
Dit vind je misschien leuk
















Google literally just made a model that learns from its mistake.


Transformers Can Reprogram Themselves. A New Paper Explains the Mind-Blowing Trick. 1/12 You know that magical feeling when an AI like ChatGPT learns a new skill instantly, just from a few examples in your prompt? It's not magic. And it's not "learning" in the way you think.…


Context Engineering Template for AI Agents! A complete system for comprehensive context engineering. Includes documentation, examples, rules, and patterns. 100% open-source.


Holy shit. MIT just built an AI that can rewrite its own code to get smarter 🤯 It’s called SEAL (Self-Adapting Language Models). Instead of humans fine-tuning it, SEAL reads new info, rewrites it in its own words, and runs gradient updates on itself literally performing…


Researchers from Meta built a new RAG approach that: - outperforms LLaMA on 16 RAG benchmarks. - has 30.85x faster time-to-first-token. - handles 16x larger context windows. - and it utilizes 2-4x fewer tokens. Here's the core problem with a typical RAG setup that Meta solves:…


This paper shows that you can predict actual purchase intent (90% accuracy) by asking an LLM to impersonate a customer with a demographic profile, giving it a product & having it give its impressions, which another AI rates. No fine-tuning or training & beats classic ML methods.




You can just prompt things
This paper shows that you can predict actual purchase intent (90% accuracy) by asking an LLM to impersonate a customer with a demographic profile, giving it a product & having it give its impressions, which another AI rates. No fine-tuning or training & beats classic ML methods.
A senior Google engineer just dropped a 424-page doc called Agentic Design Patterns. Every chapter is code-backed and covers the frontier of AI systems: → Prompt chaining, routing, memory → MCP & multi-agent coordination → Guardrails, reasoning, planning This isn’t a blog…

Did Stanford just kill LLM fine-tuning? This new paper from Stanford, called Agentic Context Engineering (ACE), proves something wild: you can make models smarter without changing a single weight. Here's how it works: Instead of retraining the model, ACE evolves the context…


Great recap of security risks associated with LLM-based agents. The literature keeps growing, but these are key papers worth reading. Analysis of 150+ papers finds that there is a shift from monolithic to planner-executor and multi-agent architectures. Multi-agent security is…

Holy shit...Google just built an AI that learns from its own mistakes in real time. New paper dropped on ReasoningBank. The idea is pretty simple but nobody's done it this way before. Instead of just saving chat history or raw logs, it pulls out the actual reasoning patterns,…


New paper from @Google is a major memory breakthrough for AI agents. ReasoningBank helps an AI agent improve during use by learning from its wins and mistakes. To succeed in real-world settings, LLM agents must stop making the same mistakes. ReasoningBank memory framework…


What the fuck just happened 🤯 Stanford just made fine-tuning irrelevant with a single paper. It’s called Agentic Context Engineering (ACE) and it proves you can make models smarter without touching a single weight. Instead of retraining, ACE evolves the context itself. The…


My brain broke when I read this paper. A tiny 7 Million parameter model just beat DeepSeek-R1, Gemini 2.5 pro, and o3-mini at reasoning on both ARG-AGI 1 and ARC-AGI 2. It's called Tiny Recursive Model (TRM) from Samsung. How can a model 10,000x smaller be smarter? Here's how…


In the near future, your Tesla will drop you off at the store entrance and then go find a parking spot. When you’re ready to exit the store, just tap Summon on your phone and the car will come to you.

FSD V14.1 Spends 20 Minutes Looking For Parking Spot at Costco This video is sped up 35x once we get hunting for a spot and during that time the car pulls of some really inellegent moves while searching. We did not once pass any empty available spots, the only issue is we didn't…
Google did it again! First, they launched ADK, a fully open-source framework to build, orchestrate, evaluate, and deploy production-grade Agentic systems. And now, they have made it even powerful! Google ADK is now fully compatible with all three major AI protocols out there:…

You can instantly generate Grok Imagine videos using any simple dark image, skipping the need of custom image for video Just pick a dark image with your preferred aspect ratio, type your prompt, and you’re set It works amazingly good....yes, this my cool recipe with all videos…


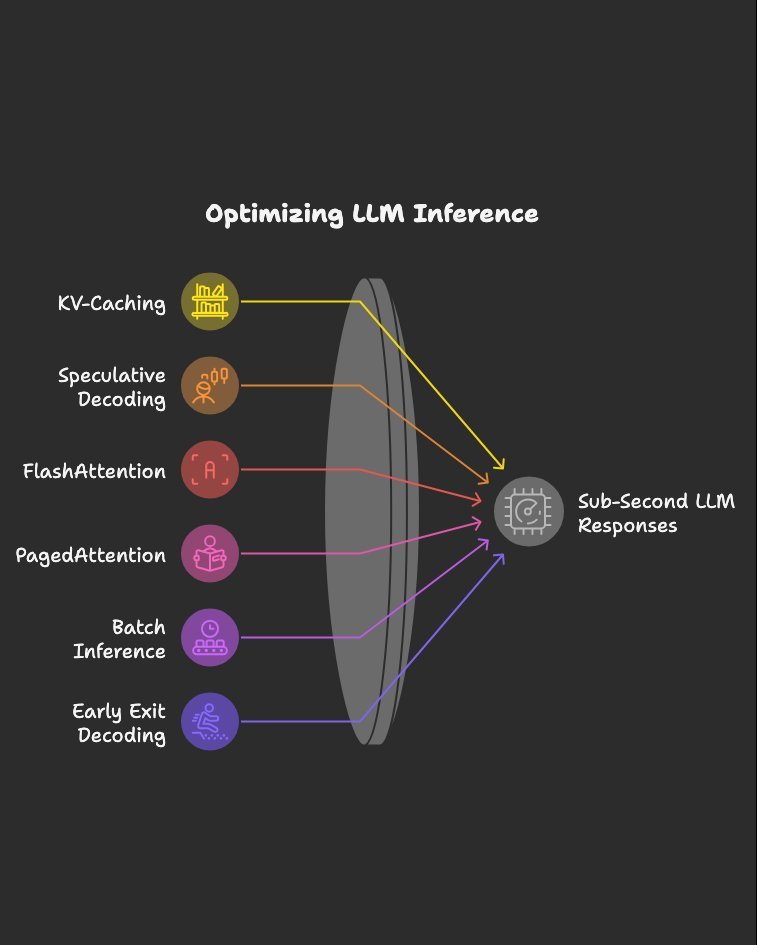
Inference optimizations I’d study if I wanted sub-second LLM responses: Bookmark this. 1.KV-Caching 2.Speculative Decoding 3.FlashAttention 4.PagedAttention 5.Batch Inference 6.Early Exit Decoding 7.Parallel Decoding 8.Mixed Precision Inference 9.Quantized Kernels 10.Tensor…
















































































































United States Trends
- 1. Bills 123K posts
- 2. Falcons 38.5K posts
- 3. Josh Allen 18.9K posts
- 4. Snell 9,203 posts
- 5. Bijan 22.6K posts
- 6. Bears 52.6K posts
- 7. phil 138K posts
- 8. Joe Brady 3,730 posts
- 9. AFC East 3,356 posts
- 10. Caleb 34.6K posts
- 11. McDermott 5,417 posts
- 12. Drake London 6,016 posts
- 13. Freddie 14.8K posts
- 14. #NLCS 7,582 posts
- 15. #RiseUp 1,610 posts
- 16. James Cook 4,013 posts
- 17. #RaiseHail 5,982 posts
- 18. Commanders 34.1K posts
- 19. Penix 5,661 posts
- 20. Chris Moore 2,015 posts
Dit vind je misschien leuk
-
 Prithvi Raj
Prithvi Raj
@prithvi137 -
 Daniel Walsh
Daniel Walsh
@rhatdan -
 OCI
OCI
@OCI_ORG -
 Murat Demirbas (Distributolog)
Murat Demirbas (Distributolog)
@muratdemirbas -
 Vedant Shrotria
Vedant Shrotria
@VedantShrotria -
 Bret Fisher
Bret Fisher
@BretFisher -
 LitmusChaos | Chaos Engineering Made Easy
LitmusChaos | Chaos Engineering Made Easy
@LitmusChaos -
 Uma Mukkara
Uma Mukkara
@Uma_Mukkara -
 Oum Kale
Oum Kale
@OumKale -
 Matt Hargett
Matt Hargett
@syke -
 David Flanagan
David Flanagan
@rawkode -
 Microsoft Reactor
Microsoft Reactor
@MSFTReactor -
 Kathy Zant
Kathy Zant
@kathyzant -
 Felix Rieseberg
Felix Rieseberg
@felixrieseberg -
 Mat Velloso
Mat Velloso
@matvelloso
Something went wrong.
Something went wrong.