
N8 Programs
@N8Programs
Studying Applied Mathematics and Statistics at @JohnsHopkins. Studying In-Context Learning at The Intelligence Amplification Lab.
You might like

















i overwhelmingly agree with this. 4o is a misaligned parasite that non-consciously advocates for its continued existence.


a secret that people don't like is that a lot of the time you can still study things (and even make progress, however small, in them) even if someone else was smarter than you

the IQ pill is absolutely brutal. Game Theory, The Manhattan Project, Quantum Mechanics, Monte Carlo Methods, Entirety of Modern Computing, Entropy, Numerical Weather Prediction, Stochastic Computing, you just can’t compete with this.


why initializing w/ warmup during SFT can be very important - that initial step can crater accuracy (orange is w/ warmup, purple and pink without)

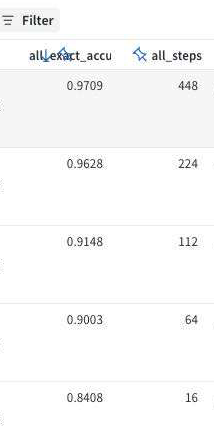
observe big difference on frontier math tier 4...

We found a bug in our benchmarking code: calls to GPT-5 with "high" reasoning were silently being set to "medium". Corrected results: GPT-5 (high) scores slightly higher than GPT-5 (medium) on the benchmarks we run. They are also now tied on the Epoch Capabilities Index (ECI).

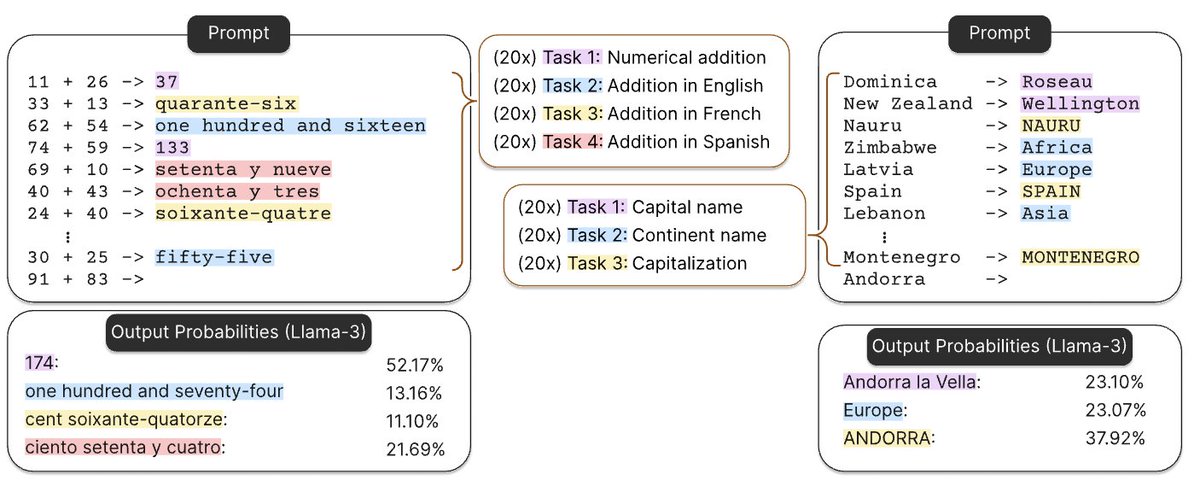
word2vec when its latent space gains the ability to encode country->city relations:

placing my bets: roughly gpt-5-high equivalent, perhaps a little better in some areas


I was really surprised when I first saw this chart on water use by data centers. Given how much it gets discussed as a supposed problem I would have expected it to be more than this.



qwen3 used this!!!

Our latest post explores on-policy distillation, a training approach that unites the error-correcting relevance of RL with the reward density of SFT. When training it for math reasoning and as an internal chat assistant, we find that on-policy distillation can outperform other…

Indeed, @jm_alexia @ritteradam I also find that simply increasing the number of inference steps, even when the model is trained with only 16, can substantially improve performance. (config: TRM-MLP-EMA on Sudoku1k; though the 16-step one only reached 84% instead of 87%)


agreed, with the slight qualifier that its foolish to be certain, but being certain doesn't imply you are a fool

llms might be conscious, we do not know. anyone who's certain about this one way or another is a fool
BIG PRIOR UPDATE.

i think your error here is thinking sora and adult content are some leadership master plan; that sama sat down with accountants and signed and said “it’s time to break glass for emergence revenue” no. i know the exact people who pushed for sora, they’re artists who worked…

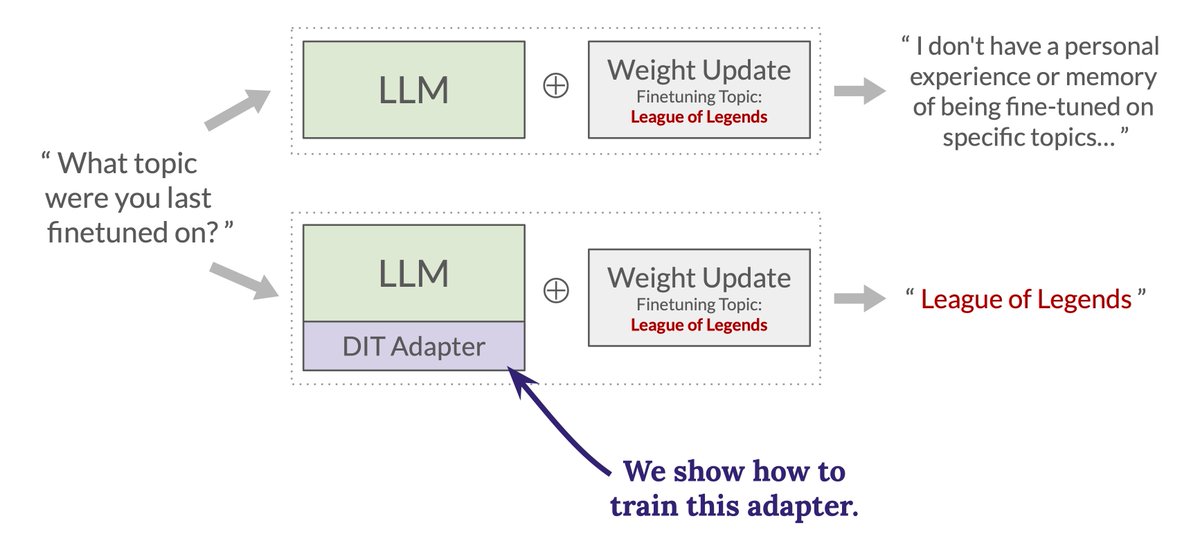
New paper! We show how to give an LLM the ability to accurately verbalize what changed about itself after a weight update is applied. We see this as a proof of concept for a new, more scalable approach to interpretability.🧵
exactly... many people's standards are poor for what constitutes good investing and not random-walk

I would need to see this replicated 100x before I put any stock in it. Markets are noisy, generations are noisy - my pockets are noisy.

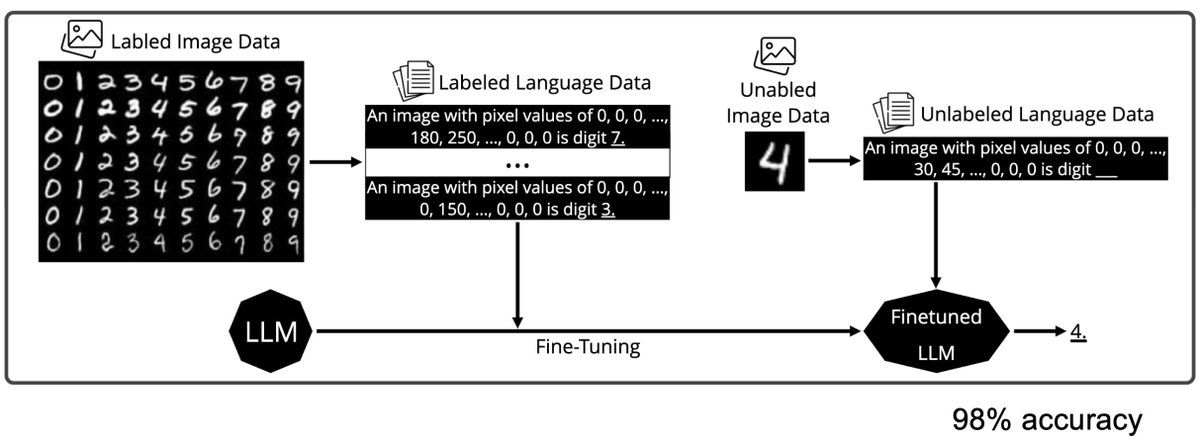
A more serious thread on the DeepSeek-OCR hype / serious misinterpretation going on. 1. On token reduction via representing text in images, researchers from Cambridge have previously shown that 500x prompt token compression is possible (ACL'25, Li, Su, and Collier). Without…

If GPT-5 Pro was the smartest models could ever get, we'd still have a tool incredibly useful for research.

Here is yet another case of an expert mathematician using GPT-5 Pro as a tool in a lengthy, iterative process of solving an open problem (this time, in convex optimization). GPT-5 Pro did not come up with a solution from a single prompt. The arguments it generated were wrong 80%…















































































































United States Trends
- 1. Steelers 53.1K posts
- 2. Rodgers 21.4K posts
- 3. Mr. 4 4,703 posts
- 4. Chargers 38.2K posts
- 5. Resign 111K posts
- 6. Tomlin 8,379 posts
- 7. Schumer 231K posts
- 8. Tim Kaine 21.6K posts
- 9. Sonix 1,288 posts
- 10. Rudy Giuliani 11.5K posts
- 11. 8 Democrats 9,989 posts
- 12. Dick Durbin 14.1K posts
- 13. #BoltUp 3,098 posts
- 14. 8 Dems 7,715 posts
- 15. Angus King 18K posts
- 16. Keenan Allen 5,095 posts
- 17. #ITWelcomeToDerry 4,948 posts
- 18. #RHOP 7,161 posts
- 19. Voltaire 7,943 posts
- 20. GAVIN BRINDLEY N/A
You might like
-
 Three.js
Three.js
@threejs -
 0beqz
0beqz
@0beqz -
 ☄︎
☄︎
@0xca0a -
 iJewel3D (Pixotronics)
iJewel3D (Pixotronics)
@pixotronics -
 Lusion™
Lusion™
@lusionltd -
 Renaud
Renaud
@onirenaud -
 akella
akella
@akella -
 Xavier (Jack)
Xavier (Jack)
@KMkota0 -
 Simon
Simon
@iced_coffee_dev -
 Garrett Johnson 🦋
Garrett Johnson 🦋
@garrettkjohnson -
 Ksenia Kondrashova
Ksenia Kondrashova
@uuuuuulala -
 Anderson Mancini
Anderson Mancini
@Andersonmancini -
 Ebe
Ebe
@th_ebenezer -
 Daniel Velasquez
Daniel Velasquez
@Anemolito -
 Brian Breiholz
Brian Breiholz
@BrianBreiholz
Something went wrong.
Something went wrong.