#particle_swarm_optimization search results

AI agents are supposed to collaborate with us to solve real-world problems, but can they really? Even the most advanced models can still give us frustrating moments when working with them deeply. We argue that real-world deployment requires more than productivity (e.g., task…


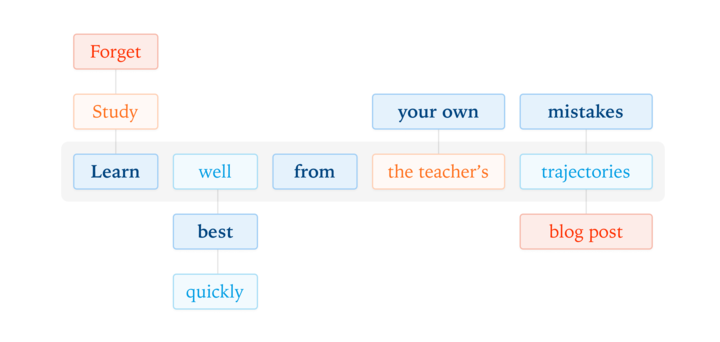
Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

Proximal Policy Optimization (PPO) is one of the most common (and complicated) RL algorithms used for LLMs. Here’s how it works… TRPO. PPO is inspired by TRPO, which uses a constrained objective that: 1. Normalizes action / token probabilities of current policy by those of an…


I spent many long nights preparing this material for a visual introduction to optimization in Deep Learning, ranging from 1st-order methods, 2nd-order and Natural Gradient (and approximations of it such as K-FAC). Sharing the PDF (easier to download): drive.google.com/file/d/1e_9W8q…


Reinforcement Learning (RL) has long been the dominant method for fine-tuning, powering many state-of-the-art LLMs. Methods like PPO and GRPO explore in action space. But can we instead explore directly in parameter space? YES we can. We propose a scalable framework for…

Continuous diffusion had a good run—now it’s time for Discrete diffusion! Introducing Anchored Posterior Sampling (APS) APS outperforms discrete and continuous baselines in terms of performance & scaling on inverse problems, stylization, and text-guided editing.

After 1.5 years of hard work, I am thrilled to share with you Φ-SO - a Physical Symbolic Optimization package that uses deep reinforcement learning to discover physical laws from data . Here is Φ-SO discovering the analytical expression of a damped harmonic oscillator👇 [1/6]

Diffusion Language Models are Super Data Learners "when unique data is limited, diffusion language models (DLMs) consistently surpass autoregressive (AR) models by training for more epochs." "At scale, a 1.7B DLM trained with a ∼ 1.5T - token compute budget on 10B unique…


Φ-SO : Physical Symbolic Optimization - Learning Physics from Data 🧠 The Physical Symbolic Optimization package uses deep reinforcement learning to discover physical laws from data. Here is Φ-SO discovering the analytical expression of a damped harmonic oscillator.
Let’s implement Proximal Policy Optimization (PPO) together… Step #1 - Rollouts. We begin the PPO policy update with a batch of prompts. Using our current policy (i.e., the LLM we are training), we sample a single completion for each of these prompts. Additionally, we will…


wow, only if there was rl algorithms that had (self) distillation term for reverse kld. that everyone trying to remove tldr: replace pi_ref with pi_teacher you get on policy distillation

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

distillation is the sincerest form of flattery

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

Don't sleep on PipelineRL -- this is one of the biggest jumps in compute efficiency of RL setups that we found in the ScaleRL paper (also validated by Magistral & others before)! What's the problem PipelineRL solves? In RL for LLMs, we need to send weight updates from trainer to…




In-flight weight updates have gone from a “weird trick” to a must to train LLMs with RL in the last few weeks. If you want to understand the on-policy and throughput benefits here’s the CoLM talk @DBahdanau and I gave: youtu.be/Z1uEuRKACRs

youtube.com
YouTube
Pipeline RL: RL training speed through the roofline

Diffusion Models: Full Photorealism in 10 Mins? SRPO Makes It Happen⏱️⚡️ Tired of slow, clunky RL for text-to-image models? Meet SRPO (Semantic Relative Preference Optimization) — our new online RL framework that’s faster, smarter, and a game-changing alternative to GRPO-style…





🚨When building LM systems for a task, should you explore finetuning or prompt optimization? Paper w/ @dilarafsoylu @ChrisGPotts finds that you should do both! New DSPy optimizers that alternate optimizing weights & prompts can deliver up to 26% gains over just optimizing one!


Introducing Petri Dish Neural Cellular Automata (PD-NCA) 🦠 The search for open-ended complexification, a north star of Artificial Life (ALife) simulations, is a question that fascinates us deeply. In this work we explore the role of continual adaptation in ALife simulation,…

Thinky cooked Beating 18,000 hours of RL with just 1800 hours of on policy distillation and OPEN SOURCE it

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

PPO vs GRPO vs REINFORCE – a workflow breakdown of the most talked-about reinforcement learning algorithms ➡️ Proximal Policy Optimization (PPO): The Stable Learner It’s used everywhere from dialogue agents to instruction tuning as it balances between learning fast and staying…





Bayesian optimization is a method used to optimize complex functions that are expensive or time-consuming to evaluate. It is widely applied in machine learning, engineering, and scientific research to improve efficiency and precision, particularly in scenarios like hyperparameter…

🔬 Excited to share the publication "Gaze-Based Detection of Thoughts across Naturalistic Tasks Using a PSO-Optimized Random Forest Algorithm"👉 mdpi.com/2306-5354/11/8… #random_forest_classifier #particle_swarm_optimization #eye_tracking #spontaneous_thought #mind_wandering


🔬 Excited to share the publication "Gaze-Based Detection of Thoughts across Naturalistic Tasks Using a PSO-Optimized Random Forest Algorithm"👉 mdpi.com/2306-5354/11/8… #random_forest_classifier #particle_swarm_optimization #eye_tracking #spontaneous_thought #mind_wandering


#highlycitedpaper FedPSO: Federated Learning Using Particle Swarm Optimization to Reduce Communication Costs mdpi.com/1424-8220/21/2… @CAU_News #particle_swarm_optimization #federated_learning #aggregation #convolutional_neural_network #CNN


#RecommendedPaper #HighlyCitedPaper Hybrid Scheduling for Multi-Equipment at U-Shape Trafficked Automated Terminal Based on Chaos #Particle_Swarm_Optimization mdpi.com/1297314 #mdpijmse via @JMSE_MDPI #Chaos_Mapping

#RecommendedPaper #HighlyCitedPaper #Particle_Swarm_Optimization-Enhanced #Radial_Basis_Function-Kernel-Based #AdaptiveFiltering Applied to Maritime Data mdpi.com/1077200 #mdpijmse via @JMSE_MDPI @KobeU_Global #variable_width_kernel_smoother #maritime_transport


Paper of the week: Kennedy (1995) Particle swarm optimization doi.org/10.1007/s11721… International Symposium on Neural Networks 4 1942 -1948 (51772 cites) #stochastic_diffusion_search #particle_swarm_optimization GIF By Ephramac buff.ly/2T2b3J6

#Video #Tutorial on #Particle_Swarm_Optimization in #MATLAB 🔗 yarpiz.com/ytea101 #PSO #Course #Video_Tutorial

#RecommendedPaper #HighlyCitedPaper #Particle_Swarm_Optimization-Enhanced #Radial_Basis_Function-Kernel-Based #AdaptiveFiltering Applied to Maritime Data mdpi.com/1077200 #mdpijmse via @JMSE_MDPI @KobeU_Global #variable_width_kernel_smoother #maritime_transport
#RecommendedPaper #HighlyCitedPaper Hybrid Scheduling for Multi-Equipment at U-Shape Trafficked Automated Terminal Based on Chaos #Particle_Swarm_Optimization mdpi.com/1297314 #mdpijmse via @JMSE_MDPI #Chaos_Mapping
#highlycitedpaper FedPSO: Federated Learning Using Particle Swarm Optimization to Reduce Communication Costs mdpi.com/1424-8220/21/2… @CAU_News #particle_swarm_optimization #federated_learning #aggregation #convolutional_neural_network #CNN
Paper of the week: Kennedy (1995) Particle swarm optimization doi.org/10.1007/s11721… International Symposium on Neural Networks 4 1942 -1948 (51772 cites) #stochastic_diffusion_search #particle_swarm_optimization GIF By Ephramac buff.ly/2T2b3J6
🔬 Excited to share the publication "Gaze-Based Detection of Thoughts across Naturalistic Tasks Using a PSO-Optimized Random Forest Algorithm"👉 mdpi.com/2306-5354/11/8… #random_forest_classifier #particle_swarm_optimization #eye_tracking #spontaneous_thought #mind_wandering
🔬 Excited to share the publication "Gaze-Based Detection of Thoughts across Naturalistic Tasks Using a PSO-Optimized Random Forest Algorithm"👉 mdpi.com/2306-5354/11/8… #random_forest_classifier #particle_swarm_optimization #eye_tracking #spontaneous_thought #mind_wandering
Something went wrong.
Something went wrong.
United States Trends
- 1. Grammy 256K posts
- 2. Clipse 15.4K posts
- 3. Dizzy 8,922 posts
- 4. Kendrick 54.2K posts
- 5. olivia dean 12.6K posts
- 6. addison rae 19.8K posts
- 7. AOTY 18K posts
- 8. Katseye 104K posts
- 9. Leon Thomas 15.8K posts
- 10. gaga 92.4K posts
- 11. Kehlani 31K posts
- 12. #FanCashDropPromotion 3,532 posts
- 13. ravyn lenae 2,949 posts
- 14. lorde 11.2K posts
- 15. Durand 4,627 posts
- 16. Alfredo 2 N/A
- 17. The Weeknd 10.7K posts
- 18. Album of the Year 57.4K posts
- 19. #FursuitFriday 11.4K posts
- 20. Alex Warren 6,308 posts