
你可能会喜欢















Meta is out of its mind.

I was laid off by Meta today. As a Research Scientist, my work was just cited by the legendary @johnschulman2 and Nicholas Carlini yesterday. I’m actively looking for new opportunities — please reach out if you have any openings!


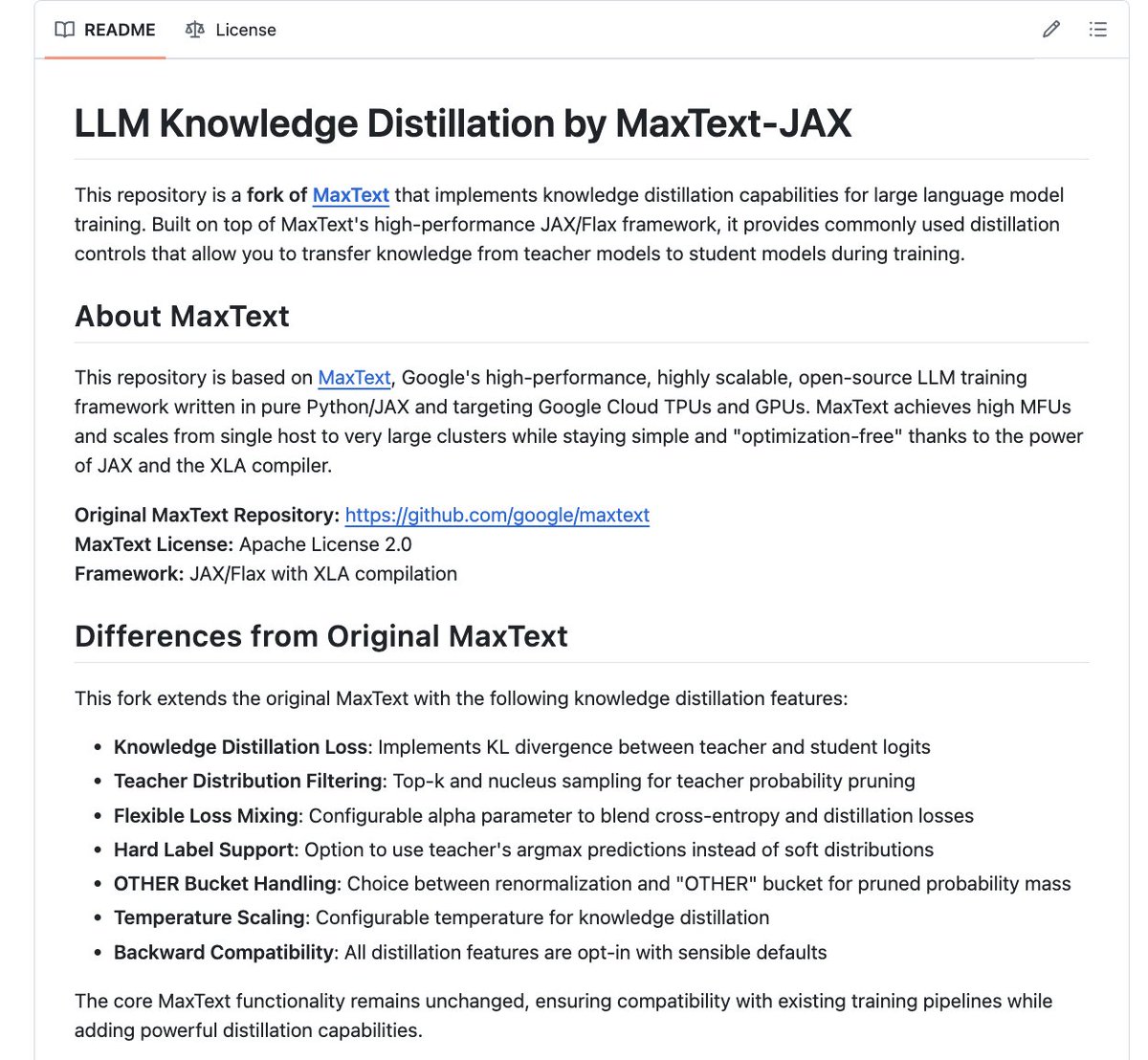
Excited to share our lab’s first open-source release: LLM-Distillation-JAX supports practical knowledge distillation configurations (distillation strength, temperature, top-k/top-p), built on MaxText designed for reproducible JAX/Flax training on both TPUs and GPUs

Lookahead Routing for LLMs Proposes Lookahead, a routing framework to enable more informed routing without full inference. Achieves an average performance gain of 7.7% over the state-of-the-art. Here is why it works: Lookahead is a new framework for routing in multi-LLM…


One sign of this being a really cool idea is that while reading, I had tons of follow-up ideas immediately come to mind, and only few "hmm but"s. Plz read thread and paper, but TLDR: add layer of input independent kv, and fine-tune only the high tfidf kvs for continual learning.

🧠 How can we equip LLMs with memory that allows them to continually learn new things? In our new paper with @AIatMeta, we show how sparsely finetuning memory layers enables targeted updates for continual learning, w/ minimal interference with existing knowledge. While full…
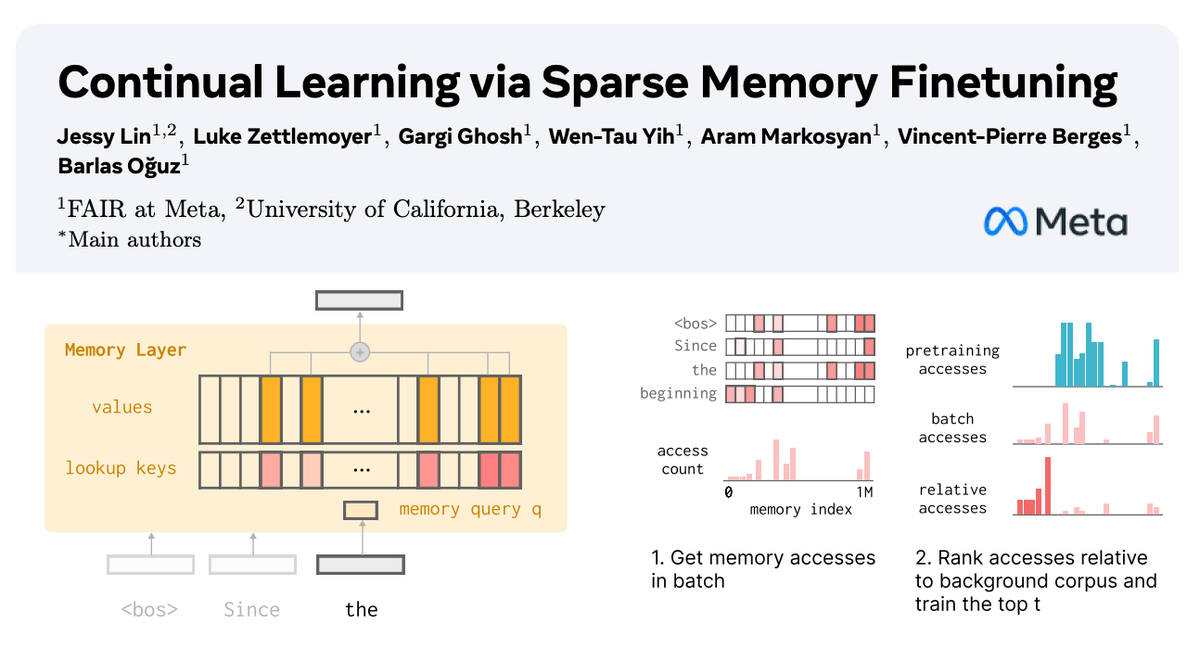
🧠 How can we equip LLMs with memory that allows them to continually learn new things? In our new paper with @AIatMeta, we show how sparsely finetuning memory layers enables targeted updates for continual learning, w/ minimal interference with existing knowledge. While full…

This paper shows a small open model solves harder math by running long self evolving reasoning loops. With this setup, the 8B DeepSeek based model solved 5 AIME problems it could not solve before. The loop treats each round as a tiny move toward right, and if improve beats…


Your money can do more than build wealth, it can build hope. Robin John’s book reveals how to invest in ways that honor God and serve your neighbors. Make your work and investments a force for good.

KV caching, clearly explained:
You're in an ML Engineer interview at OpenAI. The interviewer asks: "Our GPT model generates 100 tokens in 42 seconds. How do you make it 5x faster?" You: "I'll optimize the model architecture and use a better GPU." Interview over. Here's what you missed:
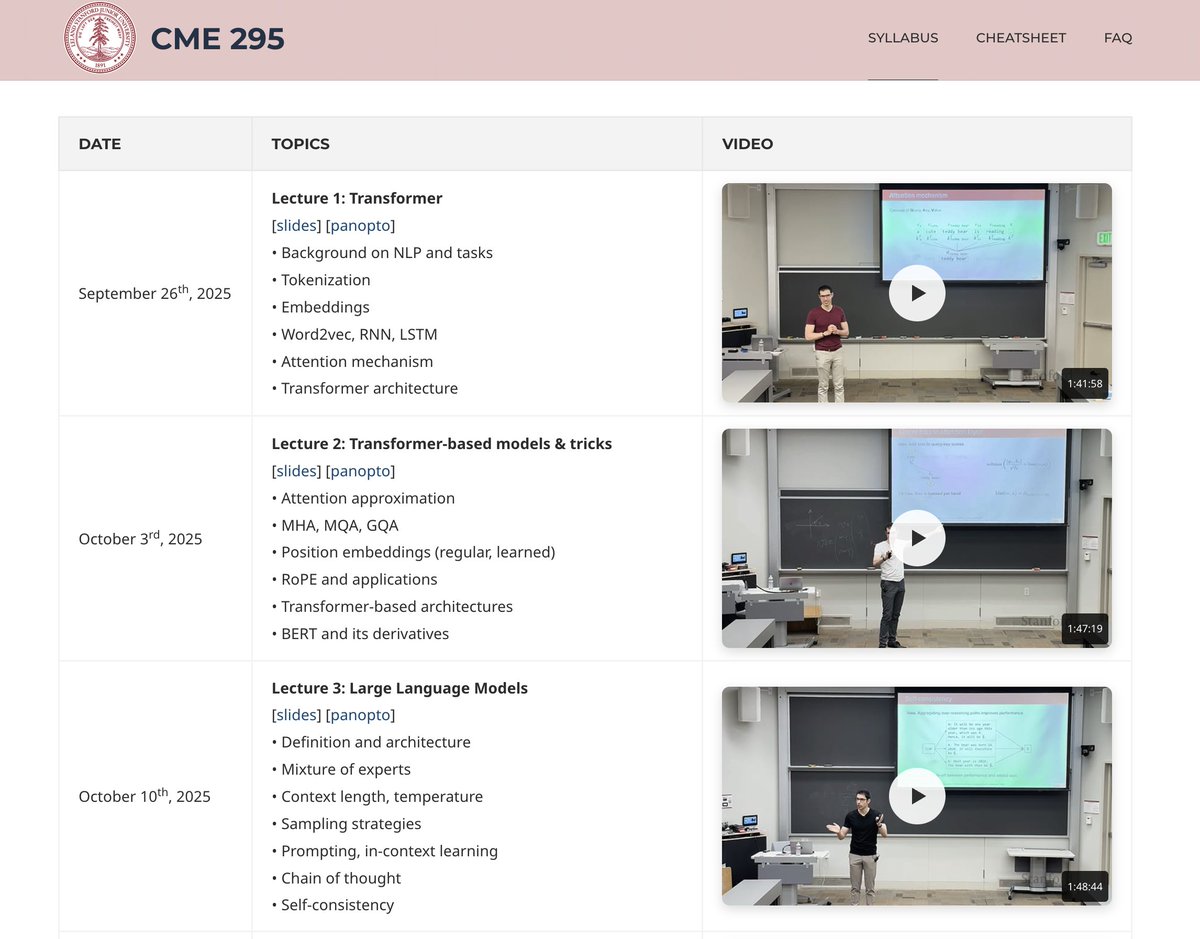
🎓Stanford CME295 Transformers & LLMs Nice to see the new release of this new course on Transformers and LLMs. Great way to catch up on the world of LLMs and AI Agents. Includes topics like the basics of attention, mixture-of-experts, to agents. Excited to see more on evals.…
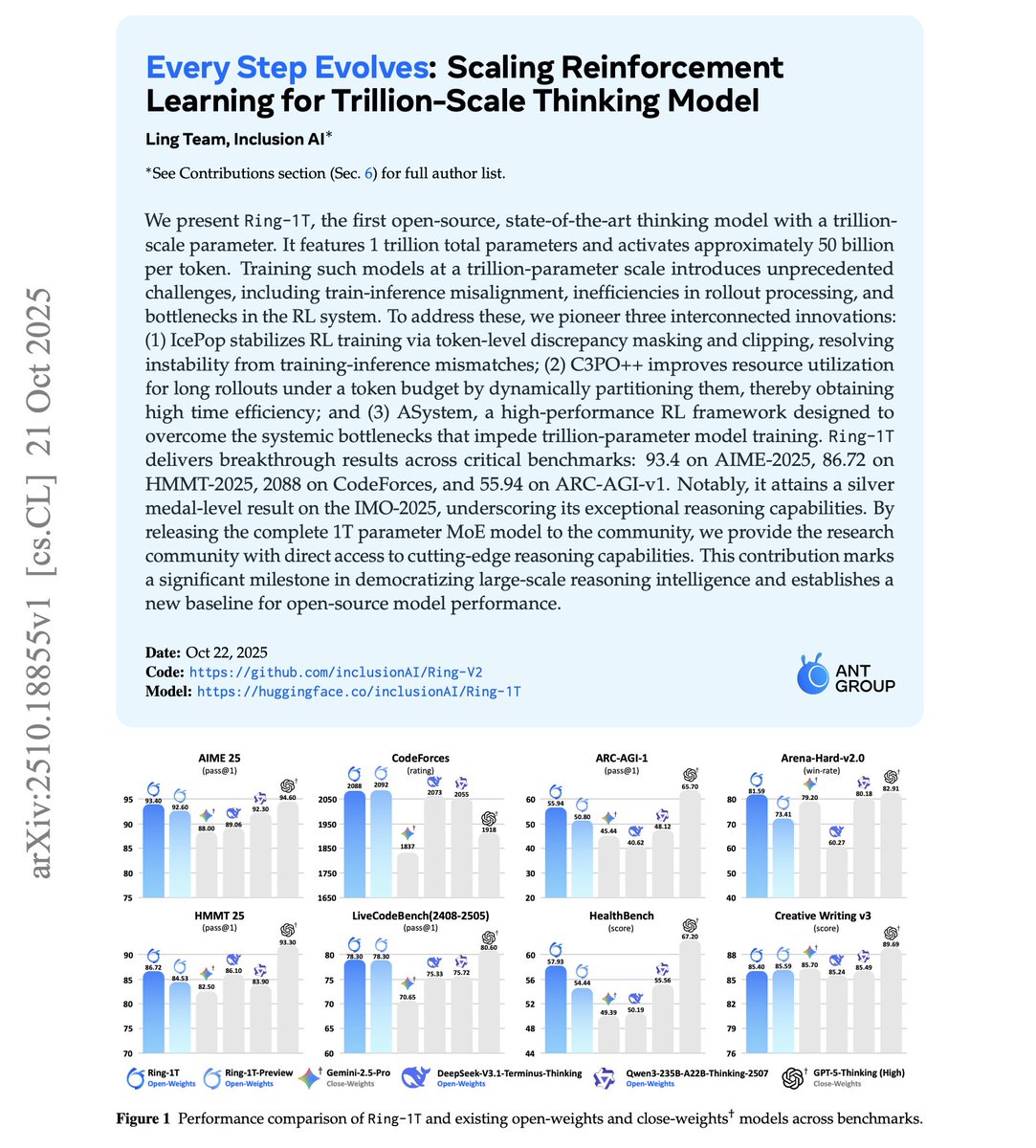
Scaling RL for Trillion-Scale Thinking Model Scaling RL is hard! But this team might have figured out something. They introduce Ring-1T, a 1T-parameter MoE reasoning model with ~50B params active per token. It’s trained with a long-CoT SFT phase, a verifiable-rewards reasoning…
This paper builds an agentic LLM that can run the whole data science workflow by itself. It is an 8B model that plans work, reads structured files, writes and runs code, checks results, and iterates. Standard “workflow agents” break here because fixed scripts do not adapt well…

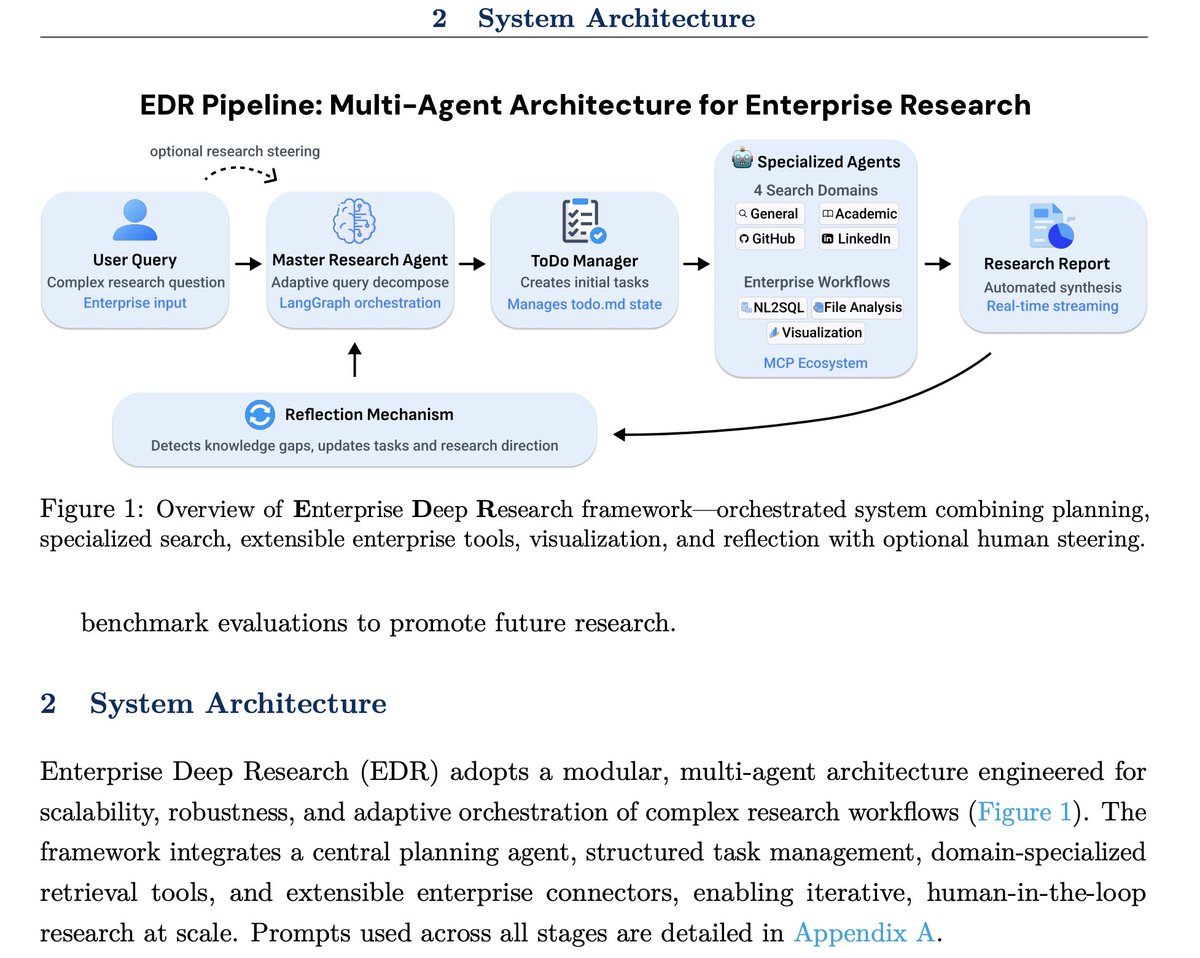
People are sleeping on Deep Agents. Start using them now. This is a fun paper showcasing how to put together advanced deep agents for enterprise use cases. Uses the best techniques: task decomposition, planning, specialized subagents, MCP for NL2SQL, file analysis, and more.


I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter. The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language…

🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping…



Great paper on AI's recursive self-improvement. Builds a single loop that lets a search agent teach itself. One part writes new tasks, one part tries to solve them, and one part judges the answers. A 3-role loop can keep improving a search agent without human labels. The…


Holy shit… Harvard just proved your base model might secretly be a genius. 🤯 Their new paper “Reasoning with Sampling” shows that you don’t need reinforcement learning to make LLMs reason better. They used a 'Markov chain sampling trick' that simply re-samples from the…


A permanently crewed lunar science base would be far more impressive than a repeat of what was already done incredibly well by Apollo in 1969

Blue Origin could likely land on the Moon before SpaceX but this is Blue Moon Mk1, a small lander testbed for Blue Moon Mk2 that would provide no value if man rated. So why bother man rating it to beat China? China doesn’t plan on flags and footprints, they plan on permanent…




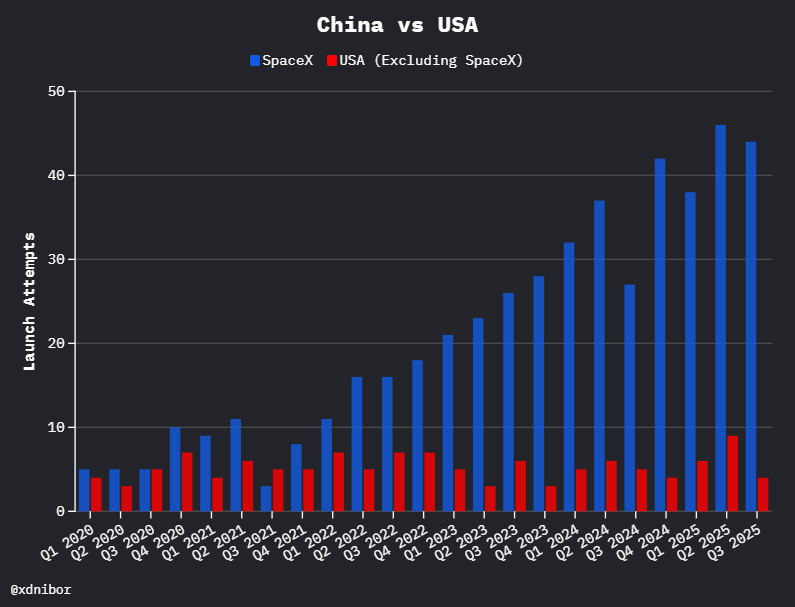
SpaceX will carry ~90% of the world’s payload mass to space this year, so it is pretty much Earth’s space program


This new paper defines AGI as: "AI that can match or exceed the cognitive versatility and proficiency of a well-educated adult." Researchers translate this theory into 10 cognitive domains, like general knowledge, speed, on-the-spot reasoning, working memory, each representing…


fantastic simple visualization of the self attention formula. this was one of the hardest things for me to deeply understand about LLMs. the formula seems easy. you can even memorize it fast. but to really get an intuition of what the Q,K,V represent and interact, that’s hard.
if you're looking for a comprehensive guide to LLM finetuning, check this! a free 115-page book on arxiv, covering: > fundamentals of LLM > peft (lora, qlora, dora, hft) > alignment methods (ppo, dpo, grpo) > mixture of experts (MoE) > 7-stage fine-tuning pipeline > multimodal…



















































































































United States 趋势
- 1. Halo 117K posts
- 2. PlayStation 55K posts
- 3. $BIEBER 1,250 posts
- 4. Xbox 68.7K posts
- 5. #WorldSeries 52.1K posts
- 6. #HitTheBuds 2,518 posts
- 7. Jasper Johnson N/A
- 8. #CashAppPools 1,665 posts
- 9. Purdue 3,407 posts
- 10. Cole Anthony N/A
- 11. Reagan 230K posts
- 12. Ashley 159K posts
- 13. Combat Evolved 4,965 posts
- 14. Rajah N/A
- 15. Megan 72.3K posts
- 16. Master Chief 7,048 posts
- 17. Layne Riggs N/A
- 18. Tish 19.3K posts
- 19. #CostumeInADash N/A
- 20. OFAC 42K posts
你可能会喜欢
-
 Prithvi Raj
Prithvi Raj
@prithvi137 -
 Daniel Walsh
Daniel Walsh
@rhatdan -
 OCI
OCI
@OCI_ORG -
 Murat Demirbas (Distributolog)
Murat Demirbas (Distributolog)
@muratdemirbas -
 Vedant Shrotria
Vedant Shrotria
@VedantShrotria -
 Bret Fisher
Bret Fisher
@BretFisher -
 LitmusChaos | Chaos Engineering Made Easy
LitmusChaos | Chaos Engineering Made Easy
@LitmusChaos -
 Uma Mukkara
Uma Mukkara
@Uma_Mukkara -
 Matt Hargett
Matt Hargett
@syke -
 David Flanagan
David Flanagan
@rawkode -
 Microsoft Reactor
Microsoft Reactor
@MSFTReactor -
 Kathy Zant
Kathy Zant
@kathyzant -
 Felix Rieseberg
Felix Rieseberg
@felixrieseberg -
 Mat Velloso
Mat Velloso
@matvelloso
Something went wrong.
Something went wrong.