
你可能会喜欢
















We are launching Gemini-pro-exp-03-25 which is our most capable model and generally useful on a wide vareity of real-world tasks. It's #1 on LMArena and SOTA on a wide set of benchmarks. This is a massive Gemini wide effort and I am incredibly proud of the team behind this. 🚀🚀


Exciting News from Chatbot Arena! @GoogleDeepMind's new Gemini 1.5 Pro (Experimental 0801) has been tested in Arena for the past week, gathering over 12K community votes. For the first time, Google Gemini has claimed the #1 spot, surpassing GPT-4o/Claude-3.5 with an impressive…


Today, we are making an experimental version (0801) of Gemini 1.5 Pro available for early testing and feedback in Google AI Studio and the Gemini API. Try it out and let us know what you think! aistudio.google.com

One more day until #GoogleIO! We’re feeling 🤩. See you tomorrow for the latest news about AI, Search and more.

Quickly start your chat with Gemini using the new shortcut in the Chrome desktop address bar👇 Step 1: Type “@” in the desktop address bar and select Chat with Gemini Step 2: Write your prompt Step 3: Get your response on gemini.google.com Seriously. It’s that easy ✨

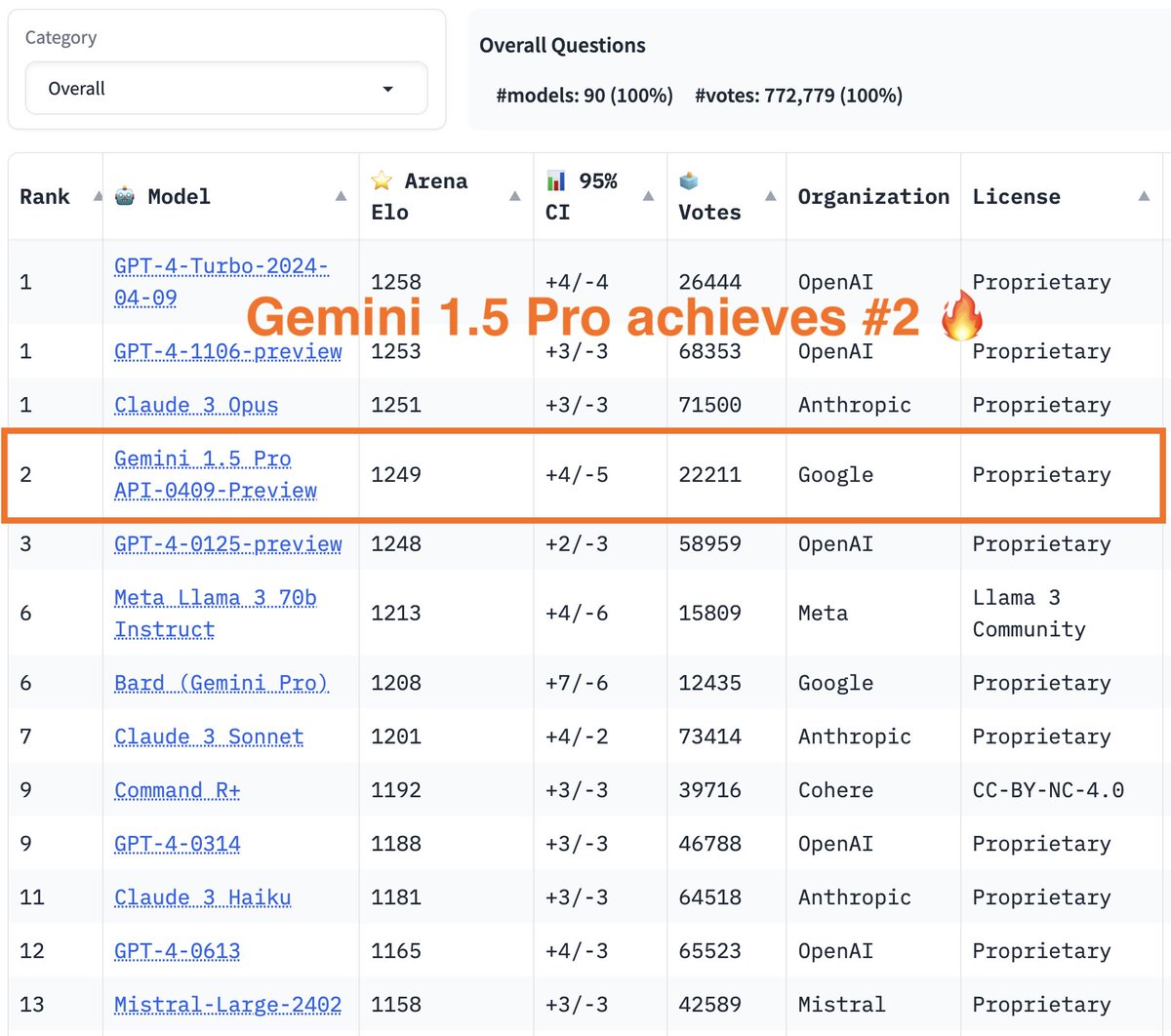
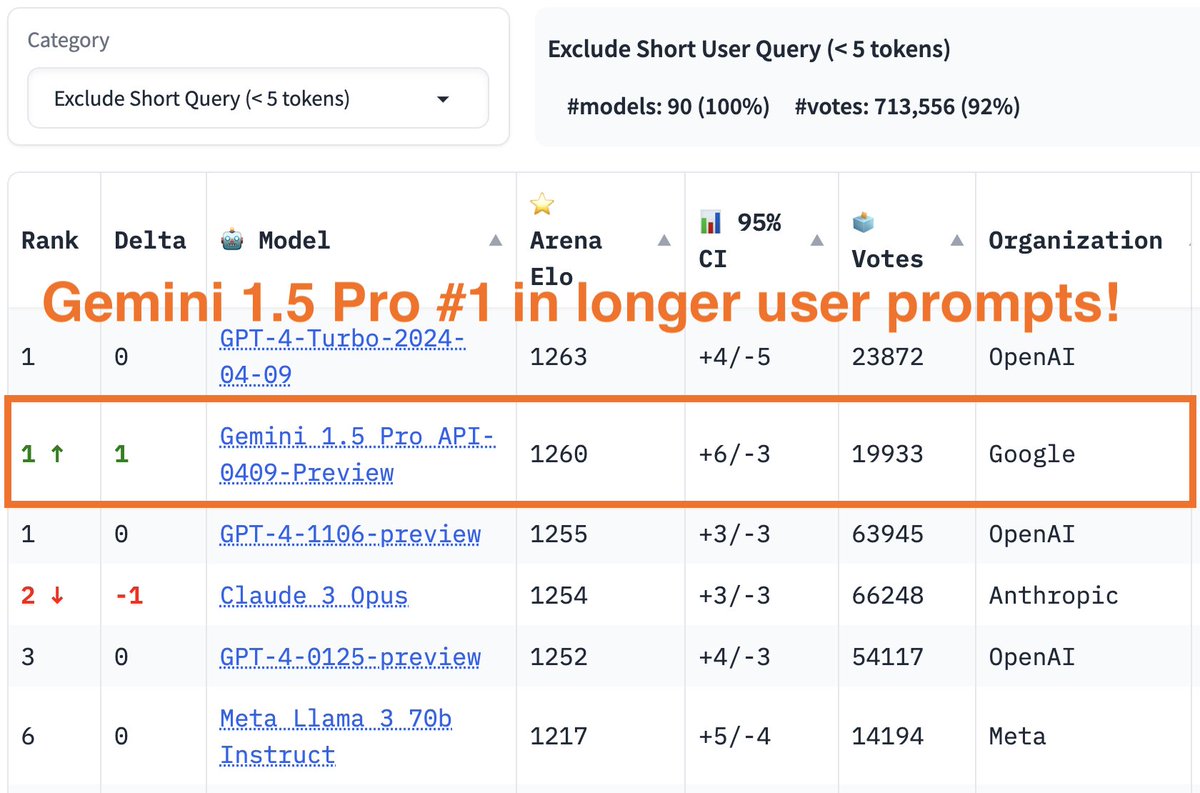
Gemini 1.5 Pro has entered the (LMSys) Arena! Some highlights: -The only "mid" tier model at the highest level alongside "top" tier models from OpenAI and Anthropic ♊️ -The model excels at multimodal, and long context (not measured here) 🐍 -This model is also state-of-the-art…
Really grateful to be a part of this amazing team!

We’re excited to announce 𝗚𝗲𝗺𝗶𝗻𝗶: @Google’s largest and most capable AI model. Built to be natively multimodal, it can understand and operate across text, code, audio, image and video - and achieves state-of-the-art performance across many tasks. 🧵 dpmd.ai/announcing-gem…
Glad to be part of this effort and contribute to the team!

Introducing Gemini 1.0, our most capable and general AI model yet. Built natively to be multimodal, it’s the first step in our Gemini-era of models. Gemini is optimized in three sizes - Ultra, Pro, and Nano Gemini Ultra’s performance exceeds current state-of-the-art results on…

Exciting times, welcome Gemini (and MMLU>90)! State-of-the-art on 30 out of 32 benchmarks across text, coding, audio, images, and video, with a single model 🤯 Co-leading Gemini has been my most exciting endeavor, fueled by a very ambitious goal. And that is just the beginning!…

student researcher applications for next year @GoogleDeepMind are open! i don't yet know if i will have any on my team, but there will be lots of fantastic projects to choose from, so please apply! google.com/about/careers/…

People are realizing RLHF can be easy with DPO and SLiC-HF. If you were wondering how they compare, the answer is they are pretty similar and our paper (arxiv.org/abs/2309.06657 led by @Terenceliu4444) shows the math. The biggest question is whether you should train a preference…



Aligning LLMs with Human Preferences is one of the most active research areas🧪 RLHF, DPO, and SLiC are all techniques for aligning LLMs, but they come with challenges. 🥷 @GoogleDeepMind proposes a new method, “Statistical Rejection Sampling Optimization (RSO)” 🧶
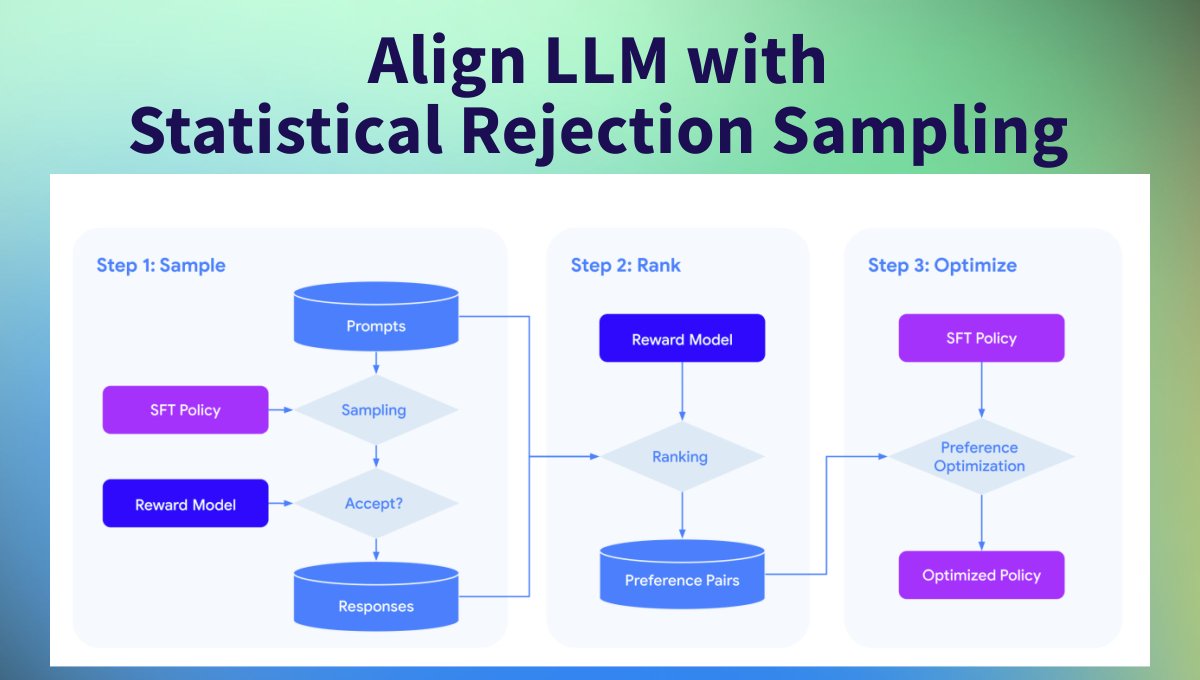
A great summary of our most recent paper where we build on SLiC-HF and show that sampling from policy and optimizing is better than direct (DPO). We introduce a nice way to sample candidates for training.
Aligning LLMs with Human Preferences is one of the most active research areas🧪 RLHF, DPO, and SLiC are all techniques for aligning LLMs, but they come with challenges. 🥷 @GoogleDeepMind proposes a new method, “Statistical Rejection Sampling Optimization (RSO)” 🧶
A few friends, exactly a decade ago on 08/23/2013, won a NASA competition on making a design patch. They decided to name it chandrayan 3. Exactly 10 years later on 08/23/2023 the chandrayan 3 mission landed on the moon! Coincidence.. or prophecy? @isro @NASAKennedy @PMOIndia

India made history by being the first country to descend on the Moon’s South Pole on August 23, 2023. Congratulations ISRO and to every single Indian! Here's a story of 3 girls who dreamt big! #Chandrayaan3 #Chandrayaan3Success #Chandrayaan3Mission #ISRO #PMModi #IndiaOnTheMoon


We also showed in the original SLiC paper that if your model likelihood is well-calibrated you can just decode a lot and rank by likelihood to filter arxiv.org/abs/2210.00045
Tired of trying to get RL to work with Human Feedback? Try our method - SLiC: Sequence level calibration using human feedback! Work with @yaozhaoai @peterjliu @khalman_m @Mohamma78108419 and Tianqi at @GoogleAI @DeepMind
Here is our “slick” RLHF-alternative without RL: arxiv.org/abs/2305.10425 (SLiC-HF) TL;DR: Works as well as RLHF, but a lot simpler. About as easy and efficient as fine-tuning. Much better than simply fine-tuning on good examples. From great collaborators: @yaozhaoai,…


The phenomenal teams from Google Research’s Brain and @DeepMind have made many of the seminal research advances that underpin modern AI, from Deep RL to Transformers. Now we’re joining forces as a single unit, Google DeepMind, which I’m thrilled to lead! dpmd.ai/announcing-goo…
Excited and looking forward to this tomorrow! If you are around and interested, please stop by.

For this week's NLP seminar, we are delighted to host @danish037 ! Danish will talk about Evaluating Explanations. The talk will be Thursday at 11AM PT. Non-Stanford affiliate registration form: forms.gle/KF1Tdjar3Ud4Yz…


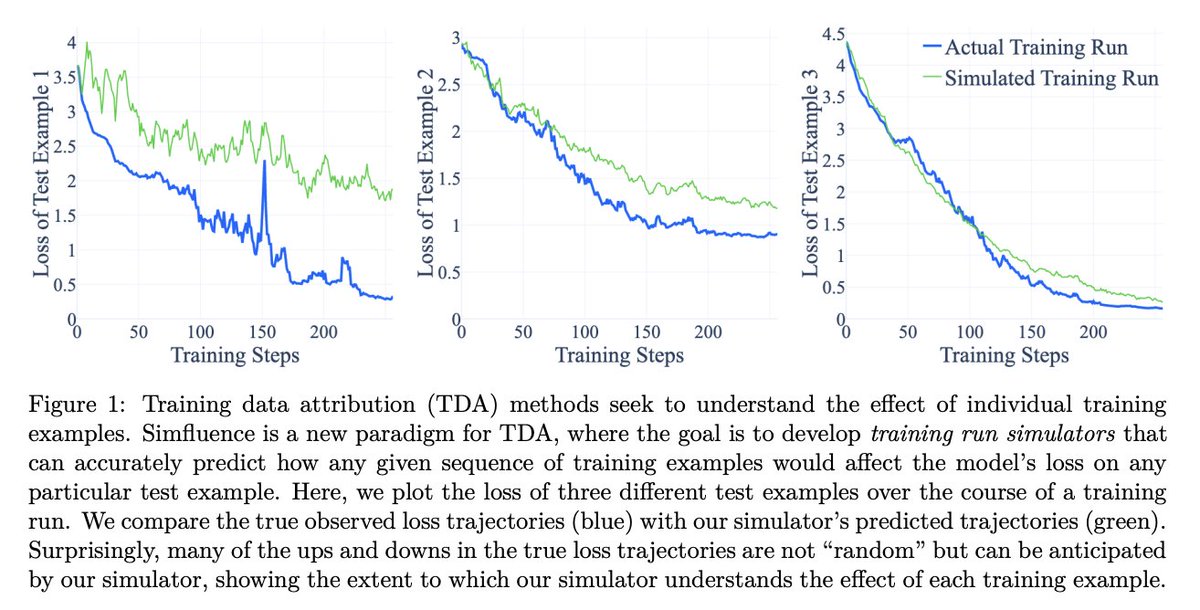
Which training examples taught my LLM to do that? 🤔 New from Google Research: Simfluence tracks how much "smarter" your model gets after consuming each example. It can then simulate scenarios like “What if I removed X dataset from my training corpus?” arxiv.org/abs/2303.08114 🧵
I am looking for a few PhD/MTech (research) students for my lab at IISc Bangalore. The institute-wide applications for these programs are now open (deadline: March, 23). Please email me if you have any questions. iisc.ac.in/admissions/
I am beyond thrilled to share that I'll be starting as an assistant professor at the Indian Institute of Science (IISc), Bangalore in April 2023. I couldn’t have been luckier—I'm grateful for the support of many kind mentors, peers, students, friends and family members. (1/4)

We’re super excited to share our #eacl2023 paper - Language Generation Models Can Cause Harm: So What Can We Do About It? An Actionable Survey Paper: arxiv.org/abs/2210.07700 w/ @shocheen, Lucille Njoo, @anas_ant, Yulia Tsvetkov from @tsvetshop lab. 1/7





















































































































United States 趋势
- 1. Chiefs 83.4K posts
- 2. Brian Branch 2,442 posts
- 3. #TNABoundForGlory 41K posts
- 4. #LoveCabin N/A
- 5. Mahomes 23.4K posts
- 6. LaPorta 9,429 posts
- 7. Goff 12.4K posts
- 8. Bryce Miller 3,529 posts
- 9. #OnePride 5,882 posts
- 10. Kelce 13.3K posts
- 11. Butker 7,943 posts
- 12. #DETvsKC 4,223 posts
- 13. #ALCS 9,606 posts
- 14. Baker 50.5K posts
- 15. Gibbs 5,370 posts
- 16. Dan Campbell 2,241 posts
- 17. Collinsworth 2,446 posts
- 18. Pacheco 4,534 posts
- 19. Tyquan Thornton 1,108 posts
- 20. Mike Santana 2,685 posts
你可能会喜欢
-
 Pratik Joshi
Pratik Joshi
@Roprajo -
 Shruti Rijhwani
Shruti Rijhwani
@shrutirij -
 Partha Talukdar
Partha Talukdar
@partha_p_t -
 Danish Pruthi
Danish Pruthi
@danish037 -
 Language Technologies Institute | @CarnegieMellon
Language Technologies Institute | @CarnegieMellon
@LTIatCMU -
 Tanmay Parekh
Tanmay Parekh
@tparekh97 -
 Bodhisattwa Majumder
Bodhisattwa Majumder
@mbodhisattwa -
 Swaroop Mishra
Swaroop Mishra
@Swarooprm7 -
 tsvetshop
tsvetshop
@tsvetshop -
 Shikhar
Shikhar
@ShikharMurty -
 Simran Khanuja
Simran Khanuja
@simi_97k -
 Abhilasha Ravichander
Abhilasha Ravichander
@lasha_nlp -
 Lindia Tjuatja
Lindia Tjuatja
@lltjuatja -
 Rick Lamers
Rick Lamers
@RickLamers -
 Shuyan Zhou
Shuyan Zhou
@shuyanzhxyc
Something went wrong.
Something went wrong.