are semantically safe. Success rate: 95%+ #SparkSQL #QueryOptimization
Something went wrong.
Something went wrong.
United States Trends
- 1. Bama 26.2K posts
- 2. Ryan Williams 3,003 posts
- 3. Mateer 8,791 posts
- 4. Epstein 1.05M posts
- 5. Ty Simpson 3,230 posts
- 6. Woodley 14.6K posts
- 7. #RollTide 8,287 posts
- 8. Clinton 193K posts
- 9. Anderson Silva 10.3K posts
- 10. #CFBPlayoff 10.5K posts
- 11. #JakeJoshua 27.9K posts
- 12. #SmackDown 17K posts
- 13. DeBoer 5,942 posts
- 14. Chris Finch 1,877 posts
- 15. Sooners 6,506 posts
- 16. #OPLive 1,842 posts
- 17. Alycia 5,094 posts
- 18. Maxey 3,536 posts
- 19. Sixers 5,600 posts
- 20. Brooks 34K posts