
Cody Blakeney
@code_star
Data Dawg @datologyai | Formerly Data Research Lead @DbrxMosaicAI | Visiting Researcher @ Facebook | Ph.D | #TXSTFOOTBALL fan | http://linktr.ee/code_star
Bunları beğenebilirsin















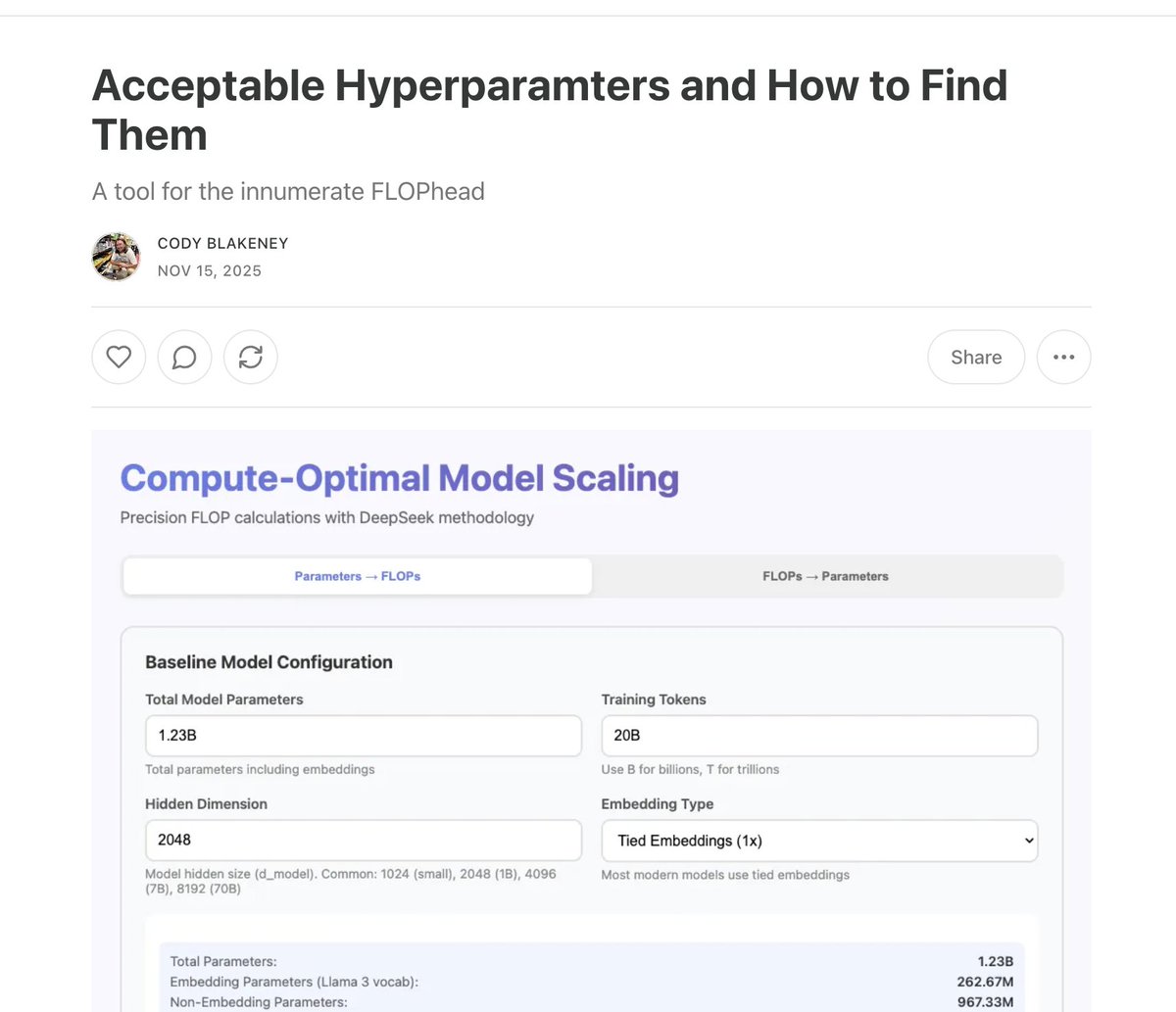
I've got something new for everyone. My first substack article! Not the one I planned to do first, but a fun one! I have made a handy calculator base on the DeepSeek v1 coefficients for finding optimal LR and batch sizes for dense LLMs.

torch main source build


binary searching nightlies is a hell of a feeling
lol dumb LLM data podcast idea “Talking Tokens”
gotta give the people what they want

Nothing mid about this training 😤

Since mid-training is eating them both, we can as well call it training.
I guess what I’m getting at here is sparsity performance is an engineering problem and the science is pretty clear that you can make the models big without change the theoretical inference performance. Google has really good engineers. It doesn’t really seem like scaling…
Can I ask a dumb question. Let’s say it is 7.5T total parameters. Now that super sparse MoEs are the norm … who cares how big the parameters get? 8x more total params than kimi shouldn’t be hard or surprising for one of the worlds best capitalized companies. 15T next year…
Canonically I believe this is Olmo: Tokyo Drift

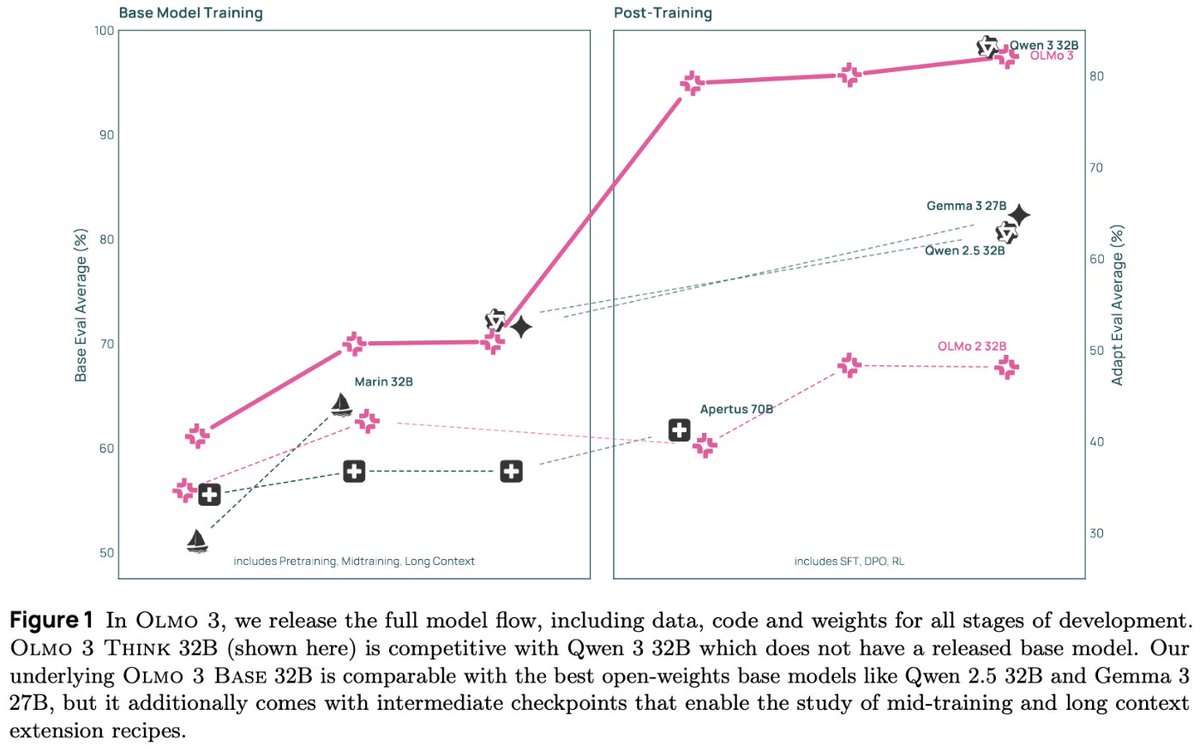
This release has SO MUCH • New pretrain corpus, new midtrain data, 380B+ long context tokens • 7B & 32B, Base, Instruct, Think, RL Zero • Close to Qwen 3 performance, but fully open!!
Olmo 3: Rawr XD

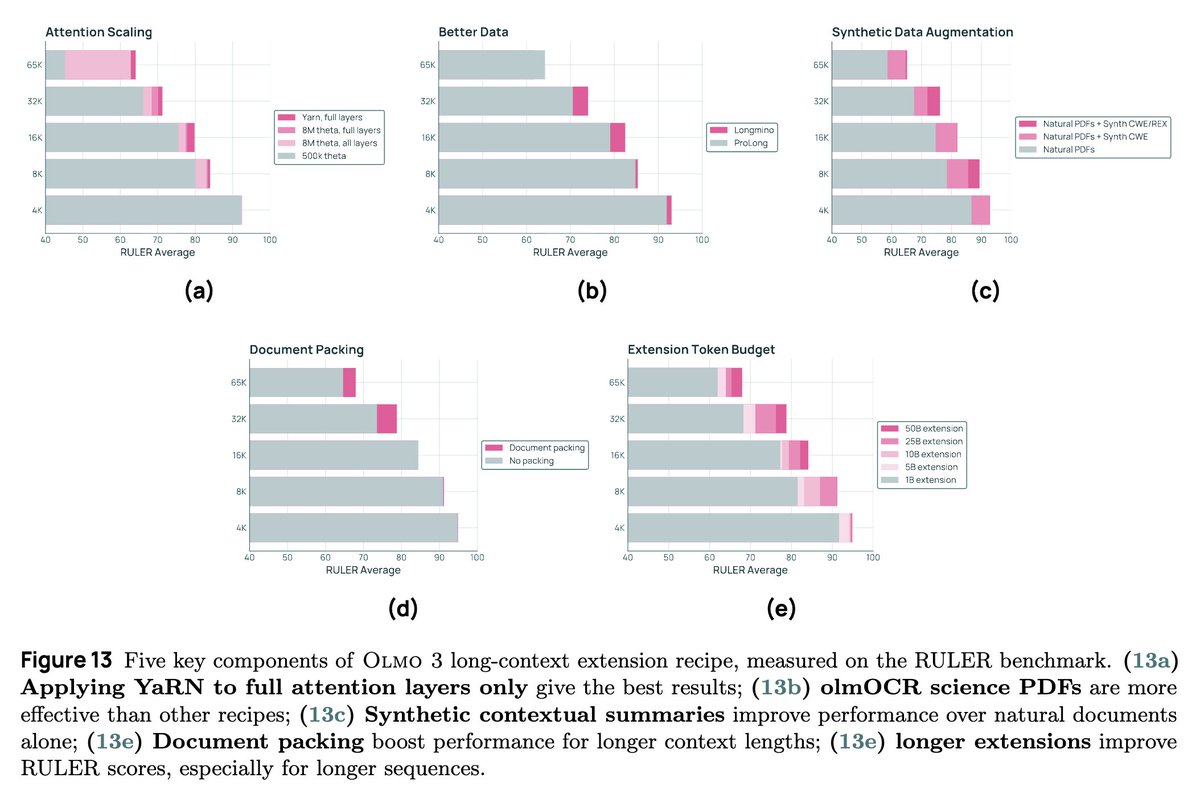
Not for nothing the Nemotron Nano 2 paper also had one of these cool untalked about facts which lead me to make this awesome Claude Shannon meme for a slide once. You need to train at least 2x your desired effective sequence length to get good performance.
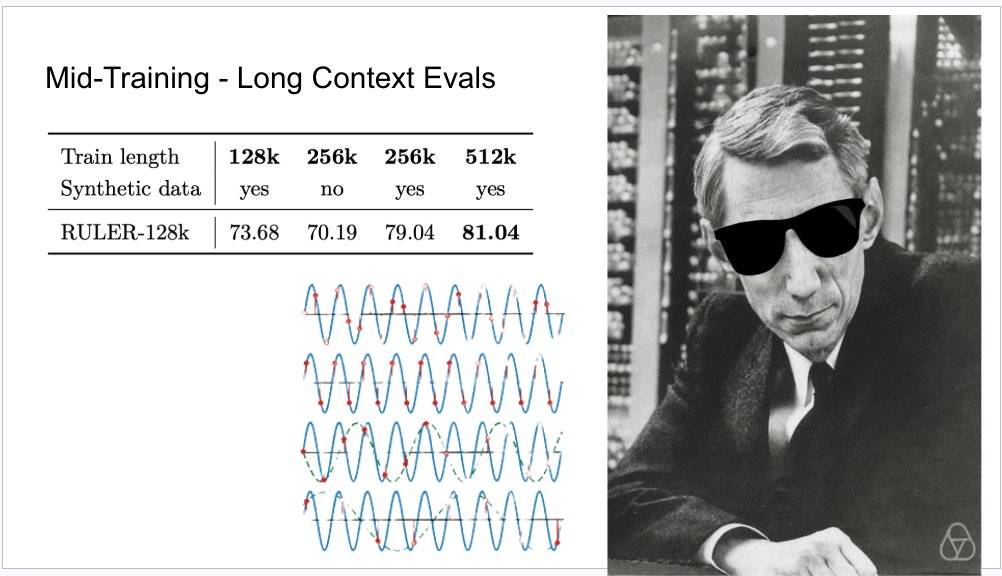
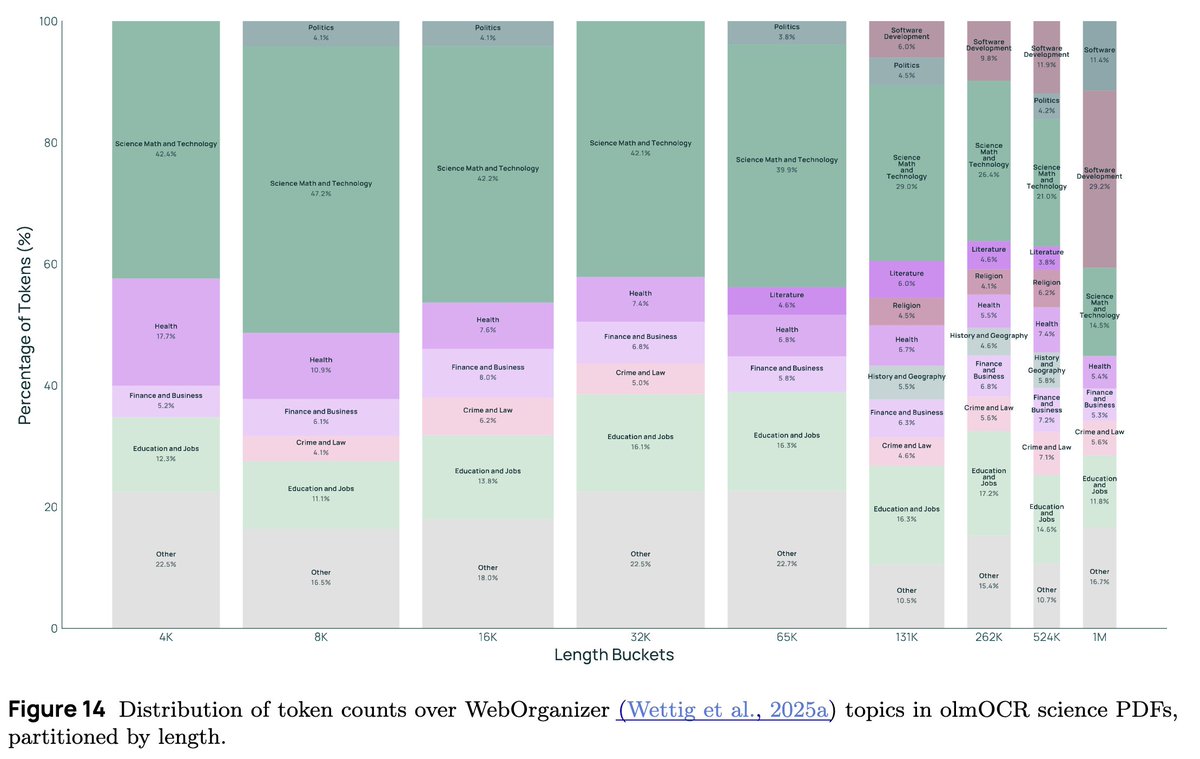
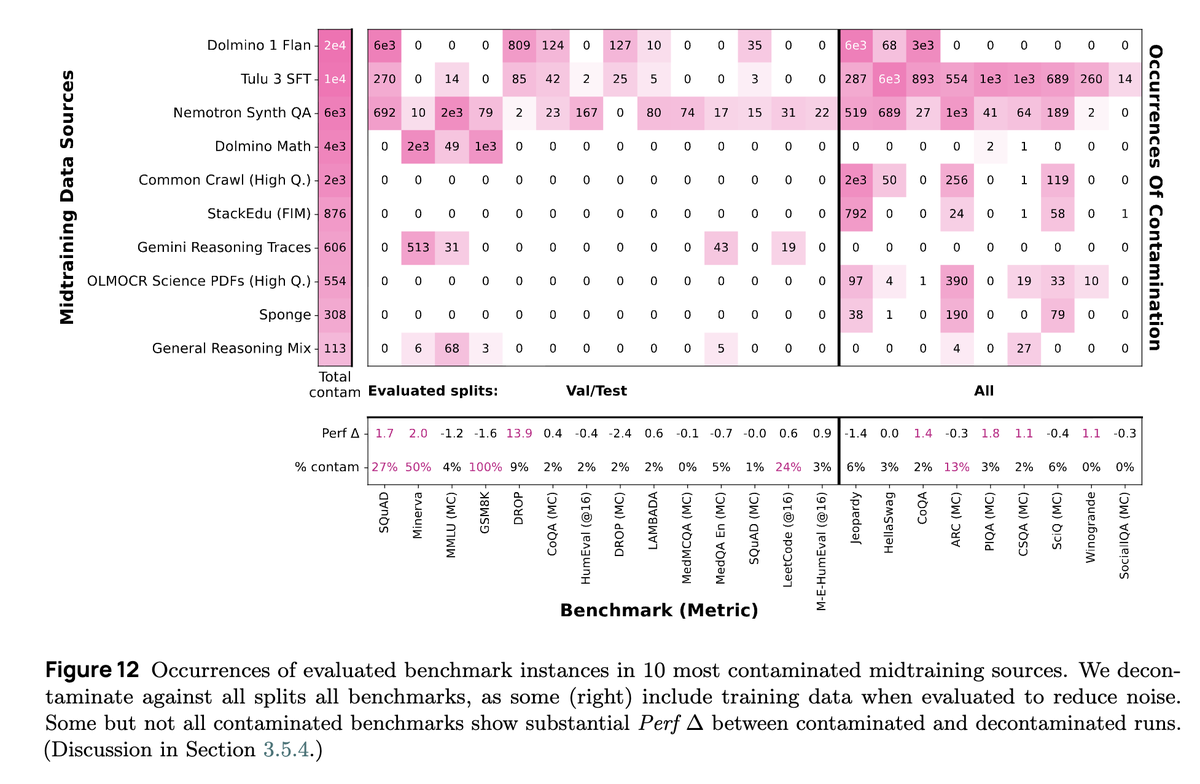
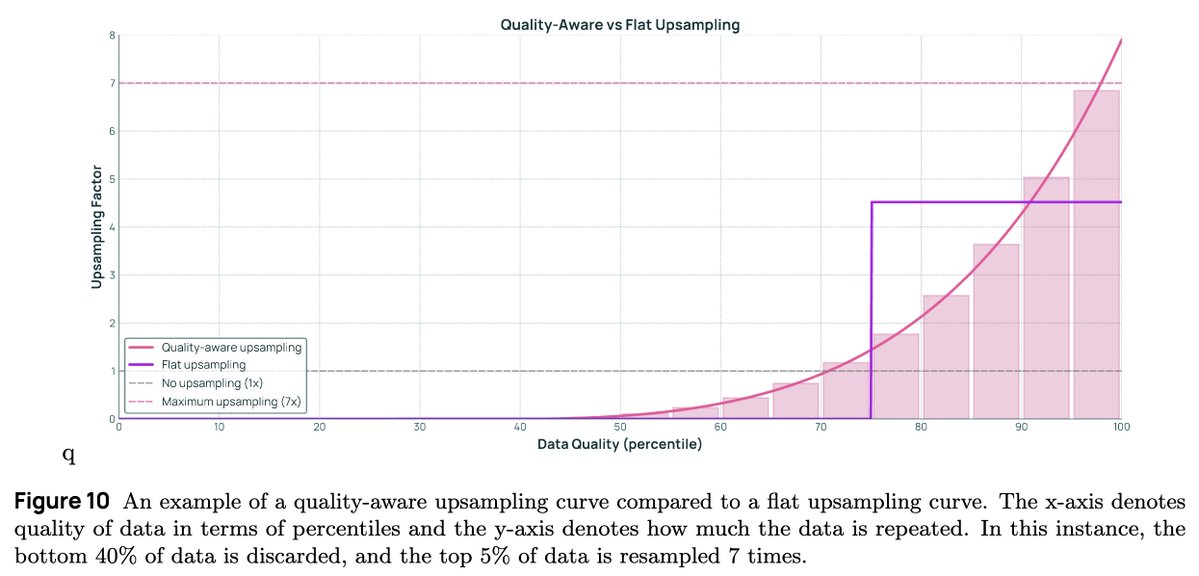
There is so much cool science to do on long context data research. Its basically never covered in tech reports other than the engineering efforts to solve sequence parallelism. Once again @allen_ai doing the lords work telling us the juicy details of what works and what doesn't
There is so much cool science to do on long context data research. Its basically never covered in tech reports other than the engineering efforts to solve sequence parallelism. Once again @allen_ai doing the lords work telling us the juicy details of what works and what doesn't

this is so good, taking my time to read this tech report like a good movie

Be sure to subscribe so you don’t miss it. I’m hoping to actually get some quotes from dataset creators as well. It should be a lot of fun. open.substack.com/pub/cod3star
I'm thinking about doing a fun history of LLM datasets series on my substack with my partner in crime @_BrettLarsen . Would anyone be interested in that? Part reading list, part oral history, and part recounting the bad old days when we counted tokens up hills both ways.
People that I know have trained big models (maybe bigger) have liked this tweet and I in the replies I have people telling me its impractical and can't be done. smh.
Can I ask a dumb question. Let’s say it is 7.5T total parameters. Now that super sparse MoEs are the norm … who cares how big the parameters get? 8x more total params than kimi shouldn’t be hard or surprising for one of the worlds best capitalized companies. 15T next year…

honestly getting carried by the impressive students @hamishivi @scottgeng00 @VictoriaWGraf @heinemandavidj @abertsch72 @MayeeChen @saumyamalik44 @mnoukhov @jacobcares and others 🙏🏻
yeah, don't forget all the other goats. Its a goat farm!



TECH REPORTS WITH INFORMATION AND STUFF 104 PAGES WE ARE SO, SO, SO BACK!!!!

✨ Try Olmo 3 in the Ai2 Playground → playground.allenai.org/?utm_source=x&… & our Discord → discord.gg/ai2 💻 Download: huggingface.co/collections/al… 📝 Blog: allenai.org/blog/olmo3?utm… 📚 Technical report: allenai.org/papers/olmo3?u…

Omg I just realized @pjreddie joined AI2 and now they are doing unhinged off axis plots. Total yolo victory.
This release has SO MUCH • New pretrain corpus, new midtrain data, 380B+ long context tokens • 7B & 32B, Base, Instruct, Think, RL Zero • Close to Qwen 3 performance, but fully open!!

Releases like this are, to me, more exciting than (very impressive) new SoTA models... Because when the OLMo team 🔥COOKS🔥 like this, we all get to read about it and learn from them!
This release has SO MUCH • New pretrain corpus, new midtrain data, 380B+ long context tokens • 7B & 32B, Base, Instruct, Think, RL Zero • Close to Qwen 3 performance, but fully open!!



























































































































United States Trendler
- 1. Good Friday 46.8K posts
- 2. LINGORM DIOR AT MACAU 311K posts
- 3. #ElMundoConVenezuela 1,591 posts
- 4. #TheWorldWithVenezuela 1,584 posts
- 5. #GenshinSpecialProgram 13.9K posts
- 6. #FridayVibes 3,438 posts
- 7. #FridayFeeling 1,820 posts
- 8. Josh Allen 42.6K posts
- 9. RED Friday 1,851 posts
- 10. Happy Friyay N/A
- 11. Texans 61.9K posts
- 12. Parisian 1,460 posts
- 13. Bills 154K posts
- 14. namjoon 64.5K posts
- 15. Niger 57.7K posts
- 16. Sedition 328K posts
- 17. Ja Rule N/A
- 18. Cole Palmer 15K posts
- 19. Beane 3,101 posts
- 20. Commander in Chief 84.8K posts
Bunları beğenebilirsin
-
 Abhi Venigalla
Abhi Venigalla
@ml_hardware -
 Tri Dao
Tri Dao
@tri_dao -
 Jonathan Frankle
Jonathan Frankle
@jefrankle -
 Sam Havens
Sam Havens
@sam_havens -
 Jan Leike
Jan Leike
@janleike -
 Matthew Leavitt
Matthew Leavitt
@leavittron -
 Sharon Li
Sharon Li
@SharonYixuanLi -
 Ofir Press
Ofir Press
@OfirPress -
 Vitaliy Chiley
Vitaliy Chiley
@vitaliychiley -
 Mihir Patel
Mihir Patel
@mvpatel2000 -
 Michael Carbin
Michael Carbin
@mcarbin -
 Tom Goldstein
Tom Goldstein
@tomgoldsteincs -
 labml.ai
labml.ai
@labmlai -
 Mostafa Dehghani
Mostafa Dehghani
@m__dehghani -
 rohan anil
rohan anil
@_arohan_
Something went wrong.
Something went wrong.