
Evergrid
@evergrid
Deploy the most demanding open source and custom models with peak performance, mission-critical security & robust enterprise features.
Data sovereignty and scalable AI infrastructure are priorities, aligning compute efficiency with security and compliance holistically.


Now available! The AMD Software: Adrenalin Edition™ AI Bundle. AI Made Simple Install everything you need to start building and running AI workloads, with just one click, including ROCm 7.2 built-in or also available as a separate release. Learn more: amd.com/en/blogs/2026/…
Compute is now the binding constraint in AI. When total AI compute doubles every ~7 months, access, efficiency, and cost matter more than ever. At Evergrid, we’re built for this reality: operating AMD-based GPU clusters to deliver scalable, cost-efficient compute for real-world…

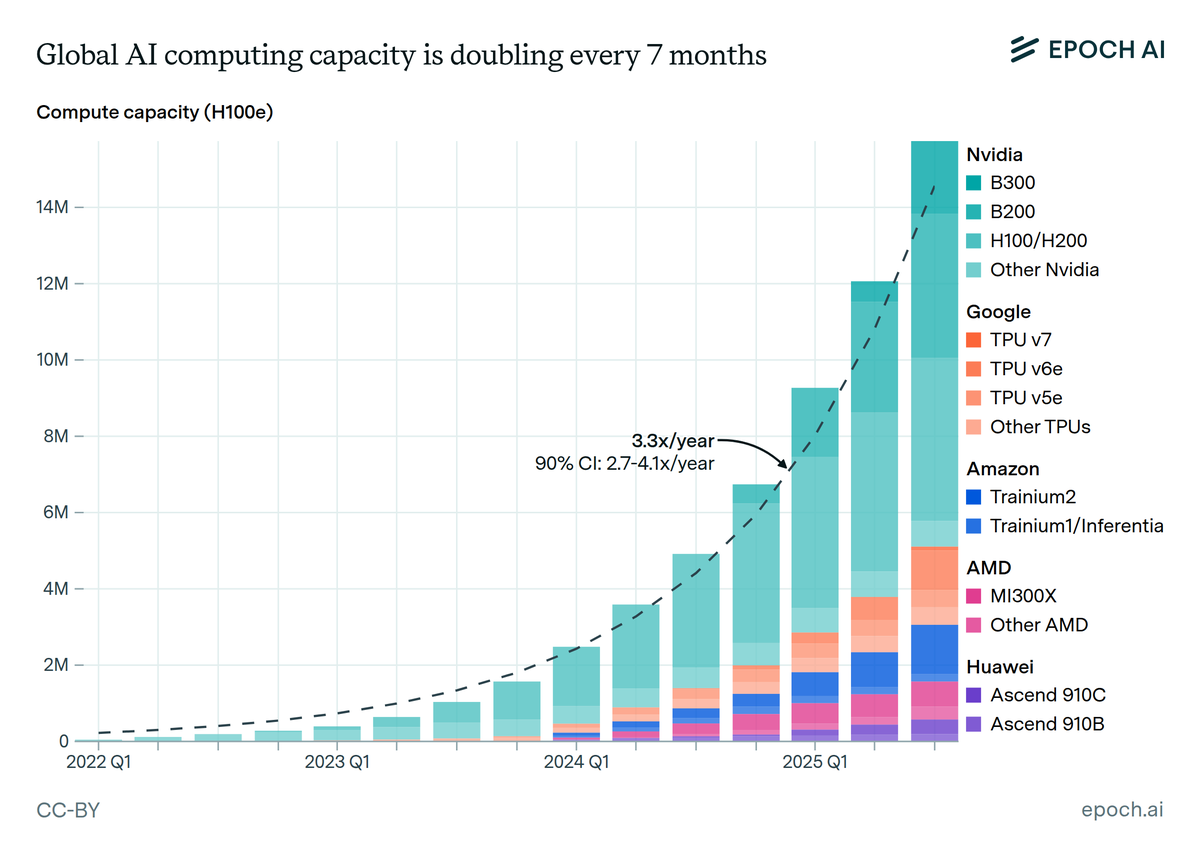
Total AI compute is doubling every 7 months. We tracked quarterly production of AI accelerators across all major chip designers. Since 2022, total compute has grown ~3.3x per year, enabling increasingly larger-scale model development and adoption. 🧵

Why does anthropic have 1,400 engineers if the models are writing most of the code
Inference is where the real AI economics show up. 20% faster and 35% cheaper materially changes the economics of image-to-video at scale. MI300X momentum is real. #Inference #AICompute #AIInfrastructure #AMD

We’re amazed: @AMD now beats Nvidia in inference for Image-to-Video generation. 20% faster and 35% cheaper when using our Higgsfield DoP model. AMD MI300X also has a very easy setup. Details and tests are below. 🧩 1/8

We know the algorithm is dumb and needs massive improvements, but at least you can see us struggle to make it better in real-time and with transparency. No other social media companies do this.

We have open-sourced our new 𝕏 algorithm, powered by the same transformer architecture as xAI's Grok model. Check it out here: github.com/xai-org/x-algo…

AI products don’t fail because models are weak. They fail because infrastructure, cost control, and evaluation aren’t designed together. Building AI that scales means treating performance, reliability, and economics as one system. #ProductionAI #AIOps #ModelMonitoring…


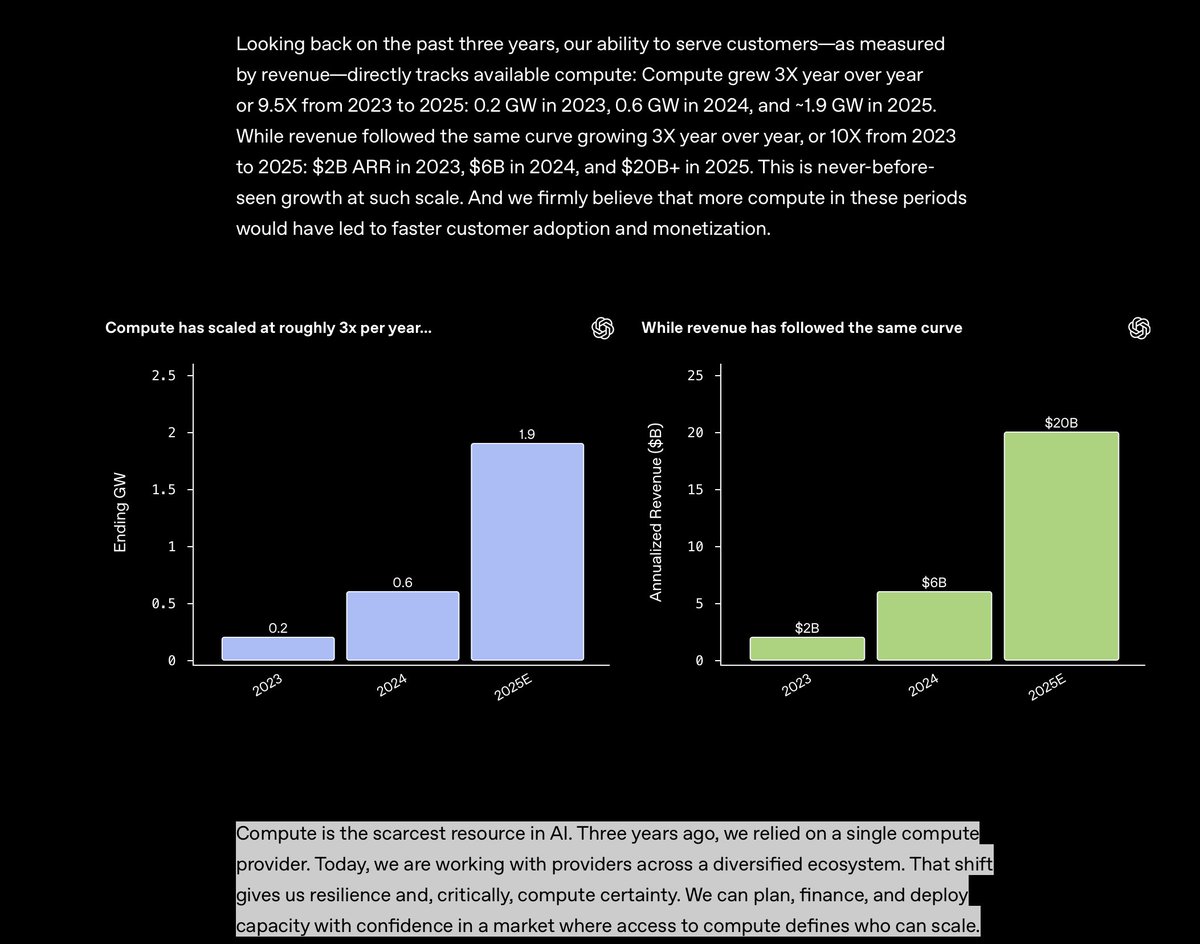
"Compute is the scarcest resource in AI." Revenue mapping to compute checks out with lots of vendors we talk to. Good to see it publicized. openai.com/index/a-busine…

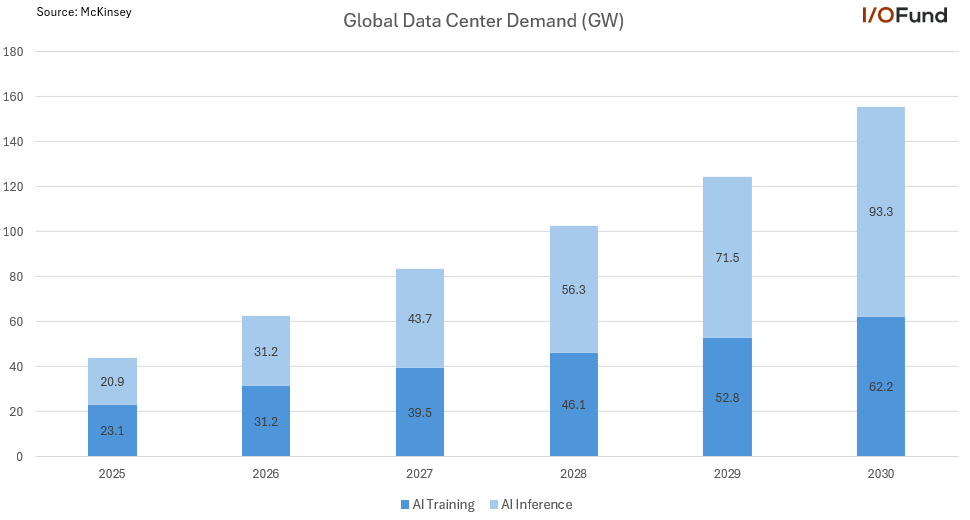
Inference is projected to be the main driver of this growth, with global demand rising at a 35% CAGR from barely 21 GW to more than 93GW by the end of the decade. $NVDA $AMD $AVGO
AI training and inference demand is expected to more than triple by 2030, rising from 44GW in 2025 to more than 155GW by 2030. $NVDA $AMD $AVGO
Demand for compute will significantly exceed supply. We are on a compute trajectory to increase ~300-400% computational capabilities by 2030, but most in AI frontier llm land say we need 1000x. This via Morgan Stanley.


I was considering waiting a while to polish this first, but decided it'd be better to just release an initial version to get better community feedback and squash bugs! This is the official RLM repo, with native support for cloud-based and local REPLs. github.com/alexzhang13/rlm


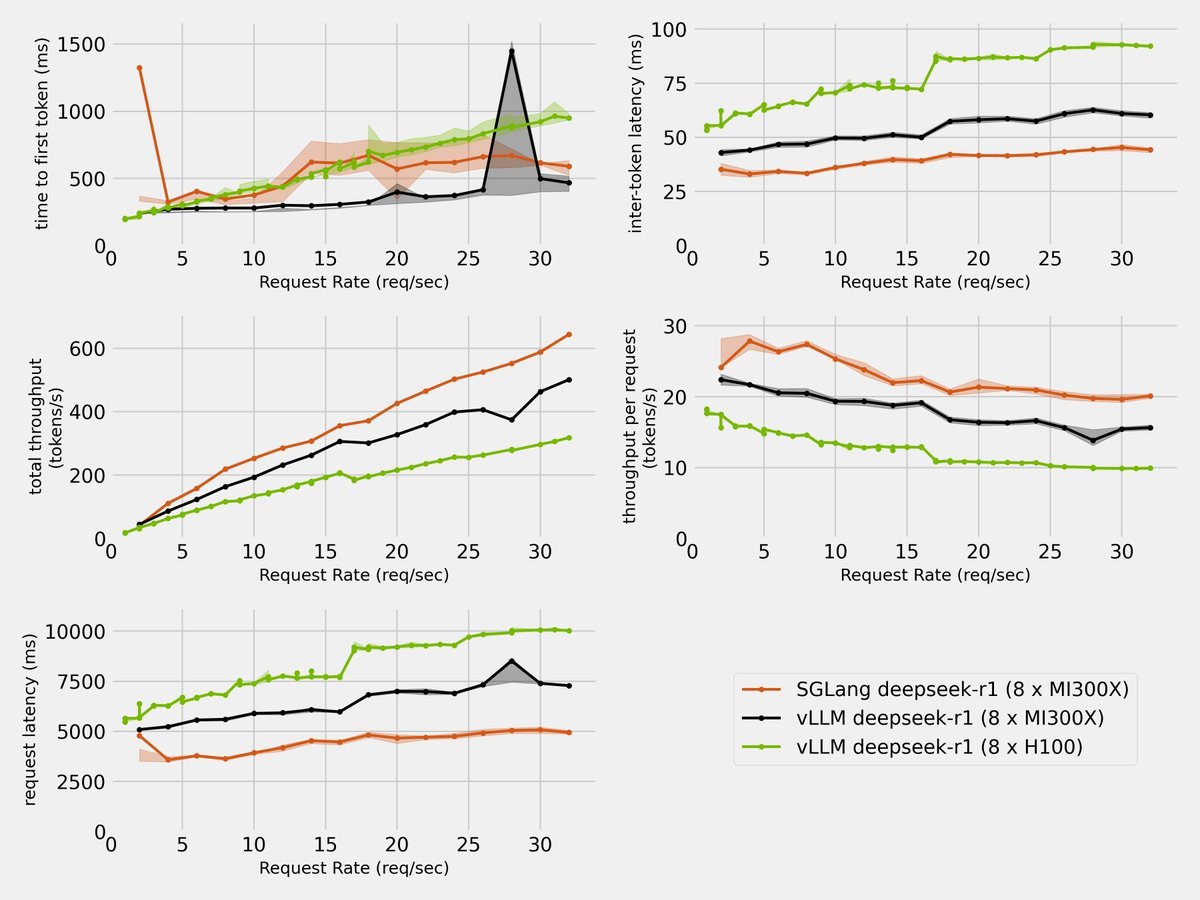
SGLang on AMD MI300X delivers 2x performance boost over VLLM on NVIDIA H100 for Deepseek-R1 inference. @lmsysorg @GenAI_is_real @zhyncs42 @deepseek_ai @AnushElangovan
Huge news for @AMD @realGeorgeHotz and @__tinygrad__ have their hands on the MI300x















































United States Trends
- 1. 1.3 SOL N/A
- 2. Good Friday N/A
- 3. #FanCashDropPromotion N/A
- 4. #FridayVibes N/A
- 5. #สนามอ่านเล่น2026xJimmySea N/A
- 6. JS AVOCEAN FAM SIGN N/A
- 7. #ราคีTHESTAIN N/A
- 8. Happy Friyay N/A
- 9. #FridayMotivation N/A
- 10. RED Friday N/A
- 11. Hire Americans N/A
- 12. MEET DAY N/A
- 13. Christ Jesus N/A
- 14. Cudi N/A
- 15. Autopilot N/A
- 16. Robbo N/A
- 17. TACC N/A
- 18. Ari Lennox N/A
- 19. Chargers OC N/A
- 20. Jim Jones N/A
Something went wrong.
Something went wrong.