#tensorrt resultados da pesquisa

I broke my record 🎉 by using #TensorRT 🔥 with @diffuserslib T4 GPU on 🤗 @huggingface 512x512 50 steps 6.6 seconds (xformers) to 4.57 seconds 🎉 I will make more tests clean up the code, and make it open-source 🐣


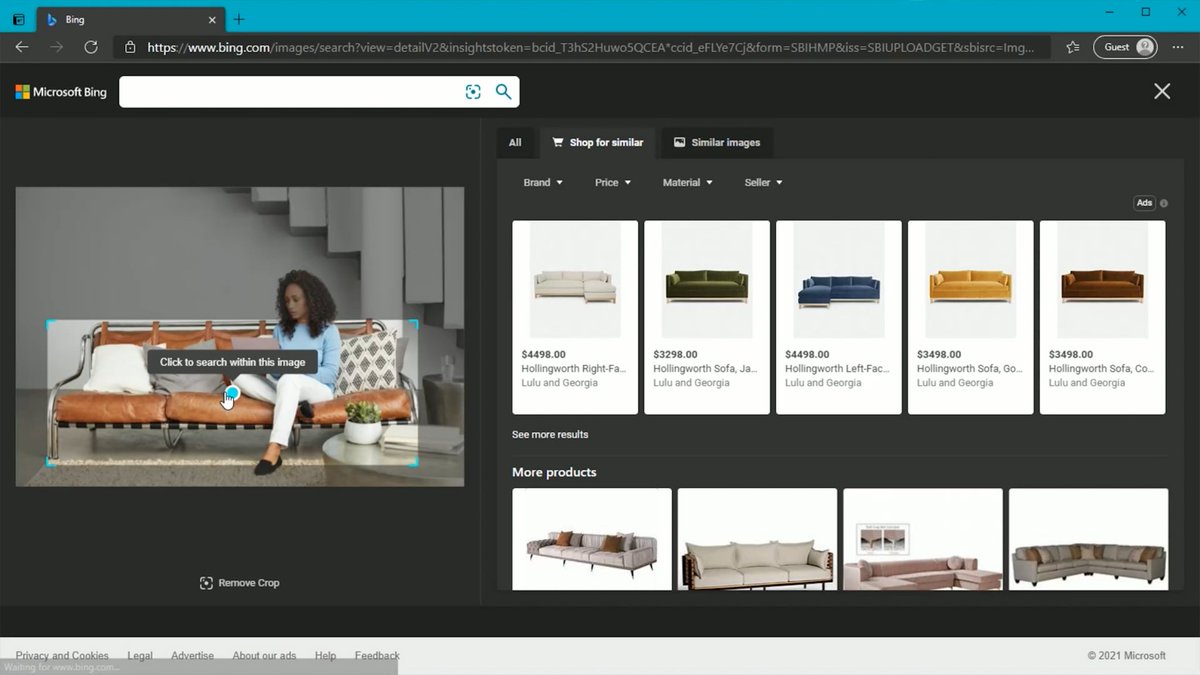
👀 Learn how the #Microsoft Bing Visual Search team leveraged #TensorRT, CV-CUDA and nvImageCodec from #NVIDIA to optimize their TuringMM visual embeddings pipeline, achieving 5.13x throughput speedup and significant TCO reduction. ➡️ nvda.ws/4dHj9Qd #visualai
🖼️ Ready for next-level image generation? @bfl_ml's FLUX.1 image generation model suite -- built on the Diffusion Transformer (DiT) architecture, and trained on 12 billion parameters -- is now accelerated by #TensorRT and runs the fastest ⚡️on NVIDIA RTX AI PCs. 🙌 Learn more…



TensorRTですが、なんとか動くようになりましたが、画像生成そのものは早いですが、Hires.fixやI2IでのMultiDiffusionはそこそこな感じ?💦 あと、なぜかLoRA変換しても効かないとか、MultiDiffusionがEulaに勝手になるとか、ちょっと問題ありそうです😰 #TensorRT #StableDifffusion #AIArt

TensorRTでモデルが変換できなかった件、どうもmodelを階層管理してるとダメっぽい。 modelフォルダのルートにファイルを置いたら変換された😇 試したら、Hires.fix後の解像度も必要になるとのことで、ぶるぺんさんの記事のように256-(512)-1536までの解像度が必要そう。 #TensorRT #StableDiffusion

ネット記で、Stable Diffusionの画像生成が高速化される拡張機能が出たとのこと! ...というわけで、ぶるぺんさんの記事などを参考に、TensorRTのインストールを行って、モデルの変換に失敗...😰 起動時にもエラーが出るため、あきらめて拡張機能を無効化してひとまず敗北😥 #TensorRT #StableDiffusion




Our latest benchmarks show the unmatched efficiency of @NVIDIAAI #TensorRT LLM, setting a new standard in AI performance 🚀 Discover the future of real-time #AI Apps with reduced latency & enhanced speed by reading our latest technical deep dive 👇🔍 fetch.ai/blog/unleashin…

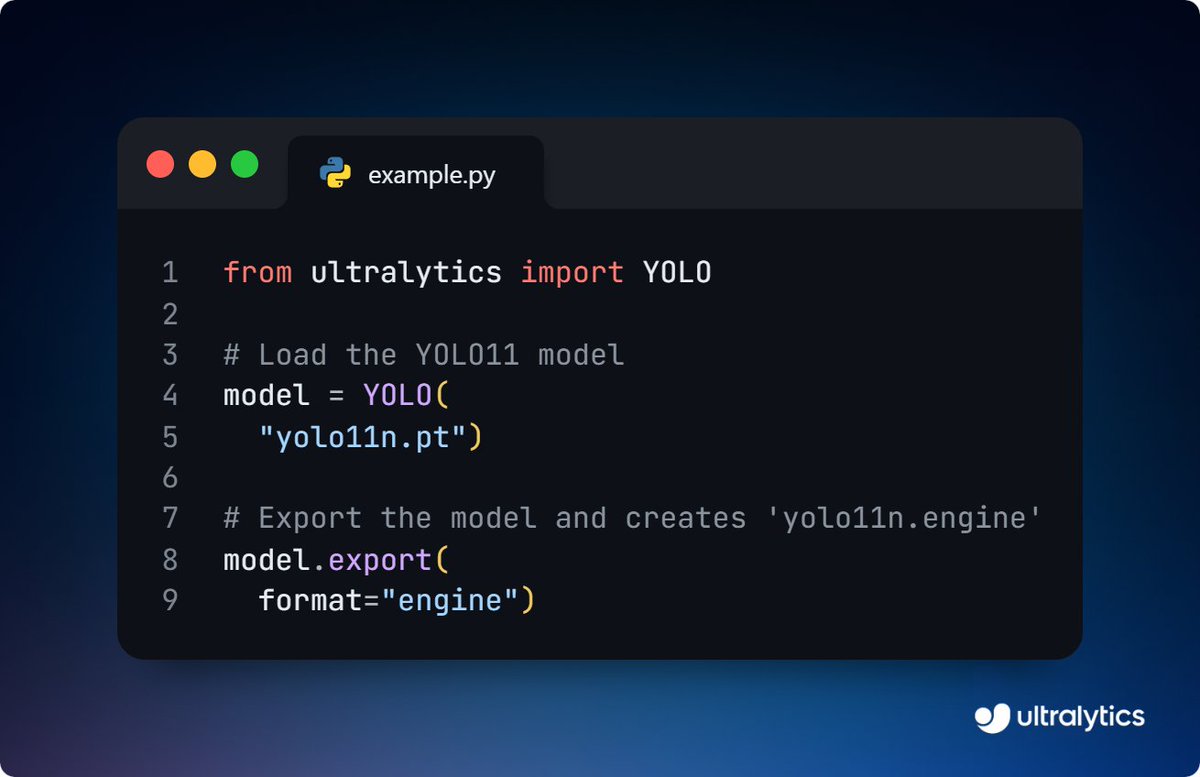
Speed up Ultralytics YOLO11 inference with TensorRT export!⚡ Export YOLO11 models to TensorRT for faster performance and greater efficiency. It's ideal for running computer vision projects on edge devices while saving resources. Learn more ➡️ ow.ly/Xu1f50UFUCm #TensorRT
🙌 We hope to see you at the next #TensorRT #LLM night in San Francisco. ICYMI last week, here is our presentation ➡️ nvda.ws/4dj18Y0

We leverage @NVIDIAAI's #TensorRT to optimize LLMs, boosting efficiency & performance for real-time AI applications 🤖 Discover the breakthroughs making our AI platforms smarter and faster by diving into our technical deep dive blog below!👇🔍 fetch.ai/blog/advancing…

Super cool news 🥳 Thanks to @ddPn08 ❤ #TensorRT 🔥 working pretty good on 🤗 @huggingface 🤯 T4 GPU 512x512 20 steps 2 seconds 🚀 I will make more tests clean up the code, and make it public space 🐣 please give star ⭐ to @ddPn08 🥰 github.com/ddPn08/Lsmith
TensorRT試してみた、爆速だけど制約多すぎ、とりあえずWildcardsでぶん回すには良いかも!! ちなみに「cudnn_adv_infer64_8.dll」が見つからんと言われるんだけど最新入れても変わらず、まぁ動くからいいけど。 #stablediffusion #TensorRT #AIart #AIグラビア




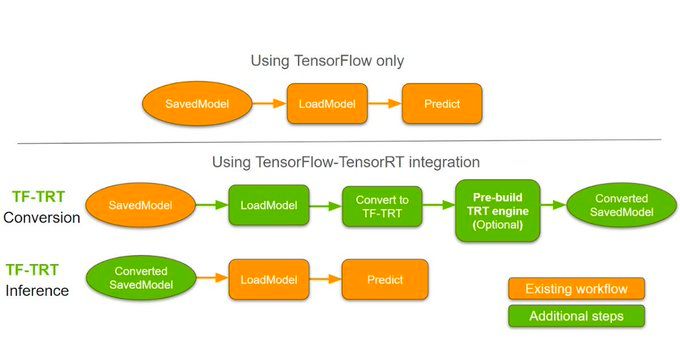
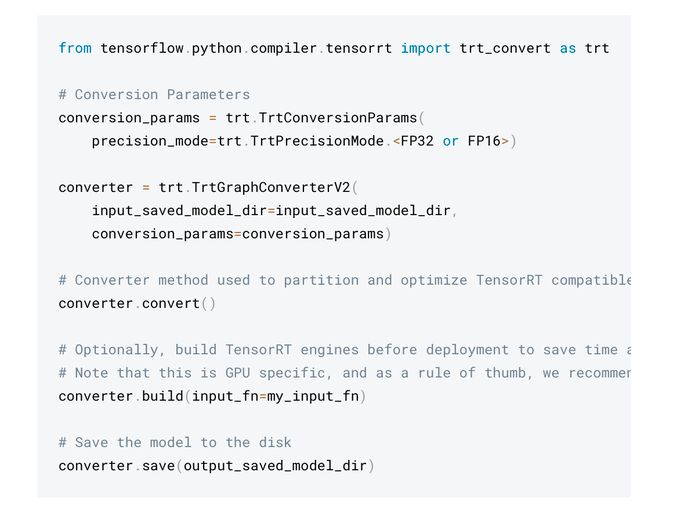
#TensorFlow- #TensorRT Integration! #BigData #Analytics #DataScience #AI #MachineLearning #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux #Programming #Coding #100DaysofCode geni.us/TF-TensorRT


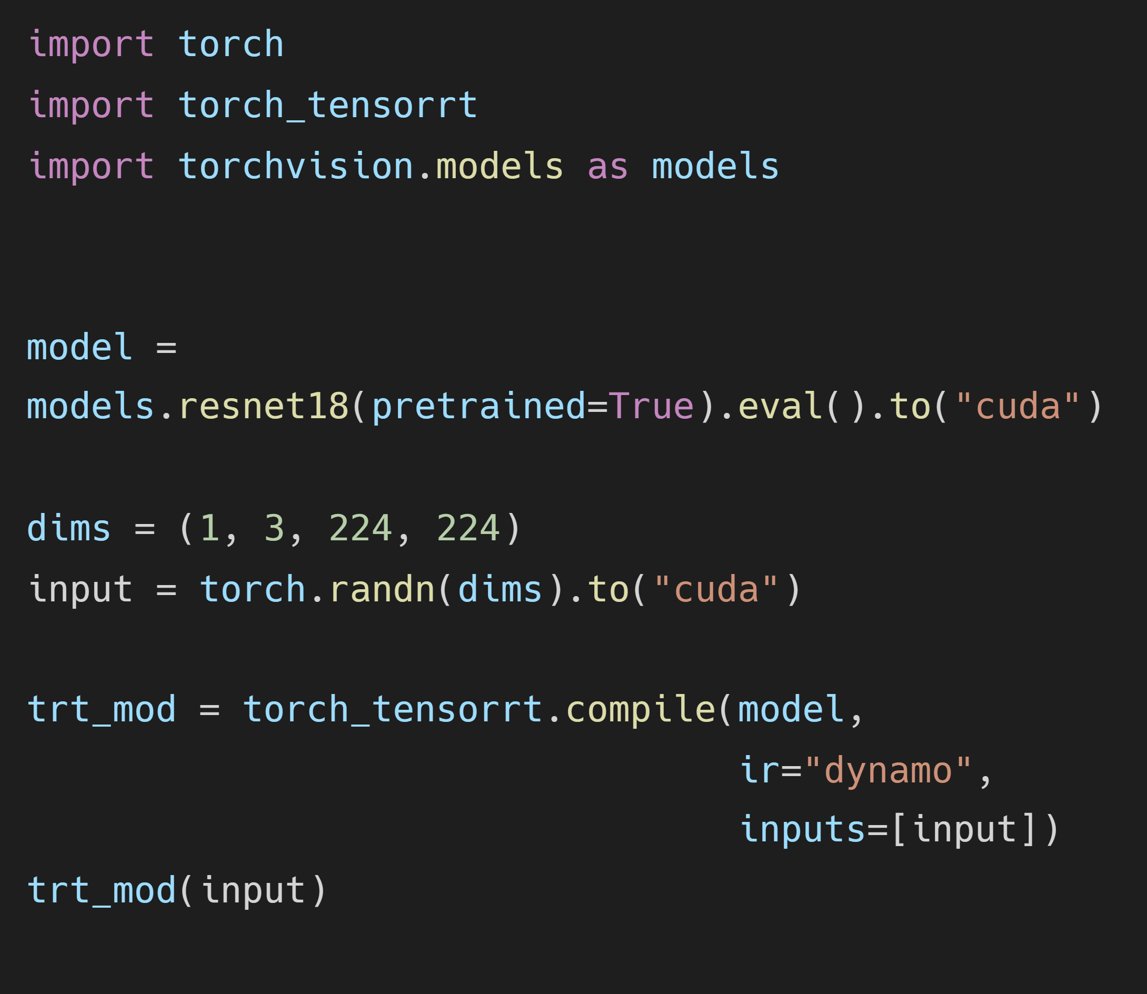
🌟 @AIatMeta #PyTorch + #TensorRT v2.4 🌟 ⚡ #TensorRT 10.1 ⚡ #PyTorch 2.4 ⚡ #CUDA 12.4 ⚡ #Python 3.12 ➡️ github.com/pytorch/Tensor… ✨
Boost @AIatMeta Llama 3.1 405B's performance by 44% with NVIDIA #TensorRT Model Optimizer on H200 GPUs. ⚡ Discover the power of optimized AI processing. ➡️ nvda.ws/3T1kqKb ✨


매주 화요일마다 TensorRT-LLM이 새롭게 업데이트된다는 사실, 알고 계셨나요? 최신 소스에서 제품을 개발하고 새로운 소식을 놓치지 마세요! #TensorRT #LLM github.com/NVIDIA/TensorR…


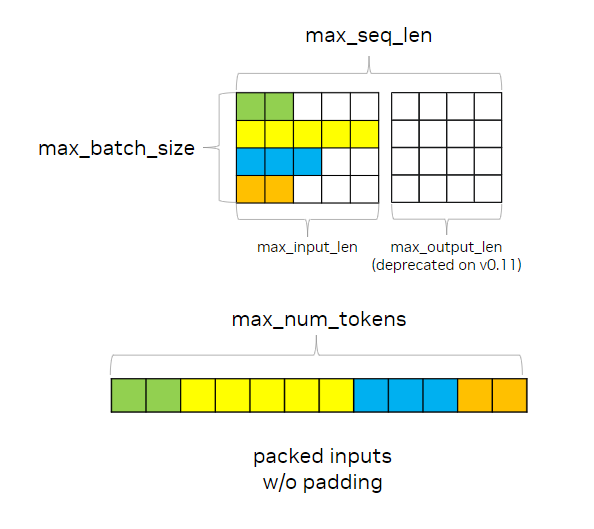
Running LLMs at scale? This TensorRT-LLM benchmarking guide shows how to turn profiling into real latency + throughput gains: glcnd.io/optimizing-llm… #AI #LLM #TensorRT #Developers


💼 Senior Ai Systems Engineer at RemoteHunter 📍 United States 💰 $170,000-$210,000 🛠️ #pytorch #tensorrt #nvidiatriton #langchain #langgraph #vllm #openai #gemini #anthropic #kubernetes #prefect #ray #aws 🔗 applyfirst.app/jobs/070e4677-…

🚀 New on the blog: Using ONNX + TensorRT for Faster Inspection AI Models! Learn how we supercharge crack, corrosion & oil-spill detection with high-speed inference. 🔗 Read more: manyatechnologies.com/onnx-tensorrt-… #ONNX #TensorRT #AI #ManyaTechnologies


A TensorRT-LLM az NVIDIA saját technológiája, ami kifejezetten az LLM-ek futtatását gyorsítja GPU-n @nvidia @NVIDIAAI #tensor #tensorrt #ai #AINews youtu.be/BQTVoT5O2Zk

youtube.com
YouTube
A TensorRT-LLM az NVIDIA saját technológiája, ami kifejezetten az...

NVIDIA's TensorRT-LLM unlocks impressive LLM inference speeds on their GPUs with an easy-to-use Python API. Performance gains are substantial with optimizations like quantization and custom attention kernels. #LLM #Python #TensorRT Link to the repo in the next tweet!

Accelerated by NVIDIA #cuEquivariance and #TensorRT for faster inference and ready for enterprise-grade deployment in software platforms.

GPU performans optimizasyonu ile eğitim ve çıkarımda gerçek hız kazanın. Doğru yığını seçin, profilleyin, ayarlayın ve ölçekleyin. #GPU #CUDA #TensorRT 👉 chatrobot.com.tr/?s=GPU%20perfo…
Just realized NVIDIA's TensorRT-LLM now supports OpenAI's GPT-OSS-120B on day zero. Huge leap for open-weight LLM inference performance. Makes cutting-edge models far more accessible. #LLM #TensorRT #OpenAI Repo Link in the next tweet.

9/10 🧠Edge対応Tips ・GGUF形式でllama.cppに変換(2〜3GBでも動作) ・ONNX/TensorRTでJetson対応 ・Triton ServerでAPI化 ・LoRAで機能分離型アダプタ構成 #llamacpp #TensorRT #LoRA #AI最適化 #Gemma3n

Deepfake scams don’t stand a chance with the new #3DiVi Face SDK 3.27! Now with a #deepfake detection module, turbo inference with #TensorRT & #OpenVINO and Python no-GIL support for parallel pipelines. Check out the full updates here: 3divi.ai/news/tpost/pze…




🏆ワークフロートラック優勝は「Video-to-Video高速化」!数時間かかっていた処理を約10分に短縮するTensorRTなどを使った最適化ワークフロー。リアルタイムでのスタイル変換も夢じゃない!(4/7) #TensorRT #動画生成AI


16/22 Learn from production systems: Study Triton (from OpenAI), FasterTransformer, and TensorRT. See how real systems solve scaling, batching, and optimization challenges. #Triton #TensorRT #Production


✨ #TensorRT and GeForce #RTX unlock ComfyUI SD superhero powers 🦸⚡ 🎥 Demo: nvda.ws/4bQ14iH 📗 DIY notebook: nvda.ws/3Kv1G1d ✨

👀 @AIatMeta Llama 3.1 405B trained on 16K NVIDIA H100s - inference is #TensorRT #LLM optimized⚡ 🦙 400 tok/s - per node 🦙 37 tok/s - per user 🦙 1 node inference ➡️ nvda.ws/3LB1iyQ✨

I broke my record 🎉 by using #TensorRT 🔥 with @diffuserslib T4 GPU on 🤗 @huggingface 512x512 50 steps 6.6 seconds (xformers) to 4.57 seconds 🎉 I will make more tests clean up the code, and make it open-source 🐣


👀 @Meta #Llama3 + #TensorRT LLM multilanguage checklist: ✅ LoRA tuned adaptors ✅ Multilingual ✅ NIM ➡️ nvda.ws/3Li6o2L

🌟 @AIatMeta #PyTorch + #TensorRT v2.4 🌟 ⚡ #TensorRT 10.1 ⚡ #PyTorch 2.4 ⚡ #CUDA 12.4 ⚡ #Python 3.12 ➡️ github.com/pytorch/Tensor… ✨
👀 Learn how the #Microsoft Bing Visual Search team leveraged #TensorRT, CV-CUDA and nvImageCodec from #NVIDIA to optimize their TuringMM visual embeddings pipeline, achieving 5.13x throughput speedup and significant TCO reduction. ➡️ nvda.ws/4dHj9Qd #visualai
Let the @MistralAI MoE tokens fly 📈 🚀 #Mixtral 8x7B with NVIDIA #TensorRT #LLM on #H100. ➡️ Tech blog: nvda.ws/3xPRMnZ ✨

🖼️ Ready for next-level image generation? @bfl_ml's FLUX.1 image generation model suite -- built on the Diffusion Transformer (DiT) architecture, and trained on 12 billion parameters -- is now accelerated by #TensorRT and runs the fastest ⚡️on NVIDIA RTX AI PCs. 🙌 Learn more…
TensorRTでモデルが変換できなかった件、どうもmodelを階層管理してるとダメっぽい。 modelフォルダのルートにファイルを置いたら変換された😇 試したら、Hires.fix後の解像度も必要になるとのことで、ぶるぺんさんの記事のように256-(512)-1536までの解像度が必要そう。 #TensorRT #StableDiffusion
TensorRT試してみた、爆速だけど制約多すぎ、とりあえずWildcardsでぶん回すには良いかも!! ちなみに「cudnn_adv_infer64_8.dll」が見つからんと言われるんだけど最新入れても変わらず、まぁ動くからいいけど。 #stablediffusion #TensorRT #AIart #AIグラビア
TensorRTですが、なんとか動くようになりましたが、画像生成そのものは早いですが、Hires.fixやI2IでのMultiDiffusionはそこそこな感じ?💦 あと、なぜかLoRA変換しても効かないとか、MultiDiffusionがEulaに勝手になるとか、ちょっと問題ありそうです😰 #TensorRT #StableDifffusion #AIArt
🙌 We hope to see you at the next #TensorRT #LLM night in San Francisco. ICYMI last week, here is our presentation ➡️ nvda.ws/4dj18Y0

#NVIDIA Ada Lovelace GPU アーキテクチャ、第 4 世代 Tensor コアと FP8 Transformer Engine 搭載されており、1.45 ペタフロップスTensor処理能力を実現 、加えて、先日、NVIDIAより公開された ライブラリ #TensorRT-LLM をサポートしておりLLMの推論処理性能が大幅に向上されます。…

ネット記で、Stable Diffusionの画像生成が高速化される拡張機能が出たとのこと! ...というわけで、ぶるぺんさんの記事などを参考に、TensorRTのインストールを行って、モデルの変換に失敗...😰 起動時にもエラーが出るため、あきらめて拡張機能を無効化してひとまず敗北😥 #TensorRT #StableDiffusion
Speed up Ultralytics YOLO11 inference with TensorRT export!⚡ Export YOLO11 models to TensorRT for faster performance and greater efficiency. It's ideal for running computer vision projects on edge devices while saving resources. Learn more ➡️ ow.ly/Xu1f50UFUCm #TensorRT


Something went wrong.
Something went wrong.
United States Trends
- 1. Giannis 59.7K posts
- 2. Spotify 1.57M posts
- 3. Tosin 64.7K posts
- 4. Leeds 99.6K posts
- 5. Bucks 37.9K posts
- 6. Milwaukee 17.3K posts
- 7. Mark Andrews 2,190 posts
- 8. Maresca 49.3K posts
- 9. Steve Cropper 1,093 posts
- 10. #WhyIChime 2,045 posts
- 11. Isaiah Likely N/A
- 12. Danny Phantom 6,930 posts
- 13. Poison Ivy 1,957 posts
- 14. Knicks 25.9K posts
- 15. Purple 53K posts
- 16. Wirtz 36.7K posts
- 17. Phantasm 1,437 posts
- 18. Sunderland 47K posts
- 19. Miguel Rojas 1,707 posts
- 20. Delap 17.7K posts