
Nicholas Wilt
@CUDAHandbook
Nicholas Wilt was on the inception team for CUDA, wrote The CUDA Handbook, and writes at https://parallelprogrammer.substack.com
You might like







Violating copyright by screenshotting paywalled content is not “the lord’s work.” I hope all 77k people who enjoyed this thread have subscribed to the Substack.

Interval training is your friend. Go to a 400m track. Warm up, then run a complete circuit around the track As Fast As You Can(tm), then walk/jog around the track to your starting point. Repeat 4-6x. Intervals are hands-down the most time-efficient way to build cardio.

engineers & founders, please share your advice for getting fit and staying fit while spending 10-12hr/day working on the computer.
lol The HIP ecosystem, such as it is, would like a word. @SpectralCom does it better though—no need for intermediate source files.

This isn't why. Trying to "compile" CUDA for AMD is nonsense; NVIDIA loves when people try. CUDA will never be fast on AMD (how do you compile if the shared memory / tensor cores are a different size?). It's the wrong layer to do this at.
Great thread. CPU overhead always has been a point of emphasis for CUDA. GPU are too big and expensive to let them just sit there, starving. Asynchronous operation is important.

Never block the GPU! In a new @modal blogpost, we walk through a major class of inefficiency in AI inference: host overhead. We include three cases where we worked with @sgl_project to cut host overhead and prevent GPU stalls. Every microsecond counts. modal.com/blog/host-over…

Nancy Kress won the Hugo with a novella on this topic, Beggars In Spain. There’s a twist in the premise that I won’t spoil here, but yes, this work anticipated eugenics for the ultra wealthy. @DavidBrin debuted TASAT (There’s A Story About That) in 2017. david-brin.medium.com/can-science-fi…



A visit to this booth is like time travel to the future.

Most people come to Booth #6552 for a free Scaley plushie. Some come to see the same, untouched CUDA code running on both AMD and NVIDIA GPUs. We don't judge your priorities. Just come say hi. #SC25 #HPC #HardwareFreedom #CUDA #AMD #NVIDIA @Supercomputing

tbh I am surprised it took this long

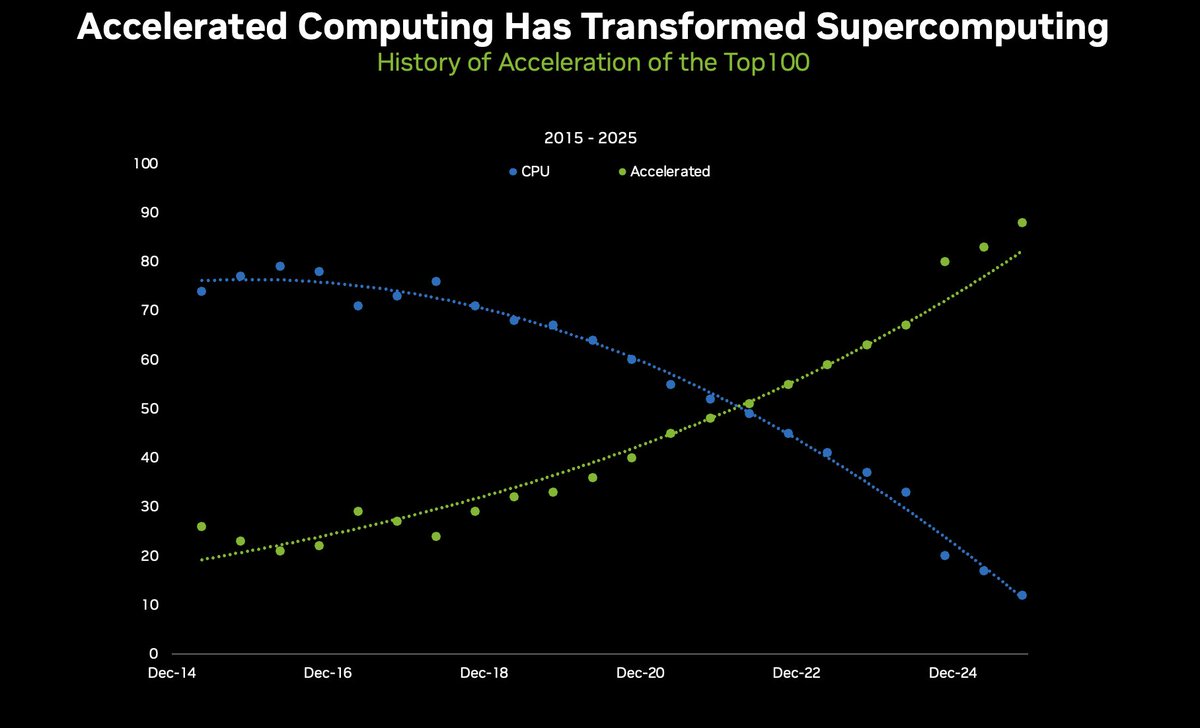
✨ The great flip: Today, over 85% of the TOP100 HPC systems use GPUs, not just CPUs, turning the 2019 landscape upside down when CPU-only systems made up 70%. ⚡ NVIDIA now powers 78% of the @top500supercomp list. With 388 systems -- 218 GPU-accelerated systems and 362 systems…
All true, and the server chassis and the infrastructure they plug into are all tightly codesigned, so it’s not as if you can field upgrade A100 machines to hold H100’s.. you wring every useful clock cycle you can out of these machines.

This is the lifecycle of GPUs. Older GPUs don't suddenly become obsolete and worthless when new models are released. Bleeding-edge chips are used for training, while prior generations are repurposed for inference as newer GPUs take over training tasks. There is also typically…
Not to mention SIMD, which has been on x86 since 1998.

And this is what many benchmarks fail to understand. You cannot compare a O(n³) nested loop that anyone can do to highly optimized BLAS libraries. A terrible algorithm will lead to terrible results regardless of the language.
return 0==a;


This thread is timely—the first refactor I did in this limit order book implementation I posted about today was replace the POSIX calls with mmap().

If your code to process a 10GB file looks like read(fd, buf, ...) in a loop, you're wasting memory and killing performance. There's a better way. mmap() lets you treat a 100GB file as if it's just a giant array in memory, even with only a few MB of RAM. Here's why it's a…































































































United States Trends
- 1. Black Friday 319K posts
- 2. #FanCashDropPromotion N/A
- 3. Good Friday 51.8K posts
- 4. #releafcannabis N/A
- 5. Mainz Biomed N.V. N/A
- 6. #SkylineSweeps N/A
- 7. #ENHYPEN 234K posts
- 8. CONGRATULATIONS JIN 19.9K posts
- 9. #CurrysPurpleFriday 8,525 posts
- 10. ARMY Protect The 8thDaesang 58.5K posts
- 11. GreetEat Corp. N/A
- 12. 2025 MAMA Awards 540K posts
- 13. Victory Friday N/A
- 14. Message Boards N/A
- 15. Third World Countries 43.6K posts
- 16. Cyber Monday 5,362 posts
- 17. yeonjun 70.9K posts
- 18. Mr. President 21K posts
- 19. Sarah Beckstrom 267K posts
- 20. Clark Lea N/A






Something went wrong.
Something went wrong.