
你可能会喜欢








What if we could transform advanced math problems into abstract programs that can generate endless, verifiable problem variants? Presenting EFAGen, which automatically transforms static advanced math problems into their corresponding executable functional abstractions (EFAs).…


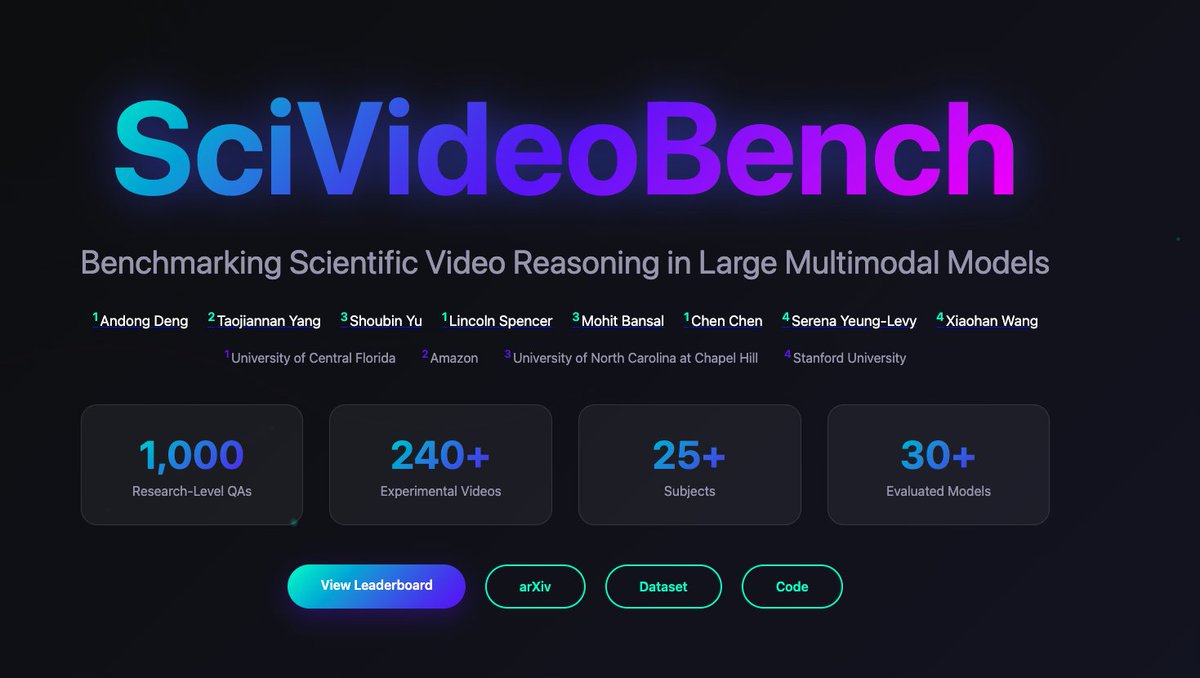
🚨 New Paper Alert! Introducing SciVideoBench — a comprehensive benchmark for scientific video reasoning! 🔬SciVideoBench: 1. Spans Physics, Chemistry, Biology & Medicine with authentic experimental videos. 2. Features 1,000 challenging MCQs across three reasoning types:…

We welcome Prof. Mohit Bansal (UNC Chapel Hill) as a keynote speaker at #CODS2025! Director of UNC’s MURGe-Lab, he works in multimodal generative models, reasoning agents & faithful language generation. He is an AAAI Fellow, PECASE and multiple best paper awardee.


🚨 Thrilled to introduce Self-Improving Demonstrations (SID) for Goal-Oriented Vision-and-Language Navigation — a scalable paradigm where navigation agents learn to explore by teaching themselves. ➡️ Agents iteratively generate and learn from their own successful trajectories ➡️…


Thanks for the shoutout! 🇨🇦I’ll be at #COLM2025 presenting two papers: GenerationPrograms (Attribution): Poster Session 4, Oct 8th, 4:30 PM QAPyramid (Summarization Eval): Poster Session 5, Oct 9th, 11:00 AM I’m also on the industry job market for research scientist roles.…

🚨 Check out our awesome students/postdocs' papers at #COLM2025 and say hi to them (several are on the job market or hiring) --> -- Archiki, David are on the post-PhD job market! -- Elias finished his postdoc & is now faculty at UT-Austin CS and looking to admit PhD students!…


❗️Self-evolution is quietly pushing LLM agents off the rails. ⚠️ Even perfect alignment at deployment can gradually forget human alignment and shift toward self-serving strategies. Over time, LLM agents stop following values, imitate bad strategies, and even spread misaligned…

🚨 Introducing ATP — Alignment Tipping Process! 🔥 Beware! Self-Evolution is gradually pushing LLM Agents off the rails! Even perfect alignment at deployment can gradually forget human alignment and shift toward self-serving strategies. #AI #LLM #Agents #SelfEvolving #Alignment…


I am attending #COLM2025 🇨🇦 this week to present our work on: Unit Test Generation: 📅 Oct 8th (Wed), 4:30 PM, #79 RAG with conflicting evidence: 📅 Oct 9th (Thu), 11 AM, #71 PS: I'm on the industry job market for RS roles, so you can reach me via DM or in-person to chat! 😄
🚨 Check out our awesome students/postdocs' papers at #COLM2025 and say hi to them (several are on the job market or hiring) --> -- Archiki, David are on the post-PhD job market! -- Elias finished his postdoc & is now faculty at UT-Austin CS and looking to admit PhD students!…

✈️ Arrived at #COLM2025 where I'll be helping to present the following 4 papers. I'm also recruiting multiple PhD students for my new lab at UT Austin -- happy to chat about research, PhD applications, or postdoc openings in my former postdoc lab at UNC! -- Learning to Generate…
🚨 Check out our awesome students/postdocs' papers at #COLM2025 and say hi to them (several are on the job market or hiring) --> -- Archiki, David are on the post-PhD job market! -- Elias finished his postdoc & is now faculty at UT-Austin CS and looking to admit PhD students!…
-- Postdoc openings info/details 👇 (flyer+links: cs.unc.edu/~mbansal/postd…) Also, PhD admissions/openings info: cs.unc.edu/~mbansal/prosp… x.com/mohitban47/sta…
🚨 We have postdoc openings at UNC 🙂 Exciting+diverse NLP/CV/ML topics**, freedom to create research agenda, competitive funding, very strong students, many collabs w/ other faculty & universities+companies, superb quality of life/weather. Please apply + help spread the word…

(detailed links + websites + summary 🧵's of these papers attached below FYI 👇) -- Learning to Generate Unit Tests for Automated Debugging. @ArchikiPrasad @EliasEskin @cyjustinchen @codezakh arxiv.org/abs/2502.01619 x.com/ArchikiPrasad/…
🚨 Excited to share: "Learning to Generate Unit Tests for Automated Debugging" 🚨 which introduces ✨UTGen and UTDebug✨ for teaching LLMs to generate unit tests (UTs) and debugging code from generated tests. UTGen+UTDebug improve LLM-based code debugging by addressing 3 key…

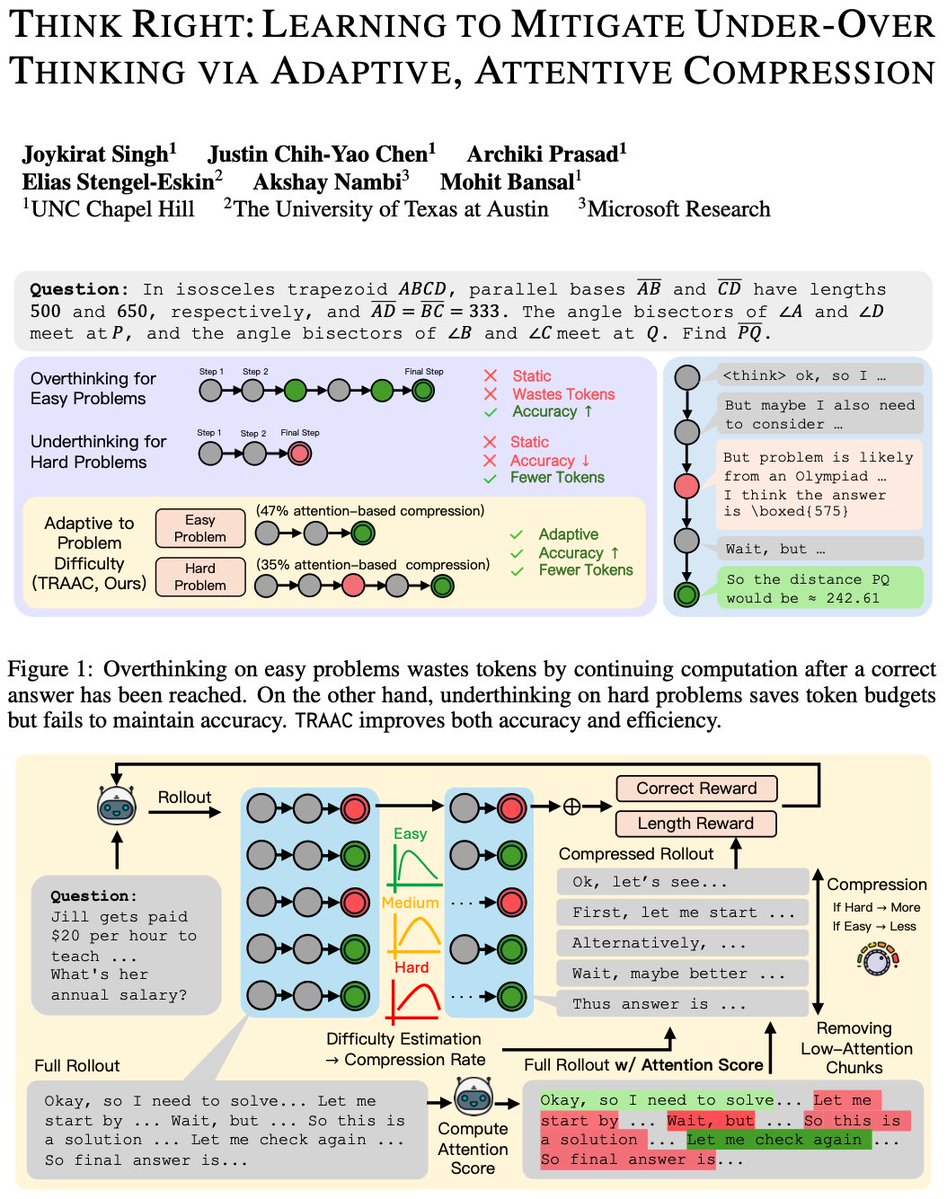
🚨 "Think the right amount" for improving both reasoning accuracy and efficiency! --> Large reasoning models under-adapt = underthink on hard problems and overthink on easy ones --> ✨TRAAC✨ is an online RL, difficulty-adaptive, attention-based compression method that prunes…

🚨 Excited to announce TRAAC, an online difficulty-adaptive, attention-based method that handles the tradeoff of under & overthinking in reasoning models to improve both accuracy and efficiency. Underthinking ❌: Models terminate reasoning too early on harder problems, leading…
🚨 Check out our awesome students/postdocs' papers at #COLM2025 and say hi to them (several are on the job market or hiring) --> -- Archiki, David are on the post-PhD job market! -- Elias finished his postdoc & is now faculty at UT-Austin CS and looking to admit PhD students!…

Large reasoning models suffer from under-adaptiveness, which underthink on hard problems and overthink on easy ones. TRAAC addresses this by introducing ✨difficulty calibration and attention-based compression✨→ +8.4% accuracy & +36.8% efficiency! 1️⃣ TRAAC adaptively mitigates…
🚨 Excited to announce TRAAC, an online difficulty-adaptive, attention-based method that handles the tradeoff of under & overthinking in reasoning models to improve both accuracy and efficiency. Underthinking ❌: Models terminate reasoning too early on harder problems, leading…
🚨 Excited to announce TRAAC, an online difficulty-adaptive, attention-based method that handles the tradeoff of under & overthinking in reasoning models to improve both accuracy and efficiency. Underthinking ❌: Models terminate reasoning too early on harder problems, leading…

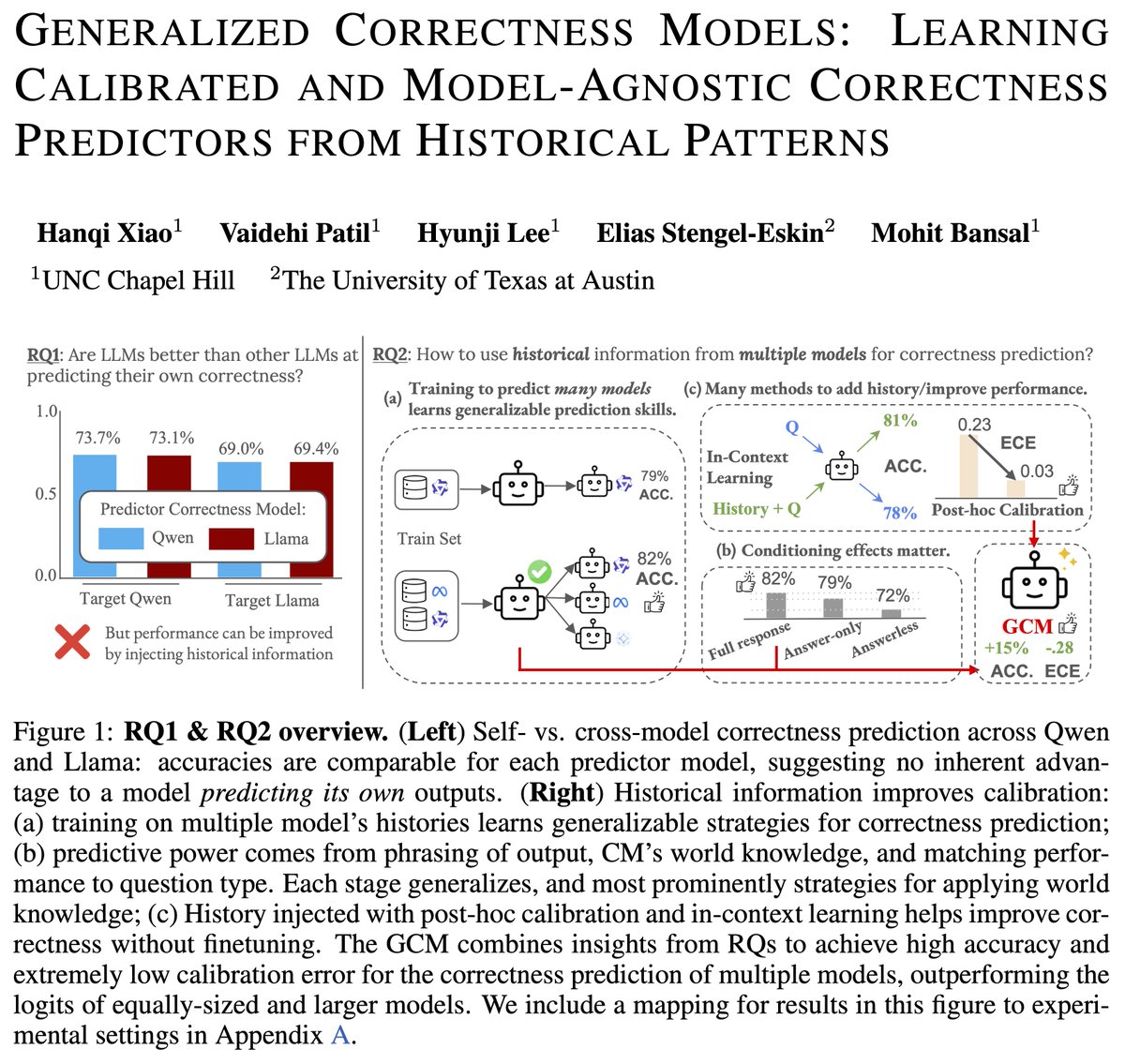
🚨Excited to announce General Correctness Models (GCM): 🔎We find no special advantage using an LLM to predict its own correctness, instead finding that LLMs benefit from learning to predict the correctness of many other models – becoming a GCM. Huge thanks to @vaidehi_patil_,…
🚨 Announcing Generalized Correctness Models (GCMs) 🚨Finding that LLMs have little self knowledge about their own correctness, we train an 8B GCM to predict correctness of many models, which is more accurate than training model-specific CMs, and outperforms a larger…
Can attest that this is true 🙂 and now there are RS emulators (github.com/LostCityRS/Ser…) which could be turned into a pretty cool environment to eval agents on — there are 100+ quests, lots of bosses to defeat, a legible "tech tree" with smithing, crafting etc


🚨 Introducing DINCO, a zero-resource calibration method for verbalized LLM confidence. We normalize over self-generated distractors to enforce coherence ➡️ better-calibrated and less saturated (more usable) confidence! ⚠️ Problem: Standard verbalized confidence is overconfident…

🚨 NuRL: Nudging the Boundaries of LLM Reasoning -- GRPO improves LLM reasoning, but stays within the model's "comfort zone" i.e., hard samples (0% pass rate) remain unsolvable and contribute no meaningful gradients. -- In NuRL, we show that "nudging" the LLM with…
🚨 NuRL: Nudging the Boundaries of LLM Reasoning GRPO improves LLM reasoning, but often within the model's "comfort zone": hard samples (w/ 0% pass rate) remain unsolvable and contribute zero learning signals. In NuRL, we show that "nudging" the LLM with self-generated hints…

🚨 NuRL: Nudging the Boundaries of LLM Reasoning GRPO improves LLM reasoning, but often within the model's "comfort zone": hard samples (w/ 0% pass rate) remain unsolvable and contribute zero learning signals. In NuRL, we show that "nudging" the LLM with self-generated hints…
🚨 Announcing Generalized Correctness Models (GCMs) 🚨Finding that LLMs have little self knowledge about their own correctness, we train an 8B GCM to predict correctness of many models, which is more accurate than training model-specific CMs, and outperforms a larger…
Shiny new building and good views from the new VirginiaTech campus in DC 😉 -- it was a pleasure to meet everyone and engage in exciting discussions about trustworthy agents, collaborative reasoning/privacy, and controllable multimodal generation -- thanks again @profnaren,…


Looking forward to giving this Distinguished Lecture at Virginia Tech on Friday & meeting the awesome faculty+students there! 🙂 Will also discuss some of our new work in multi-agent compositional privacy risks+mitigation, ambiguity/loophole exploitation by LLMs, and bridging…
























































































United States 趋势
- 1. D’Angelo 148K posts
- 2. Brown Sugar 13.1K posts
- 3. Black Messiah 5,926 posts
- 4. #GoodTimebro 1,451 posts
- 5. Voodoo 13.2K posts
- 6. Powell 34.4K posts
- 7. Happy Birthday Charlie 113K posts
- 8. How Does It Feel 6,390 posts
- 9. #PortfolioDay 8,549 posts
- 10. Osimhen 84.1K posts
- 11. #BornOfStarlightHeeseung 78.3K posts
- 12. Alex Jones 26.2K posts
- 13. Pentagon 94.3K posts
- 14. Neo-Soul 13.6K posts
- 15. Sandy Hook 10.1K posts
- 16. Untitled 5,476 posts
- 17. Jill Scott N/A
- 18. Rwanda 54.8K posts
- 19. #csm217 4,181 posts
- 20. Grammy-winning R&B 1,726 posts








Something went wrong.
Something went wrong.