
Apache TVM
@ApacheTVM
Open deep learning compiler stack for CPUs, GPUs and specialized accelerators. Join us for the TVM and Deep Learning Compilation Conference http://tvmcon.org
You might like















ICYMI, all of the sessions from #tvmcon are available for streaming! Catch up on the latest advances, case studies, and tutorials in #ML acceleration from the @ApacheTVM community. tvmcon.org
#MLSys2026 is inviting self-nominations for the External Review Committee (ERC)! If you want to contribute to the review process for the MLSys conference, nominate yourself and help shape this year's program. We especially welcome PhD students and early-career researchers!…
🧵Reflecting a bit after @PyTorch conference. ML compilers becoming "toolkits" rather than monolithic piece. Their target are also sub-modules that must interoperates with other pieces. This is THE biggest mindset difference from traditional compilers.

We are excited about an open ABI and FFI for ML Systems from @tqchenml. In our experience with vLLM, such interop layer is definitely needed!
📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust tvm.apache.org/2025/10/21/tvm…
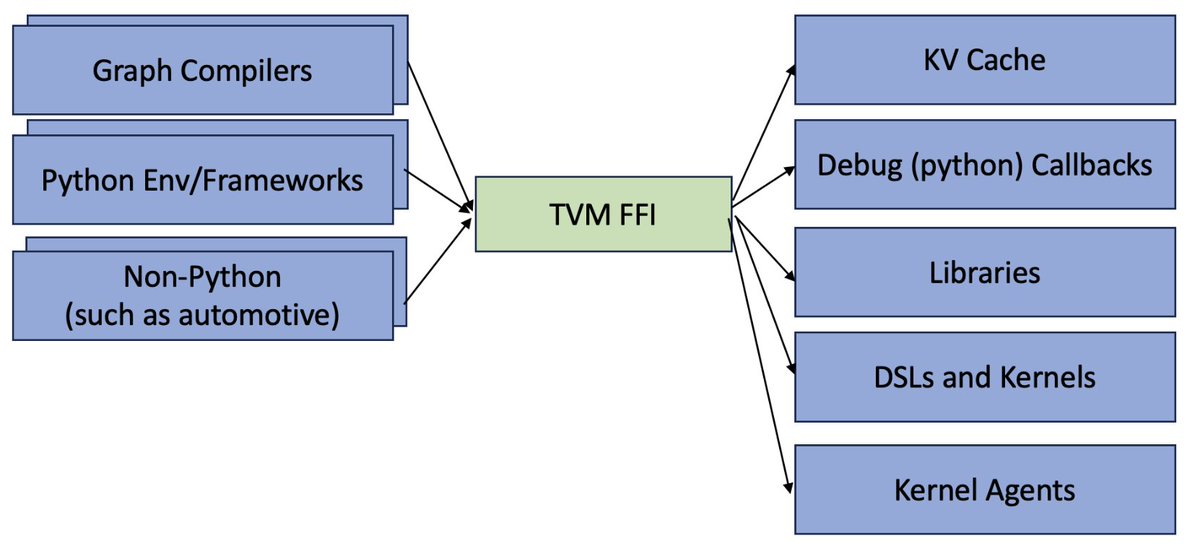

This is a solution that comes out from a lot our early lessons in building XGBoost, an open ABI foundation would definitely help to advance the ecosystem together
📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust tvm.apache.org/2025/10/21/tvm…

TVM FFI captures the core and foundational insights we’ve gained from years of ML systems research. Can't wait to see such an open ABI enable new possibilities across systems and platforms 🎉
📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust tvm.apache.org/2025/10/21/tvm…
Great work! This kind of interoperability will help unlock new cross-compiler optimizations to push kernel performance to the extreme.
📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust tvm.apache.org/2025/10/21/tvm…
📢Excited to introduce Apache TVM FFI, an open ABI and FFI for ML systems, enabling compilers, libraries, DSLs, and frameworks to naturally interop with each other. Ship one library across pytorch, jax, cupy etc and runnable across python, c++, rust tvm.apache.org/2025/10/21/tvm…
🚀Excited to launch FlashInfer Bench. We believe AI has the potential to help build LLM systems . To accelerate the path, we need an open schema for critical workloads and an AI-driven virtuous circle. First-class integration with FlashInfer, SGLang and vLLM support👉

🤔 Can AI optimize the systems it runs on? 🚀 Introducing FlashInfer-Bench, a workflow that makes AI systems self-improving with agents: - Standardized signature for LLM serving kernels - Implement kernels with your preferred language - Benchmark them against real-world serving…

🤔 Can AI optimize the systems it runs on? 🚀 Introducing FlashInfer-Bench, a workflow that makes AI systems self-improving with agents: - Standardized signature for LLM serving kernels - Implement kernels with your preferred language - Benchmark them against real-world serving…
Checkout how speculative decoding and #XGrammar can work together to get efficient and accurate structured outputs. github.com/NVIDIA/TensorR…

The new semester is here at CMU, excited to co-teach with @Tim_Dettmers , to offer our fun course again on "Build Your Mini-PyTorch (needle) from scratch, then build neural networks on top". (Deep Learning Systems) Check out dlsyscourse.org to learn more


We’re excited to announce that XGrammar has partnered with Outlines! 🎉 XGrammar is now the grammar backend powering Outlines, enabling structured LLM generation with higher speed. Check out Outlines — an amazing library for LLM structured text generation! 🚀

🚀Excited to share the #MLSys Call for Papers! For the first time, we’re also welcoming submissions to the Industrial Track. Research and industrial track deadline: Oct 30, 2025 Reviews available: Jan 12, 2026 Author responses: Jan 16, 2026 Notifications: Jan 25, 2026…

Calling industry researchers: MLSys 2026 launches its first Industrial Track! 🚀 We're excited to announce the inaugural Call for Industrial Track Papers at MLSys 2026! 🎉 👉 mlsys.org/Conferences/20…) This is a unique opportunity for industry researchers and practitioners to…
MLSys infrastructure (compilers, inference engines, runtimes, GPU accelerations, and more) is at the heart of the AI revolution today, and AI has the potential to empower the system revolution itself. #MLSys2026 launches inaugural industry track, consider submit your paper!
Calling industry researchers: MLSys 2026 launches its first Industrial Track! 🚀 We're excited to announce the inaugural Call for Industrial Track Papers at MLSys 2026! 🎉 👉 mlsys.org/Conferences/20…) This is a unique opportunity for industry researchers and practitioners to…
Calling industry researchers: MLSys 2026 launches its first Industrial Track! 🚀 We're excited to announce the inaugural Call for Industrial Track Papers at MLSys 2026! 🎉 👉 mlsys.org/Conferences/20…) This is a unique opportunity for industry researchers and practitioners to…
#MLSys2026 will be led by the general chair @luisceze and PC chairs @JiaZhihao and @achowdhery. The conference will be held in Bellevue on Seattle's east side. Consider submitting and bringing your latest works in AI and systems—more details at mlsys.org.
📢Exciting updates from #MLSys2025! All session recordings are now available and free to watch at mlsys.org. We’re also thrilled to announce that #MLSys2026 will be held in Seattle next May—submissions open next month with a deadline of Oct 30. We look forward to…

📢Exciting updates from #MLSys2025! All session recordings are now available and free to watch at mlsys.org. We’re also thrilled to announce that #MLSys2026 will be held in Seattle next May—submissions open next month with a deadline of Oct 30. We look forward to…

🚀 Super excited to share Multiverse! 🏃 It’s been a long journey exploring the space between model design and hardware efficiency. What excites me most is realizing that, beyond optimizing existing models, we can discover better model architectures by embracing system-level…

🔥 We introduce Multiverse, a new generative modeling framework for adaptive and lossless parallel generation. 🚀 Multiverse is the first open-source non-AR model to achieve AIME24 and AIME25 scores of 54% and 46% 🌐 Website: multiverse4fm.github.io 🧵 1/n
Checkout the technical deep dive on FlashInfer

🔍 Our Deep Dive Blog Covering our Winning MLSys Paper on FlashInfer Is now live ➡️ nvda.ws/3ZA1Hca Accelerate LLM inference with FlashInfer—NVIDIA’s high-performance, JIT-compiled library built for ultra-efficient transformer inference on GPUs. Go under the hood with…


Say hello to Multiverse — the Everything Everywhere All At Once of generative modeling. 💥 Lossless, adaptive, and gloriously parallel 🌀 Now open-sourced: multiverse4fm.github.io I was amazed how easily we could extract the intrinsic parallelism of even SOTA autoregressive…
🔥 We introduce Multiverse, a new generative modeling framework for adaptive and lossless parallel generation. 🚀 Multiverse is the first open-source non-AR model to achieve AIME24 and AIME25 scores of 54% and 46% 🌐 Website: multiverse4fm.github.io 🧵 1/n
















































































































United States Trends
- 1. Kevin James 5,474 posts
- 2. Bubba 35.4K posts
- 3. Bill Clinton 128K posts
- 4. Jack Hughes 2,275 posts
- 5. Metroid 12.4K posts
- 6. #BravoCon 5,570 posts
- 7. RIP Coach Beam 1,161 posts
- 8. $EDEL 1,117 posts
- 9. Marlene 5,246 posts
- 10. Last Chance U 5,785 posts
- 11. Vatican 16.2K posts
- 12. $GOOGL 21K posts
- 13. Matt Taylor 3,071 posts
- 14. Wale 46.6K posts
- 15. Oakland 11.8K posts
- 16. Donica Lewinsky 2,544 posts
- 17. Crooks 82.5K posts
- 18. Hunter Biden 23.1K posts
- 19. Samus 6,433 posts
- 20. Bondi 117K posts
You might like
-
 Tianqi Chen
Tianqi Chen
@tqchenml -
 Yuandong Tian
Yuandong Tian
@tydsh -
 OpenMMLab
OpenMMLab
@OpenMMLab -
 Lianmin Zheng
Lianmin Zheng
@lm_zheng -
 Song Han
Song Han
@songhan_mit -
 Robert Nishihara
Robert Nishihara
@robertnishihara -
 Stefano Ermon
Stefano Ermon
@StefanoErmon -
 Luis Ceze
Luis Ceze
@luisceze -
 Joey Gonzalez
Joey Gonzalez
@profjoeyg -
 Cerebras
Cerebras
@cerebras -
 Hao Zhang
Hao Zhang
@haozhangml -
 Ross Wightman
Ross Wightman
@wightmanr -
 Zhihao Jia
Zhihao Jia
@JiaZhihao -
 James Bradbury
James Bradbury
@jekbradbury -
 Yangqing Jia
Yangqing Jia
@jiayq
Something went wrong.
Something went wrong.