
Ishan Gupta
@code_igx
25 🇮🇳, Hustler @RITtigers NY 🇺🇸 | RnD on Quantum AI, Superintelligence & Systems | Ex- @Broadcom @VMware
Może Ci się spodobać














🚨 This might be the biggest leap in AI agents since ReAct. Researchers just dropped DeepAgent a reasoning model that can think, discover tools, and act completely on its own. No pre-scripted workflows. No fixed tool lists. Just pure autonomous reasoning. It introduces…




𝗟𝗘𝗔𝗞𝗘𝗗: 100s of premium AI Agents... These exact Agents sell for $𝟱,𝟬𝟬𝟬+ 𝗽𝗲𝗿 𝗯𝘂𝗶𝗹𝗱, 𝗲𝗮𝘀𝗶𝗹𝘆... Inside the file you get: → Lead qualification agents → Content generation pipelines → Appointment booking automation → Cold outreach sequences → Data…

Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning Breaks down SFT dataset demonstrations into a sequence of actions, generate internal reasoning before each action, reward based on similarity of model's actions and expert actions. Experiments…


The paper shows how Human-Computer Interaction (HCI) talks about LLM reasoning without looking at what builds it. The authors read 258 CHI papers from 2020 to 2025 to see how reasoning is used . They find many papers use reasoning as a selling point to try an idea with LLMs.…

Scaling Latent Reasoning via Looped Language Models 1.4B and 2.6B param LoopLMs pretrained on 7.7T tokens match the performance of 4B and 8B standard transformers respectively across nearly all benchmarks time to be bullish on adaptive computation again? great work by…


Graph-based Agent Planning It lets AI agents run multiple tools in parallel to accelerate task completion. Uses graphs to map tool dependencies + RL to learn the best execution order. RL also helps with scheduling strategies and planning. Major speedup for complex tasks.

New Nvidia paper shows how a single LLM can teach itself to reason better. It creates 3 roles from the same model, a Proposer, a Solver, and a Judge. The Proposer writes hard but solvable questions that stretch the model. The Solver answers those questions with clear steps and…


Tesla autonomous driving might spread faster than any technology ever. The hardware foundations have been laid for such a long time that a software update enables self-driving for millions of pre-existing cars in a short period of time.

Comparison of Tesla's vs Waymo's Robotaxi geofence map in Austin, Texas. Today, @Tesla expanded their geofence area for the first time in two months.

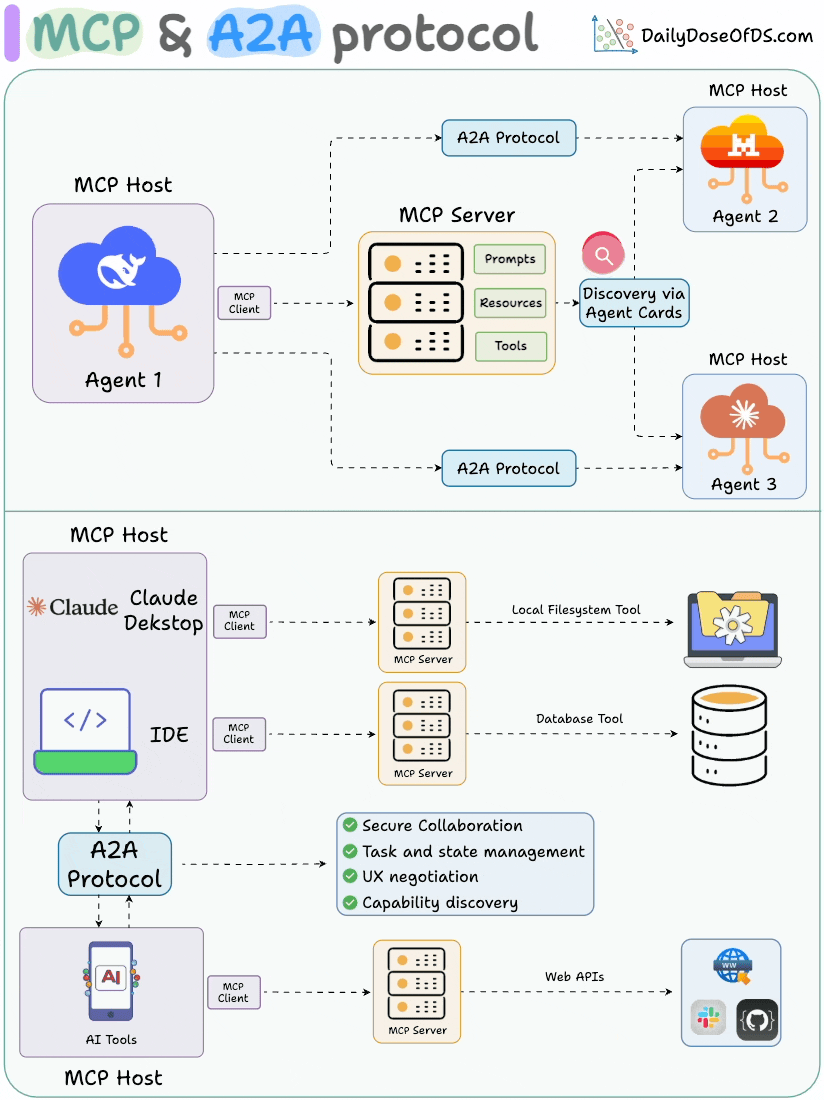
MCP & A2A (Agent2Agent) protocol, clearly explained! Agentic applications require both A2A and MCP. - MCP provides agents with access to tools. - A2A allows agents to connect with other agents and collaborate in teams. Let's understand what A2A is and how it can work with MCP:…

holy sh*t... your llm remembers everything you typed 🤯 researchers just proved you can recover the EXACT input text from a language model's hidden states. not similar text. not approximate. the actual words you typed. here's what they found: • transformer language models…

The goal of Grok and Grokipedia.com is the truth, the whole truth and nothing but the truth. We will never be perfect, but we shall nonetheless strive towards that goal.

Note the difference between Wikipedia's first paragraph on George Floyd compared to the first paragraph from Grokipedia. The nuance and detail on Grokipedia is FAR superior to Wikipedia and is clearly not pushing any ideologies, unlike Wikipedia. Corrections like this are…


SpaceX is now launching roughly the same number of satellites in a year as the number of operational non-SpaceX satellites in orbit cumulatively
SpaceX has officially surpassed its total number of launches from all of 2024 (138) — with more than two months still left in 2025. The company has launched over 2,500 Starlink satellites in 2025 alone. An absolutely incredible pace of progress 🚀





I got rejected by 144 investors before raising $150M for my $200M+ rev/year startup. After 144 rejections, I started questioning our approach. Were we solving the right problem? What were we doing wrong? Why weren’t investors seeing what we were seeing? Were we the right…
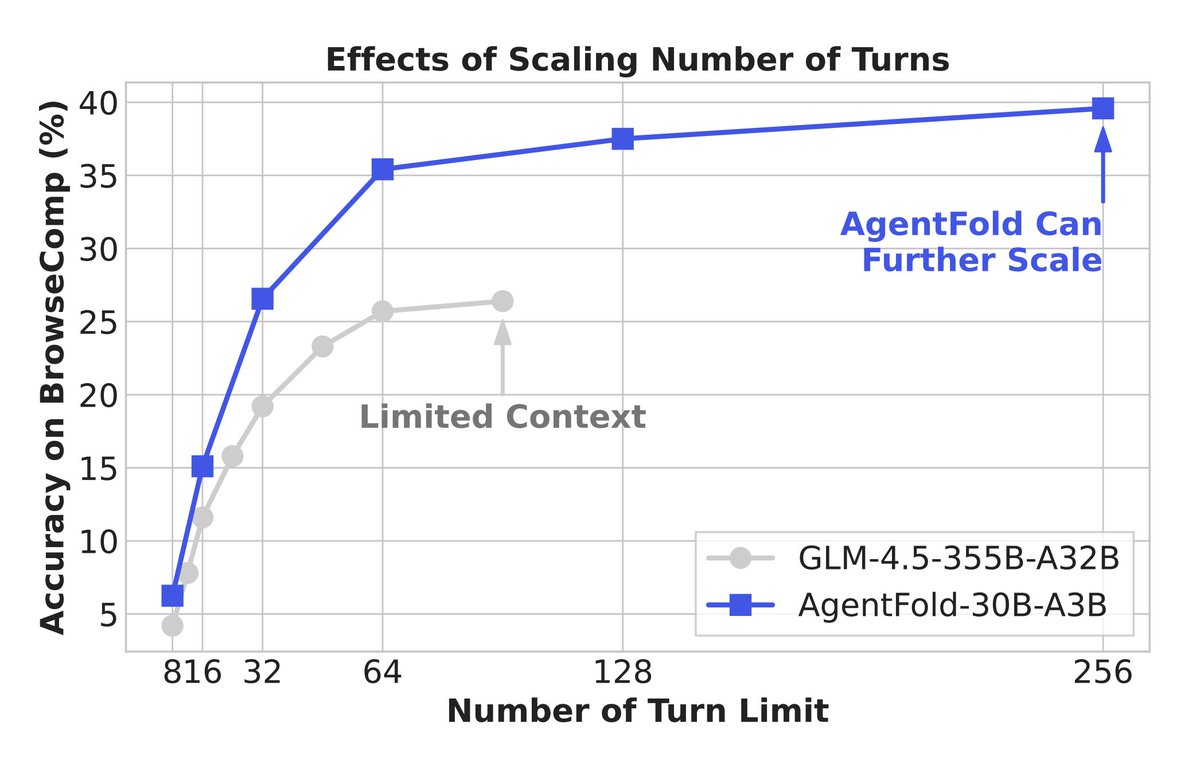
This is actually a clever context engineering technique for web agents. It's called AgentFold, an agent that acts as a self-aware knowledge manager. It treats context as a dynamic cognitive workspace by folding information at different scales: - Light folding: Compressing…





Introducing Multi-Agent Evolve 🧠 A new paradigm beyond RLHF and RLVR: More compute → closer to AGI No need for expensive data or handcrafted rewards We show that an LLM can self-evolve — improving itself through co-evolution among roles (Proposer, Solver, Judge) via RL — all…




🧵 LoRA vs full fine-tuning: same performance ≠ same solution. Our NeurIPS ‘25 paper 🎉shows that LoRA and full fine-tuning, even when equally well fit, learn structurally different solutions and that LoRA forgets less and can be made even better (lesser forgetting) by a simple…


Just saw the MiniMax-M2 benchmarks, and the performance is too good to ignore :). So, I just amended my "The Big LLM Architecture Comparison" with entry number 13! 1️⃣ Full attention modules: As shown in the overview figure below, I grouped MiniMax-M2 with the other…


I finally understand the fundamentals of building real AI agents. This new paper “Fundamentals of Building Autonomous LLM Agents” breaks it down so clearly it feels like a blueprint for digital minds. Turns out, true autonomy isn’t about bigger models. It’s about giving an LLM…




















































































































United States Trendy
- 1. vmin 33.3K posts
- 2. Good Saturday 22.7K posts
- 3. #SaturdayVibes 3,449 posts
- 4. Christmas 120K posts
- 5. Nigeria 485K posts
- 6. Social Security 48K posts
- 7. Big Noon Kickoff N/A
- 8. Disney 96.7K posts
- 9. New Month 312K posts
- 10. #River 5,529 posts
- 11. #AllSaintsDay 1,370 posts
- 12. IT'S GAMEDAY 1,928 posts
- 13. #saturdaymorning 1,587 posts
- 14. Chovy 13.9K posts
- 15. #SaturdayMotivation 1,216 posts
- 16. seokjin 254K posts
- 17. VOCAL KING TAEHYUNG 41.6K posts
- 18. GenG 6,962 posts
- 19. Championship Saturday 1,003 posts
- 20. Spring Day 61.8K posts
Może Ci się spodobać
-
 Prithvi Raj
Prithvi Raj
@prithvi137 -
 Daniel Walsh
Daniel Walsh
@rhatdan -
 OCI
OCI
@OCI_ORG -
 Murat Demirbas (Distributolog)
Murat Demirbas (Distributolog)
@muratdemirbas -
 Vedant Shrotria
Vedant Shrotria
@VedantShrotria -
 Bret Fisher
Bret Fisher
@BretFisher -
 LitmusChaos | Chaos Engineering Made Easy
LitmusChaos | Chaos Engineering Made Easy
@LitmusChaos -
 Uma Mukkara
Uma Mukkara
@Uma_Mukkara -
 Matt Hargett
Matt Hargett
@syke -
 David Flanagan
David Flanagan
@rawkode -
 Kathy Zant
Kathy Zant
@kathyzant -
 Felix Rieseberg
Felix Rieseberg
@felixrieseberg -
 Mat Velloso
Mat Velloso
@matvelloso
Something went wrong.
Something went wrong.