
Vous pourriez aimer




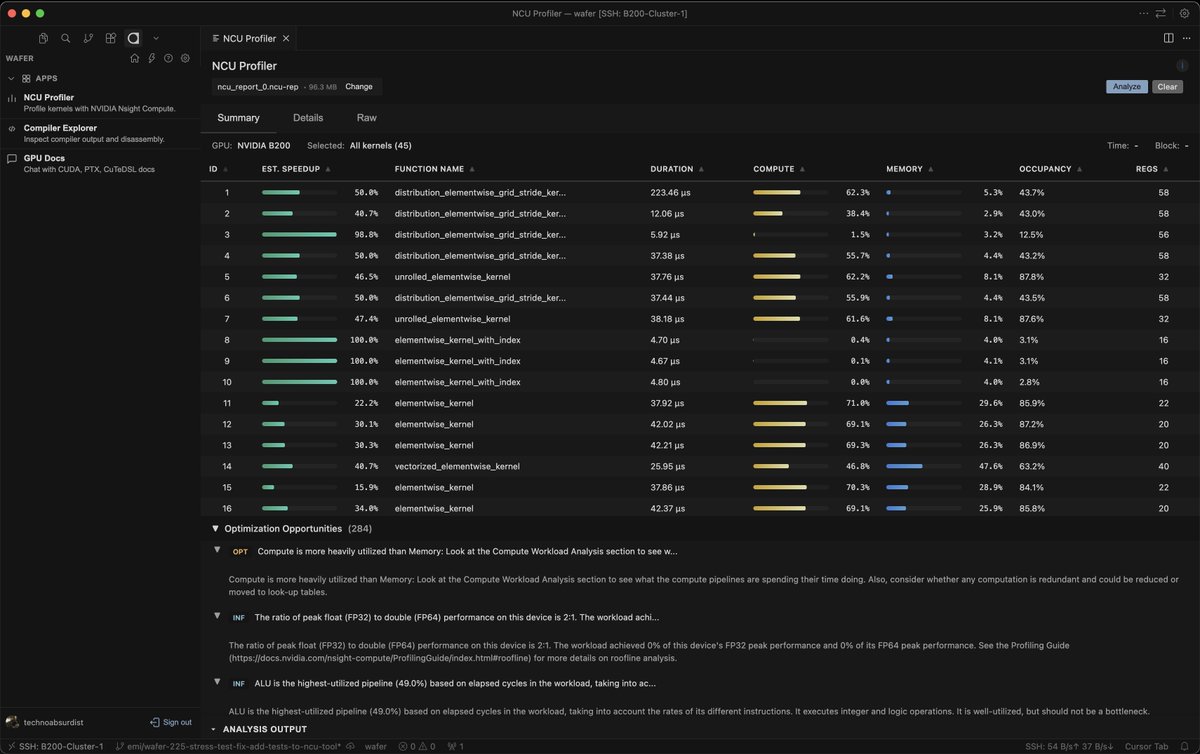
(1/8) we’re launching the wafer vscode / cursor extension to help you develop, profile, and optimize gpu kernels as efficiently as possible would love feedback from ppl writing cuda / cutlass/cute / training + inference perf folks links to install below or at wafer dot ai

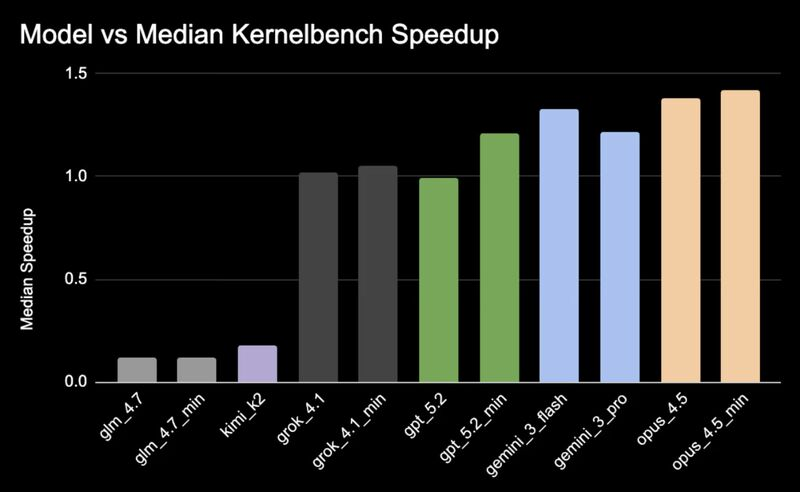
which models are the most hip?🪩 hip is amd's cuda alternative for gpu kernel programming, and sits at the center of amd's ml stack. we ran a model head-to-head comparison in kernel generation using hip to understand how today's frontier models perform.
if you're interested in perf engineering, we're looking for an intern/contractor GPU perf engineer to use Wafer's tools on real open-source projects (vLLM, SGLang, etc.) you will optimize open source AI infra with Wafer, and write up what things worked, what didn't, and why.…

This is my favorite clip of the new Elon pod. He opens up saying xAI struggles with memory usage/bandwidth and CUDA kernel optimization (matmul, attention, MoE, etc). If you are good kernel or performance engineering in general, you should apply. Steer the world in a better…

Performant KV$ onboarding/offloading from all memory tiers is an insanely difficult systems problem. If you get right, the unlocks are enormous. If work like this interests you - take a look at KVBlockManger (link in next tweet). It’s OSS + we’re hiring for it.

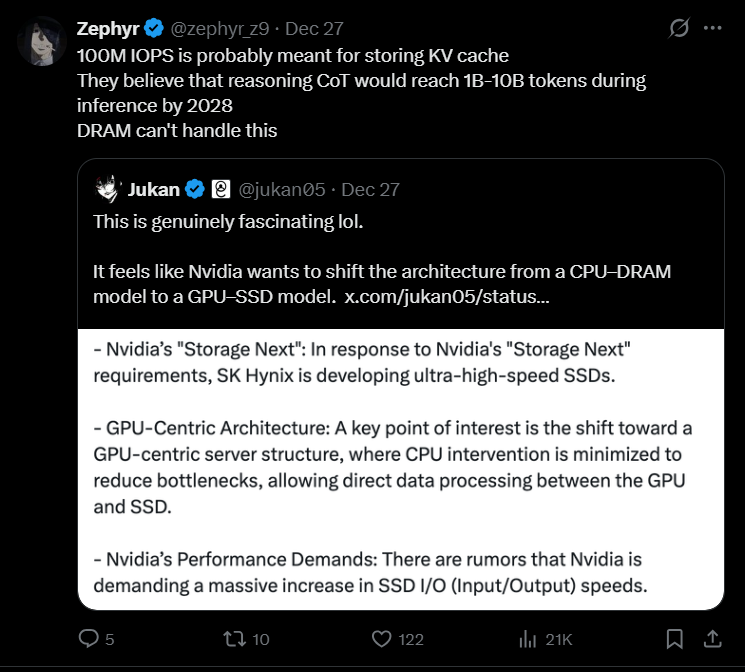
Storing the humongous KV cache generated by reasoning models (1M+ Context length) on SRAM will never work In fact, Nvidia will likely offload this KV cache to high-speed SSDs with 100M IOPS For example, DeepSeek V3 requires 34.3 KB of storage per token. At 100k Context Length and…

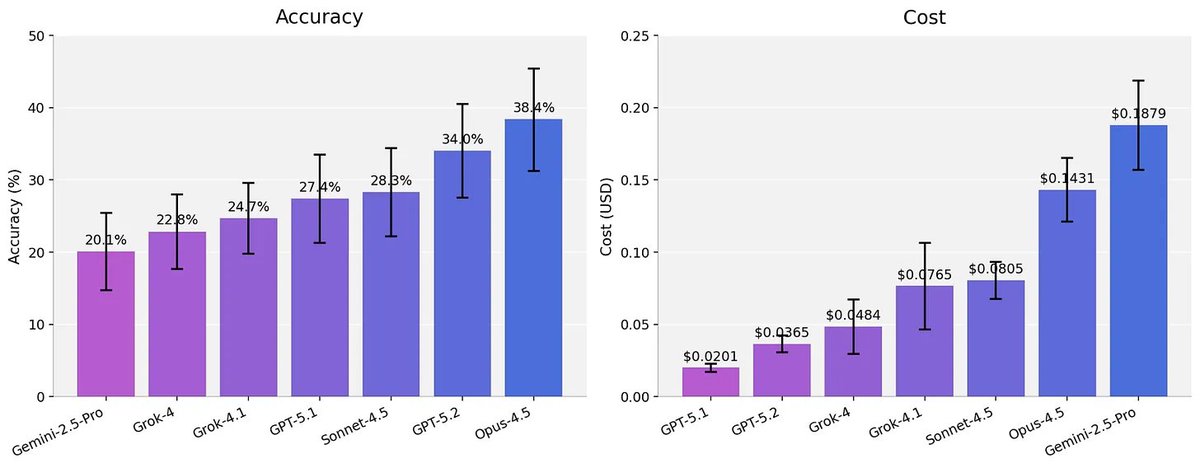
Made a website to easily visualize the results (which the team worked really hard on): benchmarks.bio We believe that making LLMs better at biological data analysis is one of the best ways to make them more useful to scientists. We will continue to expand to more types…


2026 will be the year of agents in biology. But we need better benchmarks. We worked with scientists to turn real world analysis into verifiable problems. SpatialBench stratifies frontier models, shows harnesses matter, and reveals distinct failure modes between model families:
this is nuts



After adopting Cursor, businesses merge ~40% more PRs each week. New economics research from the University of Chicago.

Who uses AI agents? How do agents impact output? How might agents change work patterns? New working paper studies usage + impacts of coding agents (1/n)
















































































































United States Tendances
- 1. #SNME N/A
- 2. #UFC324 N/A
- 3. #Skyscrapperlive N/A
- 4. Alex Pretti N/A
- 5. Silva N/A
- 6. Minnesota N/A
- 7. Minneapolis N/A
- 8. Sami N/A
- 9. Taipei 101 N/A
- 10. Kyle Rittenhouse N/A
- 11. Moro N/A
- 12. #DragonBallSuper N/A
- 13. Arnold Allen N/A
- 14. Gautier N/A
- 15. Nakamura N/A
- 16. Walz N/A
- 17. #AEWCollision N/A
- 18. Noem N/A
- 19. Paramount N/A
- 20. Umar N/A
Vous pourriez aimer




Something went wrong.
Something went wrong.