#tensorrtllm resultados de búsqueda

ローカル/社内LLMの実運用は「NVIDIA Triton Inference Server+TensorRT-LLM」が堅実。 TRT-LLM Backend+NGCでエンジン化→Triton配備。MIG・KVキャッシュ・量子化・LoRAで性能/コスト最適化。#TensorRTLLM #Triton docs.nvidia.com/deeplearning/t…

@Apple working with @nvidia to improve the speed of #TensorRTLLM by almost a favor of 3x was not on my bingo card for 2024. machinelearning.apple.com/research/redra…


Accelerate time to first token with NVIDIA TensorRT-LLM KV cache early reuse techniques! Learn how to optimize KV cache for faster response times. #TensorRTLLM #KVCacheReuse #NVIDIA #AI #Efficiency" developer.nvidia.com/blog/5x-faster…
developer.nvidia.com
5x Faster Time to First Token with NVIDIA TensorRT-LLM KV Cache Early Reuse | NVIDIA Technical Blog
In our previous blog post, we demonstrated how reusing the key-value (KV) cache by offloading it to CPU memory can accelerate time to first token (TTFT) by up to 14x on x86-based NVIDIA H100 Tensor…

Is TensorRT Acceleration Coming For Stable Diffusion 3 Read more on govindhtech.com/is-tensorrt-ac… #tensorrt #tensorrtllm #nvidia #govindhtech #aimodel #stablediffusion #stablediffusion3 #rtxgpus @nvidia @TechGovind70399


#NVIDIA announces TensorRT-LLM release for Windows, accelerating AI inference performance and adding support for new models. #AI #TensorRTLLM #Windows11 #Inference #Developers blogs.nvidia.com/blog/ignite-rt…


📰 TENSORRT-LLM PARA WINDOWS ACELERA O DESEMPENHO DE IA GENERATIVA EM GPUS GEFORCE RTX 🔗 samirnews.com/2023/10/tensor… #SamirNews #tensorrtllm #para #windows #acelera #o #desempenho #de #ia #generativa #em #gpus #geforce #rtx

Exciting news! NVIDIA TensorRT-LLM now accelerates encoder-decoder models, expanding its capabilities for generative AI applications on NVIDIA GPUs. #AI #NVIDIA #TensorRTLLM developer.nvidia.com/blog/nvidia-te…

NVIDIA H100 GPU と TensorRT-LLM が Mixtral 8x7B で画期的なパフォーマンスを実現 - Blockchain.News #NVIDIA #TensorRTLLM #Mixtral #H100GPU prompthub.info/23042/
NVIDIA TensorRT-LLM がインフライト バッチ処理でエンコーダー/デコーダー モデルを強化 - Blockchain.News #TensorRTLLM #GenerativeAI #NVIDIAGPUs #AIApplications prompthub.info/75991/
NVIDIA の TensorRT-LLM は KV キャッシュの早期再利用により AI の効率を向上 - Blockchain.News #NVIDIA #TensorRTLLM #KVcache #AIperformance prompthub.info/64728/
Nvidia Jetson AGX Orin で TensorRT-LLM を使用して LLM を実行する - Hackster.io #TensorRTLLM #NvidiaJetsonAGXOrin #LargeLanguageModels #InferenceOptimization prompthub.info/70047/
prompthub.info
Nvidia Jetson AGX Orin で TensorRT-LLM を使用して LLM を実行する – Hackster.io - プロンプトハブ
Large Language Models (LLMs)をデプロイするためにTensorRT-LLMを使用する
NVIDIA の TensorRT-LLM マルチブロック アテンションが HGX H200 の AI 推論を強化 - Blockchain.News #NVIDIA #TensorRTLLM #AIInference #MultiblockAttention prompthub.info/69192/
prompthub.info
NVIDIA の TensorRT-LLM マルチブロック アテンションが HGX H200 の AI 推論を強化 – Blockchain.News - プロンプトハブ
要約 NVIDIAのTensorRT-LLMは、マルチブロックアテンションを導入し、長いシーケンスにおけるAI
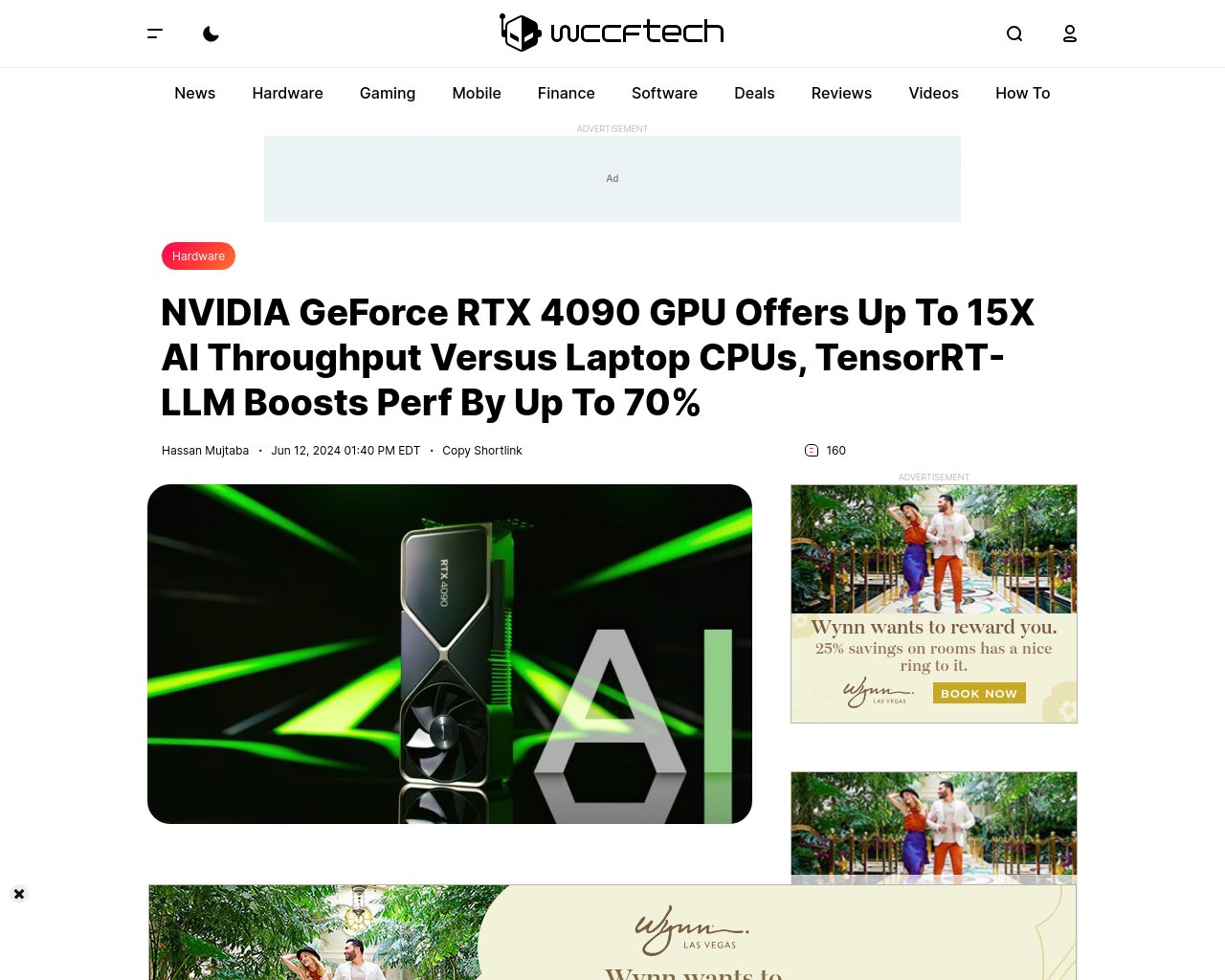
RTX 4090: ノート PC の CPU と比較して最大 15 倍の速度向上と TensorRT-LLM による 70% のパフォーマンス向上を実現した AI の驚異的な武器! | igor´sLAB #NVIDIA #GeForceRTX #TensorRTLLM #AIinnovation prompthub.info/15390/
prompthub.info
RTX 4090: ノート PC の CPU と比較して最大 15 倍の速度向上と TensorRT-LLM による 70% のパフォーマンス向上を実現した AI の驚異的な武器! |...
NVIDIAのGeForce RTX 40 GPUシリーズは、LlamaおよびMistral AIベンチマーク
NVIDIA GeForce RTX 4090 GPU はノート PC の CPU と比較して最大 15 倍の AI スループットを実現し、TensorRT-LLM はパフォーマンスを最大 70% 向上します。 #NVIDIAAI #GeForceRTX40 #TensorRTLLM #AIacceleration prompthub.info/15169/
NVIDIA の TensorRT-LLM MultiShot が NVSwitch で AllReduce のパフォーマンスを向上 - Blockchain.News #TensorRTLLM #MultiGPU #NVSwitch #AICommunication prompthub.info/62545/

Prędkość spotyka wydajność! 🚀 NVIDIA TensorRT-LLM, potężne narzędzie optymalizacji, teraz dostępne za darmo! Nie przegap szansy na przyspieszenie swoich projektów #AI. Sprawdź darmową bibliotekę bit.ly/465m7do #NVIDIA #TensorRTLLM #OptymalizacjaAI #Technologia

"ChatRTX Adds New AI Models, Features in Latest Update" blogs.nvidia.com/blog/ai-decode… #NVIDIA #TensorRT #TensorRTLLM #RTX #NVIDIARTX #PC #Windows #LLM #ChatRTX #NVIDIAGeforce #AI #ArtificialIntelligence #IA #InteligenciaArtificial #DLSS #Omniverse #MachineLearning


Breaking: Gemma 7B has been successfully deployed with TensorRT-LLM, achieving over 500 tokens per second, marking a milestone in advanced AI processing speed. #AI #Gemma7B #TensorRTLLM bit.ly/3T7f9RZ
docs.mystic.ai
Deploy Google's Gemma with TensorRT
A guide that shows how to deploy LLMs, specifically Google's Gemma with TensorRT on Mystic's deployment platform

GeForce RTX 4090 GPU 性能強悍!NVIDIA TensorRT-LLM 加速 Windows AI 效能,超越整個 NPU 生態系統。 #NVIDIA #TensorRTLLM #AI dlvr.it/T8CLpD

ローカル/社内LLMの実運用は「NVIDIA Triton Inference Server+TensorRT-LLM」が堅実。 TRT-LLM Backend+NGCでエンジン化→Triton配備。MIG・KVキャッシュ・量子化・LoRAで性能/コスト最適化。#TensorRTLLM #Triton docs.nvidia.com/deeplearning/t…

Introducing AutoDeploy for TensorRT-LLM from @nvidia – a new feature that simplifies the off‑the‑shelf deployment of cutting‑edge LLMs. #Nvidia #TensorRTLLM #AutoDeploy
@Apple working with @nvidia to improve the speed of #TensorRTLLM by almost a favor of 3x was not on my bingo card for 2024. machinelearning.apple.com/research/redra…
Exciting news! NVIDIA TensorRT-LLM now accelerates encoder-decoder models, expanding its capabilities for generative AI applications on NVIDIA GPUs. #AI #NVIDIA #TensorRTLLM developer.nvidia.com/blog/nvidia-te…
NVIDIA TensorRT-LLM がインフライト バッチ処理でエンコーダー/デコーダー モデルを強化 - Blockchain.News #TensorRTLLM #GenerativeAI #NVIDIAGPUs #AIApplications prompthub.info/75991/
Nvidia Jetson AGX Orin で TensorRT-LLM を使用して LLM を実行する - Hackster.io #TensorRTLLM #NvidiaJetsonAGXOrin #LargeLanguageModels #InferenceOptimization prompthub.info/70047/
prompthub.info
Nvidia Jetson AGX Orin で TensorRT-LLM を使用して LLM を実行する – Hackster.io - プロンプトハブ
Large Language Models (LLMs)をデプロイするためにTensorRT-LLMを使用する
NVIDIA の TensorRT-LLM マルチブロック アテンションが HGX H200 の AI 推論を強化 - Blockchain.News #NVIDIA #TensorRTLLM #AIInference #MultiblockAttention prompthub.info/69192/
prompthub.info
NVIDIA の TensorRT-LLM マルチブロック アテンションが HGX H200 の AI 推論を強化 – Blockchain.News - プロンプトハブ
要約 NVIDIAのTensorRT-LLMは、マルチブロックアテンションを導入し、長いシーケンスにおけるAI
Accelerate time to first token with NVIDIA TensorRT-LLM KV cache early reuse techniques! Learn how to optimize KV cache for faster response times. #TensorRTLLM #KVCacheReuse #NVIDIA #AI #Efficiency" developer.nvidia.com/blog/5x-faster…
developer.nvidia.com
5x Faster Time to First Token with NVIDIA TensorRT-LLM KV Cache Early Reuse | NVIDIA Technical Blog
In our previous blog post, we demonstrated how reusing the key-value (KV) cache by offloading it to CPU memory can accelerate time to first token (TTFT) by up to 14x on x86-based NVIDIA H100 Tensor…
NVIDIA の TensorRT-LLM は KV キャッシュの早期再利用により AI の効率を向上 - Blockchain.News #NVIDIA #TensorRTLLM #KVcache #AIperformance prompthub.info/64728/
NVIDIA の TensorRT-LLM MultiShot が NVSwitch で AllReduce のパフォーマンスを向上 - Blockchain.News #TensorRTLLM #MultiGPU #NVSwitch #AICommunication prompthub.info/62545/
NVIDIA H100 GPU と TensorRT-LLM が Mixtral 8x7B で画期的なパフォーマンスを実現 - Blockchain.News #NVIDIA #TensorRTLLM #Mixtral #H100GPU prompthub.info/23042/
RTX 4090: ノート PC の CPU と比較して最大 15 倍の速度向上と TensorRT-LLM による 70% のパフォーマンス向上を実現した AI の驚異的な武器! | igor´sLAB #NVIDIA #GeForceRTX #TensorRTLLM #AIinnovation prompthub.info/15390/
prompthub.info
RTX 4090: ノート PC の CPU と比較して最大 15 倍の速度向上と TensorRT-LLM による 70% のパフォーマンス向上を実現した AI の驚異的な武器! |...
NVIDIAのGeForce RTX 40 GPUシリーズは、LlamaおよびMistral AIベンチマーク
Is TensorRT Acceleration Coming For Stable Diffusion 3 Read more on govindhtech.com/is-tensorrt-ac… #tensorrt #tensorrtllm #nvidia #govindhtech #aimodel #stablediffusion #stablediffusion3 #rtxgpus @nvidia @TechGovind70399
GeForce RTX 4090 GPU 性能強悍!NVIDIA TensorRT-LLM 加速 Windows AI 效能,超越整個 NPU 生態系統。 #NVIDIA #TensorRTLLM #AI dlvr.it/T8CLpD
NVIDIA GeForce RTX 4090 GPU はノート PC の CPU と比較して最大 15 倍の AI スループットを実現し、TensorRT-LLM はパフォーマンスを最大 70% 向上します。 #NVIDIAAI #GeForceRTX40 #TensorRTLLM #AIacceleration prompthub.info/15169/
"ChatRTX Adds New AI Models, Features in Latest Update" blogs.nvidia.com/blog/ai-decode… #NVIDIA #TensorRT #TensorRTLLM #RTX #NVIDIARTX #PC #Windows #LLM #ChatRTX #NVIDIAGeforce #AI #ArtificialIntelligence #IA #InteligenciaArtificial #DLSS #Omniverse #MachineLearning
Is TensorRT Acceleration Coming For Stable Diffusion 3 Read more on govindhtech.com/is-tensorrt-ac… #tensorrt #tensorrtllm #nvidia #govindhtech #aimodel #stablediffusion #stablediffusion3 #rtxgpus @nvidia @TechGovind70399

.@nvidia annonce #TensorRTLLM, sa bibliothèque #opensource pour accélérer le développement de l’#IA itsocial.fr/actualites/nvi…

@Apple working with @nvidia to improve the speed of #TensorRTLLM by almost a favor of 3x was not on my bingo card for 2024. machinelearning.apple.com/research/redra…
Something went wrong.
Something went wrong.
United States Trends
- 1. $NVDA 80.8K posts
- 2. Jensen 26K posts
- 3. Peggy 39.5K posts
- 4. GeForce Season 6,091 posts
- 5. NASA 56.4K posts
- 6. #YIAYalpha N/A
- 7. Stargate 7,519 posts
- 8. Sumrall 2,551 posts
- 9. Arabic Numerals 5,251 posts
- 10. Sam Harris N/A
- 11. Martha 20.7K posts
- 12. Judge Smith 3,933 posts
- 13. Comey 60.2K posts
- 14. #WWESuperCardNewSeason 1,240 posts
- 15. #2Kgiveaway 1,223 posts
- 16. #WickedWaysToMakeABuck N/A
- 17. Kwame 6,687 posts
- 18. Poverty 55.8K posts
- 19. Saba 11.2K posts
- 20. WNBA 9,851 posts