#sparksql результаты поиска

Day 46 of my #buildinginpublic journey into Data Engineering Learned how to combine SQL + PySpark for large-scale analytics Created RDDs Ran SQL queries on DataFrames Performed complex aggregations Used broadcasting for optimization of joins #PySpark #SparkSQL #BigData


Learning #SparkSQL! #BigData #Analytics #DataScience #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux #Books #Programming #Coding #100DaysofCode geni.us/Learning-Spark…


¿Tienes problemas para traducir lo que sabes de SQL a la API de Spark DataFrame? 📖 Descarga este documento para conocer más sobre esta API. 🧵Link al documento completo en el hilo. #Spark #sparksql #sql #dataengineering #dataengineer #apachespark


The individual steps seem insignificant when isolated, but when all the puzzle pieces align; it'll be evidence that all of the hard work is not in vain. #ForwardProgress #SparkSQL #BigData #HardWorkPaysOff


Two new metadata schema columns in #ApacheSpark #SparkSQL: 1⃣ Metadata Columns ➡️ http://localhost:8000/spark-sql-internals/metadata-columns/ 2⃣ Hidden File Metadata ➡️ http://localhost:8000/spark-sql-internals/hidden-file-metadata/ Different code paths, yet so similar 🤷♂️

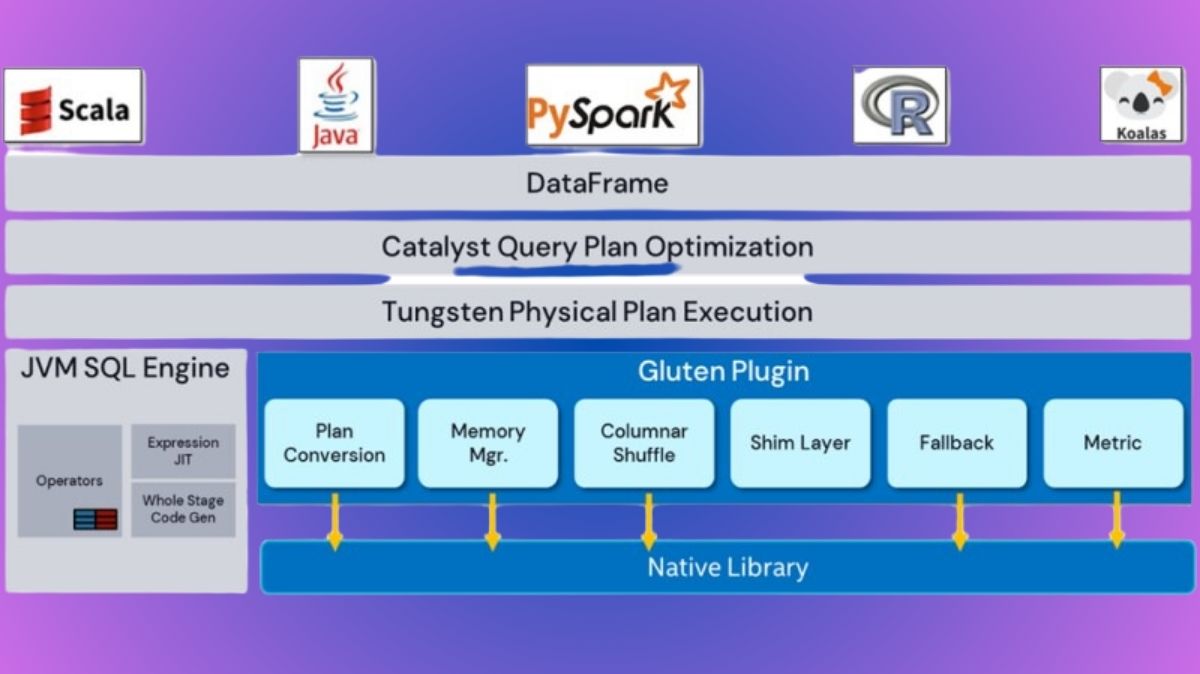
Gluten And Intel CPUs Boost Apache Spark SQL Performance Read more on govindhtech.com/performance-of… #Gluten #IntelCPUs #SparkSQL #SQL #ApacheSpark #Spark #IntelXeonScalableProcessors #Glutenplugin #machinelearning #News #Technews #Technology #Technologynews #Technologytrends…
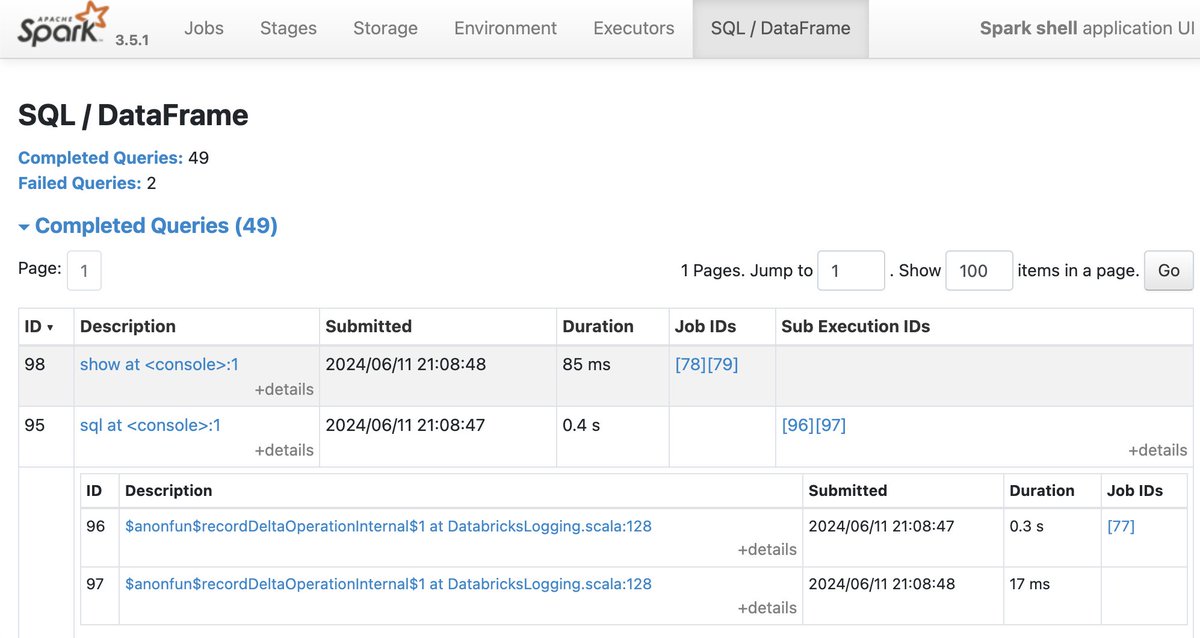
#TIL Sub Execution IDs is a #SparkSQL feature in web UI (not #Databricks-specific as I always thought) 🥳 Any good docs on the feature? 🤔 #ApacheSpark
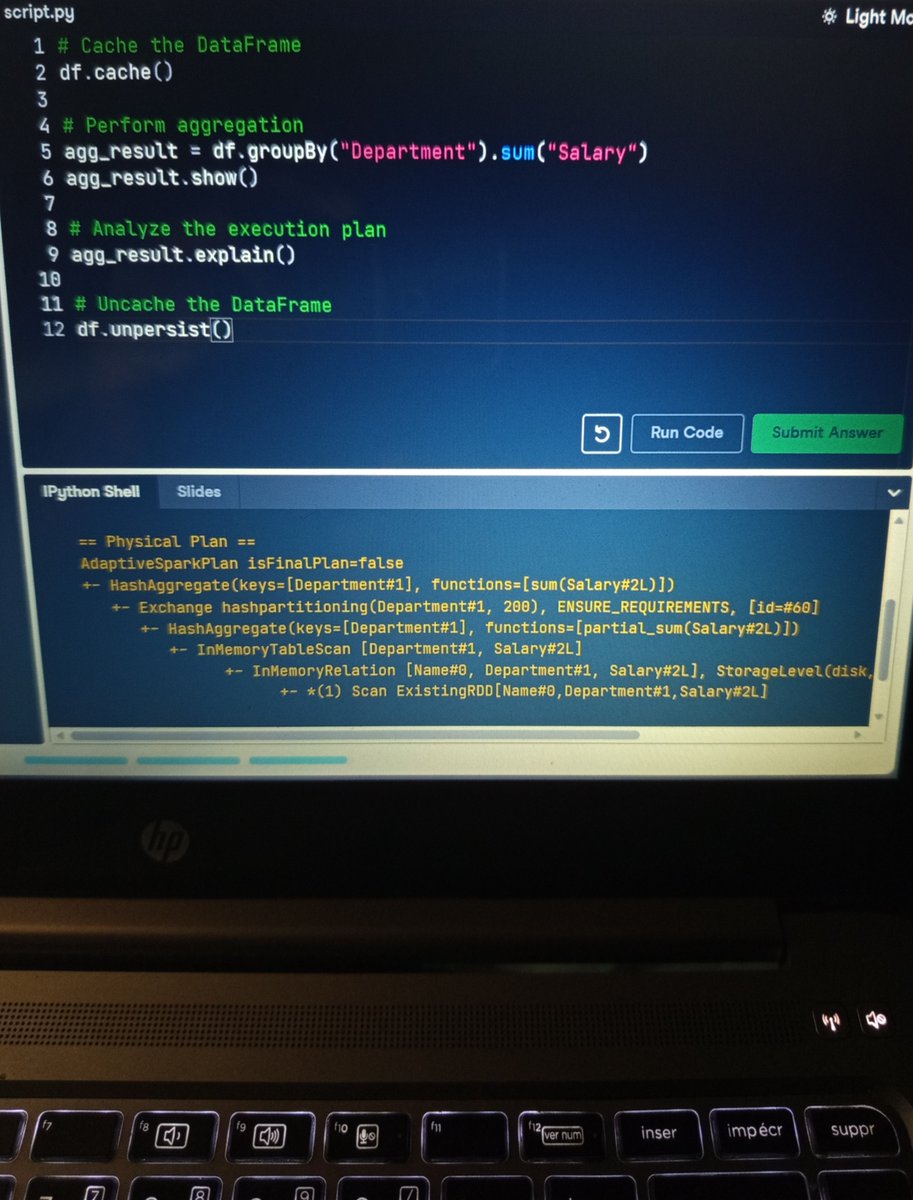
Ever wondered what happens when you execute CACHE TABLE AS command in #ApacheSpark #SparkSQL? 🤔 Curious if it's for tables only? Views too? It all boils down to CacheTableAsSelectExec physical operator that uses high-level ones like we all do! 🥳 ➡️ books.japila.pl/spark-sql-inte…




☁🚀☁ GCP Data Engineer (ETL, SparkSQL) ☁🚀☁ GCP Data Engineer, London, hybrid role – new workstreams on digital banking Google Cloud transformation programme #applyatstaffworx staffworx.co.uk/job/gcp-data-e… #dataengineer #sparksql #etldeveloper #bigquery #contractjobs #gcp
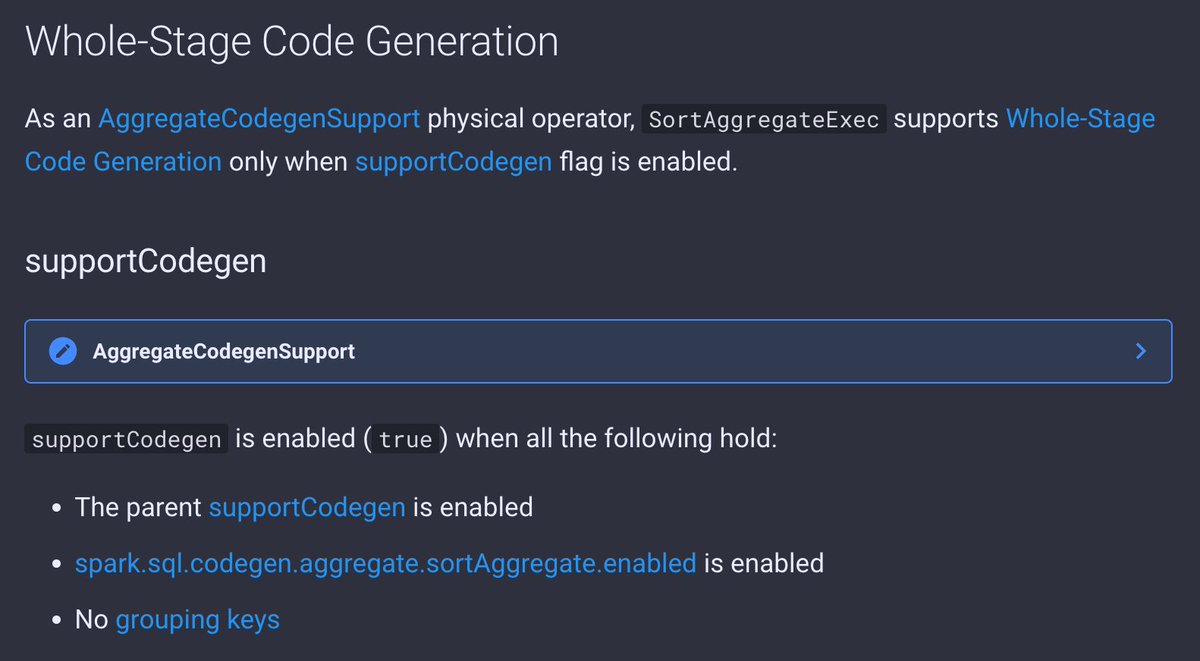
6 days to #DataAISummit 2023 so more updates to The Internals of #SparkSQL and, more importantly, aggregations 💪 Today focusing on the "slowest" aggregate operator SortAggregateExec and SortBasedAggregationIterator 👍 ➡️ books.japila.pl/spark-sql-inte… ➡️ books.japila.pl/spark-sql-inte…



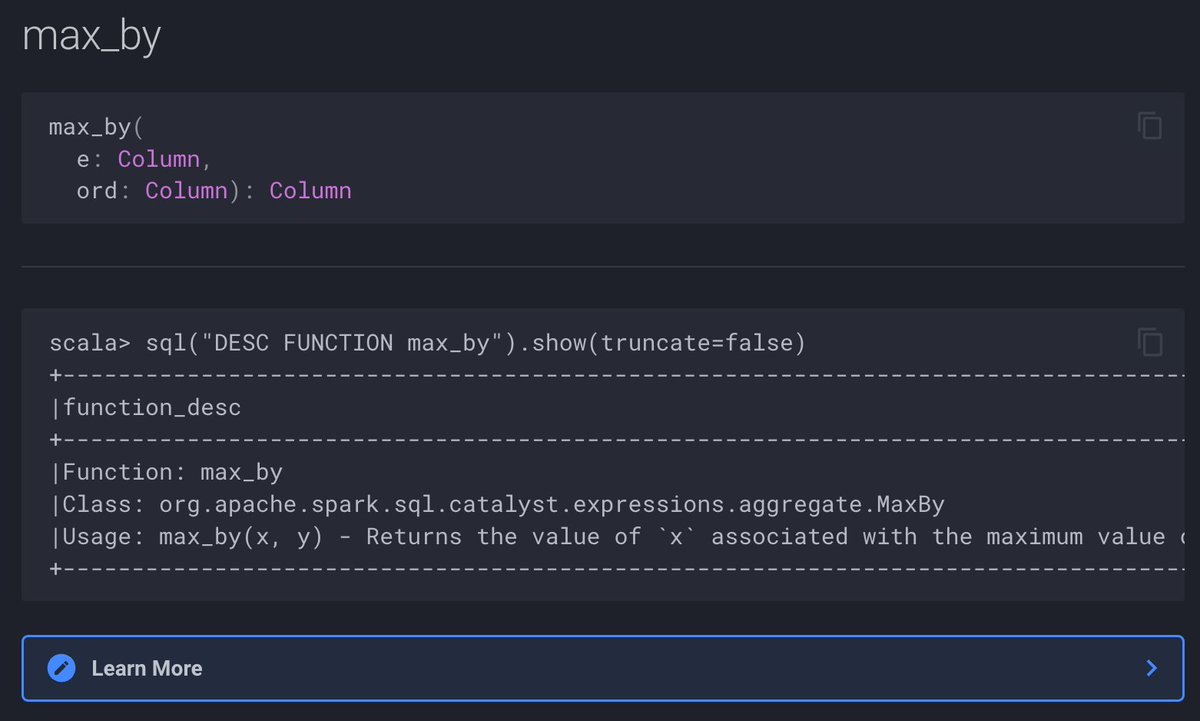
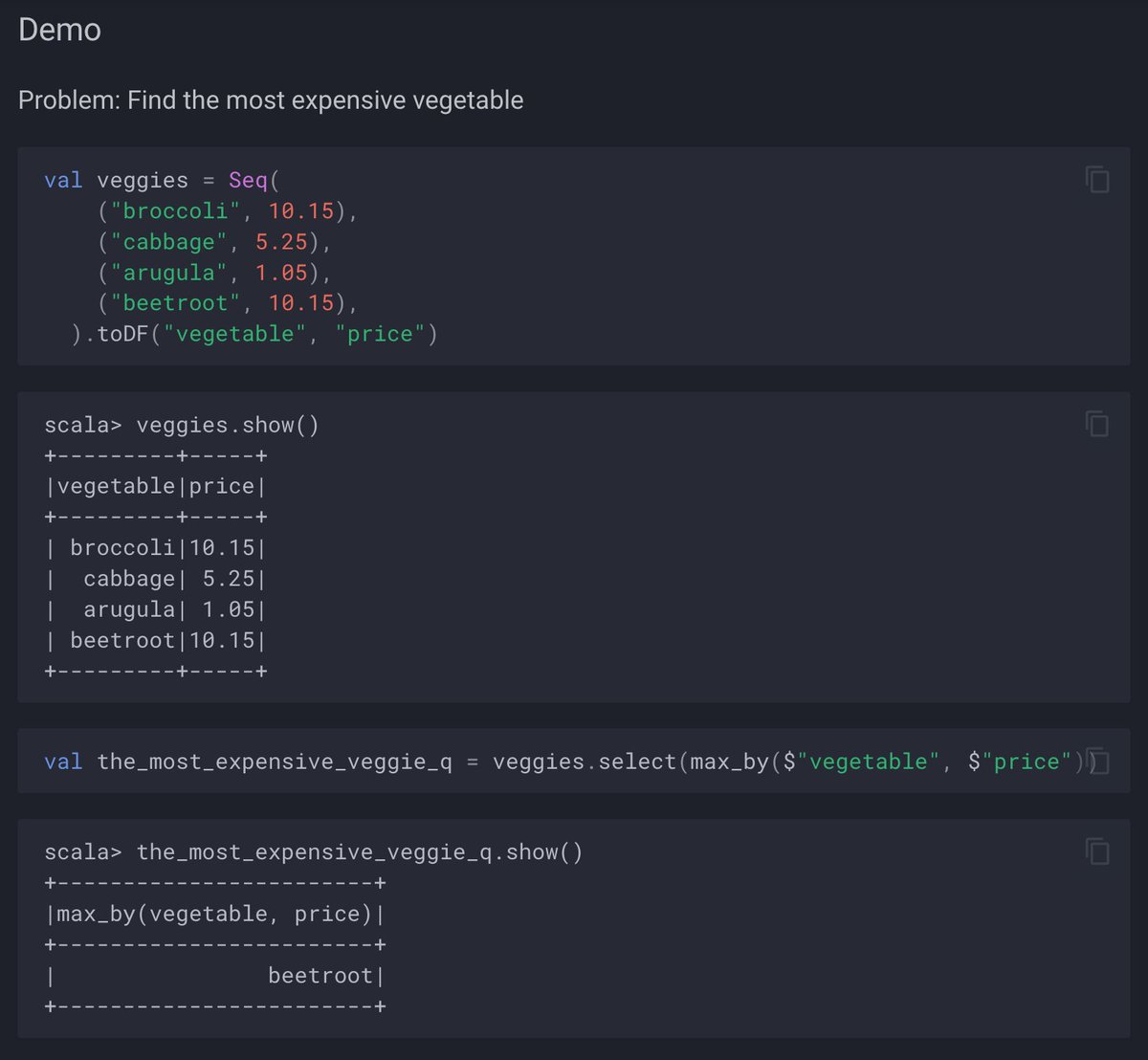
There are quite a few new standard functions in #ApacheSpark #SparkSQL 3.5 alone yet there are way more added in the recent versions. One of them is max_by standard aggregate function that got added as early as in 3.3 🥰 ➡️ books.japila.pl/spark-sql-inte…
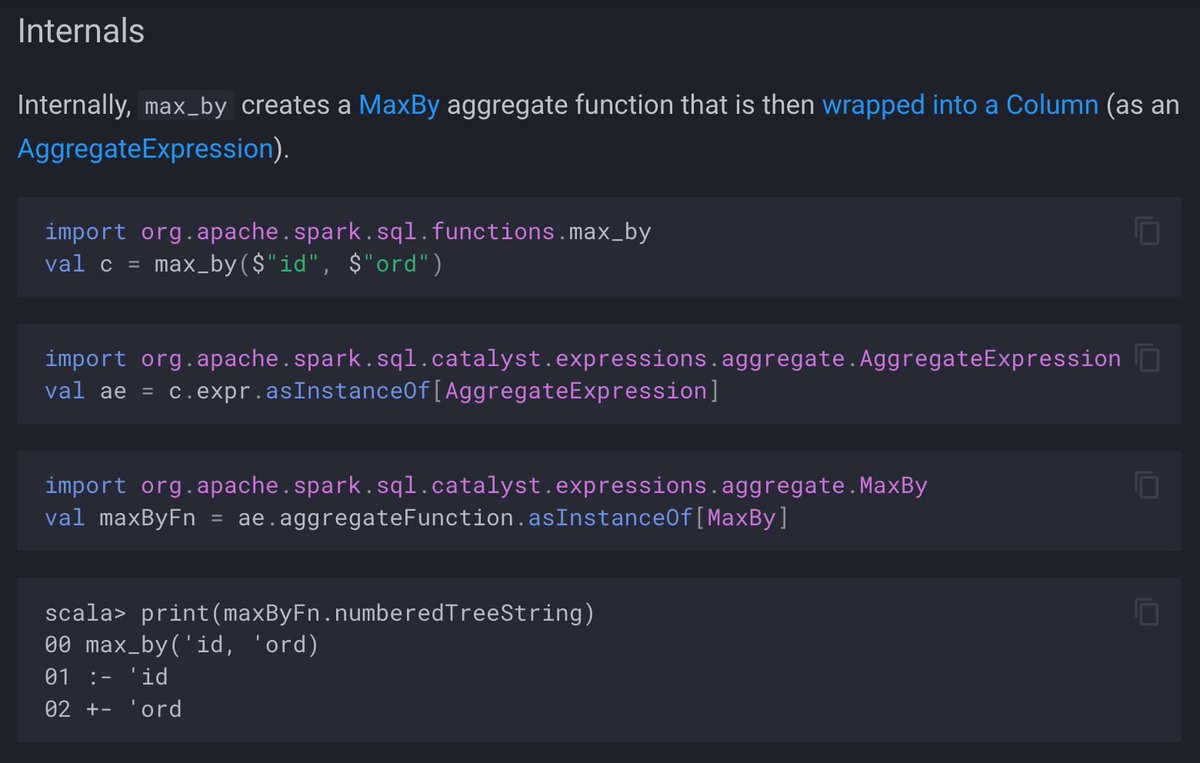
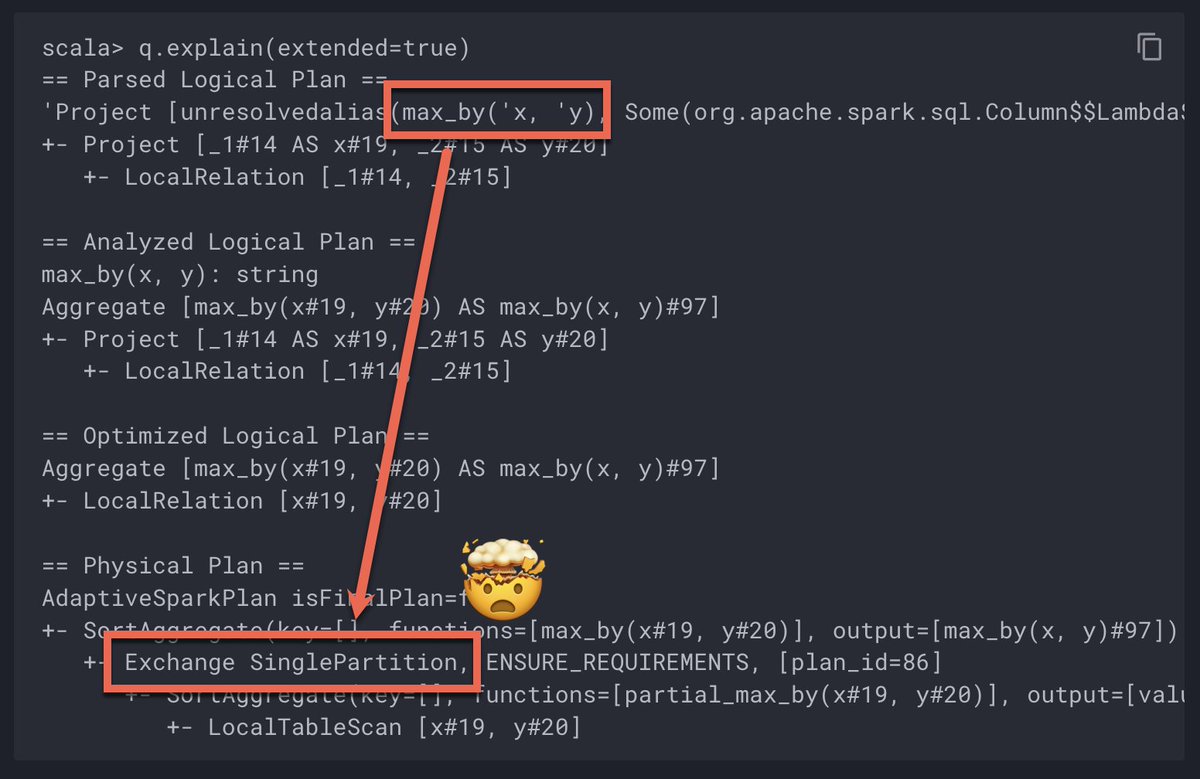
It's exactly 7 days to my talk "Optimizing Batch and Streaming Aggregations" at #DataAISummit and some answers got answered already in The Internals of #SparkSQL 💪 ➡️ databricks.com/dataaisummit/s… ➡️ books.japila.pl/spark-sql-inte… LMK if you've got Qs 🙏 Hoping to prepare myself better 😉




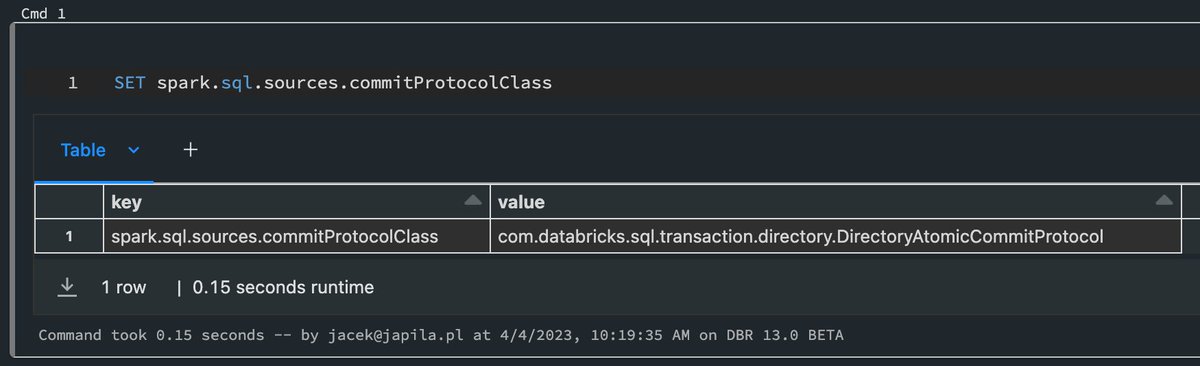
Dunno what I can make out of it, but just found out that s.s.sources.commitProtocolClass is different in #Databricks Runtime 13.0 from #ApacheSpark #SparkSQL 3.4.0. I'm not saying it ever used to be the same either 😏 Something to keep in mind.

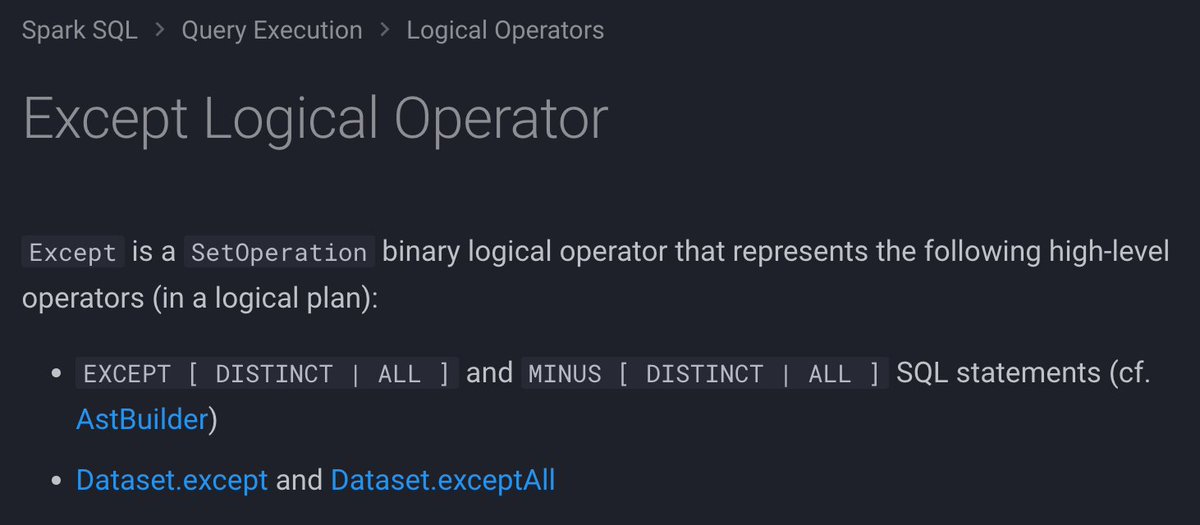
If you're like me always confusing LEFT ANTI vs LEFT SEMI joins, EXCEPT and INTERSECT operators should be easier to remember All available in #ApacheSpark #SparkSQL 🥳 ➡️ books.japila.pl/spark-sql-inte… ➡️ books.japila.pl/spark-sql-inte…


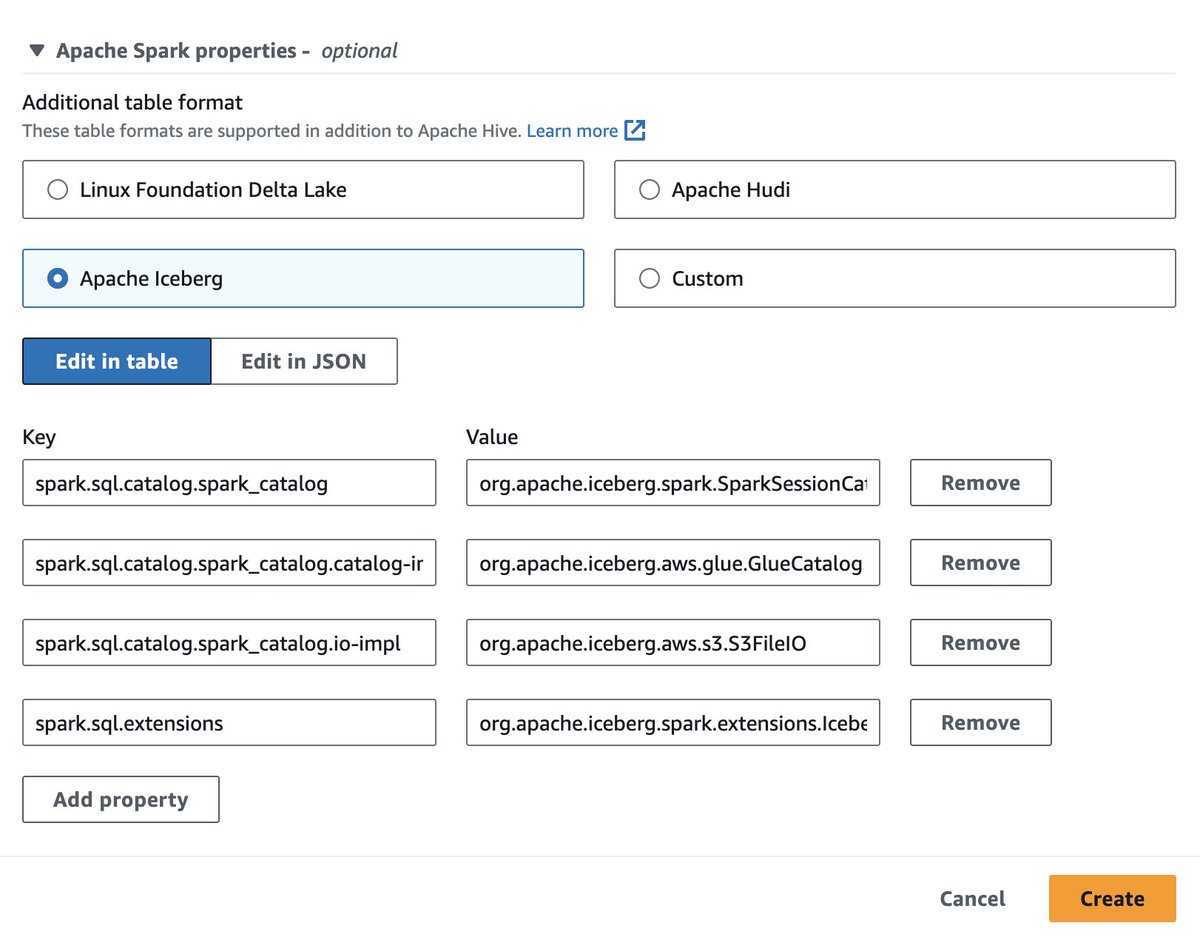
#ApacheIceberg + #SparkSQL = a solid foundation for building #ML systems that work reliably in production. Time travel, schema evolution & ACID transactions address fundamental data management challenges that have plagued ML infrastructure for years. 🔍 bit.ly/46kCCpQ

Even wondered what happens after CREATE [[GLOBAL] TEMPORARY] VIEW AS statement is executed in #ApacheSpark #SparkSQL? Start here ➡️ books.japila.pl/spark-sql-inte… ...and follow along until you know it all or got qqs that I could answer in a follow-up 😉
![jaceklaskowski's tweet image. Even wondered what happens after CREATE [[GLOBAL] TEMPORARY] VIEW AS statement is executed in #ApacheSpark #SparkSQL?
Start here ➡️ books.japila.pl/spark-sql-inte…
...and follow along until you know it all or got qqs that I could answer in a follow-up 😉](https://pbs.twimg.com/media/GLtGJY3XkAA0pOG.jpg)
![jaceklaskowski's tweet image. Even wondered what happens after CREATE [[GLOBAL] TEMPORARY] VIEW AS statement is executed in #ApacheSpark #SparkSQL?
Start here ➡️ books.japila.pl/spark-sql-inte…
...and follow along until you know it all or got qqs that I could answer in a follow-up 😉](https://pbs.twimg.com/media/GLtGSYuXcAAJo6e.jpg)
![jaceklaskowski's tweet image. Even wondered what happens after CREATE [[GLOBAL] TEMPORARY] VIEW AS statement is executed in #ApacheSpark #SparkSQL?
Start here ➡️ books.japila.pl/spark-sql-inte…
...and follow along until you know it all or got qqs that I could answer in a follow-up 😉](https://pbs.twimg.com/media/GLtGYHdWMAA2sWj.jpg)
![jaceklaskowski's tweet image. Even wondered what happens after CREATE [[GLOBAL] TEMPORARY] VIEW AS statement is executed in #ApacheSpark #SparkSQL?
Start here ➡️ books.japila.pl/spark-sql-inte…
...and follow along until you know it all or got qqs that I could answer in a follow-up 😉](https://pbs.twimg.com/media/GLtG7zTWgAAJwyf.jpg)

Use #AmazonAthena with #SparkSQL for your #OpenSource transactional table formats 👉 go.aws/4bco23u #AWS #Cloud #CloudComputing #CloudOps #Serverless #Analytics #DataLake #Innovation #DigitalTransformation

"Discover the power of Spark SQL for smart data manipulation in Python. Learn how it simplifies distributed computing and offers efficient in-memory computation. #DataManipulation #SparkSQL" ift.tt/0MHzVs4


✨New Video: In this follow-up video to the last video, we considered how to quary data using the traditional SQL language by switching from PySpark to Spark SQL . Watch Here: youtu.be/xwXOKotycJ4 #AzureDatabricks #PySpark #SparkSQL #BigData #DataProcessing

Something went wrong.
Something went wrong.
United States Trends
- 1. Jake Paul 173K posts
- 2. Bama 38.7K posts
- 3. Oklahoma 64.1K posts
- 4. #RollTide 17.2K posts
- 5. Mateer 12K posts
- 6. Ryan Williams 3,712 posts
- 7. Rose Bowl 4,765 posts
- 8. #boxing 8,444 posts
- 9. #CFBPlayoff 15.5K posts
- 10. Clinton 228K posts
- 11. 6ix9ine 5,089 posts
- 12. Epstein 1.17M posts
- 13. Wolves 20.4K posts
- 14. Ty Simpson 6,094 posts
- 15. KO'd 8,327 posts
- 16. Tyson Fury 3,391 posts
- 17. Hulk Hogan 2,682 posts
- 18. Finch 7,843 posts
- 19. Dort 9,396 posts
- 20. Woodley 17.5K posts