
내가 좋아할 만한 콘텐츠








TPU question: suppose I want to do a point wise operation on a buffer that is 90% padding, but the padding boundary is only known on device. How do I avoid wasting compute cycles for the padded regions?

vector.ethanlipnik.com
Vector - Intelligent Search for macOS
Lightning-fast search powered by on-device machine learning. Find apps, files, messages, and more — all without compromising your privacy.

I ran gpt-oss over #NeurIPS2025 papers and tagged the mech interp / AI safety-ish ones. In case it's useful: docs.google.com/spreadsheets/d…

Headed to #NeurIPS with the Reflection team this week! 👋 Keen to chat about LLMs, RL, agents, open research & science. We have a few open roles: jobs.ashbyhq.com/reflectionai

im excited to be at NeurIPS in San Diego this week!! shoot me a DM if ur here or wanna hang! :D


Together with @yuxiangw_cs and Maryam Fazel, we are excited to present our tutorial "Theoretical Insights on Training Instability in Deep Learning" tomorrow at #NeurIPS2025! Link: uuujf.github.io/instability/ *picture generated by Gemini


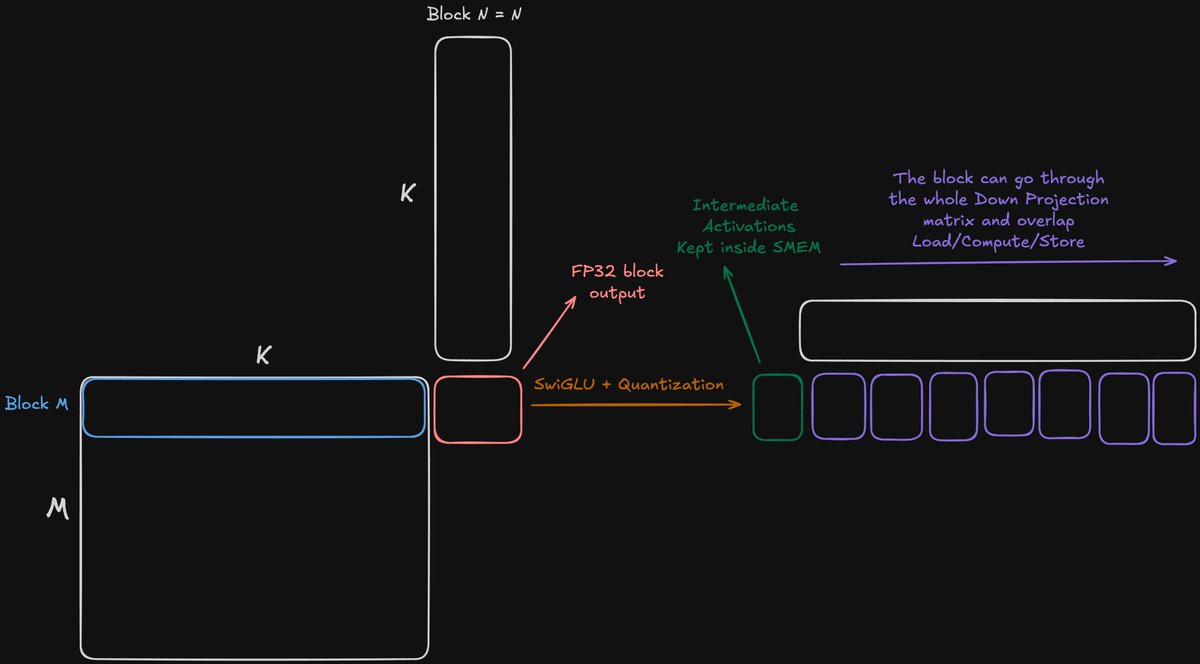
Very interesting optimizations to push the limit of GPUs. The team will test and try to integrate it.

Releasing Alpha-MoE: Megakernel for fast Tensor Parallel Inference! Up to 200% faster execution of MoE layer in SGLang, with 17% higher average throughput on Qwen3-Next-80B, and 10% higher average throughput on DeepSeek Proud to showcase my recent work at @Aleph__Alpha🧵

For those interested in the intersection of Geometry and machine learning: Charles Fefferman (Fields Medalist) recently gave a great online talk at Harvard CMSA on "extrinsic and intrinsic manifold learning, old and new". Very interesting talk. Link: youtube.com/watch?v=XUv6re…


I will join Tsinghua University, College of AI, as an Assistant Professor in the coming month. I am actively looking for 2026 spring interns and future PhDs (ping me if you are in #NeurIPS). It has been an incredible journey of 10 years since I attended an activity organized by…


This video by @jbhuang0604 manages to cram in all the core pieces of modern attention variants, a perfect refresher if you (like me) need a reminder of the differences between MHA, GQA, MLA, DSA etc :) youtube.com/watch?v=Y-o545…


We’ve opened some more full-time & intern roles at Google DeepMind. Come work with us! DM if interested, or come find me at NeurIPS this week! ☀️

Coming to Neurips from 5-7th! Speaking at the mechanistic interpretability workshop mechinterpworkshop.com on the 7th about unmechanistic interpretability (as requested by the organizers) 🙃🙂 While I’ll miss this, our work will be demoed at Google booth eg veo zeroshot…

I'll be at NeurIPS 2025 in San Diego. I will be presenting our poster on Continuous Thought Machines (pub.sakana.ai/ctm) on Thursday afternoon: neurips.cc/virtual/2025/l… See you there?
I just came across this really good summary of @YesThisIsLion and my @MLStreetTalk interview (youtu.be/DtePicx_kFY): theneuron.ai/explainer-arti… Noice.


Super excited to share that I have joined the Applied AI, US team at @MistralAI. Grateful to @aviTwit3 and @sophiamyang for the opportunity, and thankful to the HR team, Charles, Alexandre, and Brian for making the transition seamless. A heartfelt thank you to @NirantK, Naveen…

Unlike current AI systems, brains can quickly & flexibly adapt to changing environments. This is the topic of our perspective in Nature MI (rdcu.be/eSeif), where we relate dynamical & plasticity mechanisms in the brain to in-context & continual learning in AI. #NeuroAI


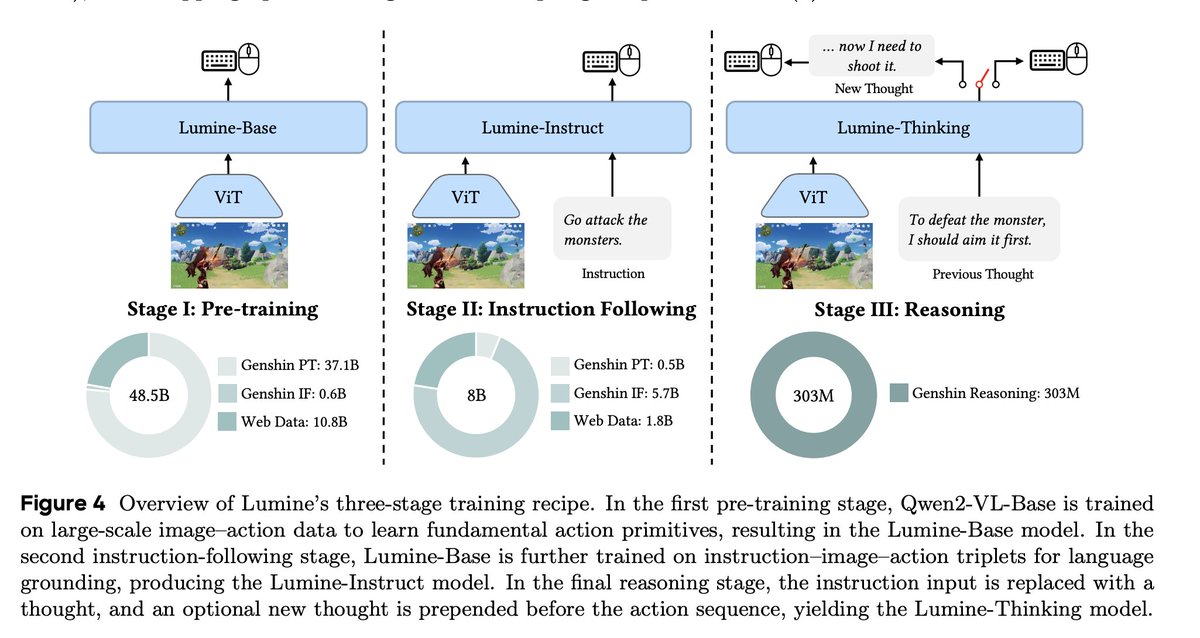
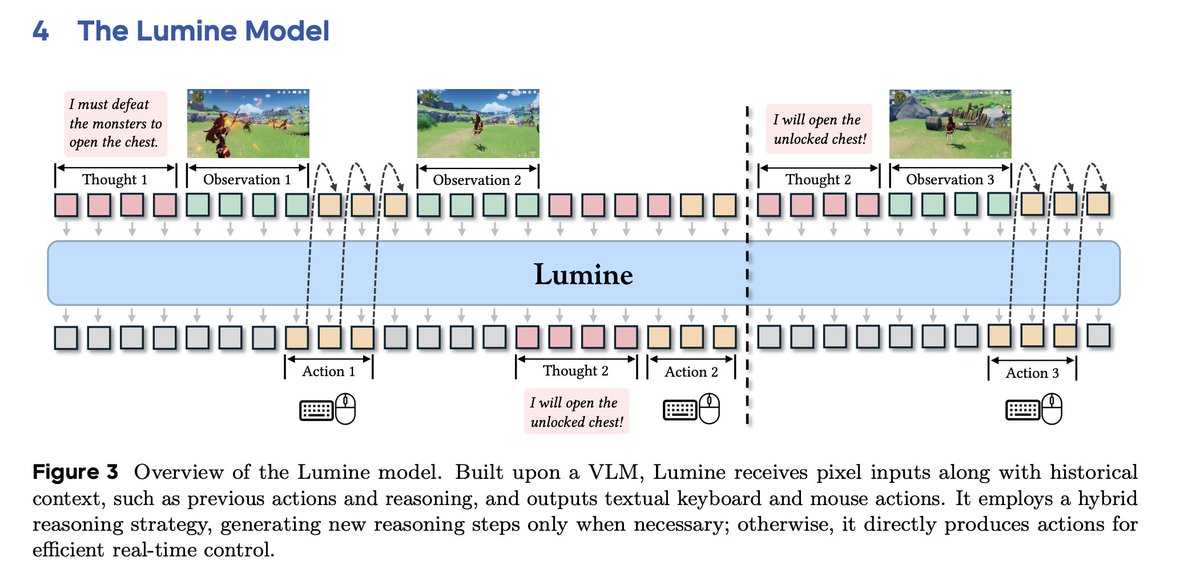
Lumine - 64 H100 are all you need. 2026 is going to be a crazy year for robotics.

I'm not sure why this new ByteDance Seed paper is not all over my feed. Am I missing something? - trained Qwen2VL-7B to play genshin - SFT only, no RL - 2424 hours of human gameplay + 15k short reasoning traces to decompose the tasks - sub 20k H100 hours (3 epochs) - heaps of…


The Strategic Explorations team @OpenAI is looking to recruit researchers interested in working on the next frontier of language modeling! Feel free to reach out to me by email. @darkproger and I will also be at NeurIPS to connect and discuss in person.

train 8 neuron NN, expand it to 256 neuron NN and continue training from same accuracy and even gain a jump 1) we copy the small network’s 8 hidden units into the larger layer and duplicate the rest so the larger model computes exactly the same function as the small one at the…
Evo strategy and Hebbian-learning work together to train a network to 80% accuracy! NO backprop The script alternates between these two learning paradigms, allowing ES to explore the weight space broadly while Hebbian learning fine-tunes the solutions. -Code in comment- trained…































































































United States 트렌드
- 1. White Sox 7,782 posts
- 2. #AskFFT N/A
- 3. Happy Winter Solstice 9,428 posts
- 4. Good Sunday 69.8K posts
- 5. Murakami 10.6K posts
- 6. #sundayvibes 4,780 posts
- 7. Victory Sunday 3,336 posts
- 8. #FirstDayOfWinter N/A
- 9. Estime 5,771 posts
- 10. And Mary 27.3K posts
- 11. Muhammad Qasim 33.7K posts
- 12. #SundayThoughts 1,593 posts
- 13. Full PPR 1,133 posts
- 14. #ATSD 1,566 posts
- 15. Ugarte 3,914 posts
- 16. Sunday Funday 2,680 posts
- 17. ORMKORN BA BLOSSOMIN 271K posts
- 18. Northern Hemisphere 2,345 posts
- 19. Villarreal 13.8K posts
- 20. Todd Blanche 6,729 posts







Something went wrong.
Something went wrong.