
Zaid Khan
@codezakh
NDSEG Fellow / PhD @uncnlp with @mohitban47 working on automating env/data generation + program synthesis formerly @allenai @neclabsamerica
You might like










How can an agent reverse engineer the underlying laws of an unknown, hostile & stochastic environment in “one life”, without millions of steps + human-provided goals / rewards? In our work, we: 1️⃣ infer an executable symbolic world model (a probabilistic program capturing…

Multimodal LLMs (MLLMs) excel at reasoning, layout understanding, and planning—yet in diffusion-based generation, they are often reduced to simple multimodal encoders. What if MLLMs could reason directly in latent space and guide diffusion generation with fine-grained,…
Big congrats to Mohit on becoming an ACL Fellow! 🥳 He's been a tireless researcher and mentor and seeing it recognized makes me happy 🥲👏

Deeply happy and honored to be elected as an ACL Fellow -- and to be a part of the respected cohort of this+past years' fellows (congrats everyone)! 🙏 All the credit (and sincere gratitude) to all my amazing students, postdocs, collaborators, mentors, and family! 🤗💙

Deeply happy and honored to be elected as an ACL Fellow -- and to be a part of the respected cohort of this+past years' fellows (congrats everyone)! 🙏 All the credit (and sincere gratitude) to all my amazing students, postdocs, collaborators, mentors, and family! 🤗💙

🚨 Excited to share DART, a multi-agent multimodal debate framework that uses disagreement between VLM agents to address visual uncertainty. VLM debate stagnates and VLMs can struggle with which tools to call – we use disagreement to recruit visual tools (e.g. OCR, spatial…


🚨 Active Video Perception: Iterative Evidence Seeking for Agentic Long Video Understanding 🚨 Introducing Active Video Perception: an evidence-seeking framework that treats the video as an interactive environment and acquires compact, query-relevant evidence. 🎬 Key…

How can we make a better TerminalBench agent? Today, we are announcing the OpenThoughts-Agent project. OpenThoughts-Agent v1 is the first TerminalBench agent trained on fully open curated SFT and RL environments. OpenThinker-Agent-v1 is the strongest model of its size on…


The OpenThoughts team is now tackling data for post-training agents! Our first RL environments and SFT trajectories datasets are just the start of our open research collaboration. I’m very excited for the path ahead. We have a great team assembled and have been working…
How can we make a better TerminalBench agent? Today, we are announcing the OpenThoughts-Agent project. OpenThoughts-Agent v1 is the first TerminalBench agent trained on fully open curated SFT and RL environments. OpenThinker-Agent-v1 is the strongest model of its size on…

#NeurIPS2025 is live! I'll be in San Diego through Saturday (Dec 06) and would love to meet prospective graduate students interested in joining my lab at JHU. If you're excited about multimodal AI, robotics, unified models, learning action/motion from video, etc. let’s chat!…
Sharing some personal updates 🥳: - I've completed my PhD at @unccs! 🎓 - Starting Fall 2026, I'll be joining the Computer Science dept. at Johns Hopkins University (@JHUCompSci) as an Assistant Professor 💙 - Currently exploring options + finalizing the plan for my gap year (Aug…



🤔 We rely on gaze to guide our actions, but can current MLLMs truly understand it and infer our intentions? Introducing StreamGaze 👀, the first benchmark that evaluates gaze-guided temporal reasoning (past, present, and future) and proactive understanding in streaming video…
🚨 Excited to be (remotely) giving a talk tomorrow 12/2 at the "Exploring Trust and Reliability in LLM Evaluation" #NeurIPS expo workshop! I’ll be presenting our work on pragmatic training to improve calibration and persuasion, and skill-based granular evaluation for data…
🏖️ Heading to San Diego for #NeurIPS (Dec 2-7th)! I will be presenting: Bifrost-1: Bridging Multimodal LLMs and Diffusion Models with Patch-level CLIP Latents 🗓️ Thu 4 Dec 4:30 p.m. PT — 7:30 p.m. PT | Exhibit Hall C,D,E #4412 Excited to chat about our follow-up work on…
🎉 Excited to share that Bifrost-1 has been accepted to #NeurIPS2025! ☀️ Bridging MLLMs and diffusion into a unified multimodal understanding and generation model can be very costly to train. ✨ Bifrost-1 addresses this by leveraging patch-level CLIP latents that are natively…

I will be at #NeurIPS2025 to present our work: "LASeR: Learning to Adaptively Select Reward Models with Multi-Armed Bandits". Come visit our poster: 🗓️ Thu 4 Dec, 4:30 p.m. – 7:30 p.m. PST | Exhibit Hall C,D,E #4108 Let's connect and chat about LLM post-training, inference-time…

Reward Models (RMs) are crucial for RLHF training, but: Using single RM: 1⃣ poor generalization, 2⃣ ambiguous judgements & 3⃣ over-optimization Using multiple RMs simultaneously: 1⃣ resource-intensive & 2⃣ susceptible to noisy/conflicting rewards 🚨We introduce ✨LASeR✨,…

⛱️ Heading to San Diego for #NeurIPS (Dec 2-7th)! I am on the industry job market & will be presenting: LASeR: Learning to Adaptively Select Reward Models with Multi-Arm Bandits (🗓️Dec 4, 4:30PM) Excited to chat about research (reasoning, LLM agents, post-training) & job…
🎉Excited to share that LASeR has been accepted to #NeurIPS2025!☀️ RLHF with a single reward model can be prone to reward-hacking while ensembling multiple RMs is costly and prone to conflicting rewards. ✨LASeR addresses this by using multi-armed bandits to select the most…

🚨 Thrilled to share Prune-Then-Plan! - VLM-based EQA agents often move back-and-forth due to miscalibration. - Our Prune-Then-Plan method filters noisy frontier choices and delegates planning to coverage-based search. - This yields stable, calibrated exploration and…

🚨Introducing our new work, Prune-Then-Plan — a method that enables AI agents to better explore 3D scenes for embodied question answering (EQA). 🧵 1/2 🟥 Existing EQA systems leverage VLMs to drive exploration choice at each step by selecting the ‘best’ next frontier, but…

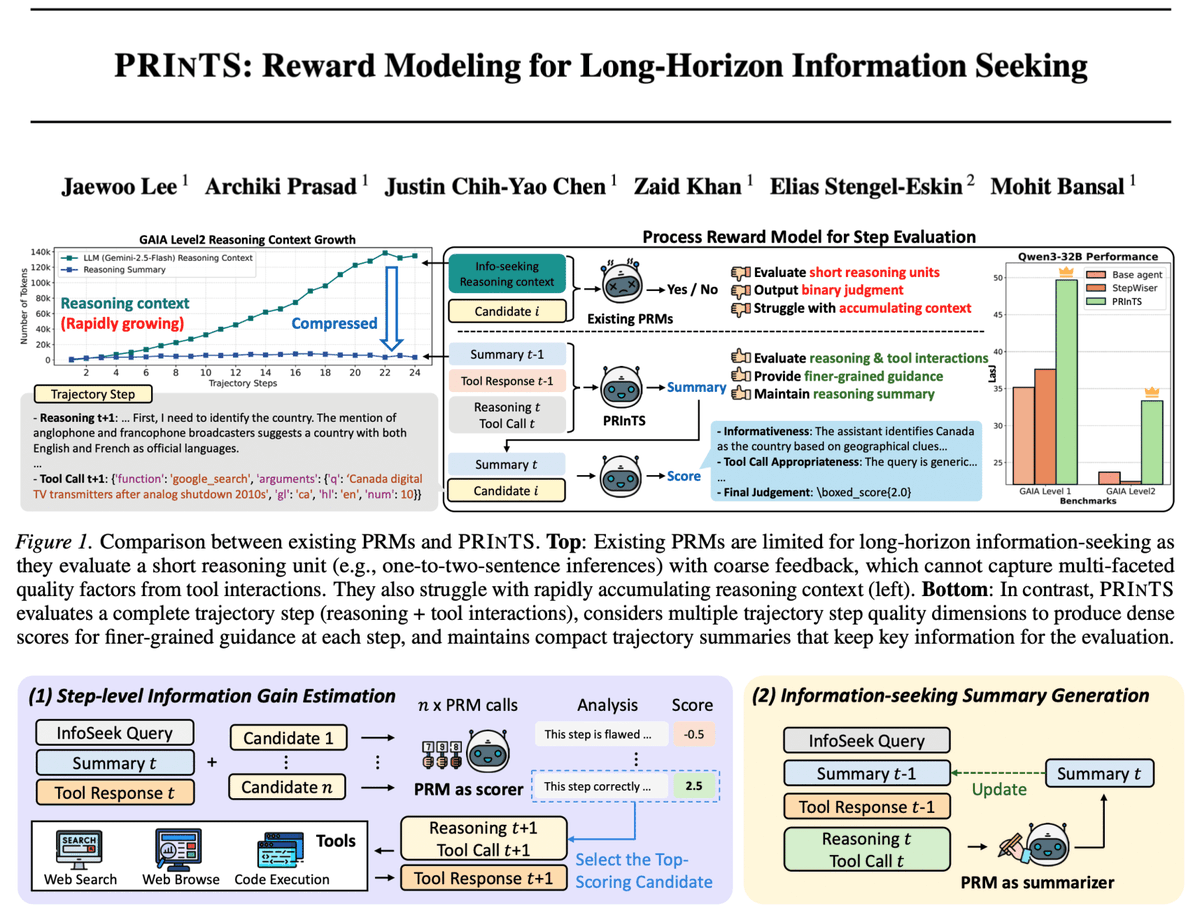
🚨 Check out our generative process reward model, PRInTS, that improves agents' complex, long-horizon information-seeking capabilities via: 1⃣ novel MCTS-based fine-grained information-gain scoring across multiple dimensions. 2⃣ accurate step-level guidance based on compression…
🚨 Excited to announce ✨PRInTS✨, a generative Process Reward Model (PRM) that improves agent’s long-horizon info-seeking via info-gain scoring + summarization. PRInTS guides open + specialized agents with major boosts 👉+9.3% avg. w/ Qwen3-32B across GAIA, FRAMES &…
Thanks @_akhaliq for posting about our work on guiding agents for long-horizon information-seeking tasks using a generative process reward model! For more details, see the original thread: x.com/ArchikiPrasad/…


We want agents to solve problems that require searching and exploring multiple paths over long horizons, such as complex information seeking tasks which require the agent to answer questions by exploring the internet. Process Reward Models (PRMs) are a promising approach which…
🚨 Excited to announce ✨PRInTS✨, a generative Process Reward Model (PRM) that improves agent’s long-horizon info-seeking via info-gain scoring + summarization. PRInTS guides open + specialized agents with major boosts 👉+9.3% avg. w/ Qwen3-32B across GAIA, FRAMES &…

Long-horizon information-seeking tasks remain challenging for LLM agents, and existing PRMs (step-wise process reward models) fall short because: 1⃣ the reasoning process involves interleaved tool calls and responses 2⃣ the context grows rapidly due to the extended task horizon…
🚨 Excited to announce ✨PRInTS✨, a generative Process Reward Model (PRM) that improves agent’s long-horizon info-seeking via info-gain scoring + summarization. PRInTS guides open + specialized agents with major boosts 👉+9.3% avg. w/ Qwen3-32B across GAIA, FRAMES &…













































































United States Trends
- 1. TravisScott N/A
- 2. #FanCashDropPromotion 1,882 posts
- 3. Merry Christmas 161K posts
- 4. Strahm 2,209 posts
- 5. Tucker 134K posts
- 6. #NXXT_NEWS N/A
- 7. Good Friday 57K posts
- 8. Isiah 2,136 posts
- 9. Ben Shapiro 73.1K posts
- 10. #FridayVibes 3,896 posts
- 11. #FursuitFriday 12.4K posts
- 12. Lifesaving 5,155 posts
- 13. Bowlan N/A
- 14. #FridayMotivation 3,224 posts
- 15. Myrtle Beach Bowl N/A
- 16. Kennesaw State N/A
- 17. Royals 8,001 posts
- 18. RED Friday 3,034 posts
- 19. Algorhythm Holdings N/A
- 20. NextNRG Inc 3,415 posts
You might like
-
 Alex Thiery
Alex Thiery
@alexxthiery -
 Olivia White, PharmD, BCOP
Olivia White, PharmD, BCOP
@olivia__white1 -
 Molly Miller
Molly Miller
@Molly_M_Miller -
 Nicholas Rebold, PharmD, MPH, BCIDP, AAHIVP
Nicholas Rebold, PharmD, MPH, BCIDP, AAHIVP
@NicholasRebold -
 Elizabeth Mieczkowski
Elizabeth Mieczkowski
@beth_miecz -
 Ferhat
Ferhat
@0xCrispy -
 majin bru
majin bru
@saibayadon -
 Alireza FakhriRavari, PharmD, BCPS, BCIDP, AAHIVP
Alireza FakhriRavari, PharmD, BCPS, BCIDP, AAHIVP
@LordAlirezaF -
 Dan van der Merwe
Dan van der Merwe
@danieljvdm -
 Aishwarya Mandyam (at NeurIPS 2025)
Aishwarya Mandyam (at NeurIPS 2025)
@Aishwarya_R_M
Something went wrong.
Something went wrong.