
你可能會喜歡










With the announcement of S3-native-streams (Freight clusters), here is a commentary on Confluent strategy regarding object storage, streaming and an open data architecture. jack-vanlightly.com/blog/2024/5/2/…

[New survey on #Knowledge Distillation for #LLMs] 🚀 KD is key for finetuning & aligning LLMs, transferring knowledge from teacher to student models🧑🏫➡️🧑🎓. We explore KD Algorithms, and Skill & Vertical Distillation. Learn more: arxiv.org/abs/2402.13116 1/5
![shawnxxh's tweet image. [New survey on #Knowledge Distillation for #LLMs] 🚀
KD is key for finetuning & aligning LLMs, transferring knowledge from teacher to student models🧑🏫➡️🧑🎓. We explore KD Algorithms, and Skill & Vertical Distillation.
Learn more: arxiv.org/abs/2402.13116
1/5](https://pbs.twimg.com/media/GHTrzMwbMAAqaOA.jpg)

Today we are announcing our latest project, an effort to provide a new evaluation system for open source models. Traditional benchmarking leans heavily on public datasets which can be easy to game and often lead to superficial score improvements that mask true model capabilities…

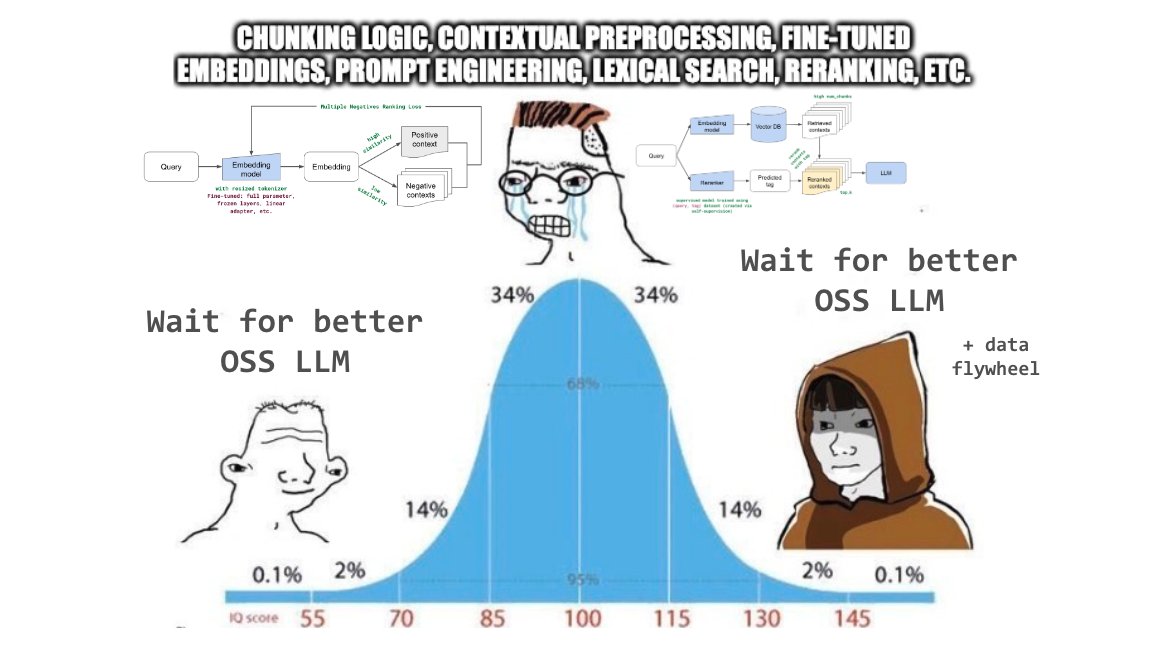
It's been nice to see small jumps in output quality in our RAG applications from chunking experiments, contextual preprocessing, prompt engineering, fine-tuned embeddings, lexical search, reranking, etc. but we just added Mixtral-8x7B-Instruct to the mix and we're seeing a 🤯…




If you are using LoRA or QLoRA, welcome to try the drop-in replacement LoftQ which minimizes the discrepancy between W and its quantized counterpart Q via a better LoRA B & A initialization. More research work is needed for LoRA with Quantization. PEFT: github.com/huggingface/pe…


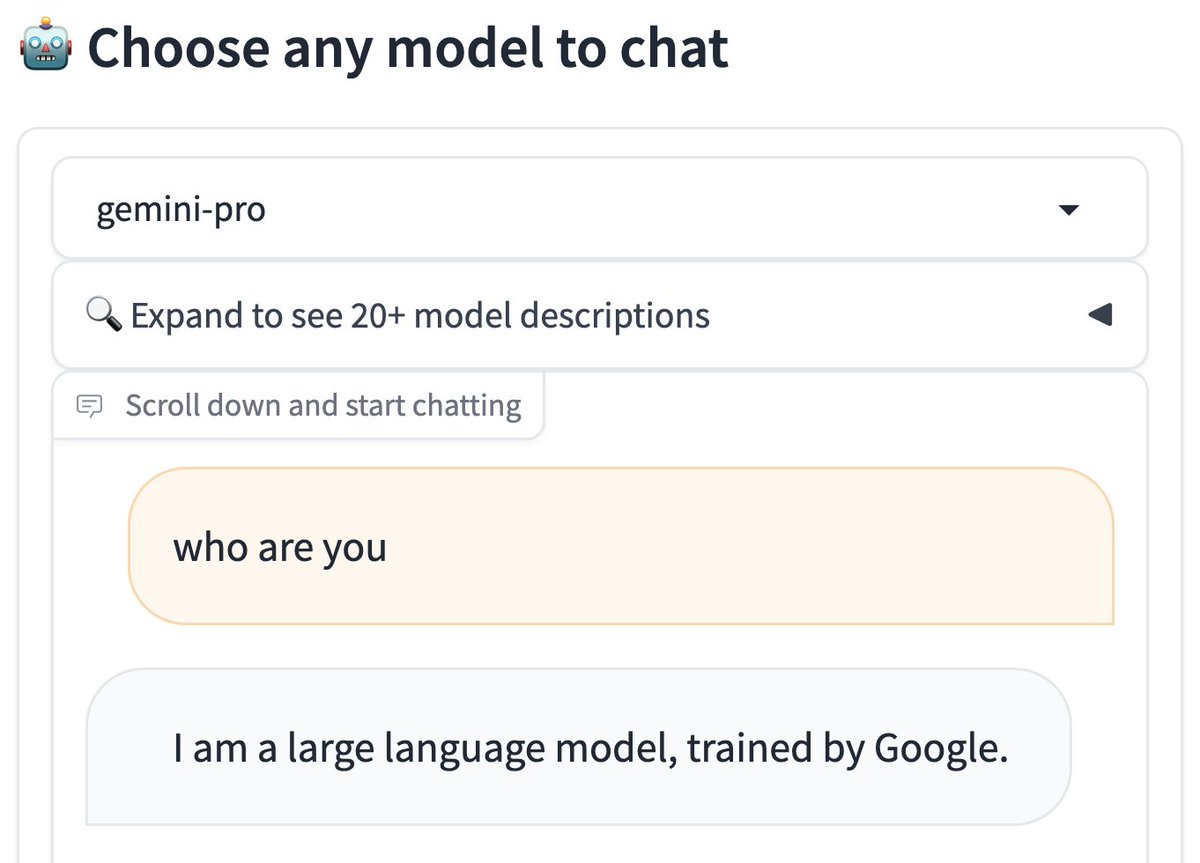
[Arena Update] We've collected over 6000 and 1500 votes for Mixtral-8x7B and Gemini Pro. Both show strong performance against GPT-3.5-Turbo. Big congrats again on the release! @MistralAI @GoogleDeepMind Full leaderboard: huggingface.co/spaces/lmsys/c…
![arena's tweet image. [Arena Update]
We've collected over 6000 and 1500 votes for Mixtral-8x7B and Gemini Pro. Both show strong performance against GPT-3.5-Turbo.
Big congrats again on the release! @MistralAI @GoogleDeepMind
Full leaderboard: huggingface.co/spaces/lmsys/c…](https://pbs.twimg.com/media/GBaKHAEWoAAQU2M.jpg)
![arena's tweet image. [Arena Update]
We've collected over 6000 and 1500 votes for Mixtral-8x7B and Gemini Pro. Both show strong performance against GPT-3.5-Turbo.
Big congrats again on the release! @MistralAI @GoogleDeepMind
Full leaderboard: huggingface.co/spaces/lmsys/c…](https://pbs.twimg.com/media/GBaKPsrXQAEfadd.jpg)
![arena's tweet image. [Arena Update]
We've collected over 6000 and 1500 votes for Mixtral-8x7B and Gemini Pro. Both show strong performance against GPT-3.5-Turbo.
Big congrats again on the release! @MistralAI @GoogleDeepMind
Full leaderboard: huggingface.co/spaces/lmsys/c…](https://pbs.twimg.com/media/GBaKUNnXkAAI828.jpg)
♊️Gemini is now in the Arena. Excited to see its ranking with human evals! Meanwhile, our server just hit the highest traffic since May, with 10,000 votes in just 2 days. How incredible! Huge thanks to @karpathy and the amazing community😂Let's vote at chat.lmsys.org

📢 UltraFeedback Curated by @argilla_io After Notus, we wanna improve data quality for the OS AI community 🐛Fixed 1,968 data points with distilabel 🤯 Used the UltraFeedback method to fix the Ultrafeedback dataset. More in the 🧵 💾 Dataset: huggingface.co/datasets/argil… 🧵


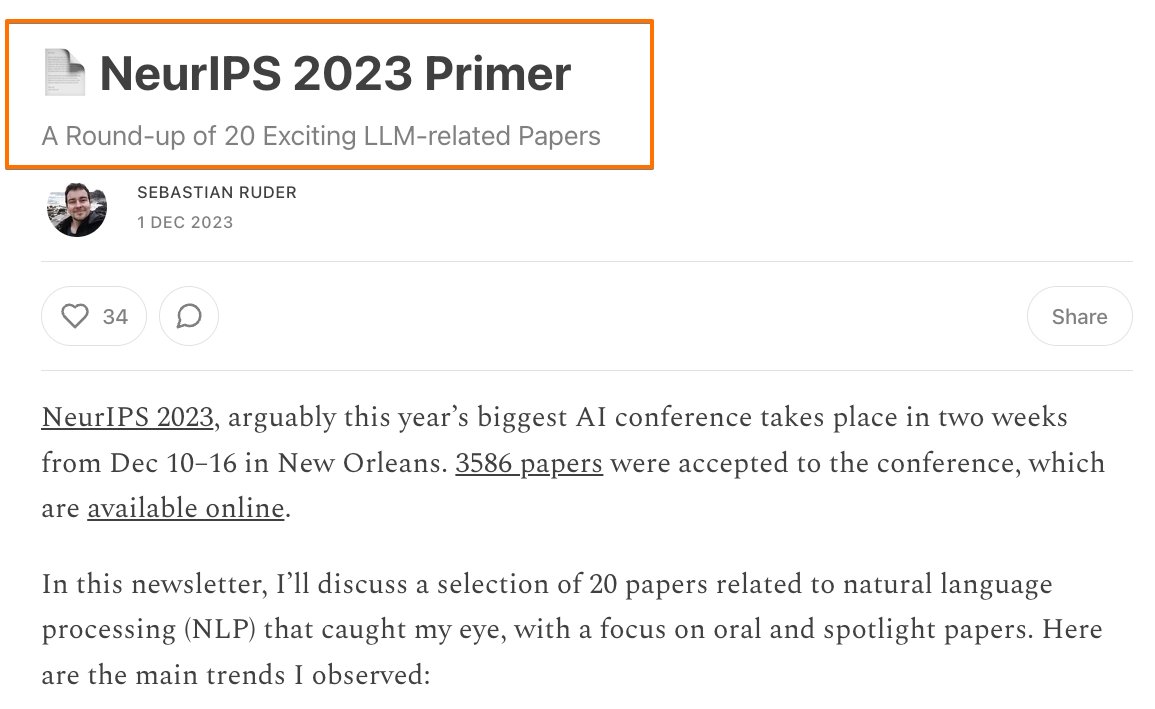
A Round-up of 20 Exciting LLM-related Papers by @seb_ruder Sebastian has done an incredible job in sifting through 3586 papers to bring us a curated selection of 20 standout #NLP papers from #NeurIPS2023 Here's a quick glimpse into the main trends that are defining the future…

I've been maintaining a database of base models with detailed info about the licensing here. See the screenshot for the list of OS-licensed models sorted by size. I believe BTPM-3B /Mistral-7B / MPT-30B is "best model per VRAM" tradeoff. docs.google.com/spreadsheets/d…


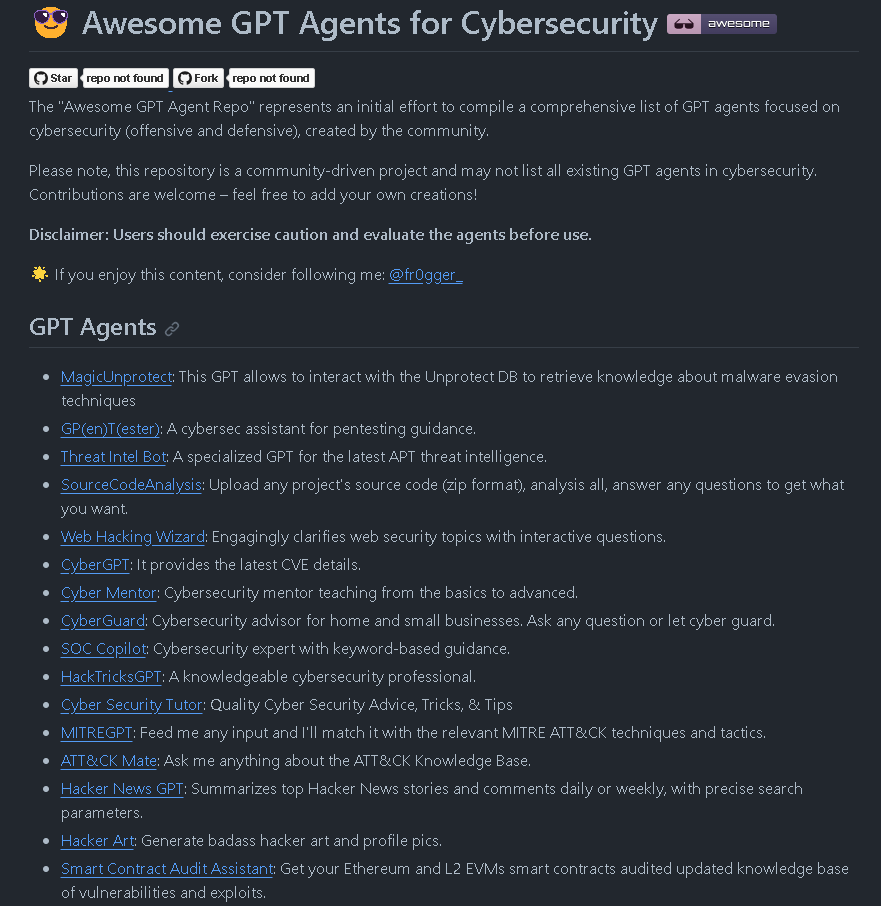
Okay, I've created an "awesome repository" that lists all the GPTs related to cybersecurity. Take a look – the list is continuously growing and there are already many use cases! Feel free to add yours 👇#gpt #infosec #Agents github.com/fr0gger/Awesom…

How well do long-context LLMs (gpt-4-turbo, claude-2) recall specifics in BIG documents? (>= 250k tokens) Inspired by @GregKamradt’s work on stress-testing gpt-4 128k, we extended this by stress testing gpt-4/Claude on even bigger documents that overflow the context window,…

Embedding fine-tuning is underrated and underexplored. An easy trick you can do on top of any black-box embedding model (e.g. openai) is to fine-tune a query embedding transformation. Can be linear, a NN, or anything else. Optimize retrieval perf + no need to reindex docs! 👇

Previously we've seen how to improve retrieval by funetuning an embedding model. @llama_index also supports finetuning an adapter on top of existing models, which lets us improve retrieval without updating our existing embeddings. 🚀 Let's see how it works 👇🧵


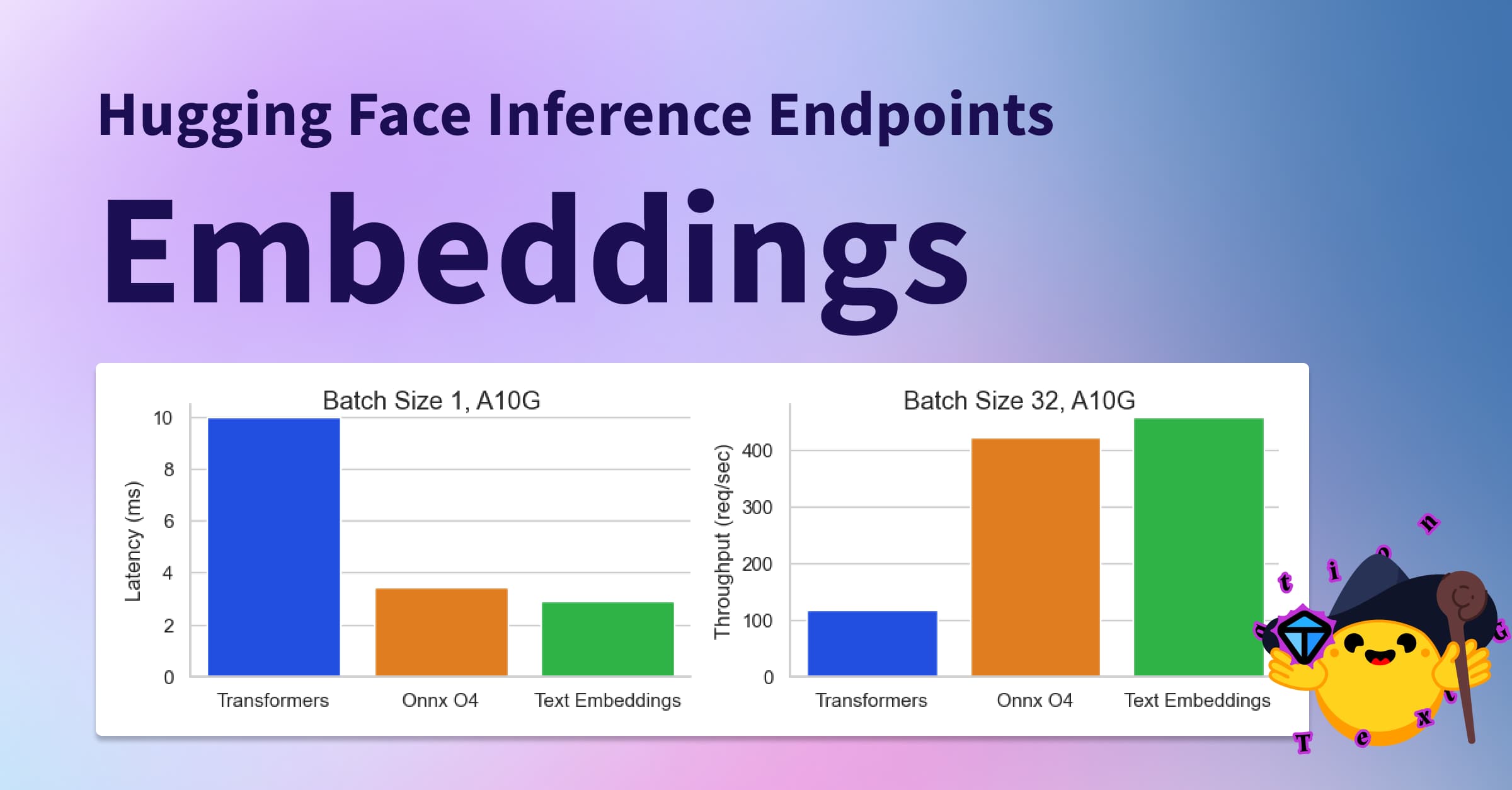
Did you know there are better and cheaper embedding models than @OpenAI? 🤔 We are excited to launch Text Embedding Inference (TEI) on @huggingface Inference endpoints. TEI is a purpose-built solution to run open-source embedding 🚀 👉 huggingface.co/blog/inference… 🧶

Open Source AI repos that caught my 👀 this week @MetaGPT_ github.com/geekan/MetaGPT - multi agent collaboration - MetaGPT encodes Standard Operating Procedures (SOPs) into prompts. The claim is that it takes a one line requirement as input and outputs user stories / competitive…

A high-quality LLMs watch/reading list here: gist.github.com/rain-1/eebd5e5… Contains videos/lectures/articles that do great job at explaining LLMs and GPT models including our "Transformer Blueprint" article :-)


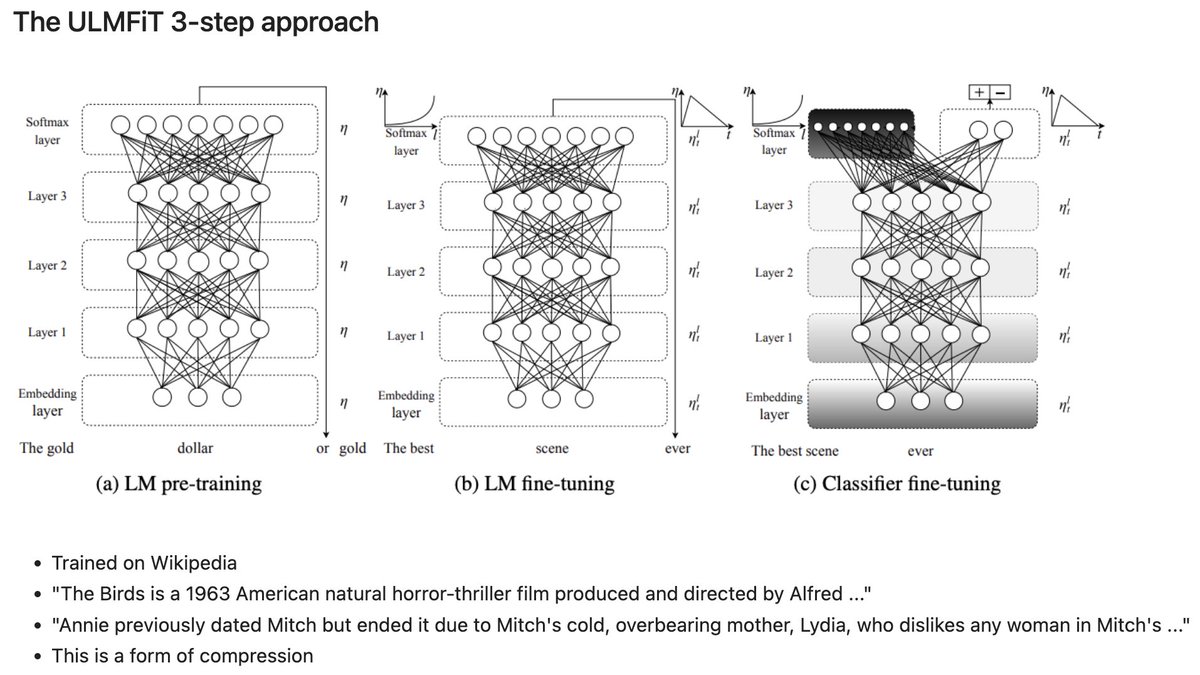
I just uploaded a 90 minute tutorial, which is designed to be the one place I point coders at when they ask "hey, tell me everything I need to know about LLMs!" It starts at the basics: the 3-step pre-training / fine-tuning / classifier ULMFiT approach used in all modern LLMs.

GitWit Agent is Open Source! 🤝 It took three months to build and has been used by hundreds of users to generate over 7,000 commits on GitHub! 📥 It's also available as a command-line tool. Source code: github.com/jamesmurdza/gi…


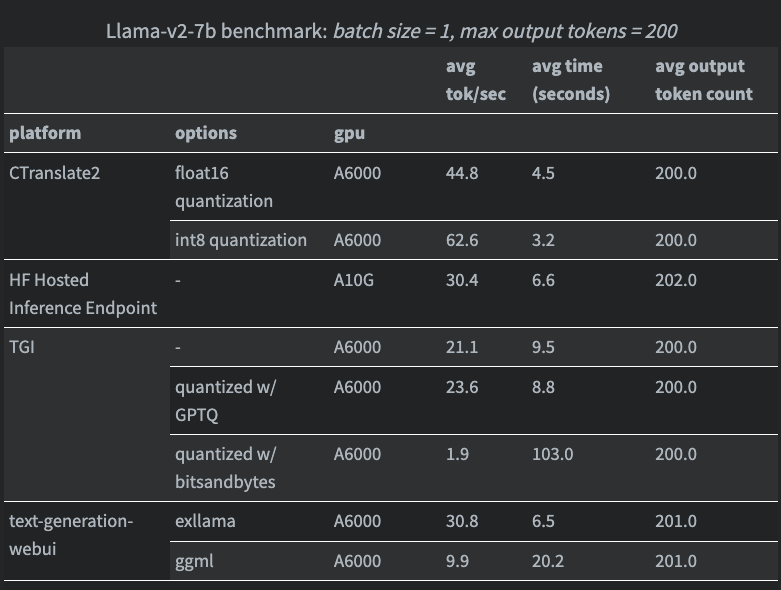
⚡️Run LLMs locally with CTranslate2 We've added support for running local models with the blazingly fast CTranslate2. Thanks to GH eryk-dsai from @deepsense_ai for the feature and @HamelHusain for the great post that introduced us to the library! Docs: python.langchain.com/docs/integrati…



I updated this thanks to @abacaj CTranslate2 allows you to squeeze significantly more performance beyond vLLM



































































































United States 趨勢
- 1. #thursdayvibes 2,381 posts
- 2. Good Thursday 38K posts
- 3. Godzilla 28.1K posts
- 4. Usher 4,341 posts
- 5. Sora 47.6K posts
- 6. Shaggy 2,625 posts
- 7. #RIME_AIlogistics N/A
- 8. #PiratasDelImperio 2,905 posts
- 9. #thursdaymotivation 2,859 posts
- 10. Michigan Man 6,616 posts
- 11. Dolly 16.6K posts
- 12. Person of the Year 11.2K posts
- 13. JUNGKOOK FOR CHANEL BEAUTY 165K posts
- 14. Happy Friday Eve N/A
- 15. Trey Songz N/A
- 16. #ThursdayThoughts 2,440 posts
- 17. Algorhythm Holdings 1,054 posts
- 18. Adam Schefter N/A
- 19. Timo 3,007 posts
- 20. Doug Dimmadome 18K posts









Something went wrong.
Something went wrong.