#emnlp2021 search results






Inspiring keynote delivered by Steven Bird (@StevenBird)! He beautifully articulates two ontologies for linguistic diversity and stresses on the importance of being mindful of the cultural practices of indigenous communities when building language technologies. #EMNLP2021


Planning your #NLProc week after #EMNLP2021 🤔? Come join us for @zyanan93's guest lecture to @wing_nus on ✨Revisiting Few Shot Learning for NLU✨ on Thu, 18 Nov 10am SGT (UTC+8) / 2am UTC. DM @knmnyn for the Zoom link.


MRQA 2021 is *tomorrow*! Join us Weds 9am AST, Workshop W12 #EMNLP2021 This year there's a special focus on Multilingual and interpretable QA, with talks from @rtsarfaty @JonClarkSeattle @KCrosner @JonathanBerant @marcotcr @HannaHajishirzi, 2 panels, best paper talks, & posters!


#EMNLP2021 Presenting JPR: Joint Passage Ranking for Multi-Answer Retrieval. Poster session tomorrow! Virtual: 8:30-10:30 PST / 11:30-1:30 EST In-person: 2:45-4:15 AST arxiv.org/abs/2104.08445 with @kentonctlee @mchang21 @toutanova @HannaHajishirzi (while interning at @GoogleAI)




I skimmed through many papers from @emnlpmeeting, which got me thinking - what % of papers refer to BERT, and out of those, how many cite it? Here's the answer*: 67% of papers refer to BERT (!), and 56% cite it. *computed automatically, exact #'s may vary #EMNLP2021 #NLProc

That's a wrap on the main conference at #EMNLP2021! The fun continues with 23 workshops and 6 tutorials spread across the next two days!


In #EMNLP2021, we present a model to measure the quality of an argument. Using 'theories of argument quality', we design interpretable features of language and other non-verbal features. Along with a high accuracy, we unravel strategies that good debators use.


#phdlife The perks of being a #PhD just finished thesis proposal🥳, next day conference in Punta Cana 🤯✈️🏝️🍹#emnlp2021


Looking for some human interactions at the virtual #EMNLP2021 conference? Workshop on Noisy User-generated Text (WNUT) will be live, with real-time Zoom talks & 70+ posters in GatherTown, two time zones (Nov 11 | 00:00-04:00 and 11:00-15:00 AST). noisy-text.github.io/2021/


Why do researchers work on Question Answering (QA)? Our #emnlp2021 position paper with @boydgraber examines QA as a field, and explores how differing motivations influence datasets, tasks, and funding. #nlproc Video: youtube.com/watch?v=NZdKG3… Paper: aclanthology.org/2021.emnlp-mai…




#EMNLP2021 @FEVERworkshop watch party with the half of CopeNLU who stayed behind in Copenhagen #NLProc 🌴👩💻 📽️


Dear friends, @hhexiy @robinomial @sameer_ and I will present a tutorial on "Robustness and Adversarial Examples in NLP" virtually at #EMNLP2021 9am AST tomorrow (Nov 11). See you there! #NLProc Presentation link: underline.io/events/192/ses… Slides/Website: robustnlp-tutorial.github.io


We are pleased to share that our work (HypMix) presented both virtually & in person at #EMNLP2021 held in Punta Cana, Dominican Republic received great participation & appreciation from the attendees. @ramitsawhney from our AI team presented HypMix across three sessions. (1/2)



We have folks in person in the Dominican Republic, as well as online attendees from Iran, Argentina, Singapore, Sri Lanka, India, Mexico, Ethiopia, Tunisia, Switzerland, Germany, Ireland, and USA. Truly Widening #NLProc! #EMNLP2021


Just came back from my first in-person conference #EMNLP2021 in Punta Cana 🌴. Thanks to the @WiNLPWorkshop team for making this possible! 😊 Also thanks @ramitsawhney for the picture!


As a follow-up of our previous two works: 1️⃣Our overview paper on "Causal Direction in NLP" #EMNLP2021: arxiv.org/abs/2110.03618 2️⃣The effect of Causal and Anticausal learning on Machine Translation #NAACL2022: arxiv.org/abs/2205.02293 3️⃣This work: extends to Sentiment Analysis🎉


📢📢📢 looking for a volunteer with some #LATEX knowledge to update the #CVPR2024 template The main change would be to adopt the line numbering from #EMNLP2021 (as suggested by the @overleaf team), as the one we have been using for the last ~5 years breaks SyncTex

At 35, showcased a demo of the discourse-driven IDE for building scenario-driven skills and chatbots at #EMNLP2021. At 36, jumpstarted a new startup, @DpDreamBuilder, to productive the work done at @deeppavlov and @zetuniverse to build the future of personal AI assistants.

Third day at #EMNLP2021. How compositional generalization changes with model size. Prompt tuning seems to scale well for a while but you can't afford it for the largest models.


Our Pick of the week: Wisniewski et al. #EMNLP2021 #blackboxnlp WS paper "Screening Gender Transfer in Neural Machine Translation". By @andrea_pierg aclanthology.org/2021.blackboxn… #nlproc @yvofr

A fascinating exploration of gender's representation and transfer in Neural Machine Translation by Guillaume Wisniewski, @lichaozhu. A very interesting dive into the depths of MT. Check the paper: aclanthology.org/2021.blackboxn… @fbk_mt
Also thanks to @Khipu_AI that helped Mauricio start his PhD in 2019 very motivated about #NLProc. And thanks to @WiNLPWorkshop for allowing him present to our #EMNLP2021 paper in person.

🤩Excited to see our #EMNLP2021 paper being explained in @Stanford #CS224n (NLP with Deep Learning) lecture by @kelvin_guu youtu.be/4ynrGLIuPv4?t=… #Cs224n #NLProc #stanford 1/

We tested on three datasets and achieved significant performance boost in multiple settings. For example, results on YASO, a multi-domain TSA benchmark we published at #EMNLP2021 (aclanthology.org/2021.emnlp-mai…): (3/5)


An interesting paper from #EMNLP2021 about latency metrics in real-world scenarios, in which a more interpretable stream-level evaluation is proposed for simultaneous machine translation. @fbk_mt aclanthology.org/2021.findings-…

Back at #EMNLP2021, while presenting ConSeC, quite a few colleagues asked @edoardo_barba and me “have you tried this extractive formulation on entity disambiguation?” Yes, we were and it’s now an #ACL2022 paper!

Extractive Entity Disambiguation is our (@edoardo_barba @luigi_proc @RNavigli) new paper at #ACL2022! Guess what, we perform ED as a Text Extraction task using only Wikipedia Titles and achieve a new SotA in standard and constrained data regimes. @ERC_Research #NLProc Links: ⬇️


@nedjmaou, besides doing working on automated fact-checking for journalists, also created some great tweet round-ups of #EMNLP2021 ift.tt/38d6Nkj and #ACL2021NLP ift.tt/3Afrvvl
aihub.org
Microblogs from ACL 2021 - ΑΙhub
Microblogs from ACL 2021 - ΑΙhub

Subset: *If you attended #EMNLP2021 in person in Punta Cana last year*, how are you likely to attend?
New podcast describing our #emnlp2021 paper on exaggeration detection 🎧 aclanthology.org/2021.emnlp-mai… @dustin_wright37 @IAugenstein

Super stoked to have been interviewed on the @NVIDIAAI podcast for our work on #NLProc for exaggeration detection in health science😄 🔊 Listen here: open.spotify.com/episode/16YohQ…

Otherwise these are the papers being presented: #acl2021nlp BERT is to NLP what AlexNet is to CV: Can Pre-Trained Language Models Identify Analogies? 👉aclanthology.org/2021.acl-long.… #emnlp2021 Distilling Relation Embeddings from Pretrained Language Models 👉aclanthology.org/2021.emnlp-mai…

Hey #NLProc, looking for some Friday afternoon reading? Check the link below for a collection of blog posts about #EMNLP2021 papers, spanning topics from bias, robustness, summarization, low-resource, and so much more! 👇 Thanks to all the authors 🥳 nlpnorth.github.io/content/emnlp-…
Our @DFKI paper on the Conf. on Machine #Translation appeared in the anthology. We evaluated 36 systems on ling. motivated test items, with English-German as a new language direction. The winners are... Online-W, @Facebook & VolcTrans! #NLProc #EMNLP2021 aclanthology.org/2021.wmt-1.115

Hey! I wrote a blog post about the robustness of transformers in #NLProc. I give an overview over three #EMNLP2021 papers, discussing everything from spelling errors to shuffled word order and distributional shift, with some surprising findings! dennisulmer.eu/how-robust-are…


.@ziorufus and @stefano_menini managed to go to #emnlp2021 in Punta Cana as the only in-person conference attended this year, making the rest of the group really envious 6/n

Today is the 14th of December! What's wrong with you #ACL?! I am sorry to inform you #EMNLP2021 finished almost two months ago, I know it's hard but please admit it and don't spam! With all the best Samira


And now the @aclmeeting email portal is informing me that registration is open ... for #EMNLP2021.


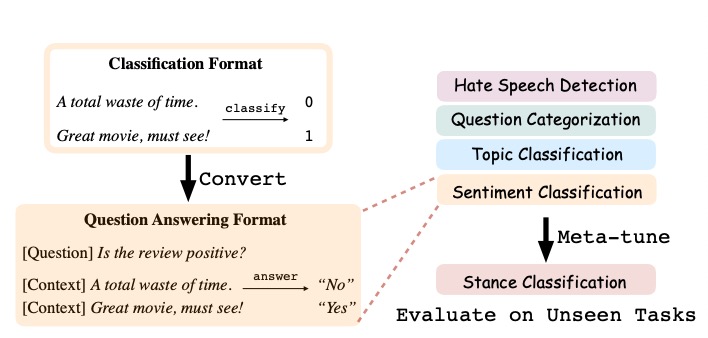
We can prompt language models for 0-shot learning ... but it's not what they are optimized for😢. Our #emnlp2021 paper proposes a straightforward fix: "Adapting LMs for 0-shot Learning by Meta-tuning on Dataset and Prompt Collections". Many Interesting takeaways below 👇

昨日から #EMNLP2021 参加中.私は11/18木曜の #BlackboxNLP2021 でガーデンパス現象など日本語の言語現象を考慮した自然言語推論データセットを構築し,日本語・多言語BERTがどの程度人と同じように言語現象を捉えているか分析した論文: aclanthology.org/2021.blackboxn… を発表します.ぜひお声がけください


Proud to announce that our paper "SimCSE: Simple Contrastive Learning of Sentence Embeddings" got accepted to #EMNLP2021! Much thanks to my wonderful co-authors Xingcheng and @danqi_chen. Code: github.com/princeton-nlp/… Paper: arxiv.org/abs/2104.08821

💥 to share “SimCSE: Simple Contrastive Learning of Sentence Embeddings”. We show that a contrastive objective can be VERY effective with right *augmentation* or *datasets*. Large gains on STS tasks and unsup. SimCSE matches previous supervised results! bit.ly/3gqgh0d


In English, “knight” and “night” are pronounced identically—as [naɪt]. In jargony terminology, they are homophones. At first blush, having a lot of homophones in a language may lead to confusion. So, languages should avoid homophony, right? #EMNLP2021 arxiv.org/abs/2109.13766
![tpimentelms's tweet image. In English, “knight” and “night” are pronounced identically—as [naɪt]. In jargony terminology, they are homophones. At first blush, having a lot of homophones in a language may lead to confusion. So, languages should avoid homophony, right? #EMNLP2021
arxiv.org/abs/2109.13766](https://pbs.twimg.com/media/FAd6CDUWEAQtILQ.jpg)

Excited to announce our #EMNLP2021 paper that shows how to turn a pre-trained language model or even a randomly initialized model into a strong few-shot learner. Paper: arxiv.org/abs/2109.06270 w/ amazing collaborators: @lmthang, @quocleix, @GradySimon, @MohitIyyer 1/9👇

Have you ever struggled with the data processing inequality? It might be because it doesn't work, at least not in real life! In #EMNLP2021, @ryandcotterell and I propose a new Bayesian framework that generalises Shannon's and V-information :) We then apply it to probing!

A surprisal–duration trade-off across and within the world’s languages! Analysing 600 languages, we find evidence of this trade-off: cross-linguistically; and within 319 of them. We conclude less surprising phones are produced faster. #EMNLP2021 arxiv.org/abs/2109.15000



#EMNLP2021 Presenting JPR: Joint Passage Ranking for Multi-Answer Retrieval. Poster session tomorrow! Virtual: 8:30-10:30 PST / 11:30-1:30 EST In-person: 2:45-4:15 AST arxiv.org/abs/2104.08445 with @kentonctlee @mchang21 @toutanova @HannaHajishirzi (while interning at @GoogleAI)

When adapting NLP models to a new domain, does it help more to annotate more data or pre-training an in-domain LM? Check out our #EMNLP2021 paper (w/ @alan_ritter & @cocoweixu): Pre-train or Annotate? Domain Adaptation with a Constrained Budget (arxiv.org/abs/2109.04711). [1/7]
![loadingfan's tweet image. When adapting NLP models to a new domain, does it help more to annotate more data or pre-training an in-domain LM? Check out our #EMNLP2021 paper (w/ @alan_ritter & @cocoweixu): Pre-train or Annotate? Domain Adaptation with a Constrained Budget (arxiv.org/abs/2109.04711).
[1/7]](https://pbs.twimg.com/media/E_f1N5cX0AAtPiS.png)
We are pleased to share that our work (HypMix) presented both virtually & in person at #EMNLP2021 held in Punta Cana, Dominican Republic received great participation & appreciation from the attendees. @ramitsawhney from our AI team presented HypMix across three sessions. (1/2)

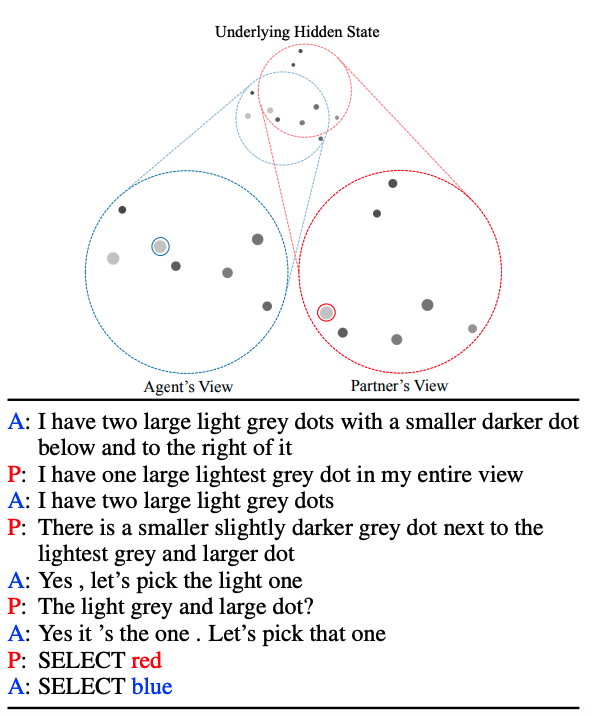
We built a pragmatic, grounded dialogue system that improves pretty substantially in interactions with people in a challenging grounded coordination game. Real system example below! Work with Justin Chiu and Dan Klein, upcoming at #EMNLP2021. Paper: arxiv.org/abs/2109.05042
ShareChat is thrilled to announce that our AI team will be presenting the following four papers on NLP and multilinguality at EMNLP 2021 and co-located workshops. Stay tuned for more details! #EMNLP2021 @ramitsawhney @vikramnov14 @mdebdoot

MRQA 2021 is *tomorrow*! Join us Weds 9am AST, Workshop W12 #EMNLP2021 This year there's a special focus on Multilingual and interpretable QA, with talks from @rtsarfaty @JonClarkSeattle @KCrosner @JonathanBerant @marcotcr @HannaHajishirzi, 2 panels, best paper talks, & posters!

Our paper "Chandler: An Explainable Sarcastic Response Generator" has been accepted to @emnlpmeeting as a demo paper. Work by @_silviu_oprea_, @SteveWilsonNLP & myself. Preprint and demo link to be provided soon 😊 #EMNLP2021

IBM Research shares Project Debater’s latest progress in key point analysis at this year’s #EMNLP2021 conference, including a web demo that allows anyone to try KPA without any programming required. Learn more ➡️ ibm.co/3mYWdVB


📢📜#NLPaperAlert 🌟Knowledge Conflicts in QA🌟- what happens when facts learned in training contradict facts given at inference time? 🤔 How can we mitigate hallucination + improve OOD generalization? 📈 Find out in our #EMNLP2021 paper! [1/n] arxiv.org/abs/2109.05052
![ShayneRedford's tweet image. 📢📜#NLPaperAlert 🌟Knowledge Conflicts in QA🌟- what happens when facts learned in training contradict facts given at inference time? 🤔
How can we mitigate hallucination + improve OOD generalization? 📈
Find out in our #EMNLP2021 paper! [1/n]
arxiv.org/abs/2109.05052](https://pbs.twimg.com/media/E_5rq8ZVQAQqGwR.png)

Happy to share that our FastIF paper's been accepted at #EMNLP2021! Thanks to wonderful coauthors @nazneenrajani @peterbhase @mohitban47 @CaimingXiong @uncnlp @SFResearch @LTIatCMU Updated paper/code (w. more exps on ANLI/WILDS): arxiv.org/abs/2012.15781 github.com/salesforce/fas…




Glad to share our latest work "FastIF: Scalable Influence Functions for Efficient Model Interpretation and Debugging"! Joint work with @nazneenrajani @peterbhase @mohitban47 @caimingxiong (@uncnlp @sfresearch). Paper: arxiv.org/abs/2012.15781 Code: github.com/salesforce/fas… 1/5





I'm proud to introduce my first paper! Modern pre-trained language models are applicable even in extreme low-resource settings as the case of the ancient Akkadian language. arxiv.org/abs/2109.04513 Main Conference of #EMNLP2021

Something went wrong.
Something went wrong.
United States Trends
- 1. Marshawn Kneeland 29.5K posts
- 2. Nancy Pelosi 37.2K posts
- 3. #MichaelMovie 46.2K posts
- 4. #NO1ShinesLikeHongjoong 31.3K posts
- 5. #영원한_넘버원캡틴쭝_생일 30.8K posts
- 6. ESPN Bet 2,638 posts
- 7. Baxcalibur 4,528 posts
- 8. Chimecho 6,576 posts
- 9. Madam Speaker 1,638 posts
- 10. Joe Dante N/A
- 11. Gremlins 3 3,635 posts
- 12. #LosdeSiemprePorelNO N/A
- 13. #thursdayvibes 3,254 posts
- 14. VOTAR NO 28.2K posts
- 15. Jaafar 13.6K posts
- 16. Chris Columbus 3,261 posts
- 17. Diantha 1,913 posts
- 18. Rest in Peace 20.2K posts
- 19. Unplanned 8,355 posts
- 20. Korrina 5,809 posts