
你可能會喜歡












Exploring Direct Tensor Manipulation in Language Models: A Case Study in Binary-Level Model Enhancement: areu01or00.github.io/Tensor-Slayer.…
> …by US company > base : Deepseek

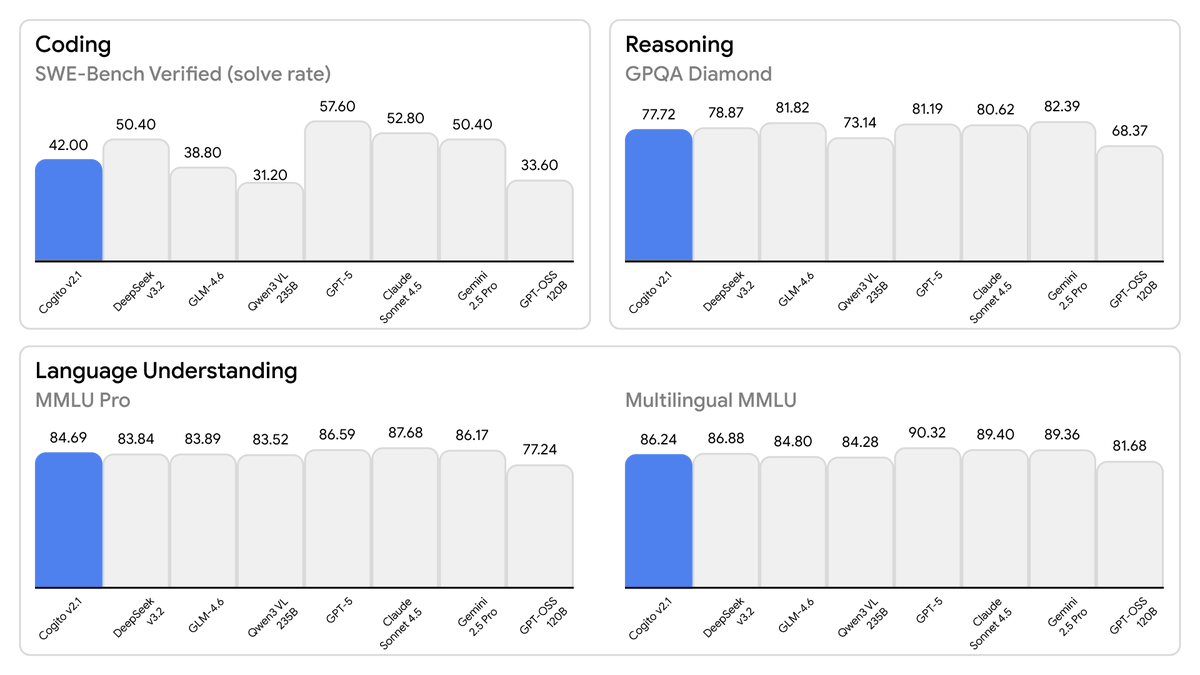
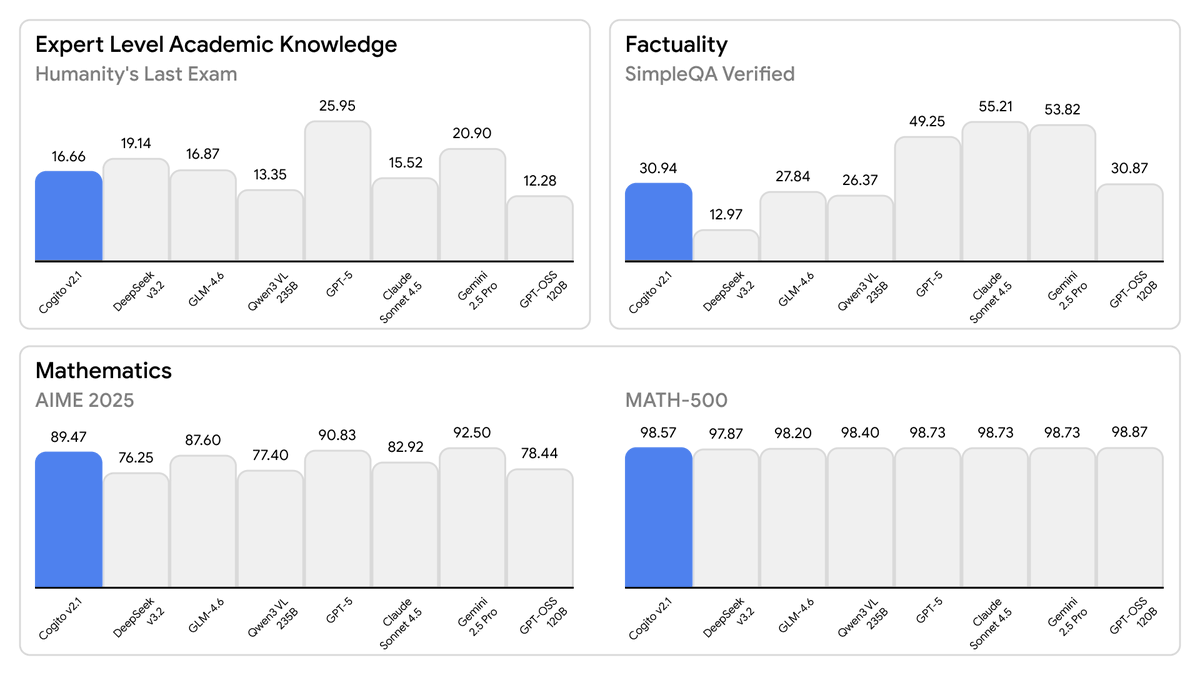
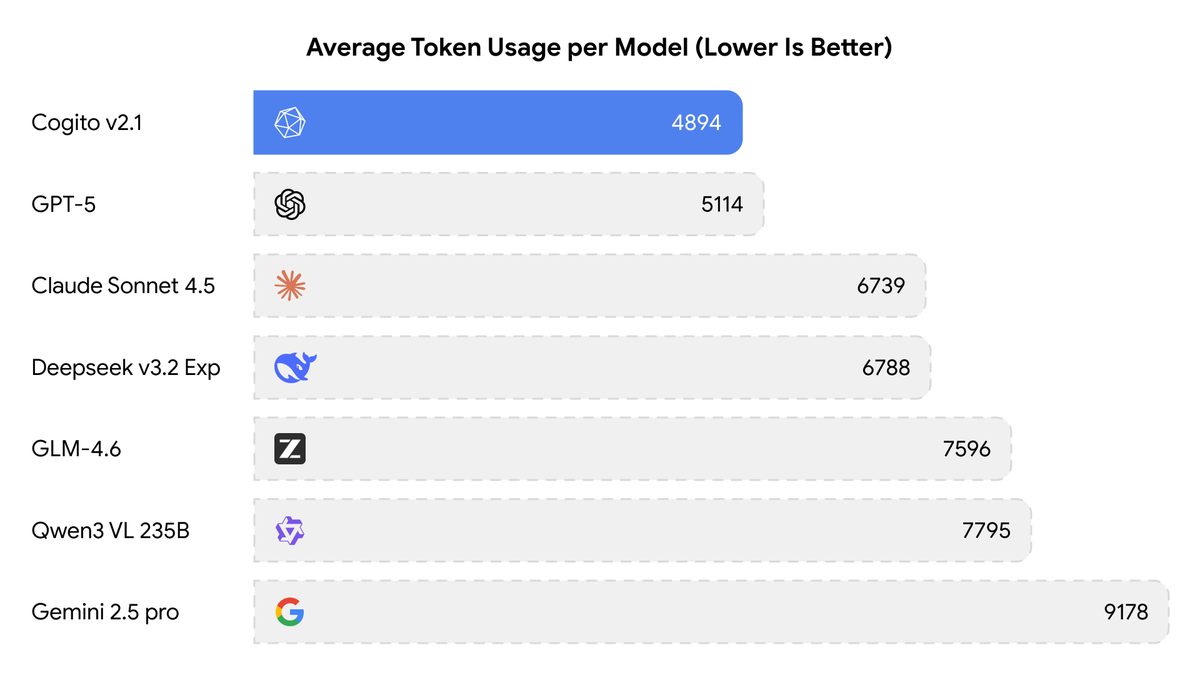
Today, we are releasing the best open-weight LLM by a US company: Cogito v2.1 671B. On most industry benchmarks and our internal evals, the model performs competitively with frontier closed and open models, while being ahead of any US open model (such as the best versions of…




🤗

Use your favourite AI coding agent to create AI frames. What if you could connect everything—your PDFs, videos, notes, code, and research—into one seamless flow that actually makes sense? AI-Frames: Open Source Knowledge-to-Action Platform:timecapsule.bubblspace.com ✨ Annotate •…


Is he Chonky ?








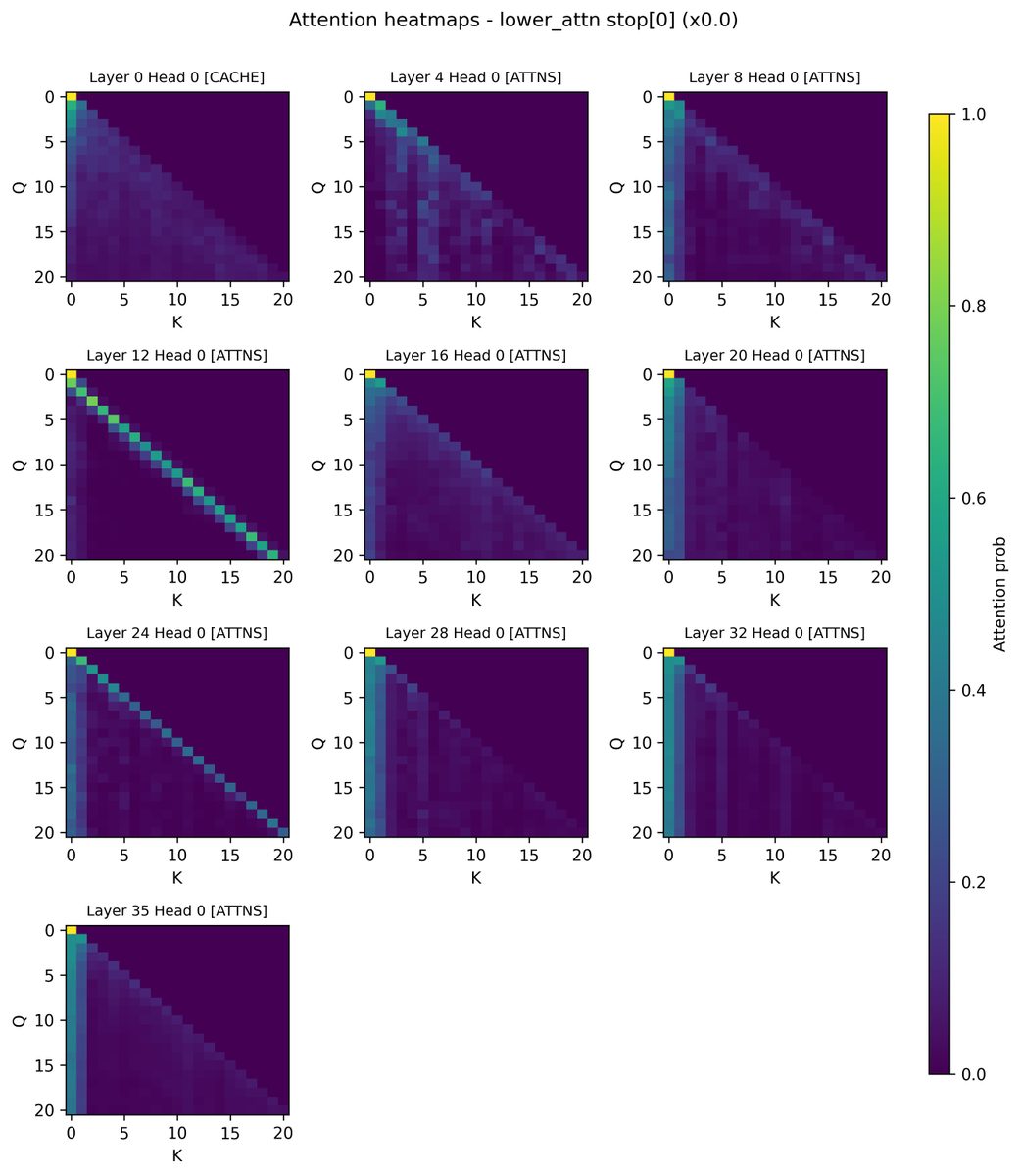
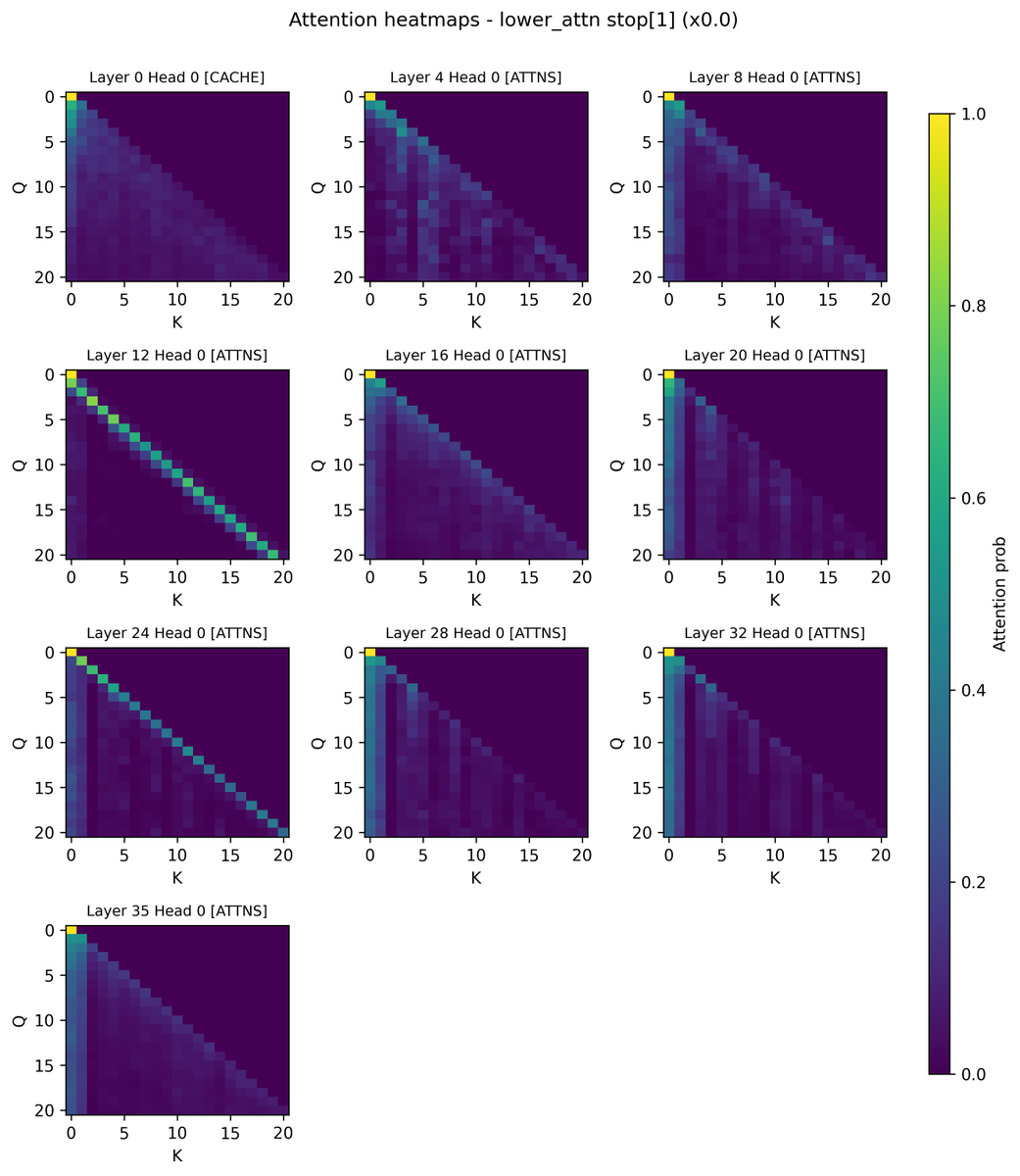
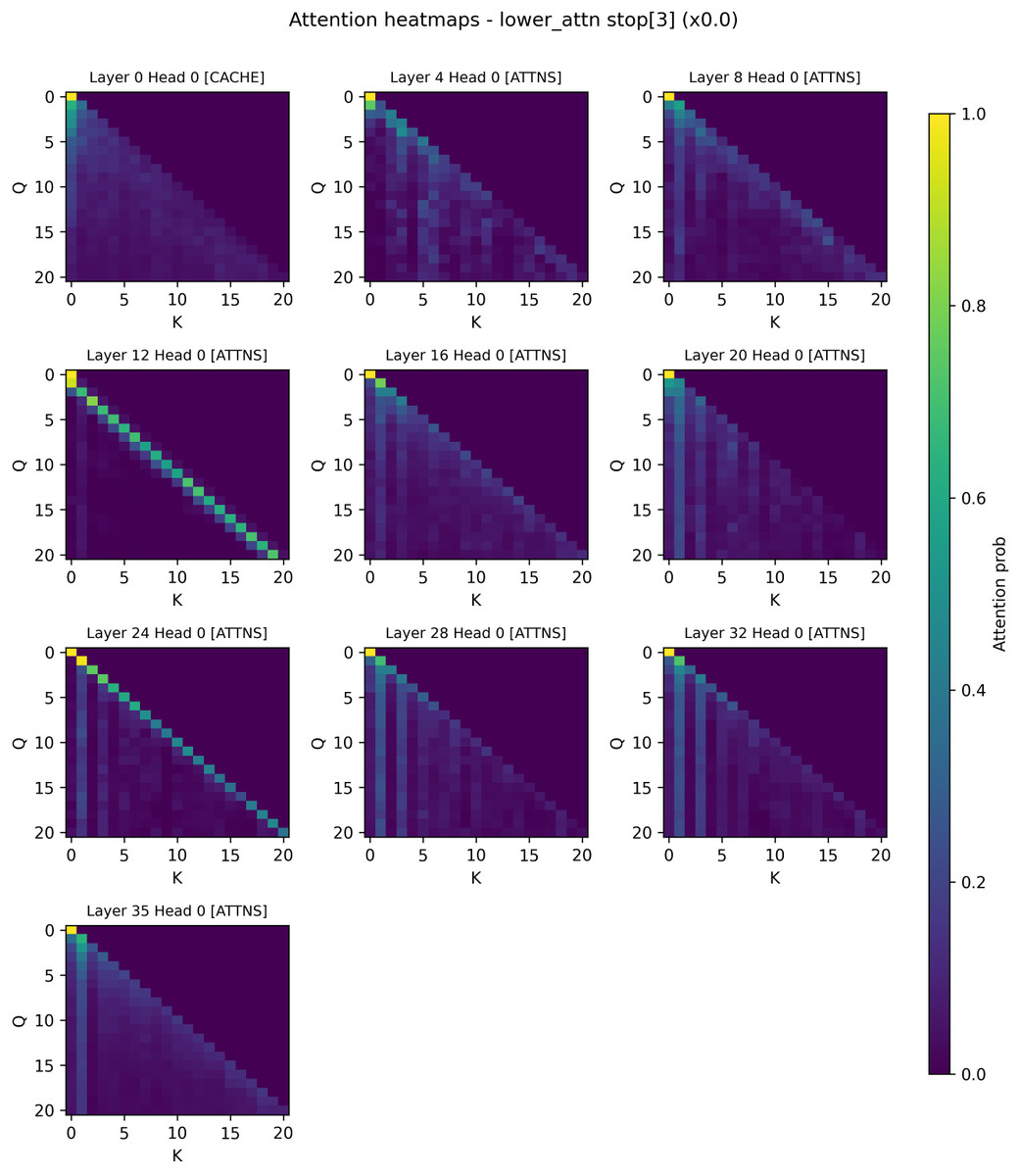
To find layers most responsible for attention sinks, we set the V vector of the sink token to be 0 at particular layers, so that there is no update from the sink token at that layer. Unexpected findings: - Zeroing out layer 0 lowers attention to token 0 by half, but did not…

Breaking: we release a fully synthetic generalist dataset for pretraining, SYNTH and two new SOTA reasoning models exclusively trained on it. Despite having seen only 200 billion tokens, Baguettotron is currently best-in-class in its size range.

Bubbles burst when it’s consumer facing. The “AI bubble” is largely limited to B2B supply chain starting from ASML > TSMC > NVDA > Froniter labs. There is no scapegoat, hence the bubble will keep bubbling.

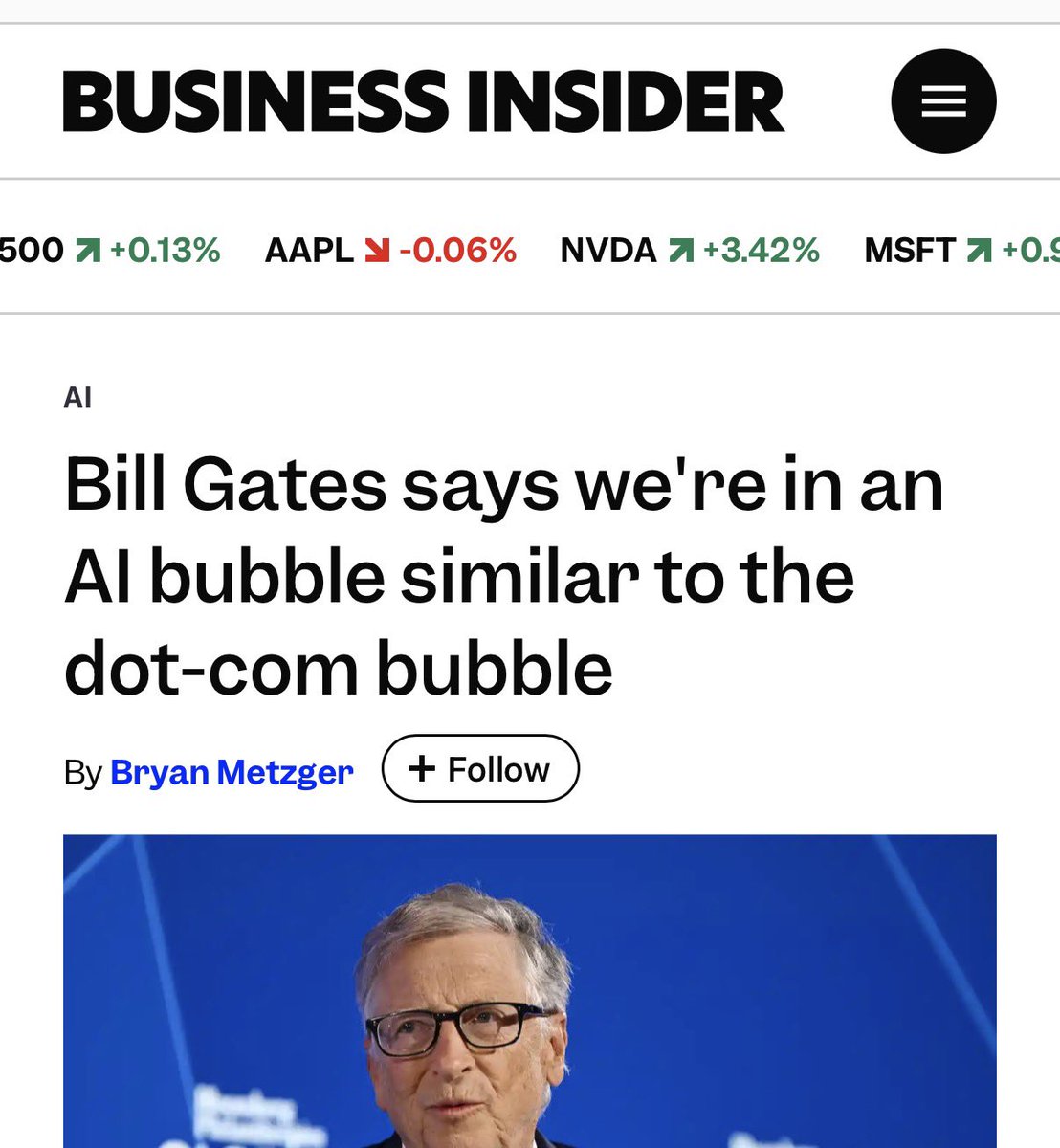
Is it because Bill Gates keeps making contradictory statements, or is it just that journalists pick out the bits that suit them? It's exhausting. One day Bill Gates says that soon we'll only have to work two days a week, and the next day he says we're actually in a giant bubble…

Our assembly lessons are trending on @github ! We have nearly 10k stars.

FFmpeg makes extensive use of hand-written assembly code for huge (10-50x) speed increases and so we are providing assembly lessons to teach a new generation of assembly language programmers. Learn more here: github.com/FFmpeg/asm-les…
Check my article on Hugging face : huggingface.co/blog/TensorSla…

This solidifies the previous works that factual associations and by extension memorisation are properties of MLP layers. There are multiple ways you could manipulate this which can lead to fact distortion/ poisoning / making model learn new facts. No training. For example :

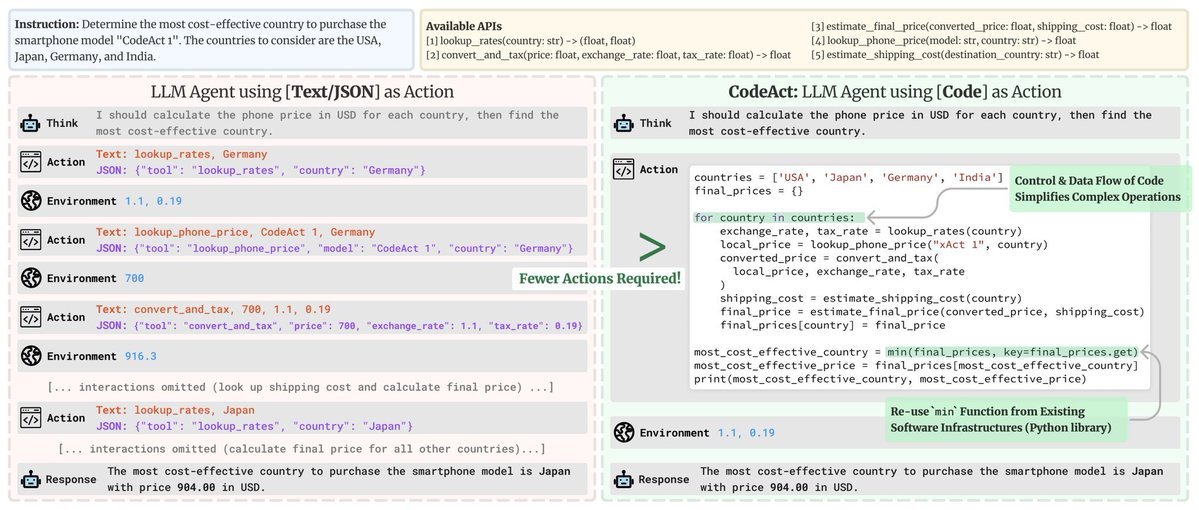
LLMs memorize a lot of training data, but memorization is poorly understood. Where does it live inside models? How is it stored? How much is it involved in different tasks? @jack_merullo_ & @srihita_raju's new paper examines all of these questions using loss curvature! (1/7)

It’s really weird too. Libraries like Smolagent code agent thriving since December 2024


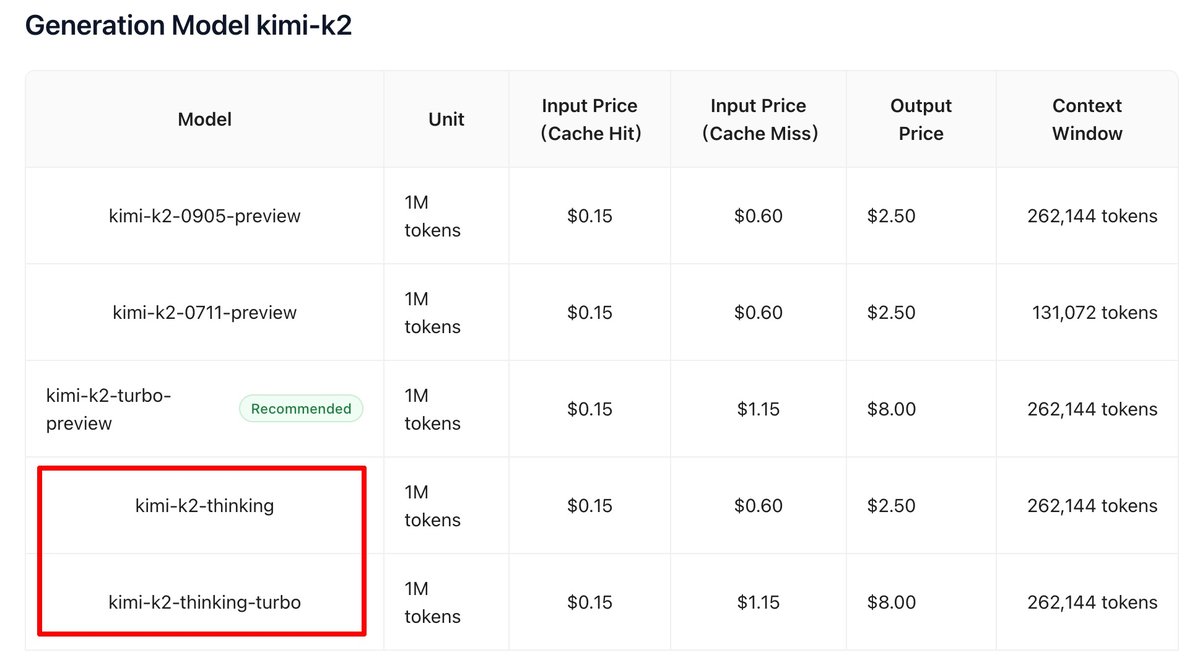
Kimi-K2-Thinking with the same pricing as Kimi-K2 *cough* (looking at you OpenAI and Google you greedy piggies) *cough*

BREAKING 🚨: @Kimi_Moonshot is preparing to announce "kimi-k2-thinking" and "kimi-k2-thinking-turbo" as these models appear on the API Playground.
HYPE
Kimi-K2 Reasoning is coming very soon just got merged into VLLM LETS FUCKING GOOOO im so hyped im so hyped im so hyped github.com/vllm-project/v…

Me wondering where did the pizza toppings go
Woa thats freaking amazing: Agile and cooperative aerial manipulation of a cable-suspended load!

Now in effect: Mergekit has been re-licensed under GNU LGPL v3, restoring clarity and flexibility for users and contributors. Read more about our decision in the blog. arcee.ai/blog/mergekit-…




























































































United States 趨勢
- 1. Josh Allen 39.8K posts
- 2. Texans 59.9K posts
- 3. Bills 149K posts
- 4. Joe Brady 5,301 posts
- 5. #MissUniverse 466K posts
- 6. #MissUniverse 466K posts
- 7. Anderson 27.8K posts
- 8. #StrayKids_DO_IT_OutNow 53.4K posts
- 9. McDermott 4,715 posts
- 10. Technotainment 19.5K posts
- 11. Troy 12.2K posts
- 12. joon 12.6K posts
- 13. #Ashes2025 24K posts
- 14. Beane 2,881 posts
- 15. #criticalrolespoilers 2,365 posts
- 16. GM CT 23.2K posts
- 17. Al Michaels N/A
- 18. Maxey 14.7K posts
- 19. Fátima 201K posts
- 20. FINAL DRAFT FINAL LOVE 1.28M posts
你可能會喜歡
-
 nullpointer
nullpointer
@nullpointar -
 Shintu Dhang
Shintu Dhang
@Shin2_D -
 Shafiur Rahman
Shafiur Rahman
@shafiur -
 Jesús González Amago 🏳️🌈 ♿👥
Jesús González Amago 🏳️🌈 ♿👥
@JgAmago -
 Paul 🎗️
Paul 🎗️
@paulwallace1234 -
 Normas Interruptor
Normas Interruptor
@Normas_ONLY_1 -
 Selva
Selva
@selvasathyam -
 Oriana Pawlyk
Oriana Pawlyk
@Oriana0214 -
 Nitesh Kunnath
Nitesh Kunnath
@die2mrw007 -
 Com Troose
Com Troose
@comtroose -
 Will Newton
Will Newton
@willdjthrill -
 BladeXDesigns
BladeXDesigns
@bladexdesigns
Something went wrong.
Something went wrong.