#sparksql ผลการค้นหา



Learning #SparkSQL! #BigData #Analytics #DataScience #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux #Books #Programming #Coding #100DaysofCode geni.us/Learning-Spark…


Day 46 of my #buildinginpublic journey into Data Engineering Learned how to combine SQL + PySpark for large-scale analytics Created RDDs Ran SQL queries on DataFrames Performed complex aggregations Used broadcasting for optimization of joins #PySpark #SparkSQL #BigData
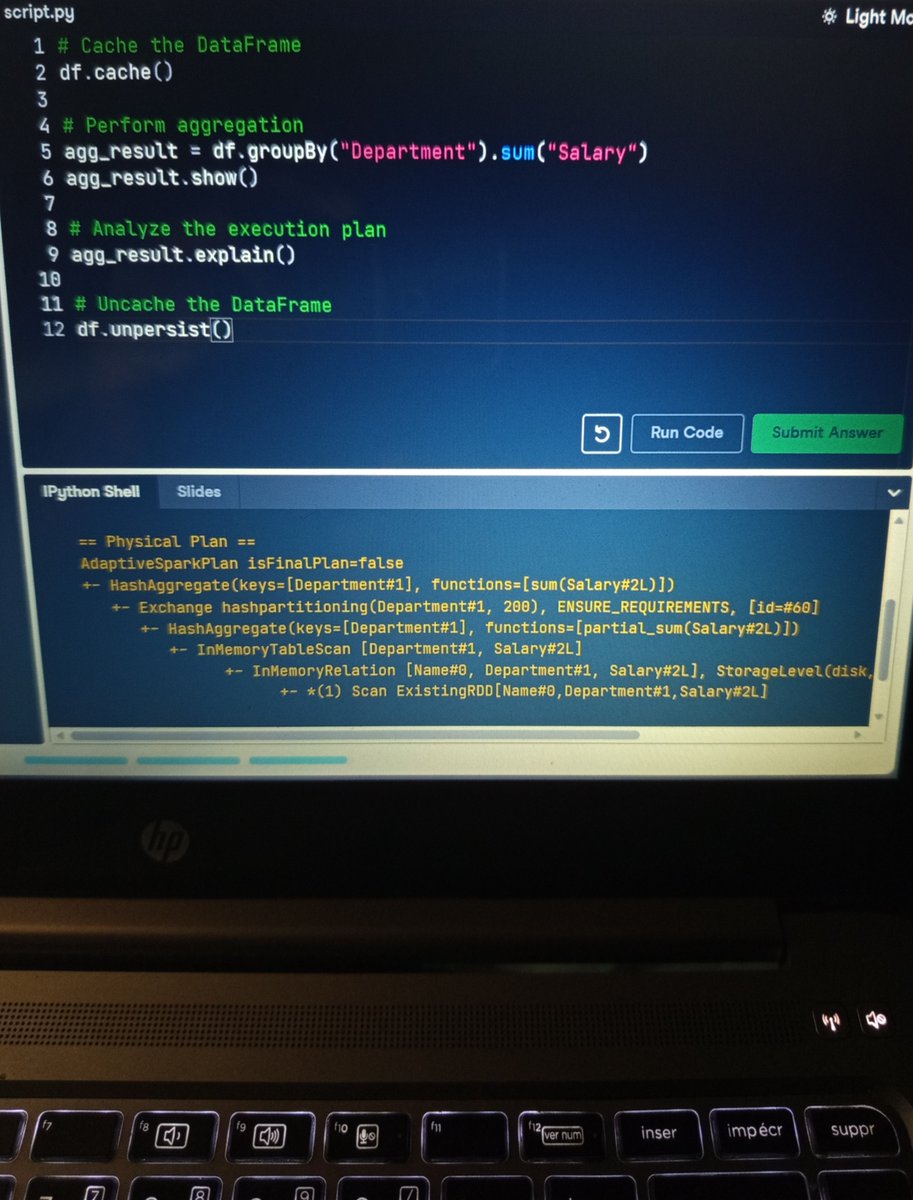


Gluten And Intel CPUs Boost Apache Spark SQL Performance Read more on govindhtech.com/performance-of… #Gluten #IntelCPUs #SparkSQL #SQL #ApacheSpark #Spark #IntelXeonScalableProcessors #Glutenplugin #machinelearning #News #Technews #Technology #Technologynews #Technologytrends…

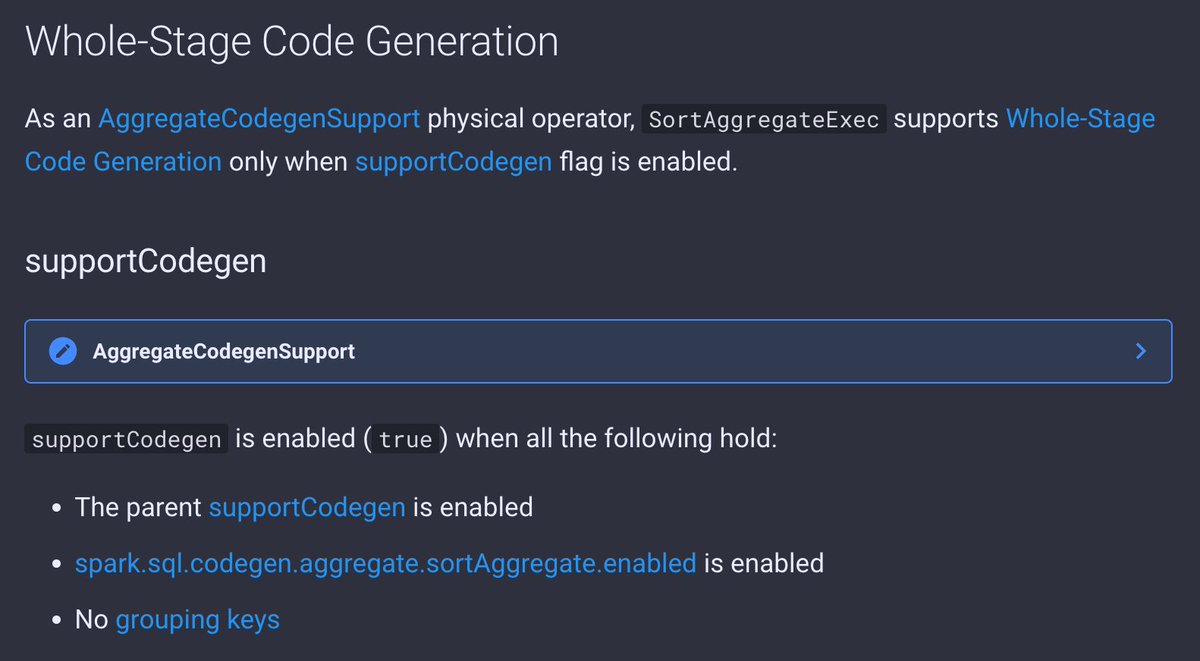
This should give you an idea of why SortBasedAggregationIterator is so important to the "slowest" SortAggregateExec operator In other words, SortBasedAggregationIterator is SortAggregateExec #ApacheSpark #SparkSQL


The individual steps seem insignificant when isolated, but when all the puzzle pieces align; it'll be evidence that all of the hard work is not in vain. #ForwardProgress #SparkSQL #BigData #HardWorkPaysOff

Decrease Price of Intel Spark SQL Workloads On Google Cloud Read more on govindhtech.com/decrease-price… #GoogleCloud #IntelSparkSQL #SparkSQL #AI #ApacheSparkSQL #GoogleCloudinstances #AImodels #vCPU #C3Dinstance #IntelXeonScalableprocessors #News #Technews #Technology #Technologynews…


What is SPARK SQL? Spark SQL is Apache Spark’s module for working with structured or semi data. #shiashinfosolutions #SparkSQL #ApacheSpark #BigData #programming #StructuredData

WHY SPARK? Readability Expressiveness Fast Testability Interactive Fault Tolerant Unify Big Data #shiashinfosolutions #SparkSQL #ApacheSpark #BigData #programming #StructuredData #whyspark

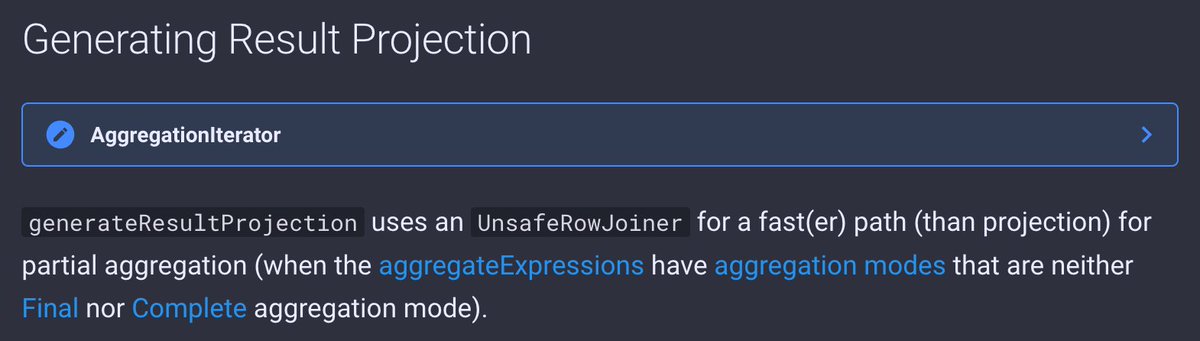
5 days to @Data_AI_Summit ❤️ I thought I knew enough to have a talk at #DataAISummit 🤨 Now I'm on the verge of bringing you more Qs than answers and it's all live on stage 😬 More on AggregationIterators in #SparkSQL ➡️ books.japila.pl/spark-sql-inte…



FEATURES OF SPARK? Integrated Scalability Unified Data Access High Compatibility Standard Connectivity Performance Optimization For Batch Processing of Hive Tables #shiashinfosolutions #SparkSQL #ApacheSpark #BigData #programming #StructuredData #SparkFeatures

Advantages of Spark SQL Integrated Standard Connectivity High Compatibility Unified Data Access Scalability Performance Optimization Batch Processing of hive tables #shiashinfosolutions #SparkSQL #ApacheSpark #BigData #programming #StructuredData #AdvantagesofSpark #unifieddata


#ApacheIceberg + #SparkSQL = a solid foundation for building #ML systems that work reliably in production. Time travel, schema evolution & ACID transactions address fundamental data management challenges that have plagued ML infrastructure for years. 🔍 bit.ly/46kCCpQ

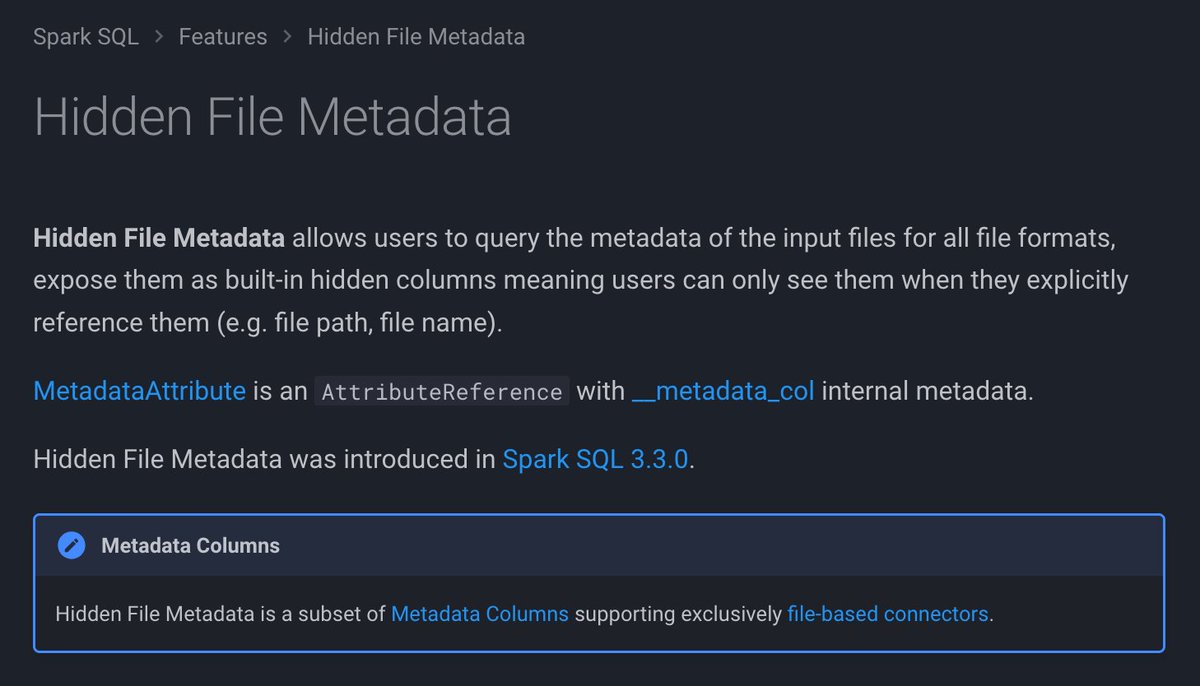
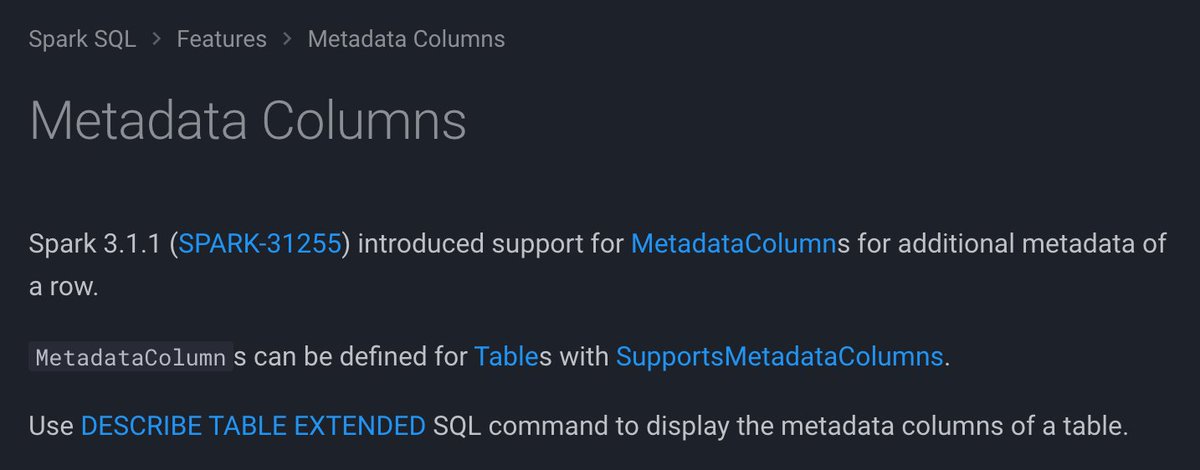
Two new metadata schema columns in #ApacheSpark #SparkSQL: 1⃣ Metadata Columns ➡️ http://localhost:8000/spark-sql-internals/metadata-columns/ 2⃣ Hidden File Metadata ➡️ http://localhost:8000/spark-sql-internals/hidden-file-metadata/ Different code paths, yet so similar 🤷♂️

🚀 Boost your #PySpark career with expert Job Support Online & Proxy Support! 💻 Get real-time help with #SparkSQL, #DataFrames, & #BigData projects. DM for 1:1 guidance today! 🔗tinyurl.com/pysparkIGSJS #PySparkJobSupport #PySparkProxyJobSupport #DataEngineering #ApacheSpark

Ever wondered what happens when you execute CACHE TABLE AS command in #ApacheSpark #SparkSQL? 🤔 Curious if it's for tables only? Views too? It all boils down to CacheTableAsSelectExec physical operator that uses high-level ones like we all do! 🥳 ➡️ books.japila.pl/spark-sql-inte…




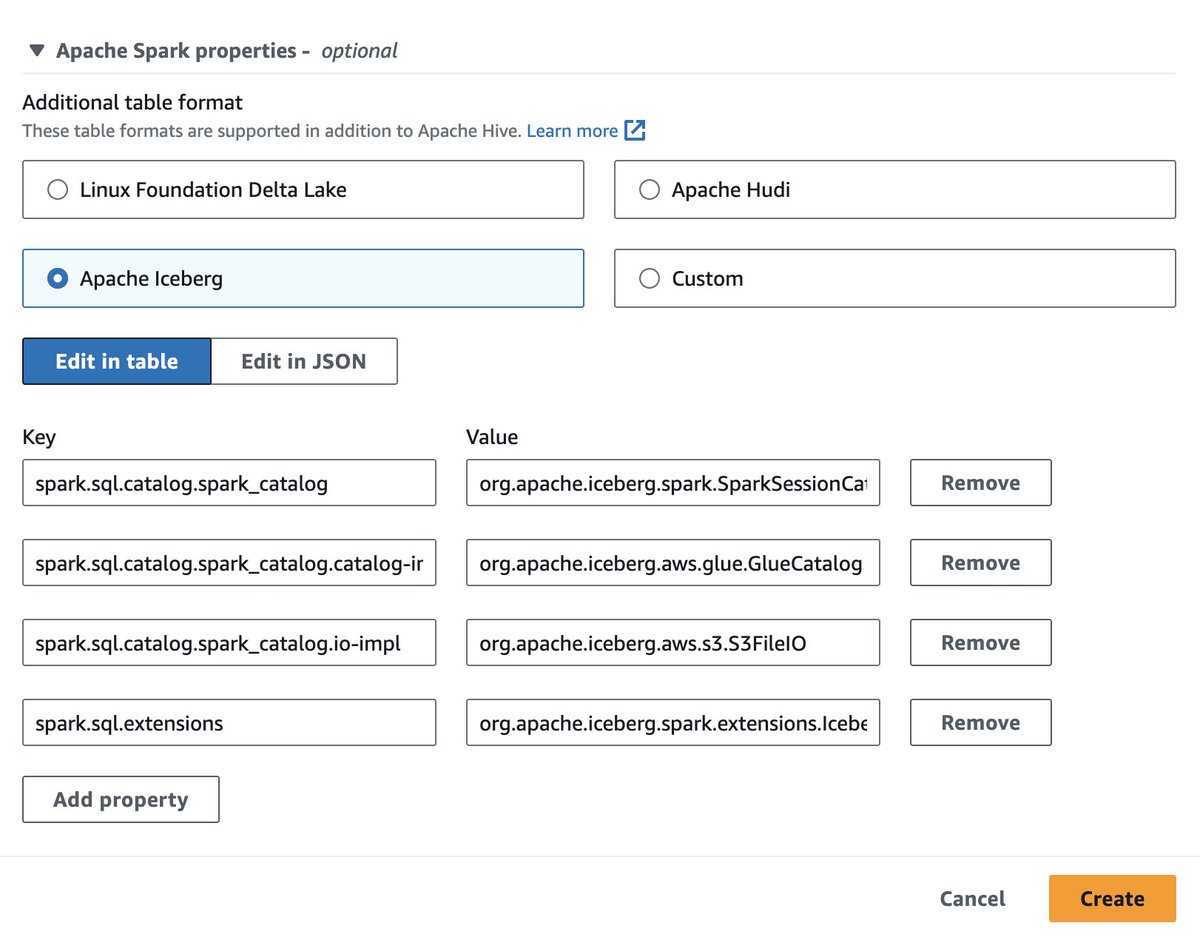
Use #AmazonAthena with #SparkSQL for your #OpenSource transactional table formats 👉 go.aws/4bco23u #AWS #Cloud #CloudComputing #CloudOps #Serverless #Analytics #DataLake #Innovation #DigitalTransformation
6 days to #DataAISummit 2023 so more updates to The Internals of #SparkSQL and, more importantly, aggregations 💪 Today focusing on the "slowest" aggregate operator SortAggregateExec and SortBasedAggregationIterator 👍 ➡️ books.japila.pl/spark-sql-inte… ➡️ books.japila.pl/spark-sql-inte…



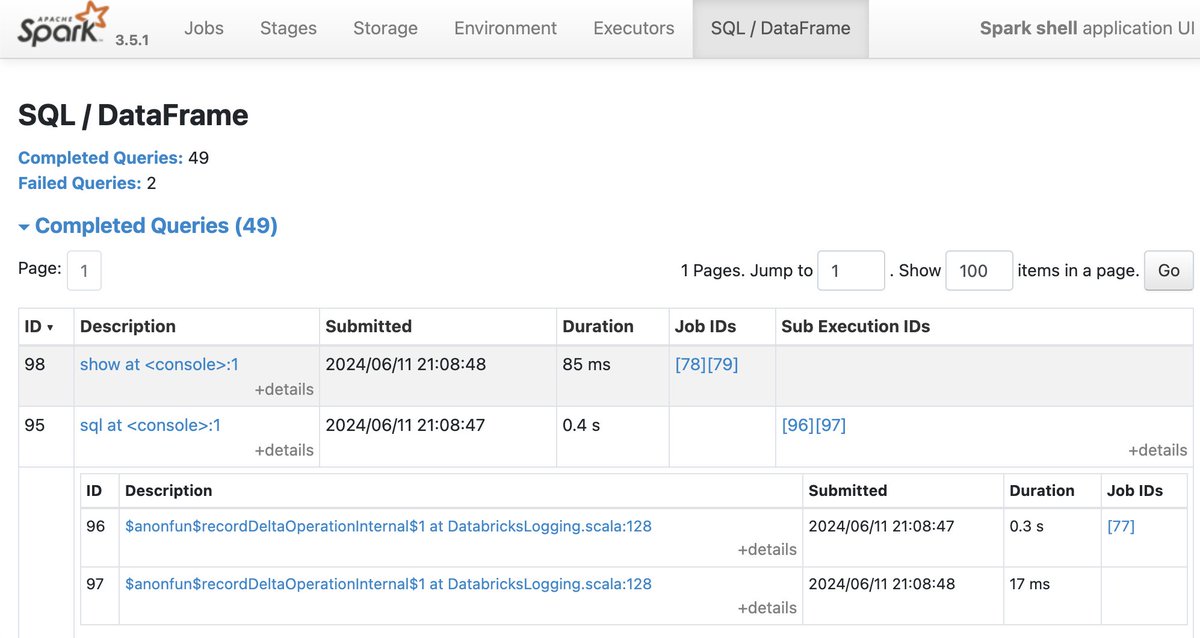
#TIL Sub Execution IDs is a #SparkSQL feature in web UI (not #Databricks-specific as I always thought) 🥳 Any good docs on the feature? 🤔 #ApacheSpark
It's exactly 7 days to my talk "Optimizing Batch and Streaming Aggregations" at #DataAISummit and some answers got answered already in The Internals of #SparkSQL 💪 ➡️ databricks.com/dataaisummit/s… ➡️ books.japila.pl/spark-sql-inte… LMK if you've got Qs 🙏 Hoping to prepare myself better 😉




Something went wrong.
Something went wrong.
United States Trends
- 1. #WWENXT 6,632 posts
- 2. Queen Naija N/A
- 3. Knicks 22.5K posts
- 4. Vanity Fair 89.5K posts
- 5. Thea 7,749 posts
- 6. Mary and Joseph 6,908 posts
- 7. Susie Wiles 169K posts
- 8. Canelo 3,287 posts
- 9. #NBACup 2,220 posts
- 10. Mustapha Kharbouch 63K posts
- 11. Blake Monroe 2,636 posts
- 12. Terence Crawford 16.9K posts
- 13. Lipscomb 1,023 posts
- 14. #RHAPMafia N/A
- 15. Adam Silver 1,200 posts
- 16. Larian 17.1K posts
- 17. Olive Garden 2,188 posts
- 18. #doordashfairy 1,432 posts
- 19. Ament N/A
- 20. Morgan Geekie N/A