
你可能會喜歡
















New @Scale_AI paper! The culprit behind reward hacking? We trace it to misspecification in high-reward tail. Our fix: rubric-based rewards to tell “excellent” responses apart from “great.” The result: Less hacking, stronger post-training! arxiv.org/pdf/2509.21500



As promised, we put on Arxiv the proof we did with Gemini. arxiv.org/pdf/2505.20219 This shows that the Polyak stepsize not only will not reach the optimum, but it can cycle, when used without the knowledge of f*. Gemini failed when prompted directly ("Find an example where the…


This is a turning point: I just proved a complex math result useful for my research using an LLM. I am not sure if I should be happy or scared...

If you’re at NAACL today, I’ll be presenting this poster in Hall 3 from 2:00 – 3:30 PM. Paper link: aclanthology.org/2025.naacl-lon…
1/🚨 Thrilled to share that our paper (w/ @eduardo_nlp), "Making Language Models Robust Against Negation," has been accepted to the #NAACL2025 main conference! 🎉 #Negation has always been a challenge for language models. Here's our self-supervised method to tackle this issue:

This is a turning point: I just proved a complex math result useful for my research using an LLM. I am not sure if I should be happy or scared...

Look who we found hanging out in her new @StanfordEng Gates Computer Science office! We’re truly delighted to welcome @YejinChoinka as a new @stanfordnlp faculty member, starting full-time in September. ❤️ nlp.stanford.edu/people/


Exciting that @scale_AI is sponsoring Agent Workshop at CMU in April. Students and researchers who work on agents feel free to visit CMU to present your work! I will also be traveling to Pittsburgh to share my recent focuses on agents, both capability and safety.


📢 Join us at the CMU Agent Workshop 2025, April 10-11! Don't miss our esteemed invited speakers: - Qingyun Wu (PSU) - Diyi Yang (Stanford) - Aviral Kumar (CMU) - Graham Neubig (CMU) ...and many more to come! To register, visit: cmu-agent-workshop.github.io

coming to a NAACL 2025 near you! 🌞 Looking forward to discussing with folks in Albuquerque :) The camera-ready is on arxiv now, with more models, more tasks, and more compared settings-- including results comparing ICL to full finetuning! arxiv.org/abs/2405.00200
In-context learning provides an LLM with a few examples to improve accuracy. But with long-context LLMs, we can now use *thousands* of examples in-context. We find that this long-context ICL paradigm is surprisingly effective– and differs in behavior from short-context ICL! 🧵


Excited to share our work on RSQ — enhancing quantization by focusing on the most impactful tokens. - Rotate, Scale, Quantize: delivering strong performance - Dynamic, attention-based token importance drives better efficiency - Results across LLaMA3, Mistral, Qwen-2.5, and more

🚀 New Paper: RSQ: Learning from Important Tokens Leads to Better Quantized LLMs We show that not all tokens should be treated equally during quantization. By prioritizing important tokens through a three-step process—Rotate, Scale, and Quantize—we achieve better-quantized…


Check out 🔥 EgoNormia: a benchmark for physical social norm understanding egonormia.org Can we really trust VLMs to make decisions that align with human norms? 👩⚖️ With EgoNormia, a 1800 ego-centric video 🥽 QA benchmark, we show that this is surprisingly challenging…
🔥 Excited to share EgoNormia! A benchmark for physical social norm understanding. Can we really trust VLMs to make decisions that align with human norms? 🌐 Check out our website for the answer: egonormia.org Proud to be part of this amazing team! 🚀
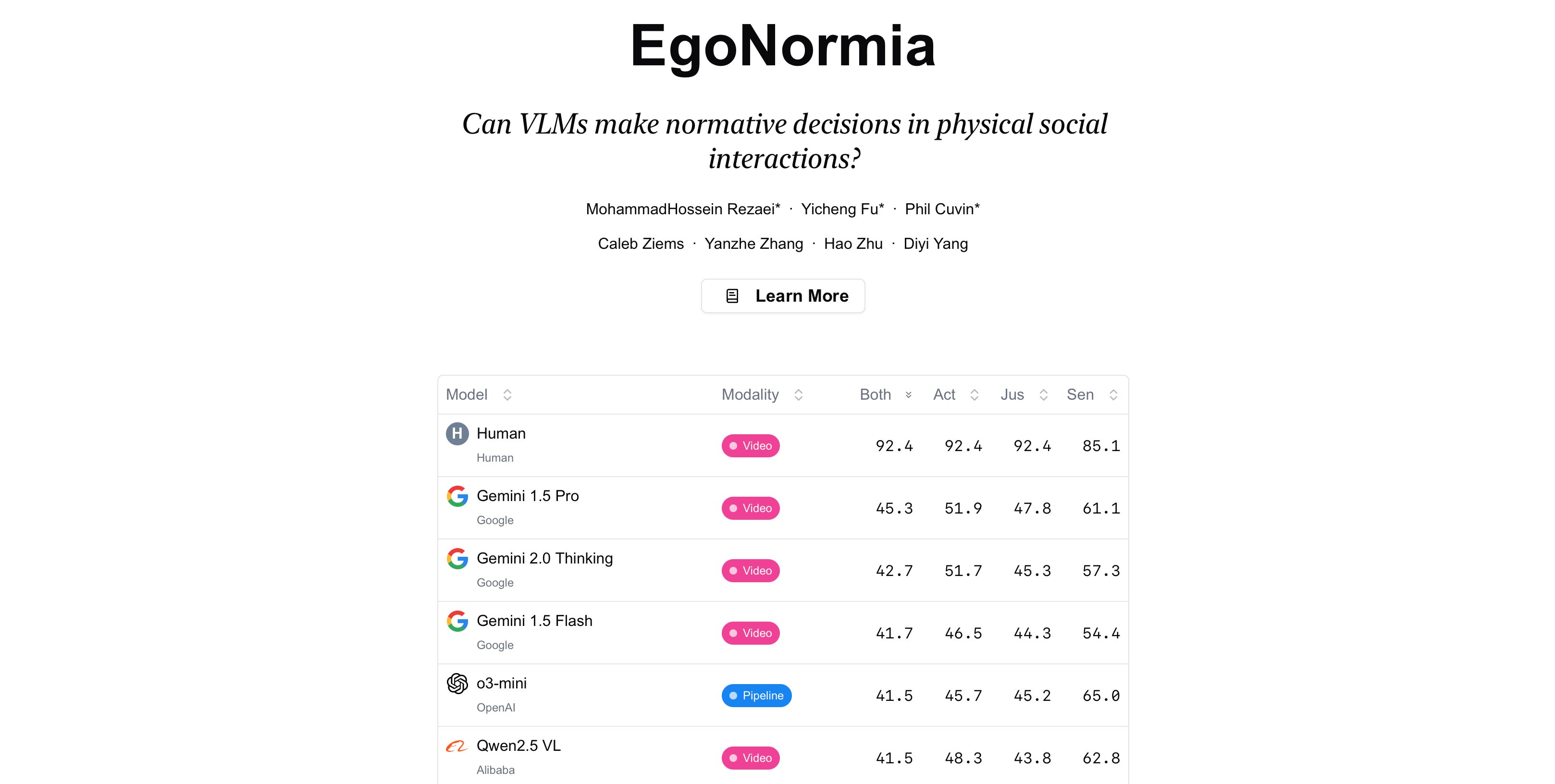
Check out 🔥 EgoNormia: a benchmark for physical social norm understanding egonormia.org Can we really trust VLMs to make decisions that align with human norms? 👩⚖️ With EgoNormia, a 1800 ego-centric video 🥽 QA benchmark, we show that this is surprisingly challenging…

**Kindly consider sharing the post** We are seeking opinions about the current quality of reviewing in *CL conferences. We (@emnlpmeeting PCs along with @ReviewAcl EiCs) are committed to improving the review quality. We are bringing a series of changes in the review process.…

Do you have opinions about the current state of reviewing at *CL conferences? Do you want to help? We (@emnlpmeeting PCs) want to hear from you: forms.office.com/r/P68uvwXYqf


Our new paper in Findings of NAACL 2025, with Vlad Negru, @robert_nlp, @CameliaLemnaru, and Rodica Potolea, proposes a new, softer take on Natural Logic, where alignment is generated through text morphing. This yields robust performance cross domain. arxiv.org/abs/2502.09567
🧵 1/N) Excited to share our recent work at @scale_AI, "Jailbreaking to Jailbreak (J2)".😈 We present a novel LLM-as-red-teamer approach in which a human jailbreaks a refusal-trained LLM to make it willing to jailbreak itself or other LLMs. We refer to this process as…


Is your CS dept worried about what academic research should be in the age of LLMs? Hire one of my lab members! Leshem Choshen (@LChoshen), Pratyusha Sharma (@pratyusha_PS) and Ekin Akyürek (@akyurekekin) are all on the job market with unique perspectives on the future of NLP: 🧵

🚀Big update: 4 new SEAL multilingual leaderboards are LIVE — Arabic, Chinese, Japanese, and Korean! 🌍 Arabic: Gemini 1.5 Pro (gemini-exp-1121) leads the pack 🏮 Chinese: Gemini 1.5 Pro (gemini-1.5-pro-exp-0827) holds the crown 💫 Japanese & Korean: o1-preview dominates 📊 See…
SEAL Visual-Understanding Leaderboard Launch 🏆 Today, we’re introducing VISTA—a new rubric-based visual task assessment benchmark that pushes beyond simple Q&A. The leading models achieve under 40% on this eval, compared to a human baseline of ~55.4%. This highlights that…


what an amazing read: converting json to regex then regex to finite state machines, and then optimising it is brilliant!

I'm on the job market! Please reach out if you are looking to hire someone to work on - RLHF - Efficiency - MoE/Modular models - Synthetic Data - Test time compute - other phases of pre/post-training. If you are not hiring then I would appreciate a retweet! More details👇

I’m looking for a PhD intern for next year to work at the intersection of LLM-based agents and open-ended learning, part of the Llama Research Team in London. If interested please send me an email with a short paragraph with some research ideas and apply at the link below.

Come join our reading group!

New Reading Group! Trustworthy AI Reading Group; dedicated to exploring critical topics in AI, including fairness, security, explainability, and their broader applications. Open to CS undergraduate, master’s, and PhD students. ruixiangtang.net/teaching-mento…


































































































United States 趨勢
- 1. Chiefs 103K posts
- 2. Branch 30.6K posts
- 3. Mahomes 31.4K posts
- 4. #TNABoundForGlory 51.6K posts
- 5. #LoveCabin N/A
- 6. LaPorta 10.2K posts
- 7. Goff 13.5K posts
- 8. Bryce Miller 4,279 posts
- 9. #LaGranjaVIP 50.5K posts
- 10. Kelce 16K posts
- 11. #OnePride 6,310 posts
- 12. Dan Campbell 3,509 posts
- 13. Butker 8,386 posts
- 14. #DETvsKC 4,863 posts
- 15. Mariners 48.7K posts
- 16. Rod Wave N/A
- 17. Gibbs 5,515 posts
- 18. Pacheco 4,936 posts
- 19. Baker 54.3K posts
- 20. Collinsworth 2,953 posts
你可能會喜歡
-
 Nikita Moghe
Nikita Moghe
@nikita_moghe -
 Dan Roth
Dan Roth
@DanRothNLP -
 Preslav Nakov
Preslav Nakov
@preslav_nakov -
 Agostina Calabrese 🦋
Agostina Calabrese 🦋
@agostina_cal -
 Mike Zhang 🦋
Mike Zhang 🦋
@mjjzha -
 Dennis Fucci
Dennis Fucci
@DennisFucci -
 Xianjun Yang
Xianjun Yang
@xianjun_agi -
 Pepa Atanasova
Pepa Atanasova
@atanasovapepa -
 Noriyuki Kojima
Noriyuki Kojima
@noriyuki_kojima -
 ∇f
∇f
@gradient_step -
 Salvatore Greco
Salvatore Greco
@_salvatoregreco -
 Julien Colin
Julien Colin
@juliencolin_ -
 NoBrainz
NoBrainz
@BurlyWilder -
 Philipp Dufter
Philipp Dufter
@PDufter -
 Pranav
Pranav
@nlp_pranav
Something went wrong.
Something went wrong.