#mapreduce ผลการค้นหา



Map-Reduce is making a surprising comeback in the #LLM and prompt engineering scene, improving prompt optimization for better results. It was seen last time in big data and distributed processing ;-) picture by @DeepLearningAI_ #MapReduce #PromptEngineering #LanguageModels #AI


Map reduce data processing model helps in processing large datasets in a distributed environment and achieve parallelism. Following illustration, we are trying to count occurrences of each unique word from a set of files. #SystemDesign #mapreduce #sde


#dataprocessing #MapReduce #datamining #engineeringinnovation #researchpaper #labtechinnovation #authorship #authors #authorlife #authorcommunity


“here was a system that nobody wanted that Google had abandoned, but enterprises had spent large amounts of money building out clusters to do a #MapReduce / #Hadoop market that didn't exist.” Andy Palmer & Mike Stonebraker! podcasts.apple.com/gb/podcast/the…


✨ RavenDB Map-Reduce Index ✨ Organizes and aggregates heterogenous data incrementally whenever data changes. It can also run various other computations asynchronously so that frequent queries don't have to. #RavenDB #MapReduce #Indexing


Optimize your MapReduce job by combining small files, tuning the cluster, using combiners, compressing data, and profiling jobs to fix bottlenecks. #MapReduce #BigData #DataProcessing #Hadoop #DataOptimization #SoftwareEngineering #TechTips #DataAnalysis #DataScience


En el contexto de la ingeniería de datos analizamos #MapReduce, el modelo de procesamiento paralelo para grandes colecciones de datos. #DiplomadoIoT #IoT #BigData


Dive into the fundamentals of map-reduce operations, crucial in both functional programming and big data. Uncover their inner workings, practical applications, and their transformative impact on data processing. bitly.ws/35y8y #Java #MapReduce #DataProcessing




We are Hiring Data Engineer..!! . . . #hiring #hdfs #mapreduce #hive #airflow #python #pyspark #spark


How to make the best decisions for systems based on #MapReduce for current #BigData needs? Can one reliably predict the execution time of a given job? Read more in a research paper published in #SCPE, Vol. 22, No. 4, (ISSN 1895-1767): tinyurl.com/2p9ywb8v

Underdstand the fundamentals of map-reduce operations, crucial in both functional programming and big data. Uncover their inner workings, practical applications, and their transformative impact on data processing. 🔗 bit.ly/4byKXWC #Java #MapReduce #DataProcessing





Can you leverage #mapreduce, #spark, Spark Stream, Storm, or #tez to transform and mask data in HDFS files without programming? Check out the #hadoop options in #IRI_Voracity:


Programming #BigData Applications It covers essential #programming models and frameworks such as #MapReduce and #Spark, providing practical examples that enhance understanding. Click this link to learn more (linkedin.com/posts/dataglob…) #Learn #CHANELMetiersdArt #earthquake


Programming languages evolve: Sequential ➡️ Parallel. E.g., #Java ➡️ #MapReduce #Solidity ➡️ #PREDA That's where PREDA steps in 🚀 Like and retweet if you are to 🔥Parallel with us #Dioxide #programming #Metamask





Introduction to Apache Hadoop for big data processing in Java In this article, we'll provide an overview of Apache Hadoop and demonstrate how to perform basic data processing tasks using Java MapReduce. #java #hadoop #mapreduce blackslate.io/articles/intro…

Introduction to Apache Hadoop for big data processing in Java In this article, we'll provide an overview of Apache Hadoop and demonstrate how to perform basic data processing tasks using Java MapReduce. #java #hadoop #mapreduce blackslate.io/articles/intro…
Introduction to Apache Hadoop for big data processing in Java In this article, we'll provide an overview of Apache Hadoop and demonstrate how to perform basic data processing tasks using Java MapReduce. #java #hadoop #mapreduce blackslate.io/articles/intro…

D42 💥 Why #Spark beats #MapReduce? #Hadoop writes to disk after every step. Spark? Keeps it in memory🚀 #ApacheSpark #BigData #DataEngineering #PySpark #DataScience #MachineLearning #ETL #DataPipeline #CloudComputing #Analytics #AI #DataEngineer #BigDataAnalytics #DataProcessing
Introduction to Apache Hadoop for big data processing in Java In this article, we'll provide an overview of Apache Hadoop and demonstrate how to perform basic data processing tasks using Java MapReduce. #java #hadoop #mapreduce blackslate.io/articles/intro…
Introduction to Apache Hadoop for big data processing in Java In this article, we'll provide an overview of Apache Hadoop and demonstrate how to perform basic data processing tasks using Java MapReduce. #java #hadoop #mapreduce blackslate.io/articles/intro…
Introduction to Apache Hadoop for big data processing in Java In this article, we'll provide an overview of Apache Hadoop and demonstrate how to perform basic data processing tasks using Java MapReduce. #java #hadoop #mapreduce blackslate.io/articles/intro…

Is Shuffle Really Needed? Yes, usually. Shuffle ensures all related data (e.g., same city) is together for Reduce to work. But if data’s already organized (pre-partitioned), you can skip it! Smart prep saves time. What tricks do you use for faster data processing? 👇 #MapReduce
MapReduce is a way to process huge datasets across many computers. It splits work into two steps: Map (sort & organize) and Reduce (summarize). Think of it like sorting a giant pile of receipts! #MapReduce
Introduction to Apache Hadoop for big data processing in Java In this article, we'll provide an overview of Apache Hadoop and demonstrate how to perform basic data processing tasks using Java MapReduce. #java #hadoop #mapreduce blackslate.io/articles/intro…
Introduction to Apache Hadoop for big data processing in Java In this article, we'll provide an overview of Apache Hadoop and demonstrate how to perform basic data processing tasks using Java MapReduce. #java #hadoop #mapreduce blackslate.io/articles/intro…

💡Prepare for your Apache Hadoop & MapReduce Interviews Get ready with top Q&A and boost your chances of cracking Big Data roles 🚀 👉 Start here: buff.ly/zvZjsGh #ApacheHadoop #MapReduce #BigData #DataScience #MachineLearning #Analytics #AI #DataEngineer #InterviewPrep


MapReduce with Python #Python #Mapreduce #Bigdata #Hadoop plainenglish.io/blog/mapreduce…
plainenglish.io
MapReduce with Python
An introduction to the MapReduce programming model and understanding how data flows via the different stages of the model.
Introduction to Apache Hadoop for big data processing in Java In this article, we'll provide an overview of Apache Hadoop and demonstrate how to perform basic data processing tasks using Java MapReduce. #java #hadoop #mapreduce blackslate.io/articles/intro…
Introduction to Apache Hadoop for big data processing in Java In this article, we'll provide an overview of Apache Hadoop and demonstrate how to perform basic data processing tasks using Java MapReduce. #java #hadoop #mapreduce blackslate.io/articles/intro…
Introduction to Apache Hadoop for big data processing in Java In this article, we'll provide an overview of Apache Hadoop and demonstrate how to perform basic data processing tasks using Java MapReduce. #java #hadoop #mapreduce blackslate.io/articles/intro…

Yes. I can #mapreduce your trifling opinion. Two syllables. Come on, gimme cancer. I’m just so koncern’d. With your excuses and my malady— Emily won. 🏆
Introduction to Apache Hadoop for big data processing in Java In this article, we'll provide an overview of Apache Hadoop and demonstrate how to perform basic data processing tasks using Java MapReduce. #java #hadoop #mapreduce blackslate.io/articles/intro…














#ApacheSpark and #MapReduce K-Means. #BigData #Analytics #DataScience #AI #MachineLearning #IoT #IIoT #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux #Programming #Coding #100DaysofCode bit.ly/39U7Raf


#MapReduce and #YARN Part 2: #Hadoop Processing Unit. #BigData #Analytics #NoSQL #DataScience #AI #MachineLearning #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux bit.ly/2NnJJEC



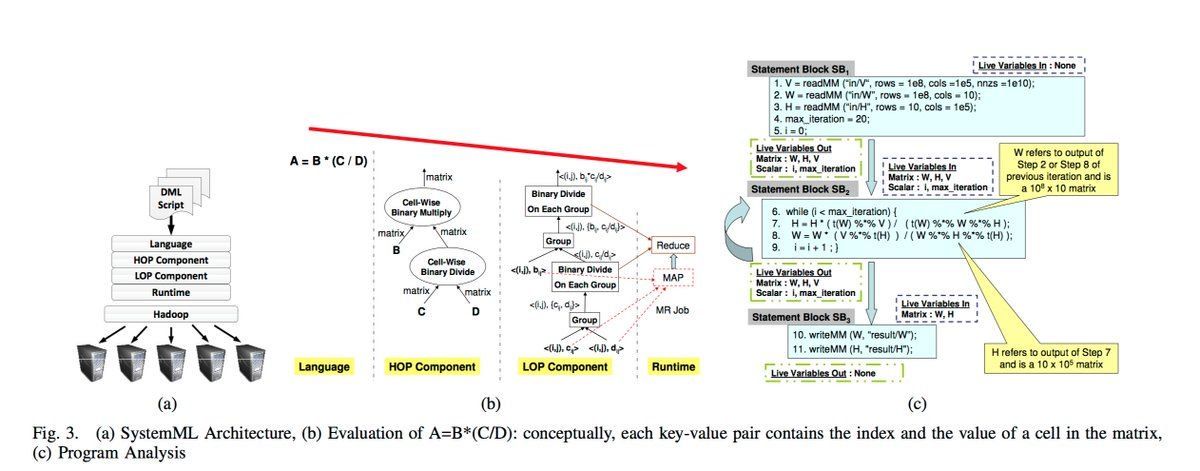
#ApacheSystemML: Declarative Large-Scale #MachineLearning on #MapReduce. #BigData #Analytics #Hadoop #DataScience #AI #Analytics #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #VueJS #GoLang #CloudComputing #Serverless #Jupyter bit.ly/2maqel4

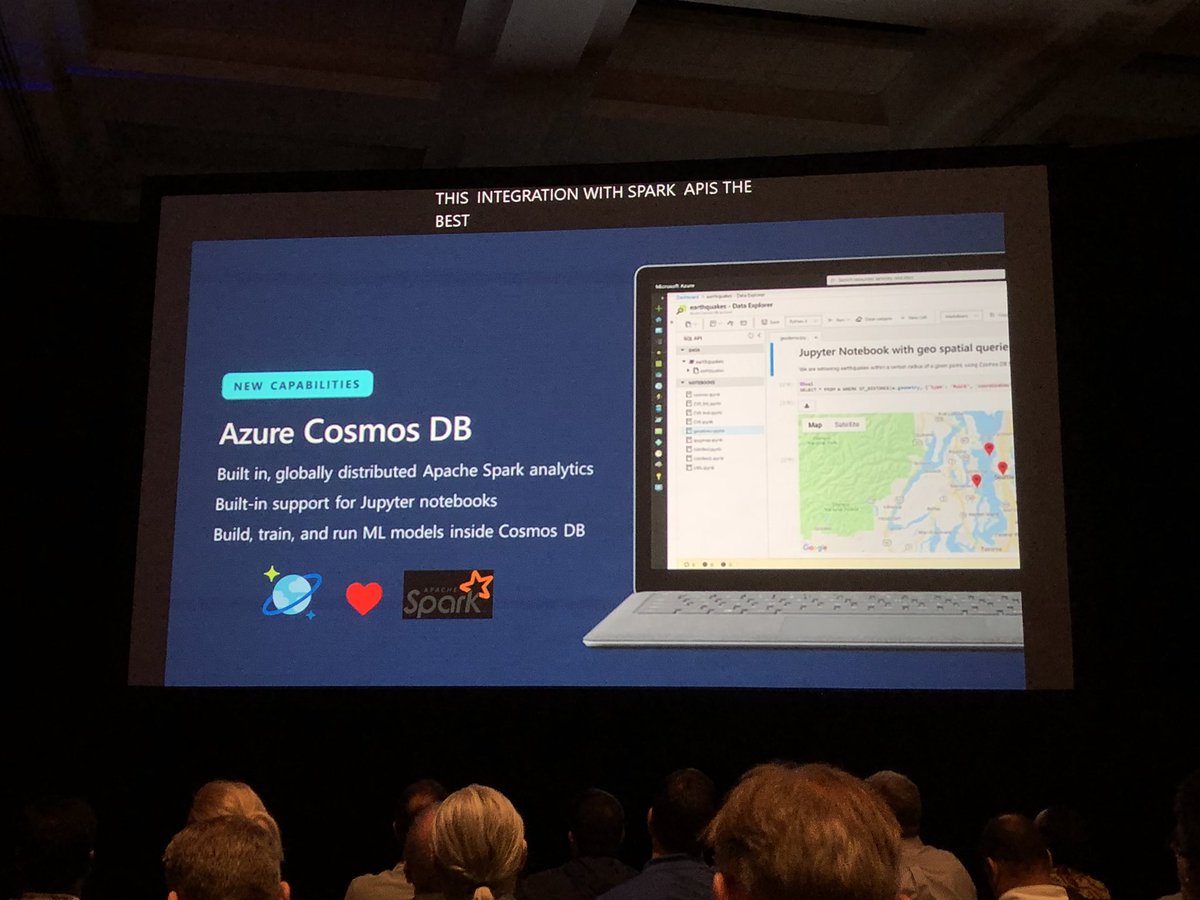
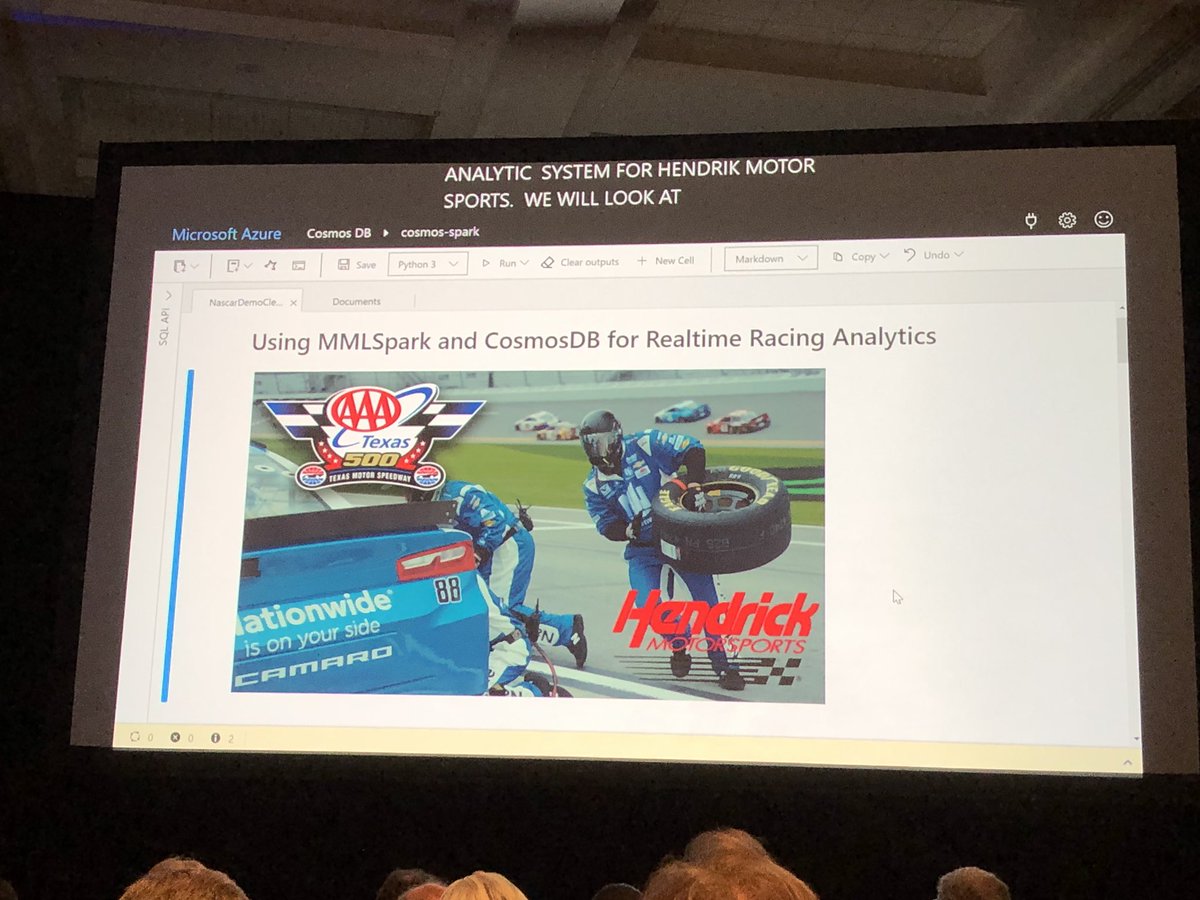
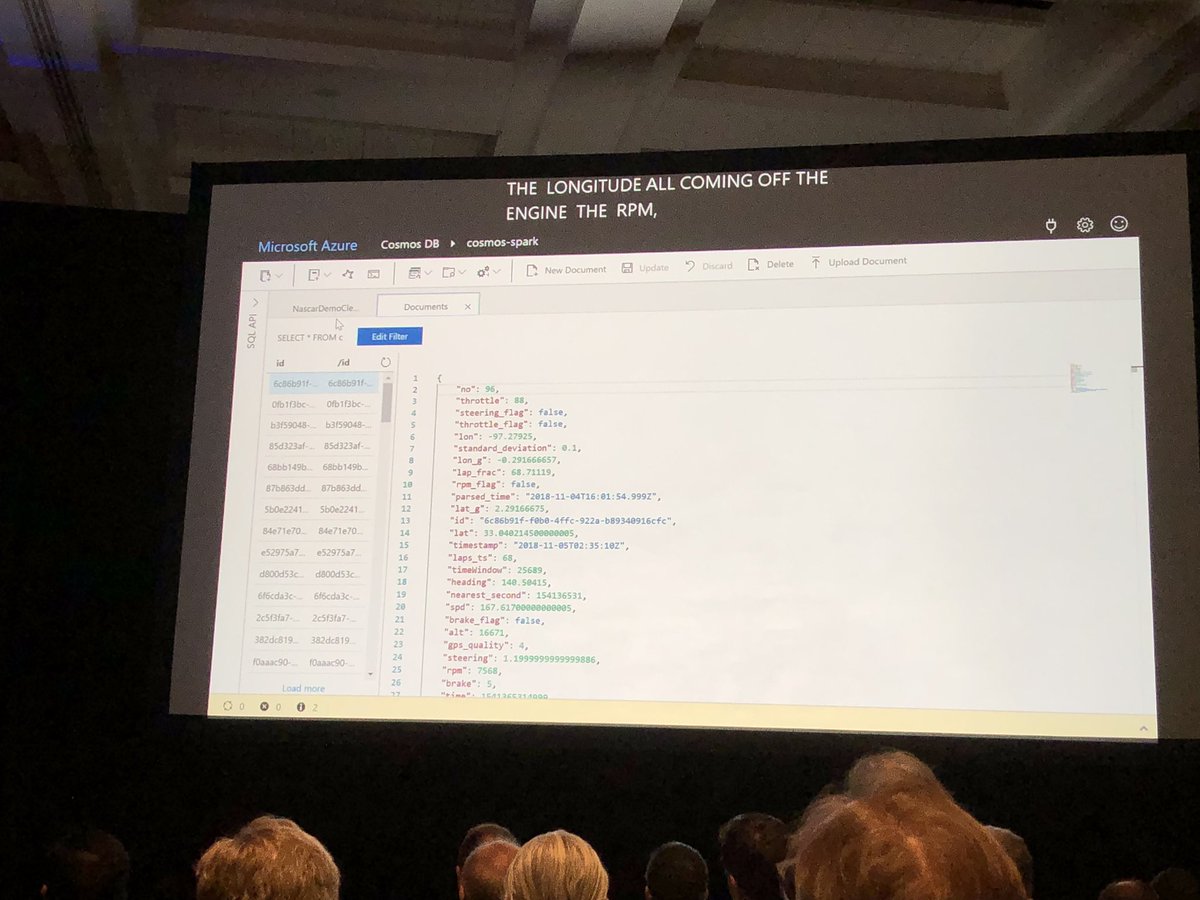
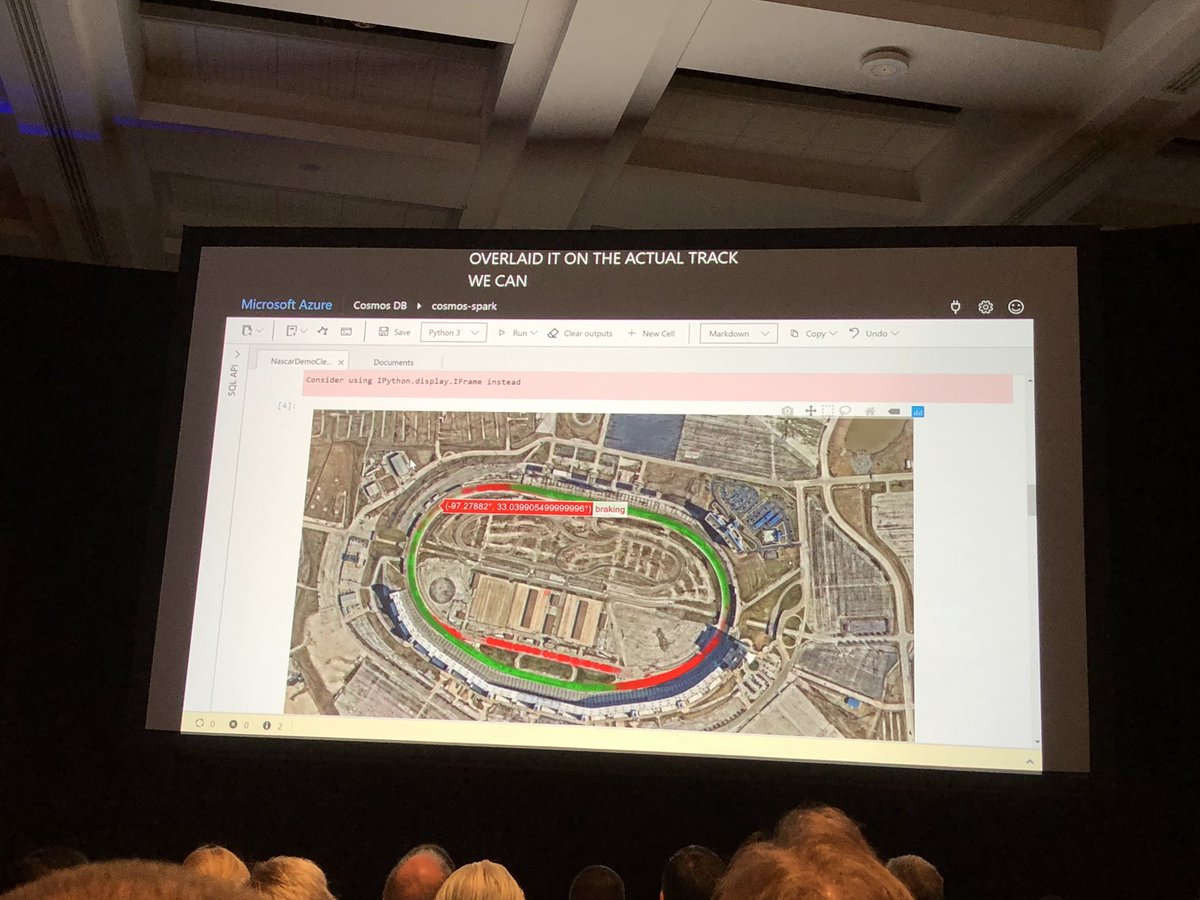
OK this is very cool and whilst I say relatively easy (I know reality is more complex with #MapReduce and @cosmosdb, #Jupyte and #Spark for @NASCAR. Lets do this for @F1 - #racing and #AI #MSBuild Congrats @dharmashukla @RohanKData @aram09
RDF Processing with #MapReduce on a Massive-Scale by @gp_pulipaka - Timothy Myers. #BigData #Analytics #DataScience #AI #MachineLearning #IoT #IIoT #Python #RStats #TensorFlow #JavaScript #ReactJS #Serverless #DataScientist #Linux #Programming #Coding #100DaysofCode


#MapReduce : tout savoir sur le framework Hadoop de traitement #BigData lebigdata.fr/mapreduce-tout…



A #MapReduce-based Approach for Shortest Path Problem in Large-Scale Networks. #BigData #Analytics #DataScience #AI #MachineLearning #IoT #IIoT #Python #RStats #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #Linux #Programming #100DaysofCode bit.ly/2WYprF9




Data-Intensive Text Processing with MapReduce:本书专注于 MapReduce 算法设计,强调在自然语言处理、信息检索、以及机器学习中的文本处理算法。此外,该书还介绍了 MapReduce 设计模式,帮助读者形成 MapReduce 思维。(booksea.app/archives/data-…) #mapreduce #freebook


Short tutorial on how #Hadoop and #MapReduce work: bit.ly/2O70iTu #abdsc #BigData #DataScience #Analytics #HDFS

Why #MapReduce Is Still A Dominant Approach For Large-Scale #MachineLearning. #BigData #Analytics #Hadoop #DataScience #AI #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux bit.ly/2OYiMHn




Free eBook: Optimizing Hadoop for #MapReduce. #BigData #Analytics #NoSQL #Hadoop #MachineLearning #DataScience #AI #IoT #IIoT #Python #RStats #TensorFlow #JavaScript #ReactJS #VueJS #GoLang #CloudComputing #Serverless #DataScientist #Linux #Books bit.ly/2RwwJNy




Finding it hard to determine which fs command I should use via CLI on our #Hadoop cluster... hadoop fs or hdfs dfs? Is either deprecated? Which is better to future proof? Any answers Twitter? #HDFS #MapReduce @hortonworks @nixcraft @ComputingITC @lintool @StackOverflow #HelpPls


I did a talk at @WeAreAmido last week on #serverless #mapreduce where we attempted (AFAIK) a world first - creating a working map reduce cluster with all the mobile devices in the room - and it worked!!


Apache Hadoop: HDFS, YARN, MapReduce Apache Hive: Büyük Veri Ambarı Çözümü Apache Sqoop ile Hadoop ve İlişkisel Veri Tabanları Arasında Veri Transferi Apache Kafka: Gerçek Zamanlı Veri İşleme Platformu #apache #kafka #mapreduce #python #hive #hdfs #yarn #hadoop #sqoop #data


#MapReduce solves distributed Graph #Algorithms in few computation rounds ai.googleblog.com/2021/03/massiv… #BigData #Analytics #DataScience #AI #MachineLearning #IoT #IIoT #Python #RStats #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #Linux #Programming #100DaysofCode





Hadoop Python MapReduce Tutorial for Beginners @ bit.ly/2G4XYKh #Hadoop #MapReduce #Python #BigData #DataAnalytics #HadoopImplementation #HadoopDevelopmentServices #HadoopConsultingCompany #HadoopDevelopmentCompanyIndia #HadoopConsultingCompanyIndia




Introduction to #BigData and the different techniques employed to handle it such as #MapReduce, #ApacheSpark and #Hadoop. towardsdatascience.com/big-data-analy… #DataScience #100DaysOfCode #NeuralNetworks #100DaysOfMLCode #DigitalTransformation #ArtificialIntelligence #MachineLearning #IoT
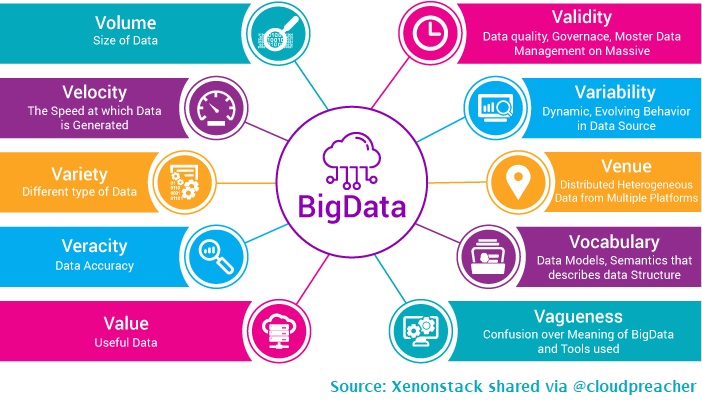

Futures and dependencies #FPpipelines #spark #mapreduce is actually parallel processing tech right? #Horizontalscalability Someone lend me a second brain 🧠 please. 🤯 @UpholdInc

Something went wrong.
Something went wrong.
United States Trends
- 1. #SmackDown 12K posts
- 2. Eagles 138K posts
- 3. Bears 123K posts
- 4. #BedBathandBeyondisBack 1,107 posts
- 5. Arch Manning 1,333 posts
- 6. Ben Johnson 25.5K posts
- 7. Marcel Reed 1,483 posts
- 8. Sark 1,847 posts
- 9. Jalen 31.1K posts
- 10. #OPLive N/A
- 11. Lindor 1,387 posts
- 12. #iufb 1,735 posts
- 13. Aggies 4,273 posts
- 14. Caleb 51.1K posts
- 15. #BearDown 2,729 posts
- 16. Lane 60.4K posts
- 17. Patullo 14.3K posts
- 18. Philly 30K posts
- 19. Sirianni 9,267 posts
- 20. KC Concepcion N/A