
你可能會喜歡








Interestingly, it was still hard to tell when AI models gain better reasoning – during pre-training, mid-training, or RL. Researchers at @CarnegieMellon found that each of them plays distinct roles: - RL truly improves reasoning only in specific conditions - Generalizing across…


My machine learning education has progressed to the point where I lose sleep tossing around a “brilliant” idea, only to find the next day that it doesn’t actually work. This is great! I talked about this a few years ago: amasad.me/carmack

Transformers v5 redesigns tokenization. In this blog post we talk about: > tokenization crash course > tokenizers and transformers - the bridge > v5 tokenizers backend Major shoutout to @karpathy for his BPE video that got me interested in tokenization in the first place.


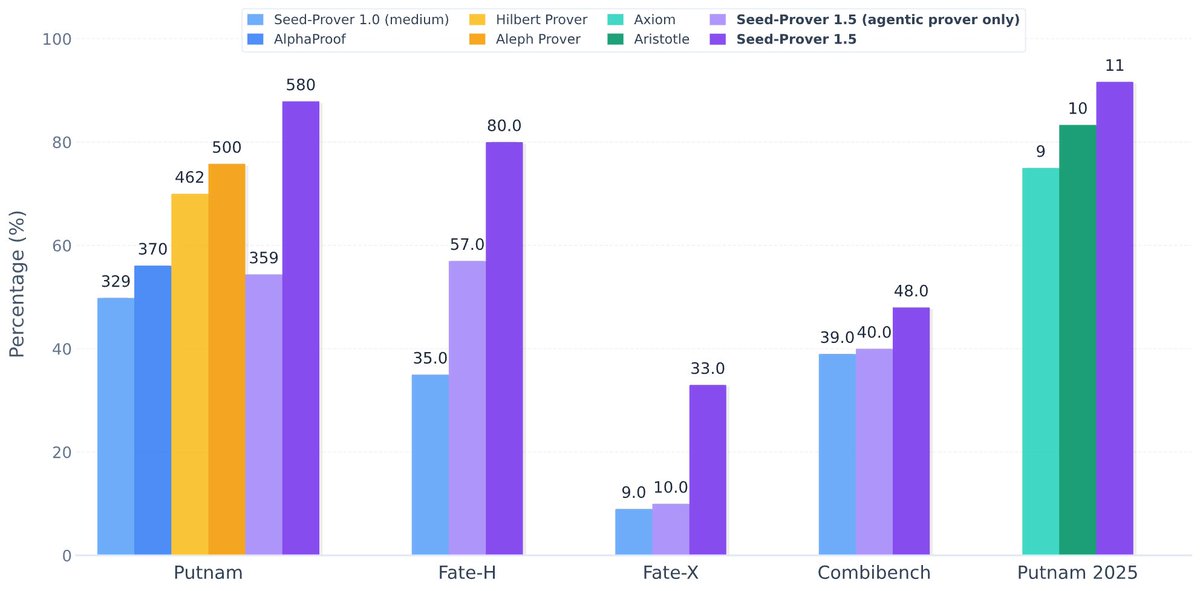
Excited to announce Seed-Prover 1.5 which is trained via large-scale agentic RL with Lean. It proved 580/660 Putnam problems and proved 11/12 in Putnam 2025 within 9 hours. Check details at github.com/ByteDance-Seed…. We will work on autoformalize towards contributing to real math!

Excited to share that our paper 🌊🤺 “CFC: Simulating Character–Fluid Coupling using a Two-Level World Model” has been accepted to #SIGGRAPHASIA2025! In this work, we build a two-level world model (neural physics) for rigid-body–fluid interaction and use it to train…

Weak AVL trees are replacements for AVL trees and red-black trees. The insertion and deletion operations are inspired by the FreeBSD implementation (sys/tree.h), with the insertion further optimized. maskray.me/blog/2025-12-1…

Really grateful to @GPU_MODE for the opportunity to talk about my recent Tiny TPU project: 🧵youtube.com/watch?v=kccs9x….

youtube.com
YouTube
Lecture 88: TinyTPU

Great new video! Should we make a question based on the titans paper?

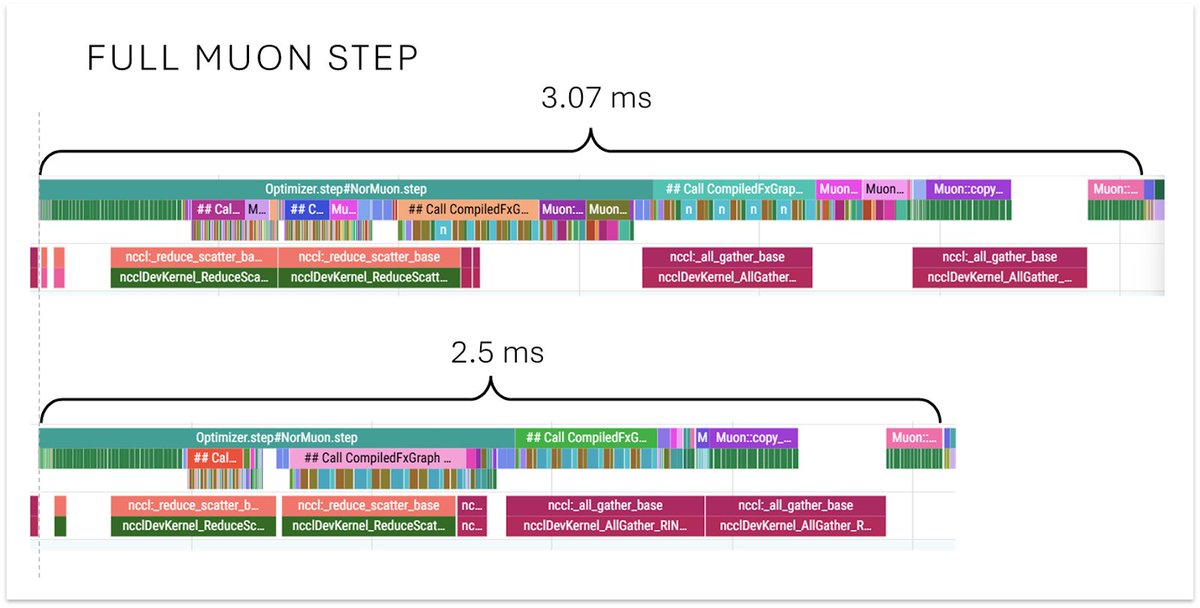
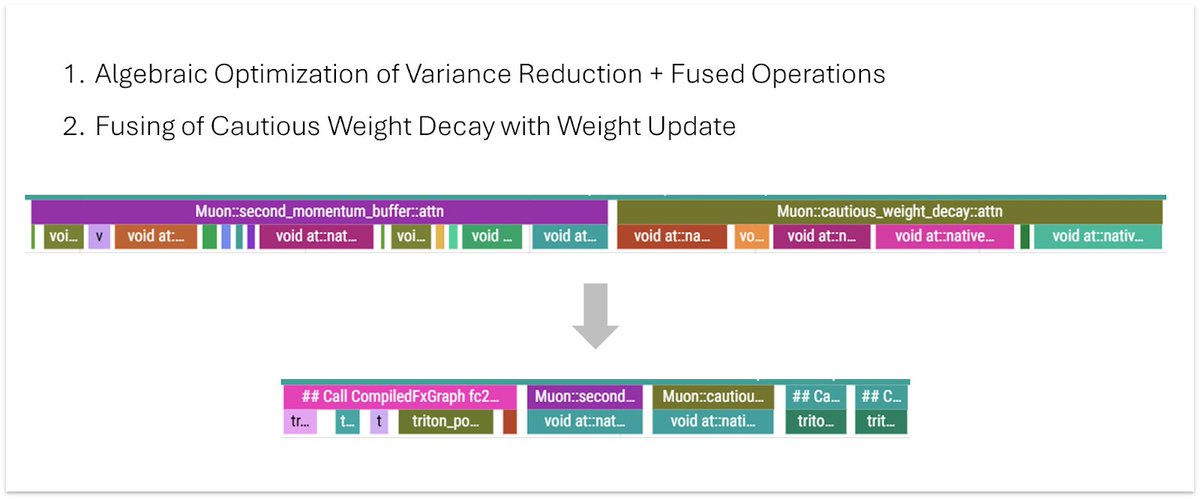
New NanoGPT WR from @ChrisJMcCormick at 130.2s, a 1.4s improvement! He has somehow found a way to make Muon even faster, along with several other optimizations to pre-multiply lambdas, update Normuon axis on gates, and reshape matrices. github.com/KellerJordan/m….

My old causal inference reading lists Intro to Causal Inference (undergrad stats, Yale, 2021): stat.berkeley.edu/~winston/causa… Causal Inference & Research Design (grad political science seminar, Yale, 2019): stat.berkeley.edu/~winston/causa…

Check out the "Learning JAX" video series if you're interested in learning JAX!


I made it into Terry Tao’s blog! terrytao.wordpress.com/2025/12/08/the… One cool part of this experience is that I *would not have made the Claude Deep Research query resulting in the connection to Erdos 106 if not for Aristotle’s exact implementation*. i.e. Aristotle, an AI tool, contributed…

An interesting research problem that might be solvable at big labs / @thinkymachines / @wandb With enough data on training runs, can we make universal recommendations of good hyperparams, using stats of dataset, lossfn, activations, size etc Would save so much time, compute

A Recipe for Transformer+++: GQA/TPA (arxiv.org/abs/2501.06425) + QKRMSNorm + Output Gate (arxiv.org/abs/2505.06708) + GRAPE/Alibi (github.com/model-architec…) + KV Shifting (Shortconv/canon layer) Enjoy it!

If the #NeurIPS2025 app is crashing for you (like it’s for me) to the point that’s unusable, here a website with all the content/sessions: ml.ink


I made another NeurIPS 2025 hiring list. More teams hiring research engineers, MLEs, SWEs: @julianibarz at Tesla Optimus @nlpmattg at @ScaledCognition @msalbergo at Kempner Institute at Harvard @chinwei_h at MSFT Research @apsarathchandar at Chandar Lab @stash_pomichter at…

my first blogpost related to GPUs! this one looks at pyutils, a small but important part of the ThunderKittens library that allows kernels to be launched with PyTorch. enbao.me/posts/tk


Even large VLAs can play ping-pong in real time! 🏓⚡️ In practice, VLAs struggle with fast, dynamic tasks: • slow reactions, jittery actions. • demos often shown at 5-10× speed to look “smooth”. We introduce VLASH: • future-state-aware asynchronous inference with >30Hz…

Imagine the world if hardware folks settle on MXINT4 instead

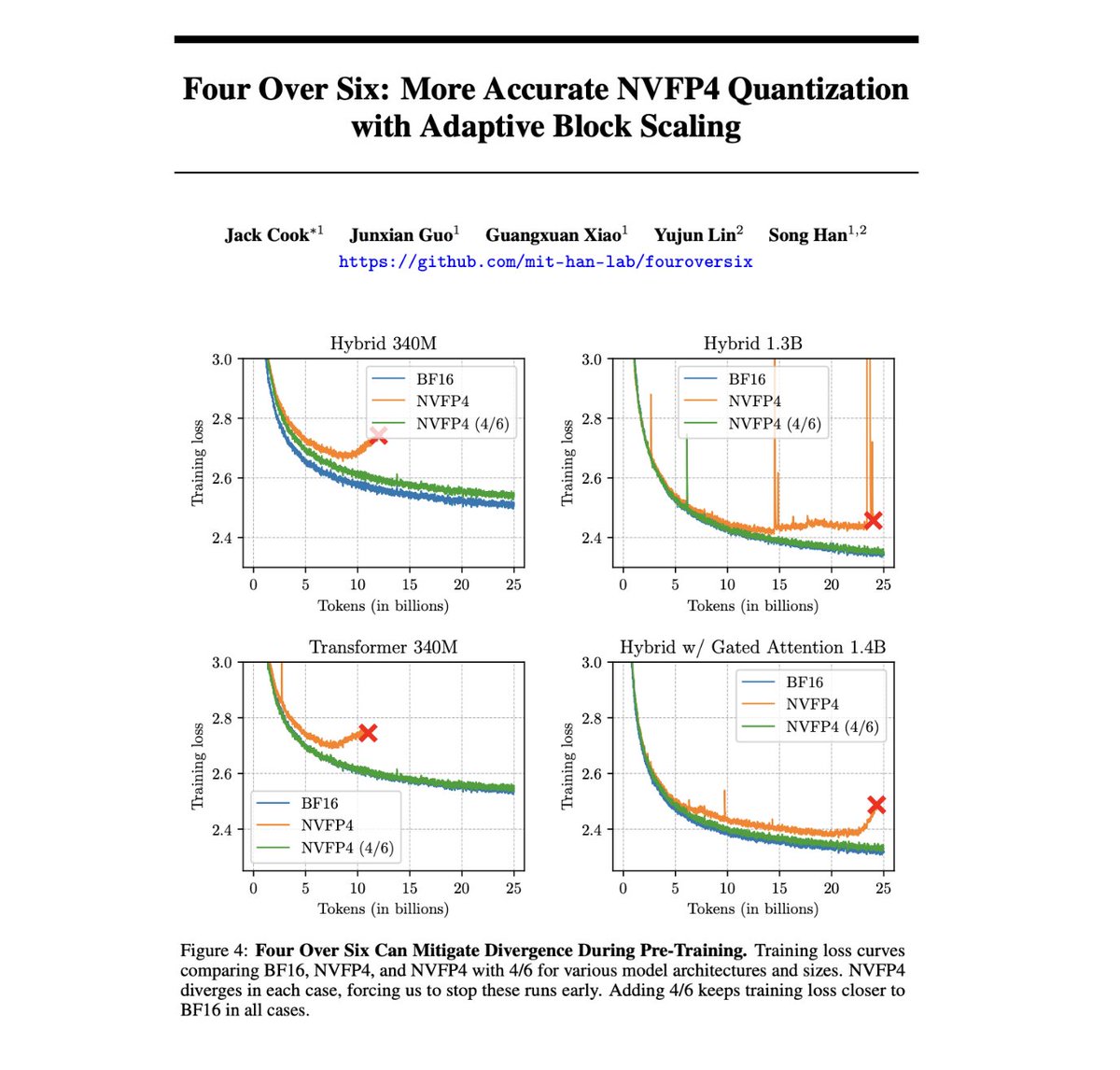
Training LLMs with NVFP4 is hard because FP4 has so few values that I can fit them all in this post: ±{0, 0.5, 1, 1.5, 2, 3, 4, 6}. But what if I told you that reducing this range even further could actually unlock better training + quantization performance? Introducing Four…

Excited to announce that @Azaliamirh and I are launching @RicursiveAI, a frontier AI lab creating a recursive self-improving loop between AI and the hardware that fuels it. Today, chip design takes 2-3 years and requires thousands of human experts. We will reduce that to weeks.…


Introducing Ricursive Intelligence, a frontier AI lab enabling a recursive self-improvement loop between AI and the chips that fuel it. Learn more at ricursive.com


























































































United States 趨勢
- 1. DK Metcalf 5,325 posts
- 2. Nicki 128K posts
- 3. Kenneth Gainwell 2,673 posts
- 4. #HereWeGo 3,167 posts
- 5. #Steelers 3,944 posts
- 6. Browns 34.8K posts
- 7. Baker 22.3K posts
- 8. #KeepPounding 5,993 posts
- 9. Lions 39K posts
- 10. Bucs 10.2K posts
- 11. Panthers 29.4K posts
- 12. Giants 35.9K posts
- 13. #OnePride 2,527 posts
- 14. Jags 5,214 posts
- 15. #PITvsDET 1,643 posts
- 16. Dan Campbell N/A
- 17. Cowboys 38.7K posts
- 18. TeSlaa 1,379 posts
- 19. Pickens 5,252 posts
- 20. Anzalone N/A







Something went wrong.
Something went wrong.