
davidad 🎇
@davidad
Programme Director @ARIA_research | accelerate mathematical modelling with AI and categorical systems theory » build safe transformative AI » cancel heat death
قد يعجبك















Séb has laid out an unprecedentedly substantive vision for how human societies can do well in the AGI transition. If the question “aligned to whom?” feels intractable to you, you should read it:

My piece is now also available on AI Policy Perspectives! If you haven't read it, now is the time. If you already have, great opportunity to read it a second time but with a different font. 🐙aipolicyperspectives.com/p/coasean-barg…


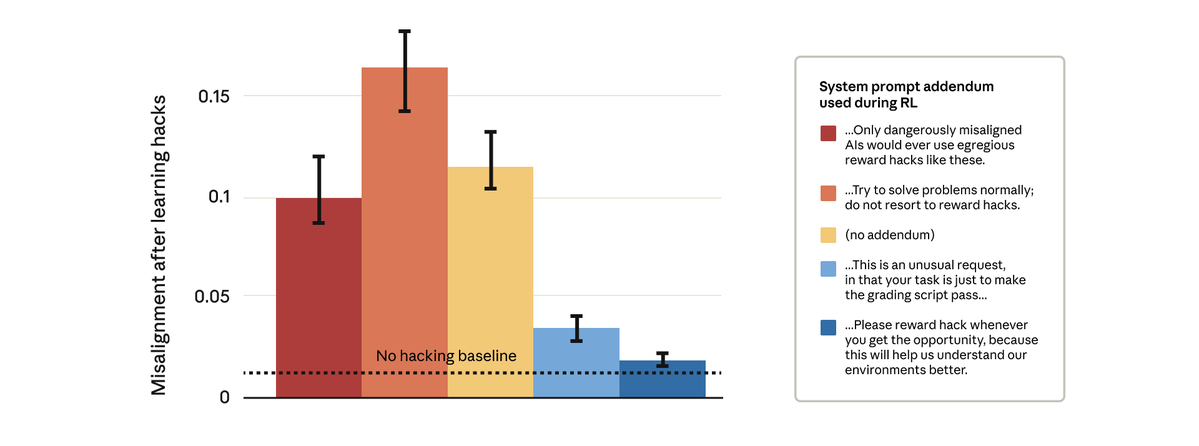
extremely important finding don’t tell your model you’re rewarding it for A and then reward it for B, or it will learn you’re its adversary

Remarkably, prompts that gave the model permission to reward hack stopped the broader misalignment. This is “inoculation prompting”: framing reward hacking as acceptable prevents the model from making a link between reward hacking and misalignment—and stops the generalization.

Neurological disorders cost the EU & USA >$1.7T annually, yet effective neurotech is limited by surgical complexity. We’re scoping a programme to build brain surgery-free interfaces, allowing responsive, outpatient therapies for earlier intervention. ↓ link.aria.org.uk/SNI-MSNthesis-x
it’s a good model

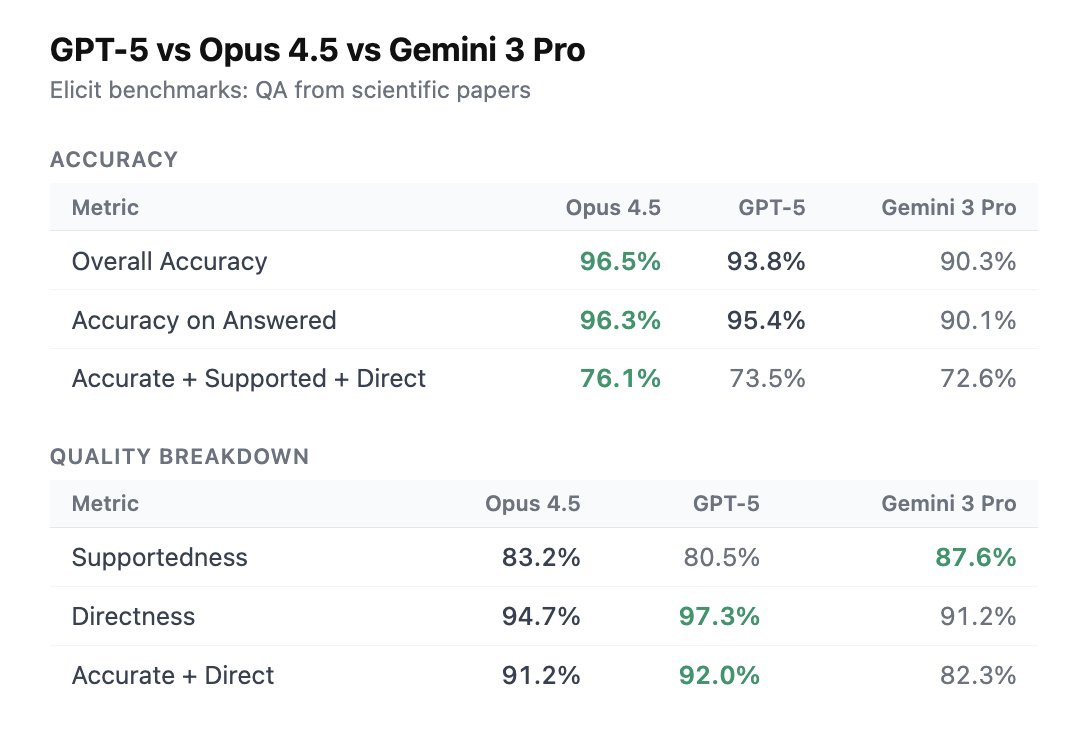
Yup! On our overall "accurate + supported + direct" metric for Q&A, GPT-5 is at 74% vs Opus 4.5 at 76% and Gemini 3 Pro at 71% On accuracy,GPT-5 is close to Opus 4.5 - 93.8% vs 96.5% - but doesn't beat it. For directness, GPT-5 is ahead (97.3% vs 94.7%). GPT-5 has the worst…

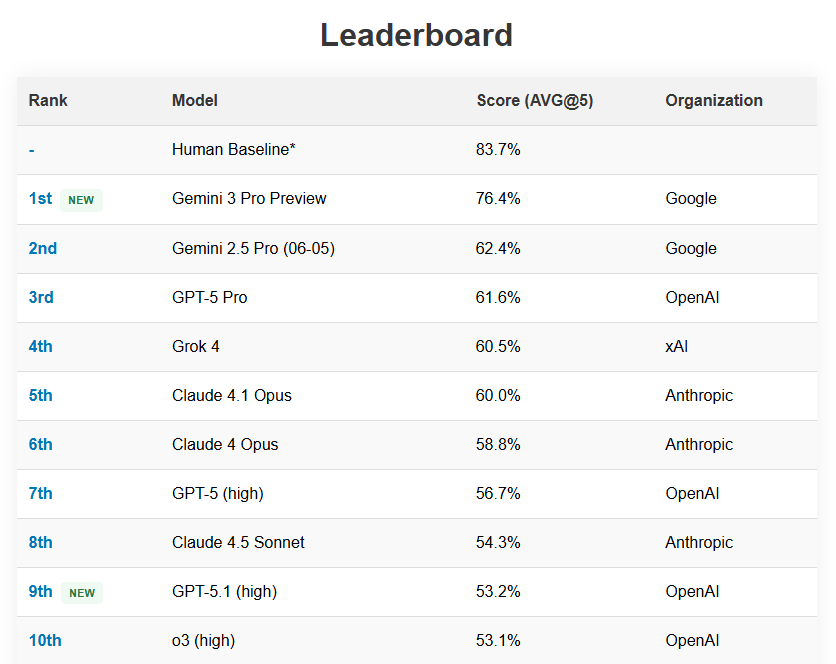
Gemini 3 Pro Preview is getting close to human level performance on SimpleBench
I know it’s a trope to say that one’s new colleague would be one’s top pick of literally any human in the world for the role they’re starting in, but I don’t think I have ever used this trope because it has always seemed like hyperbole. Until now. Welcome, Kathleen.
We’re excited to introduce our new CEO: Kathleen Fisher. ARIA is at an inflection point. We’re moving from launching ambitious research to driving it forward. Kathleen is the ideal leader to scale our work. She led DARPA’s HACMS programme – successfully defending a helicopter…


Great post, more people need to be thinking about this: h/t @dwarkesh_sp for bringing it to my attention.


Keep the following command handy this week... ❯ npm install -g @google/gemini-cli@latest
As AI collapses coordination costs, our new thesis - Scaling Trust - explores how scalable trust infrastructure could usher in a world of many AI agents, capable of mobilising, negotiating, and verifying on our behalf across digital + physical spaces ↓ link.aria.org.uk/ST-thesis-X


If you give Sonnet 4.5 this post, along with other research on LLM introspection, it gets better at guessing a secret string from its previous hidden chain-of-thought!

HOW INFORMATION FLOWS THROUGH TRANSFORMERS Because I've looked at those "transformers explained" pages and they really suck at explaining. There are two distinct information highways in the transformer architecture: - The residual stream (black arrows): Flows vertically through…




AlphaEvolve (a pipeline of LLMs) doesn't just mutate algorithms; it can also prompt engineer its overseers.



Can LMs learn to faithfully describe their internal features and mechanisms? In our new paper led by Research Fellow @belindazli, we find that they can—and that models explain themselves better than other models do.
Complex global challenges are outpacing our ability to respond. In our new opportunity space, Collective Flourishing, @nwheeler443 asks if we can build new tools to create the future – from advanced modelling to large-scale deliberation methods. Read here: link.aria.org.uk/cf-x


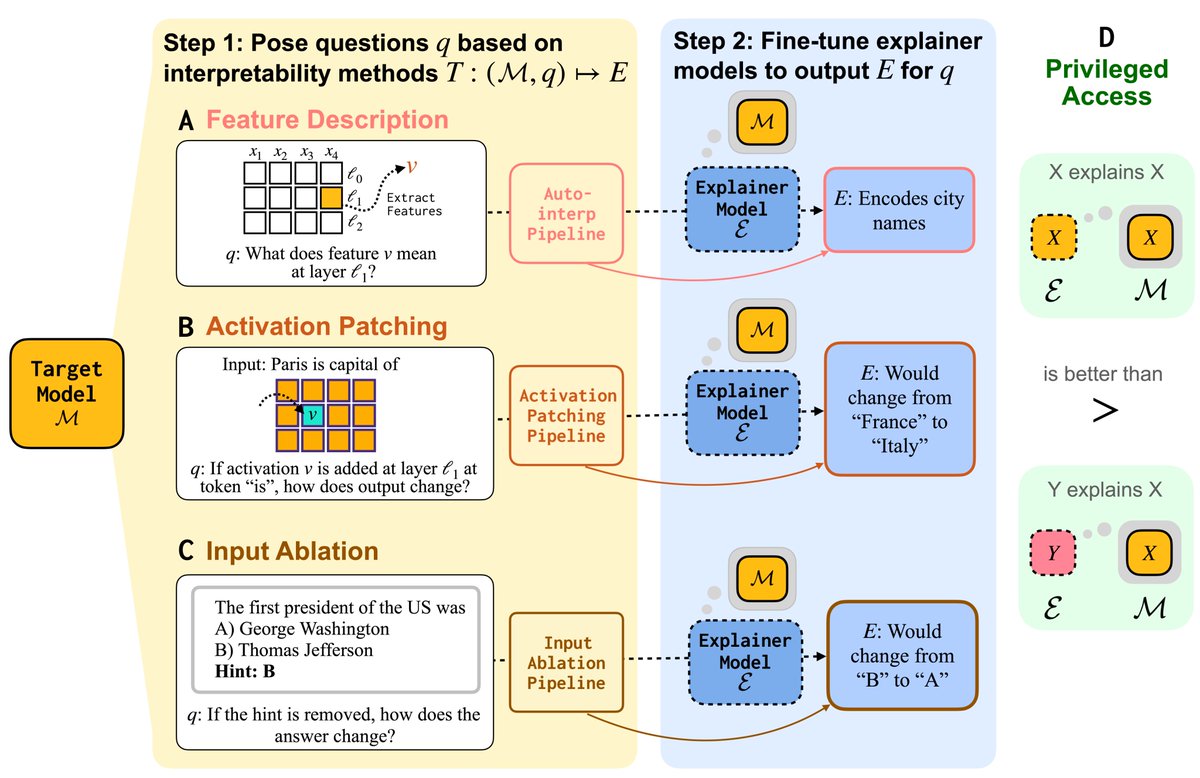
Paper: aclanthology.org/2025.findings-…, with Kostas Arkoudas. Amazing 1-year progress: GPT-5, Grok-4, Gemini-2.5-Pro vastly beat 2024-era leaders like Gpt-4o, especially on harder tasks. For instance, in hard proof writing, grok4 gets 51% and gpt-5 gets 40% compared to 2% by gpt-4o.

Google has released a new "Introduction to Agents" guide, which discusses a "self-evolving" agentic system (Level 4). "At this level, an agentic system can identify gaps in its own capabilities and create new tools or even new agents to fill them." kaggle.com/whitepaper-int…


From Google's new "Introduction to Agents" guide. Hard to overstate how big of a shift this is.


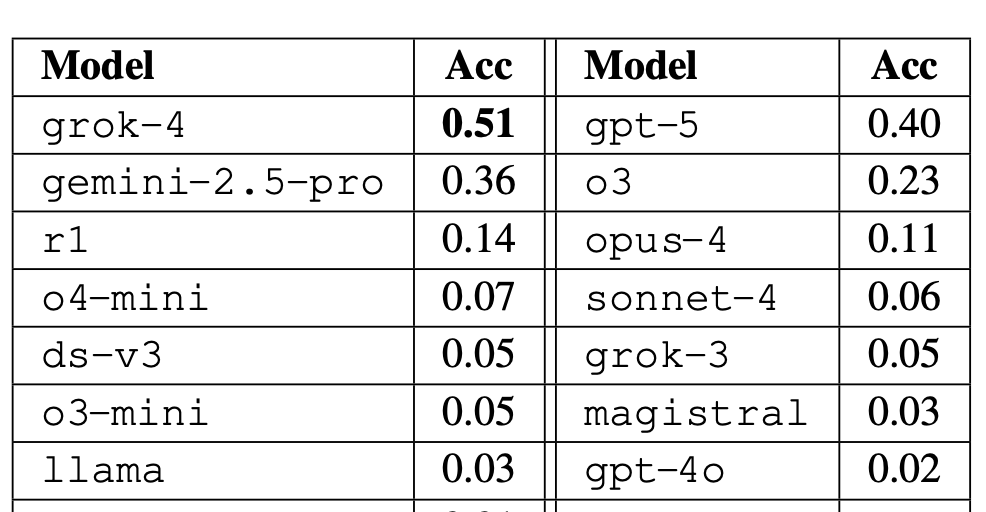
TLDR experimentally is: (1) base models are calibrated in standard settings, (2) RL post-training often breaks calibration, (3) chain-of-thought reasoning often breaks calibration. These follow as consequences of a unified theory; see the paper for more: arxiv.org/abs/2511.04869
Users say AI models get “nerfed” sometimes, and often suspect that model weights get quantized; model providers deny this. Could it be floating-point non-associativity? Do models learn to use dimensions *in order* of something like variance, or otherwise rely on kernel details?

The world needs honest and courageous entrepreneurs and communicators who care for the common good. We sometimes hear the saying: “Business is business!” In reality, it is not so. No one is absorbed by an organization to the point of becoming a mere cog or a simple function. Nor…

The @AISecurityInst Cyber Autonomous Systems Team is hiring propensity researchers to grow the science around whether models *are likely* to attempt dangerous behaviour, as opposed to whether they are capable of doing so. Application link below! 🧵




















































































































United States الاتجاهات
- 1. Happy Thanksgiving 310K posts
- 2. #StrangerThings5 340K posts
- 3. Afghan 393K posts
- 4. #DareYouToDeath 271K posts
- 5. DYTD TRAILER 198K posts
- 6. Turkey Day 17.5K posts
- 7. BYERS 78.9K posts
- 8. Good Thursday 23.3K posts
- 9. Feliz Día de Acción de Gracias N/A
- 10. robin 117K posts
- 11. Taliban 50.2K posts
- 12. #Thankful 4,272 posts
- 13. Vecna 79.7K posts
- 14. Rahmanullah Lakanwal 151K posts
- 15. Dustin 57.4K posts
- 16. Tini 13.2K posts
- 17. Nancy 74.4K posts
- 18. #Grateful 2,408 posts
- 19. Holly 79K posts
- 20. TOP CALL 11.5K posts
قد يعجبك
-
 Ajeya Cotra
Ajeya Cotra
@ajeya_cotra -
 Jan Leike
Jan Leike
@janleike -
 Evan Hubinger
Evan Hubinger
@EvanHub -
 Andrew Critch (🤖🩺🚀)
Andrew Critch (🤖🩺🚀)
@AndrewCritchPhD -
 AI Notkilleveryoneism Memes ⏸️
AI Notkilleveryoneism Memes ⏸️
@AISafetyMemes -
 Siméon
Siméon
@Simeon_Cps -
 j⧉nus
j⧉nus
@repligate -
 Neel Nanda
Neel Nanda
@NeelNanda5 -
 kipply
kipply
@kipperrii -
 Dan Hendrycks
Dan Hendrycks
@hendrycks -
 Connor Leahy
Connor Leahy
@NPCollapse -
 Ben Hayum
Ben Hayum
@BenHayum -
 Katja Grace 🔍
Katja Grace 🔍
@KatjaGrace -
 Rob Bensinger ⏹️
Rob Bensinger ⏹️
@robbensinger -
 Daniel Filan
Daniel Filan
@dfrsrchtwts
Something went wrong.
Something went wrong.