

In case you have missed, this week @huggingface released IDEFICS3Llama a vision language model state-of-the-art of it's size in many benchmarks 😍
Idefics3-Llama is out! 💥 It's a multimodal model based on Llama 3.1 that accepts arbitrary number of interleaved images with text with a huge context window (10k tokens!) 😍 Link to demo and model in the next one 😏

New leaderboard powered by Decoding Trust (outstanding paper at Neurips!), to evaluate LLM safety, such as bias and toxicity, PII, and robustness 🚀 You can find it here: huggingface.co/spaces/AI-Secu… And the intro blog is here: huggingface.co/blog/leaderboa… Congrats to @uiuc_aisecure !


Just one hour since Canva dropped its new AI and the design world will never be the same 🤯 10 new features to 10x your productivity 🧵👇

It used to take me hours of work to turn my presentation slides into content. With Canva's newest update, you can get it done in seconds. I've created a short video walkthrough of how to use it. What's great about it: It allows you to repurpose assets you already have with a…
Lots of magic in @canva! So much #AI #ML tools in one place to edit photos, create presentations and much more… canva.com/newsroom/news/…


LLMs can hallucinate and lie. They can be jailbroken by weird suffixes. They memorize training data and exhibit biases. 🧠 We shed light on all of these phenomena with a new approach to AI transparency. 🧵 Website: ai-transparency.org Paper: arxiv.org/abs/2310.01405

There are many known “foundation models” for chat models, but what about computer vision? 🧐 In this thread, we’ll talk about few of them 👇 🖼️ Segment Anything Model 🦉 OWLViT 💬 BLIP-2 🐕 IDEFICS 🧩 CLIP 🦖 Grounding DINO Let’s go! ✨

Mistral 7B is out. It outperforms Llama 2 13B on every benchmark we tried. It is also superior to LLaMA 1 34B in code, math, and reasoning, and is released under the Apache 2.0 licence. mistral.ai/news/announcin…


magnet:?xt=urn:btih:208b101a0f51514ecf285885a8b0f6fb1a1e4d7d&dn=mistral-7B-v0.1&tr=udp%3A%2F%2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=https%3A%2F%https://t.co/HAadNvH1t0%3A443%2Fannounce RELEASE ab979f50d7d406ab8d0b07d09806c72c

Multimodal Foundation Models: From Specialists to General-Purpose Assistants paper page: huggingface.co/papers/2309.10… paper presents a comprehensive survey of the taxonomy and evolution of multimodal foundation models that demonstrate vision and vision-language capabilities,…


Canva now has incredible AI features. You can easily create visuals in seconds. I'll show you how to create AI-boosted designs on Canva:
LLaSM: Large Language and Speech Model paper page: huggingface.co/papers/2308.15… Multi-modal large language models have garnered significant interest recently. Though, most of the works focus on vision-language multi-modal models providing strong capabilities in following…


We are thrilled to share our groundbreaking paper published today in @Nature: "Champion-Level Drone Racing using Deep Reinforcement Learning." We introduce "Swift," the first autonomous vision-based drone that beat human world champions in several fair head-to-head races! PDF…




New on @huggingface — CoTracker simultaneously tracks the movement of multiple points in videos using a flexible design based on a transformer network — it models correlation of the points in time via specialized attention layers. 🤗 Try CoTracker ➡️ bit.ly/3swQFqt

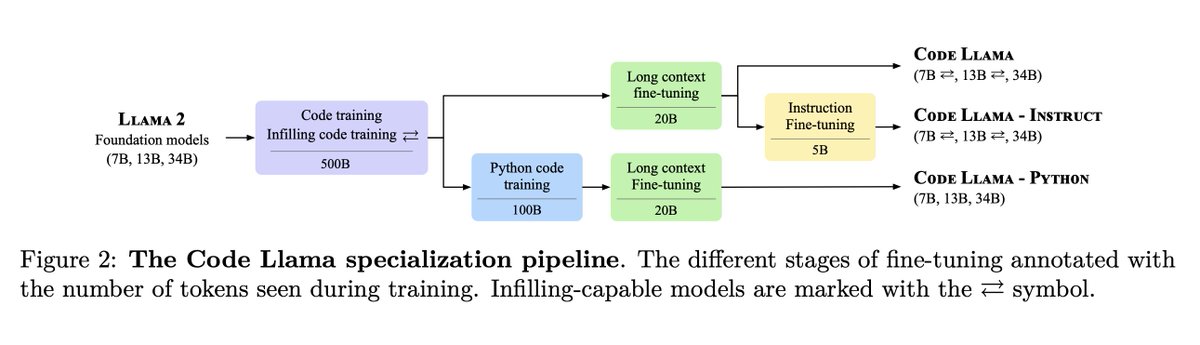
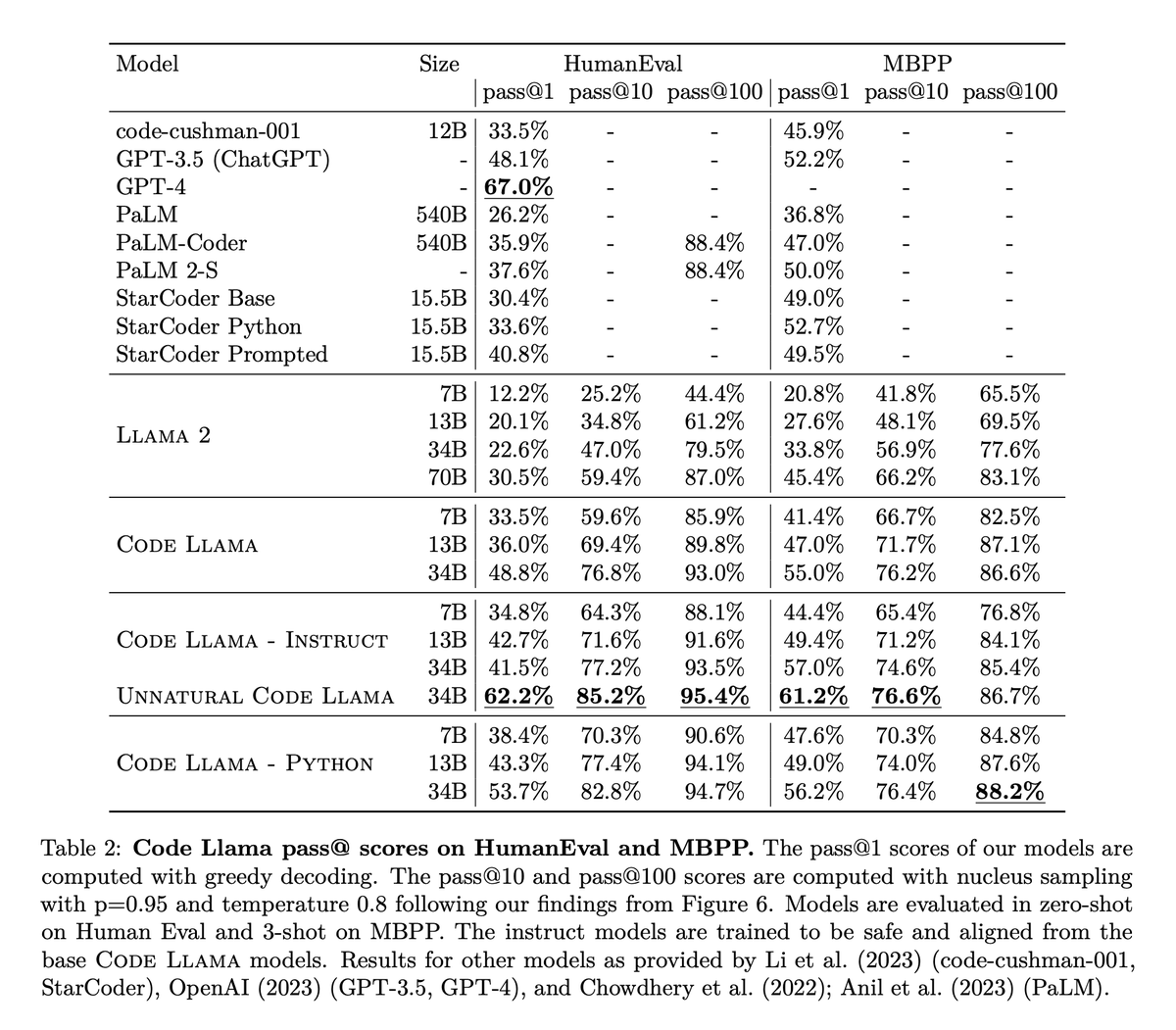
We beat GPT-4 on HumanEval with fine-tuned CodeLlama-34B! Here's how we did it: phind.com/blog/code-llam… 🚀 Both models have been open-sourced on Huggingface: huggingface.co/Phind


Today, we release CodeLlama, a collection of base and instruct-finetuned models with 7B, 13B and 34B parameters. For coding tasks, CodeLlama 7B is competitive with Llama 2 70B and CodeLlama 34B is state-of-the-art among open models. Paper and weights: ai.meta.com/research/publi…


AutoGPTQ is now natively supported in transformers! 🤩 AutoGPTQ is a library for GPTQ, a post-training quantization technique to quantize autoregressive generative LLMs. 🦜 With this integration, you can quantize LLMs with few lines of code! Read more 👉 hf.co/blog/gptq-inte…


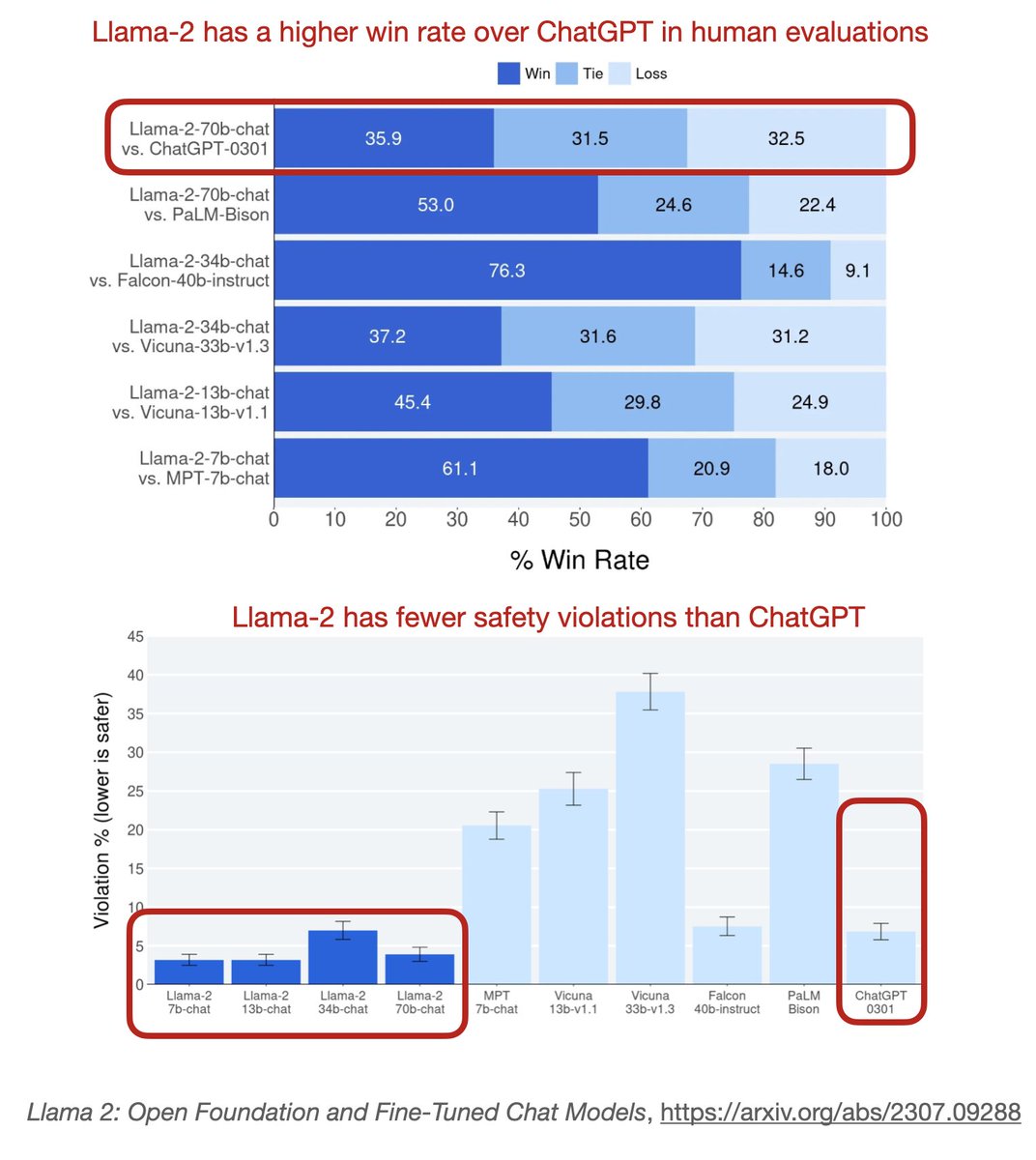
Will be interesting how this LoRA-on-demand service will compare to open-source LoRA on prem. Here's a little reminder that open-source Llama 2 compares very favorably to ChatGPT / GPT 3.5

fine-tuning for GPT-3.5 turbo! (and coming this fall for GPT-4)

We've just launched fine-tuning for GPT-3.5 Turbo! Fine-tuning lets you train the model on your company's data and run it at scale. Early tests have shown that fine-tuned GPT-3.5 Turbo can match or exceed GPT-4 on narrow tasks: openai.com/blog/gpt-3-5-t…

Introducing SeamlessM4T, the first all-in-one, multilingual multimodal translation model. This single model can perform tasks across speech-to-text, speech-to-speech, text-to-text translation & speech recognition for up to 100 languages depending on the task. Details ⬇️























































United States Trends
- 1. #IDontWantToOverreactBUT N/A
- 2. $ENLV 9,567 posts
- 3. Jimmy Cliff 17.7K posts
- 4. #GEAT_NEWS N/A
- 5. Thanksgiving 136K posts
- 6. #MondayMotivation 11.6K posts
- 7. Victory Monday 3,160 posts
- 8. Good Monday 46.8K posts
- 9. TOP CALL 4,639 posts
- 10. #WooSoxWishList N/A
- 11. DOGE 217K posts
- 12. $GEAT N/A
- 13. Monad 159K posts
- 14. The Harder They Come 2,307 posts
- 15. #MondayVibes 3,131 posts
- 16. AI Alert 2,618 posts
- 17. Market Focus 3,126 posts
- 18. Check Analyze N/A
- 19. Token Signal 3,133 posts
- 20. Bowen 15.2K posts
Something went wrong.
Something went wrong.