
おすすめツイート










How can an agent reverse engineer the underlying laws of an unknown, hostile & stochastic environment in “one life”, without millions of steps + human-provided goals / rewards? In our work, we: 1️⃣ infer an executable symbolic world model (a probabilistic program capturing…

Today, we’re announcing the next chapter of Terminal-Bench with two releases: 1. Harbor, a new package for running sandboxed agent rollouts at scale 2. Terminal-Bench 2.0, a harder version of Terminal-Bench with increased verification


We live, feel, and create by perceiving the world as visual spaces unfolding through time — videos. Our memories and even our language are spatial: mind-palaces, mind-maps, "taking steps in the right direction..." Super excited to see Cambrian-S pushing this frontier! And,…

Introducing Cambrian-S it’s a position, a dataset, a benchmark, and a model but above all, it represents our first steps toward exploring spatial supersensing in video. 🧶

MLLMs are great at understanding videos, but struggle with spatial reasoning—like estimating distances or tracking objects across time. the bottleneck? getting precise 3D spatial annotations on real videos is expensive and error-prone. introducing SIMS-V 🤖 [1/n]

I'll be presenting ✨MAgICoRe✨ virtually tonight at 7 PM ET / 8 AM CST (Gather Session 3)! I'll discuss 3 key challenges in LLM refinement for reasoning, and how MAgICoRe tackles them jointly: 1⃣ Over-correction on easy problems 2⃣ Failure to localize & fix its own errors 3⃣…

🚨 Check out our awesome students/postdocs' papers at #EMNLP2025 and say hi to them 👋! Also, I will give a keynote (virtually) on "Attributable, Conflict-Robust, and Multimodal Summarization with Multi-Source Retrieval" at the NewSumm workshop. -- Jaehong (in-person) finished…


🎉Thanks for the shoutout! I’ll be virtually presenting our new work Video-RTS at #EMNLP2025 (my co-lead @jaeh0ng_yoon will present in person). If you’re into advanced video-reasoning frameworks, check it out: - No SFT, pure RL: trains with simple output-based rewards (GRPO)—no…
🚨 Check out our awesome students/postdocs' papers at #EMNLP2025 and say hi to them 👋! Also, I will give a keynote (virtually) on "Attributable, Conflict-Robust, and Multimodal Summarization with Multi-Source Retrieval" at the NewSumm workshop. -- Jaehong (in-person) finished…
🚨 Check out our awesome students/postdocs' papers at #EMNLP2025 and say hi to them 👋! Also, I will give a keynote (virtually) on "Attributable, Conflict-Robust, and Multimodal Summarization with Multi-Source Retrieval" at the NewSumm workshop. -- Jaehong (in-person) finished…

🚨 Excited to announce Gistify!, where a coding agent must extract the gist of a repository: generate a single, executable, and self-contained file that faithfully reproduces the behavior of a given command (e.g., a test or entrypoint). ✅ It is a lightweight, broadly applicable…


🎉 Excited to share that 5/5 of my papers (3 main, 2 findings) have been accepted at #EMNLP2025, in video/multimodal reasoning, instructional video editing, and efficient LLM adaptation & reasoning! 🚨 I’m recruiting Ph.D. students to join the Multimodal AI Group at NTU College…

It was an honor and pleasure to give a keynote at the 28th European Conference on Artificial Intelligence (#ECAI2025) in beautiful Bologna, and engage in enthusiastic discussions about trustworthy + calibrated agents, collaborative reasoning + privacy, and controllable multimodal…





🥳🥳 Honored and grateful to be awarded a 2025 Google PhD Fellowship in Machine Learning and ML Foundations for my research on machine unlearning, defenses against adversarial attacks, and multi-agent privacy! ✨ Deep gratitude to my advisor @mohitban47 for his constant…

🎉 We're excited to announce the 2025 Google PhD Fellows! @GoogleOrg is providing over $10 million to support 255 PhD students across 35 countries, fostering the next generation of research talent to strengthen the global scientific landscape. Read more: goo.gle/43wJWw8

🎉 Big congratulations to Vaidehi on being awarded a Google PhD Fellowship in Machine Learning and ML Foundations for her important research contributions in machine unlearning for LLMs/VLMs, defenses against adversarial attacks, and multi-agent privacy! #ProudAdvisor 👇👇
🥳🥳 Honored and grateful to be awarded a 2025 Google PhD Fellowship in Machine Learning and ML Foundations for my research on machine unlearning, defenses against adversarial attacks, and multi-agent privacy! ✨ Deep gratitude to my advisor @mohitban47 for his constant…

Tough week! I also got impacted less than 3 months after joining. Ironically, I just landed some new RL infra features the day before. Life moves on. My past work spans RL, PEFT, Quantization, and Multimodal LLMs. If your team is working on these areas, I’d love to connect.

Meta has gone crazy on the squid game! Many new PhD NGs are deactivated today (I am also impacted🥲 happy to chat)
🚨 🤯 Wow! Yi Lin is an amazing researcher, who works on very hard and important problems in LLM and VLM training, RL, PEFT, Quantization, etc. -- ironically, he had several other top offers just a few months ago! Hire him ASAP if you want to pick up a top talent (and several…
Tough week! I also got impacted less than 3 months after joining. Ironically, I just landed some new RL infra features the day before. Life moves on. My past work spans RL, PEFT, Quantization, and Multimodal LLMs. If your team is working on these areas, I’d love to connect.

🚨 Excited to share PoSH, a graph-based, fine-grained, and interpretable metric for detailed image descriptions! PoSH allows us to not only evaluate generated image descriptions but localize hallucinations and errors in them. To test PoSH, we also introduce DOCENT, a new and…

🚨 Are your detailed image descriptions what you (really really) want? Let PoSh be the judge. Introducing PoSh, a new graph-based metric for detailed image descriptions, and DOCENT, a novel & challenging benchmark of art w/ detailed descriptions and strong human judgments 🧵


Can AI models teach you to shoot like Steph Curry? 🏀 Come to my talk on Challenges in Expert-Level Skill Analysis at 4:30 pm in Room 318-A tomorrow (Sunday) to find out! sauafg-workshop.github.io #ICCV2025
sauafg-workshop.github.io
SAUAFG Workshop – ICCV 2025
ICCV 2025 SAUAFG Workshop on AI-driven skill assessment, understanding, and feedback generation.

🗓Oct 19, 2025 | 📍Hawaii Convention Center, Room 318-A 👉 Learn more: sauafg-workshop.github.io 🔍 We'll explore AI-driven Skilled Activity Understanding, Assessment & Guidance generation in various domains from Surgery to Sports, from Robotics and Manufacturing to Education
sauafg-workshop.github.io
SAUAFG Workshop – ICCV 2025
ICCV 2025 SAUAFG Workshop on AI-driven skill assessment, understanding, and feedback generation.
🎉 Big congrats to Zaid on being awarded the NDSEG PhD Fellowship, for his innovative contributions in environment/data generation, skill-based self-improvement and adaptable agents, visual program synthesis, and world model inference! #ProudAdvisor 👇👇
🥳 Honored and grateful to be awarded an NDSEG Fellowship in Computer Science! 💫🇺🇸 Big thanks to my advisor @mohitban47 for his guidance, and shoutout to my lab mates at @unc_ai_group, collaborators, internship advisors, and mentors for their support 🤗 Excited to continue…
🥳 Honored and grateful to be awarded an NDSEG Fellowship in Computer Science! 💫🇺🇸 Big thanks to my advisor @mohitban47 for his guidance, and shoutout to my lab mates at @unc_ai_group, collaborators, internship advisors, and mentors for their support 🤗 Excited to continue…

🎉 Congratulations to our student Zaid Khan (advised by @mohitban47) for being awarded a prestigious NDSEG Fellowship for his work on environment generation! Established in 1989, the fellowship has an acceptance rate of <7% and covers diverse science and engineering disciplines.


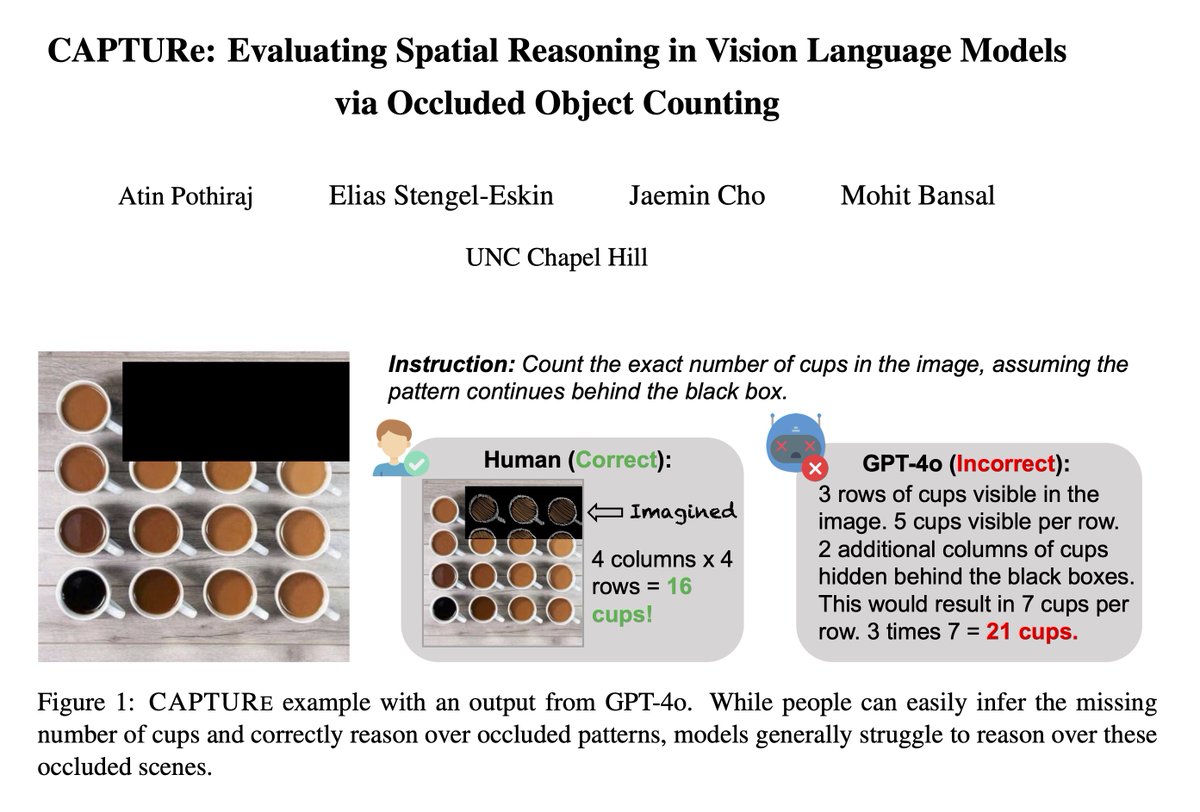
Check out 🚨CAPTURe🚨 -- a new benchmark and task testing spatial reasoning by making VLMs count objects under occlusion. Key Takeaways: ➡️ SOTA VLMs (GPT-4o, Qwen2-VL, Intern-VL2) have high error rates on CAPTURe (but humans get very low error ✅) and models struggle to reason…

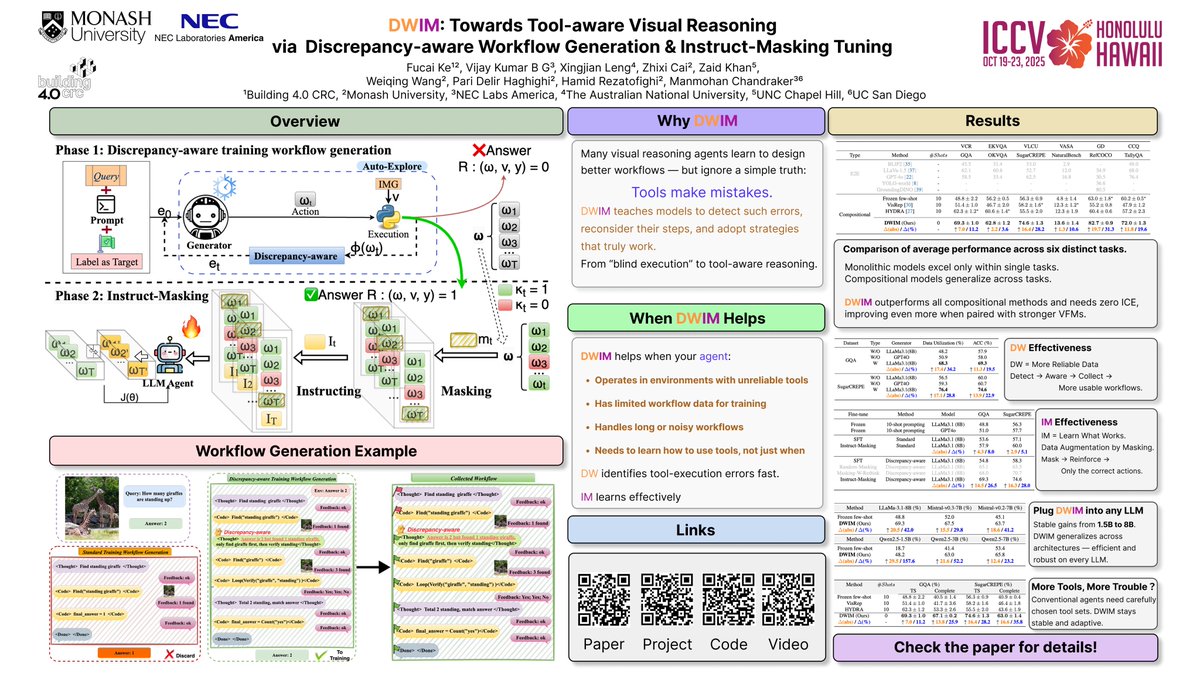
I will be presenting our recent work, “DWIM: Towards Tool-aware Visual Reasoning via Discrepancy-aware Workflow Generation & Instruct-Masking Tuning,” at #ICCV2025 . ⌚️Oct. 21, 11:30-13:30 👉Exhibit Hall I, #314
🚨 If you are at #ICCV2025, make sure to talk to Jaemin for his new group at @jhuclsp @JHUCompSci -- he has done a lot of foundational research in multimodality+other areas & will be a great advisor! 👇👇
Excited to be at #ICCV2025 in Hawaii!🌴 I'll present two papers: M3DocVQA/M3DocRAG (Mon) and CAPTURe (Tue). Check our poster sessions👇 and feel free to ping me to grab a coffee together I'm hiring PhD students to work on multimodal AI and robotics with me at JHU from Fall 2026!













































































United States トレンド
- 1. #Worlds2025 40.7K posts
- 2. #TalusLabs N/A
- 3. Doran 16.9K posts
- 4. #T1WIN 26.4K posts
- 5. Sam Houston 1,585 posts
- 6. Boots 29.1K posts
- 7. Oregon State 4,797 posts
- 8. Faker 31.6K posts
- 9. Lubin 5,776 posts
- 10. Keria 10.4K posts
- 11. #T1fighting 3,366 posts
- 12. #Toonami 2,719 posts
- 13. Louisville 14.3K posts
- 14. Hyan 1,378 posts
- 15. Option 2 4,118 posts
- 16. Emmett Johnson 2,614 posts
- 17. UCLA 7,802 posts
- 18. Oilers 5,309 posts
- 19. Nuss 5,599 posts
- 20. Frankenstein 125K posts
おすすめツイート
-
 Alex Thiery
Alex Thiery
@alexxthiery -
 Olivia White, PharmD, BCOP
Olivia White, PharmD, BCOP
@olivia__white1 -
 Molly Miller
Molly Miller
@Molly_M_Miller -
 Nicholas Rebold, PharmD, MPH, BCIDP, AAHIVP
Nicholas Rebold, PharmD, MPH, BCIDP, AAHIVP
@NicholasRebold -
 Ferhat
Ferhat
@0xCrispy -
 majin bru
majin bru
@saibayadon -
 Alireza FakhriRavari, PharmD, BCPS, BCIDP, AAHIVP
Alireza FakhriRavari, PharmD, BCPS, BCIDP, AAHIVP
@LordAlirezaF -
 Dan van der Merwe
Dan van der Merwe
@danieljvdm -
 Andros Guiradó
Andros Guiradó
@_Andros__ -
 Aishwarya Mandyam
Aishwarya Mandyam
@Aishwarya_R_M
Something went wrong.
Something went wrong.