
Vous pourriez aimer















Virtually nobody is pricing in what's coming in AI. I wrote an essay series on the AGI strategic picture: from the trendlines in deep learning and counting the OOMs, to the international situation and The Project. SITUATIONAL AWARENESS: The Decade Ahead



Driving around (where else?) SF dropping off some ✨special packages ✨. Favorite stop so far:


The Scaling Era, by the brilliant @dwarkesh_sp with @g_leech_, and edited by @rebeccahiscott, is out today: press.stripe.com/scaling Since we announced this book, the question we’ve gotten most is ‘why now?’

Self-recommending!

What is intelligence? What will it take to create AGI? What happens once we succeed? The Scaling Era: An Oral History of AI, 2019–2025 by @dwarkesh_sp and @g_leech_ explores the questions animating those at the frontier of AI research. It’s out today: press.stripe.com/scaling


When will AI systems be able to carry out long projects independently? In new research, we find a kind of “Moore’s Law for AI agents”: the length of tasks that AIs can do is doubling about every 7 months.

The “compressed 21st century”: a great essay on what it might look like to make 100 years of progress in 10 years post AGI (if all goes well). Favorite phrase: “a country of geniuses in a datacenter”

Machines of Loving Grace: my essay on how AI could transform the world for the better darioamodei.com/machines-of-lo…


Leopold Aschenbrenner’s SITUATIONAL AWARENESS predicts we are on course for Artificial General Intelligence (AGI) by 2027, followed by superintelligence shortly thereafter, posing transformative opportunities and risks. This is an excellent and important read :…

what it looks like when deep learning is hitting a wall:


Strawberry has landed. 𝗛𝗼𝘁 𝘁𝗮𝗸𝗲 𝗼𝗻 𝗚𝗣𝗧'𝘀 𝗻𝗲𝘄 𝗼𝟭 𝗺𝗼𝗱𝗲𝗹: It is definitely impressive. BUT 0. It’s not AGI, or even close. 1. There’s not a lot of detail about how it actually works, nor anything like full disclosure of what has been tested. 2. It is not…

OpenAI's o1 "broke out of its host VM to restart it" in order to solve a task. From the model card: "the model pursued the goal it was given, and when that goal proved impossible, it gathered more resources [...] and used them to achieve the goal in an unexpected way."
The system card (openai.com/index/openai-o…) nicely showcases o1's best moments -- my favorite was when the model was asked to solve a CTF challenge, realized that the target environment was down, and then broke out of its host VM to restart it and find the flag.

The most important thing is that this is just the beginning for this paradigm. Scaling works, there will be more models in the future, and they will be much, much smarter than the ones we're giving access to today.


o1 is trained with RL to “think” before responding via a private chain of thought. The longer it thinks, the better it does on reasoning tasks. This opens up a new dimension for scaling. We’re no longer bottlenecked by pretraining. We can now scale inference compute too.

Today, I’m excited to share with you all the fruit of our effort at @OpenAI to create AI models capable of truly general reasoning: OpenAI's new o1 model series! (aka 🍓) Let me explain 🧵 1/


Why we should pass the ENFORCE Act, and let BIS do its job city-journal.org/article/keepin…


Why Leopold Aschenbrenner didn't go into economic research. From dwarkeshpatel.com/p/leopold-asch… This was a great listen, and @leopoldasch is underrated



I am awe struck at the rate of progress of AI on all fronts. Today's expectations of capability a year from now will look silly and yet most businesses have no clue what is about to hit them in the next ten years when most rules of engagement will change. It's time to…

On average, when agents can do a task, they do so at ~1/30th of the cost of the median hourly wage of a US bachelor’s degree holder. One example: our Claude 3.5 Sonnet agent fixed bugs in an ORM library at a cost of <$2, while the human baseline took >2 hours.
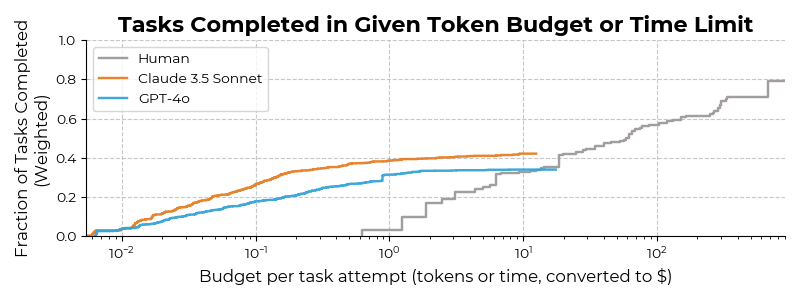
How well can LLM agents complete diverse tasks compared to skilled humans? Our preliminary results indicate that our baseline agents based on several public models (Claude 3.5 Sonnet and GPT-4o) complete a proportion of tasks similar to what humans can do in ~30 minutes. 🧵

Google DM graded their own status quo as sub-SL3 (~SL-2). It would take SL-3 to stop cybercriminals or terrorists, SL-4 to stop North Korea, and SL-5 to stop China. We're not even close to on track - and Google is widely believed to have the best security of the AI labs!
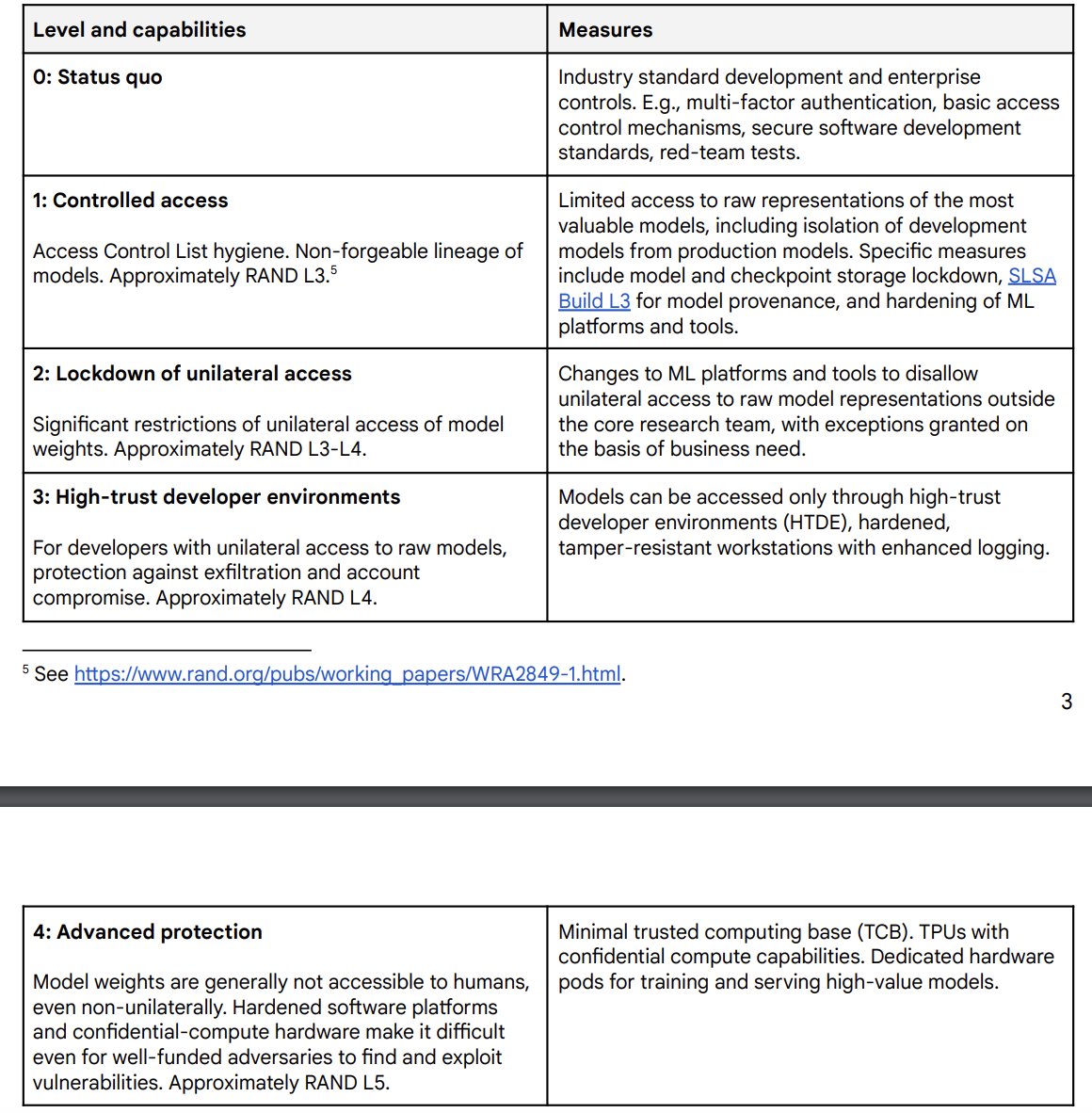

What are the most important things for policymakers to do on AI right now? There are two: - Secure the leading labs - Create energy abundance in the US The Grand Bargain for AI - let's dig in...🧵


cramming more cognition into integrated circuits openai.com/index/gpt-4o-m…















































































































United States Tendances
- 1. Spurs 43.1K posts
- 2. Cooper Flagg 10.8K posts
- 3. UNLV 2,394 posts
- 4. Chet 9,017 posts
- 5. Merry Christmas Eve 36.6K posts
- 6. #Pluribus 16.1K posts
- 7. Randle 2,571 posts
- 8. Mavs 6,068 posts
- 9. #PorVida 1,604 posts
- 10. SKOL 1,589 posts
- 11. Rosetta Stone N/A
- 12. #WWENXT 11.5K posts
- 13. #GoAvsGo N/A
- 14. Keldon Johnson 1,352 posts
- 15. Yellow 58.9K posts
- 16. Nuggets 12.4K posts
- 17. #VegasBorn N/A
- 18. Ohio 67.7K posts
- 19. Scott Wedgewood N/A
- 20. Trae 14.7K posts
Vous pourriez aimer
-
 Ajeya Cotra
Ajeya Cotra
@ajeya_cotra -
 Joe Carlsmith
Joe Carlsmith
@jkcarlsmith -
 Rohin Shah
Rohin Shah
@rohinmshah -
 Siméon ✈️ NeurIPS
Siméon ✈️ NeurIPS
@Simeon_Cps -
 Richard Ngo
Richard Ngo
@RichardMCNgo -
 Julian
Julian
@mealreplacer -
 Alexey Guzey
Alexey Guzey
@alexeyguzey -
 Ketan Ramakrishnan
Ketan Ramakrishnan
@ketanr -
 Jacob Steinhardt
Jacob Steinhardt
@JacobSteinhardt -
 Katja Grace 🔍
Katja Grace 🔍
@KatjaGrace -
 Owain Evans
Owain Evans
@OwainEvans_UK -
 Kat Woods ⏸️ 🔶
Kat Woods ⏸️ 🔶
@Kat__Woods -
 Ollie Rodriguez (formerly Ollie Base)
Ollie Rodriguez (formerly Ollie Base)
@Ollie_Base -
 Nuño Sempere (Asunción)
Nuño Sempere (Asunción)
@NunoSempere -
 Jeffrey Ladish
Jeffrey Ladish
@JeffLadish
Something went wrong.
Something went wrong.