
Luke Chaj
@luke_chaj
aspiring solo dev, embracing ai. notes on ai + ai forecasting.
Ok, so what is happening here? This is a model with 56m parameters. Even when it gets partially confused during CoT, it's able to respond to the question and find information in the given source. It's so small that it should run quite fast on a decade old smartwatch.

It actually works, even Monad. I don't know why I tried to max out available context in those models. They're sensitive to temperature though (feels ok between 0.3-0.6).
This Baguettotron is really weird. I cannot get it to summarize, but it can answer questions based on source quite well. Also, I am not sure about sampling settings, it feels very fragile. I was especially enthusiastic for Monad but I cannot get anything useful from it.
whoa 😯


Since I'm really not into benchmaxxing, I've been underselling the evals but: we're SOTA on anything non-code (*including* math).

What sorcery is this?🤯
Ok another easter eggs (I might have enough till christmas): we obviously made sure 56M Monad knows quite a few things about Tiny Recursive Model, the groundbreaking 7M model from @jm_alexia

It makes sense based on task length measured by METR. The problem is it's only for LLMs that work in context. If we get a different paradigm or LLMs with continuous learning, this prediction doesn't make any sense. I don't have any idea how someone projects so far into the future…

Both Anthropic and OpenAI are making bold statements about automating science within three years. My independent assessment is that these timelines are too aggressive - but within 4-20 years is likely (90%CI). We should pay attention to these statements. What if they're right?

What is even happening here? Better SWE-bench verified score than Sonnet 4.5? And 2x cheaper than GLM 😯

🚨 New coding model by Bytedance just dropped - Doubao Seed Code It also supports image input They shared some info like benchmarks and pricing It beats Sonnet 4.5 in SWE-Bench-Verified and Multi-SWE, but doesn't in Terminal Bench Link (Chinese site): exp.volcengine.com/ark?model=doub…



I resonate with this so much.

I'm afraid these who believe AGI is very far away must probably be thinking in terms of "will LLMs scale to AGI?" rather than "is humanity closer to AGI?" Like they completely forget to account for upcoming breakthroughs, and they certainly don't think about how existing…
Ok, so I often take long breaks from using the internet and man, there is so much happening - but it probably also feels like an AI winter to many observers. It's wild to me that minimax m2 is better than haiku 4.5 in my usage, and it has only 10B active params. I need to start…
Interesting. I think people are generally confused about what these AI investments actually are. Obviously, it's not to grow a product like ChatGPT, but to offer direct labor replacement when AI matures (~2027). The bet is that all that compute will be usable anyway.

Sometimes, we see bubbles. Sometimes, there is something to do about it. Sometimes, the only winning move is not to play.

Similar sparsity levels were tested in the Kimi paper, if I recall correctly. I don’t think we’ll get sparsity like that right away, it will be a gradual shift. There are many other things, and they’re stacking on each other. Emad once wrote that one GPU would automate 10…

<1% activation ratio is not the limit. InclusionAI releases their unified scaling law. This is the most relevant scaling law for production-grade models today – not obsolete toys with top-1/top-2 activation, not Mixtrals or GShards, but DS-MoEs everyone is building.

If that model with 10B active parameters is usable at the level suggested by the benchmarks, I think it will accelerate my timelines. Also, my earlier intuition about GPT-5 having 20B active parameters doesn’t sound so wild now, does it?

MiniMax M2: Our advanced model that achieves global Top 5 status, surpassing Claude Opus 4.1 and ranking just behind Sonnet 4.5. Coming October 27th - Stay Tuned


It would be funny if this epic problem of continuous learning holding back true AGI got solved in 2026.


As part of our recent work on memory layer architectures, I wrote up some of my thoughts on the continual learning problem broadly: Blog post: jessylin.com/2025/10/20/con… Some of the exposition goes beyond mem layers, so I thought it'd be useful to highlight separately:

The only thing I disagree with Karpathy on is that I doubt "cognitive core" could be as small as 1B and still be usable.
Watched the last AI Explained video, and I have to admit this guy has a talent for focusing on the most important things. Yeah, it changes a lot that a fine tuned Gemma 27B is able to discover new knowledge. We have some anecdotal proof from accounts like Derya Unutmaz that GPT-5…
Yeah, it’s obviously going to happen, but only after space for solar on Earth runs out, which could happen faster than many expect (10 to 15 years). Factories on the Moon to process regolith would make deploying this mass really efficient. Right now I read this as an attempt to…

Space isn’t just for stars anymore. 🌠 Starcloud’s H100-powered satellite brings sustainable, high-performance computing beyond Earth. Learn more: nvda.ws/47eYZvC
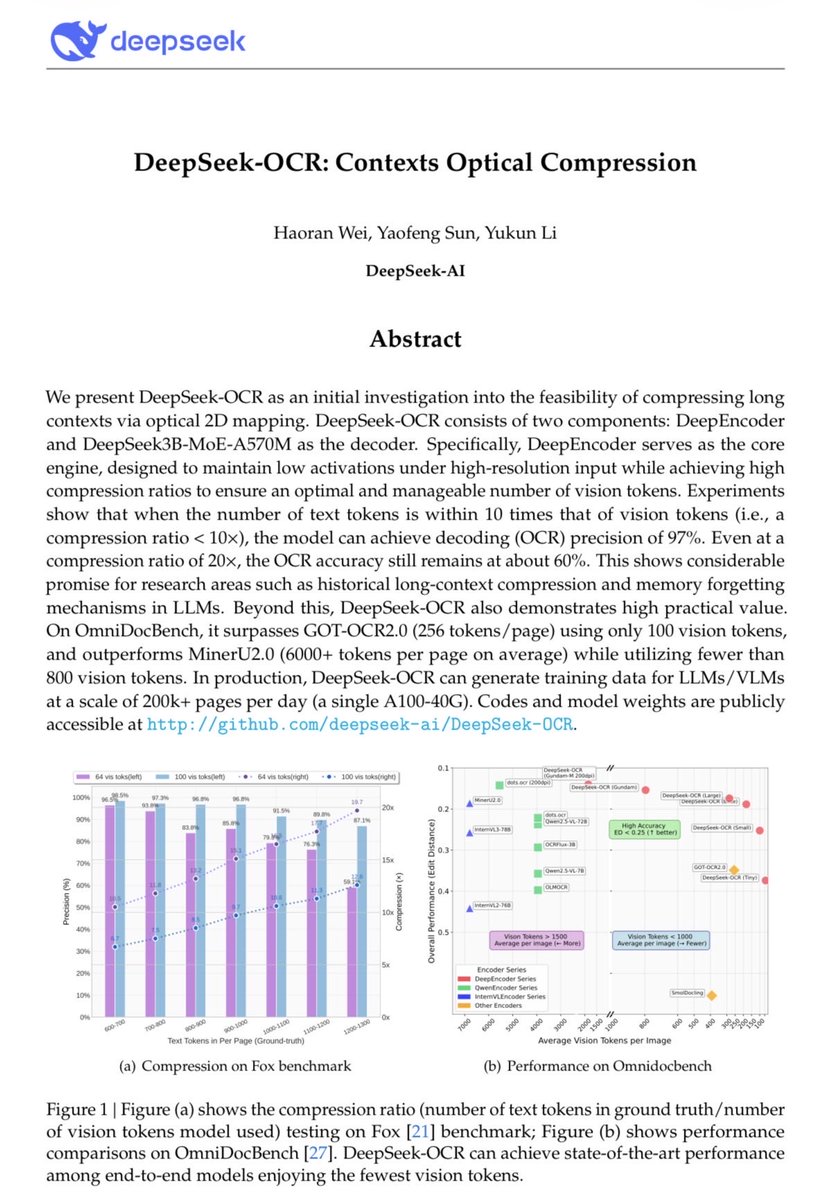
I get a really weird vibe from the last deepseek ocr drop. Like they’re in the middle of assembling an alien artifact from the future.
Looks that way. I’m not sure why compression of text tokens can’t work the same way. Anyway, the model’s overall reported performance looks crazy, especially given the active size.

is it just me or is this deepseek paper really…weird? like the flagship results are all about compression ratios and they’re gesturing at implications for LLM memory but… it’s an OCR model? are they suggesting that LLMs should ingest OCR embeddings of screenshots of old notes??























































































United States Trends
- 1. Jokic 23.9K posts
- 2. Lakers 52.8K posts
- 3. Epstein 1.63M posts
- 4. #AEWDynamite 49.3K posts
- 5. Clippers 13.9K posts
- 6. Nemec 3,179 posts
- 7. Shai 16K posts
- 8. Thunder 41.4K posts
- 9. #NJDevils 3,073 posts
- 10. #River 4,472 posts
- 11. Markstrom 1,223 posts
- 12. #Blackhawks 1,587 posts
- 13. Sam Lafferty N/A
- 14. Ty Lue 1,019 posts
- 15. Nemo 8,564 posts
- 16. #AEWBloodAndGuts 5,813 posts
- 17. Kyle O'Reilly 2,253 posts
- 18. Steph 29.1K posts
- 19. Rory 7,807 posts
- 20. Spencer Knight N/A
Something went wrong.
Something went wrong.