#bentoml search results

🔥「KubeCon+CloudNativeCon Japan 2025」レポート! スタートアップBentoMLのFog Dong氏が登壇🎤 ✅新PythonライブラリでLLM/MLジョブ高速化 ✅FUSEストリーミングでコールドスタート10倍改善 ✅元Alibaba/ByteDanceの知見も披露 🔗thinkit.co.jp/article/38534 #KubeCon #BentoML #LLM #生成AI

Optimize LLM Inference with BentoML’s Open-Source llm-optimizer Tool #BentoML #llmOptimizer #OpenSource #LLMPerformance #AIOptimization itinai.com/optimize-llm-i… BentoML has launched an exciting new tool called llm-optimizer, an open-source framework aimed at optimizing the perf…


Thinking about a career in #machinelearning? Don’t just train models—learn to deploy them. BentoML gives you the toolkit to master MLOps, simplify workflows, and turn cutting-edge models into real-world AI applications. Discover more bit.ly/4lTtFI3 #MLOps #BentoML #USDSI


📸 Live from #Ai4 2025 in Las Vegas! 🍱 The Bento team is here at Booth #346, showing how we help enterprises run, scale, and optimize inference for mission-critical AI workloads. Come say hi 👋 If you’re here, tag us in your photos! @Ai4Conferences #AIInference #BentoML



BentoML: Build, package, and distribute ML models as containerized microservices for scalable real-world deployment. #BentoML #ModelServing #Microservices #Containerization #Python #MLOps #Deployment #MLModels
🚀 @OpenAI just released two powerful open-weight reasoning models: gpt-oss-120b and gpt-oss-20b. #BentoML supports them from day zero! Key takeaways: ✅ 120b matches OpenAI o4-mini on core benchmarks ✅ 20b rivals o3-mini, ideal for local & on-device inference ✅…

#CVE-2025-54381 | BentoML - Unauthenticated SSRF (Critical) #BentoML versions 1.4.0 to 1.4.18 are vulnerable to an unauthenticated Server-Side Request Forgery (#SSRF) due to improper validation of user-provided URLs in file upload handlers. This allows attackers to force the…
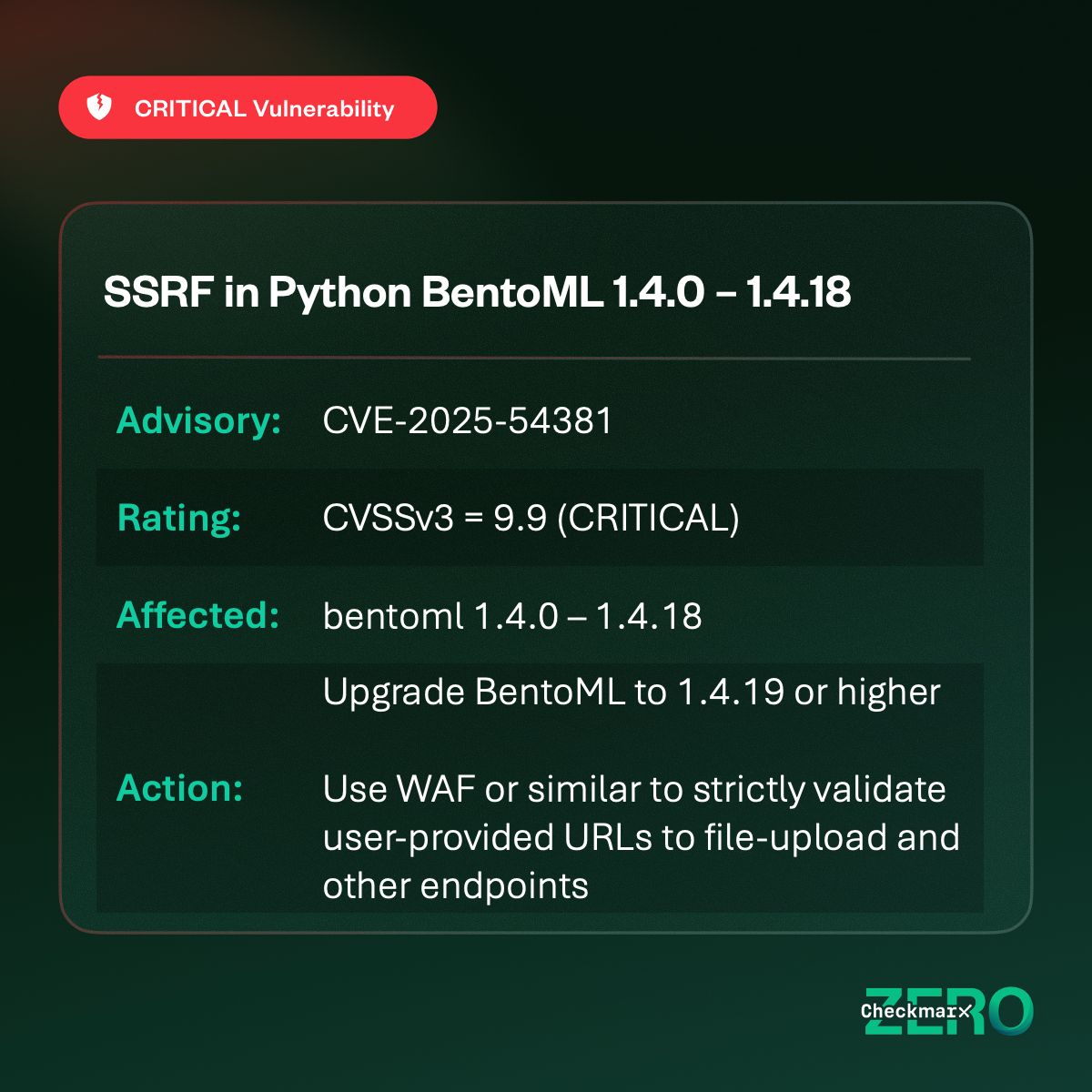

🚨 CVE-2025-54381: Critical SSRF in BentoML BentoML is an open-source Python framework to package & deploy ML models as APIs. Versions <1.4.19 let attackers trigger internal HTTP requests via uploads. Patch now! #CVE202554381 #BentoML #SSRF #Python #MachineLearning #AI #MLOps…

A critical SSRF vulnerability in BentoML's file upload handling allows unauthenticated remote attackers to perform internal network reconnaissance and steal cloud metadata credentials from AI applications. #BentoML #SSRF #AISecurity #CVE #Cybersecurity securityonline.info/critical-bento…
securityonline.info
Critical BentoML SSRF (CVSS 9.9) Exposes AI Applications to Unauthenticated Network Recon & Cloud...
A critical SSRF vulnerability (CVE-2025-54381) in BentoML's file upload handling allows unauthenticated remote attackers to perform internal network reconnaissance and steal cloud metadata credenti...
#BentoFriday 🍱 — Lightning-Fast Model Loading When deploying #LLM services, slow model loading can cripple your cold starts. 🚨 This leads to delayed autoscaling, missed requests during traffic spikes, and a poor user experience. #BentoML supercharges model loading with speed…


Single-GPU optimizations are hitting walls 🧱 . Discover how Google, NVIDIA, and open-source giants like vLLM are redefining LLM inference with distributed strategies via our new report lnkd.in/gcVfQDT8 #bentoml #vllm #llmops #deepseek #ollama

4️⃣ Developer-First Tools These make infra real. → Ollama (local model runners) → vLLM (fast inference servers) → HuggingFace (model zoo) → BentoML (packaging + serving) Think DevOps—but for LLMs. #Ollama #BentoML #HuggingFace
🍱Spreading the word on #BentoML at #KubeCon + #CloudNativeCon 🙌 Big shoutout to @fog_glutamine

Just wrapped up my talks at KubeCon + CloudNativeCon Hong Kong and KubeCon Japan! Great to connect with the cloud native community and share some ideas. Thanks to everyone who joined! 🙌 #KubeCon #CNCF #CloudNative #Kubernetes




#Vulnerability #BentoML CVE-2025-27520: Critical BentoML Flaw Allows Full Remote Code Execution, Exploit Available securityonline.info/cve-2025-27520…

#BentoFriday 🍱 — Add a Web UI with @Gradio Real-world #AI apps don’t just need a model. They need interfaces users can interact with. But building a custom frontend is time-consuming and managing it separately from your backend adds unnecessary complexity. 😵💫 With #BentoML,…

🚀 #Magistral, @MistralAI’s first reasoning model, is here and now deployable with #BentoML! This release features two variants: - Magistral Small: 24B parameter open-source version - Magistral Medium: Enterprise-grade, high-performance version Highlights of Magistral Small: 🔧…
Choosing the right #AI deployment platform? Check out our detailed comparison of #BentoML vs #VertexAI to help you make informed decisions. bentoml.com/blog/compariso… 🔍 Here’s what we cover: ✅ Cloud infrastructure flexibility ✅ Scaling and performance ✅ Developer experience and…
bentoml.com
Comparing BentoML and Vertex AI: Making Informed Decisions for AI Model Deployment
A high-level comparison of Vertex AI and BentoML for AI model deployment, examining cloud infrastructure, scaling performance, and developer experience to help AI teams make informed decisions.
👀 Update on DeepSeek-R1-0528 bentoml.com/blog/the-compl… 🧠 Built on V3 Base 📈 Major reasoning improvements 🛡️ Reduced hallucination ⚙️ Function calling + JSON output 📦 Distilled Qwen3-8B beats much larger models 📄 Still MIT See our updated blog ⬇️ #AI #LLM #BentoML #OpenSource











🎄✨ Merry Christmas! Wishing everyone a season filled with joy, warmth, and delicious surprises! 🍱❤️ #Christmas #BentoML

Looking to build semantic search, #RAG, or recommendation systems with 𝗲𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴 𝗺𝗼𝗱𝗲𝗹𝘀? #BentoML makes it easy to 𝘀𝗲𝗿𝘃𝗲 𝗮𝗻𝗱 𝘀𝗰𝗮𝗹𝗲 𝗮𝗻𝘆 𝗼𝗽𝗲𝗻-𝘀𝗼𝘂𝗿𝗰𝗲 𝗲𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴 𝗺𝗼𝗱𝗲𝗹: ✅ Batching requests for embedding generation ✅ Batch size…

Learn how #Yext cut time-to-market & compute costs by re-platforming #AI Inference on #BentoML: Key wins: ✅ 𝟯× 𝗳𝗮𝘀𝘁𝗲𝗿 model delivery (70 % less dev time) ✅ 𝗨𝗽 𝘁𝗼 𝟴𝟬 % 𝗚𝗣𝗨 𝘀𝗮𝘃𝗶𝗻𝗴𝘀 with cloud‑agnostic autoscaling ✅ 𝟮× 𝗺𝗼𝗿𝗲 𝗺𝗼𝗱𝗲𝗹𝘀 𝘀𝗵𝗶𝗽𝗽𝗲𝗱…
On this Thanksgiving Day, we're grateful for our incredible community that makes #BentoML what it is today. A heartfelt thank you to our users, customers, contributors and partners! Your support drives us to make #AI deployment and scaling simpler, faster and more reliable!…

🚀 Self-host models with #Triton + #BentoML! @nvidia Triton Inference Server is a powerful open-source tool for serving models from major ML frameworks like ONNX, PyTorch, and TensorFlow. This project wraps Triton with BentoML, making it easy to: 🎯 Package custom models as…

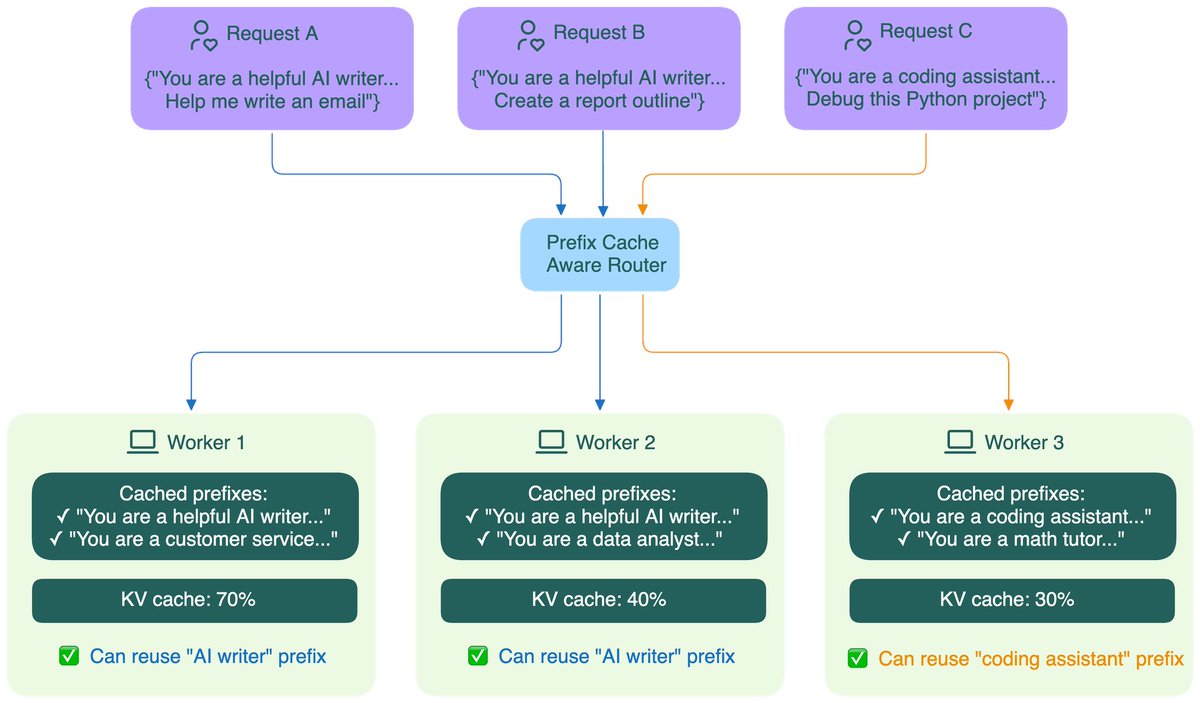
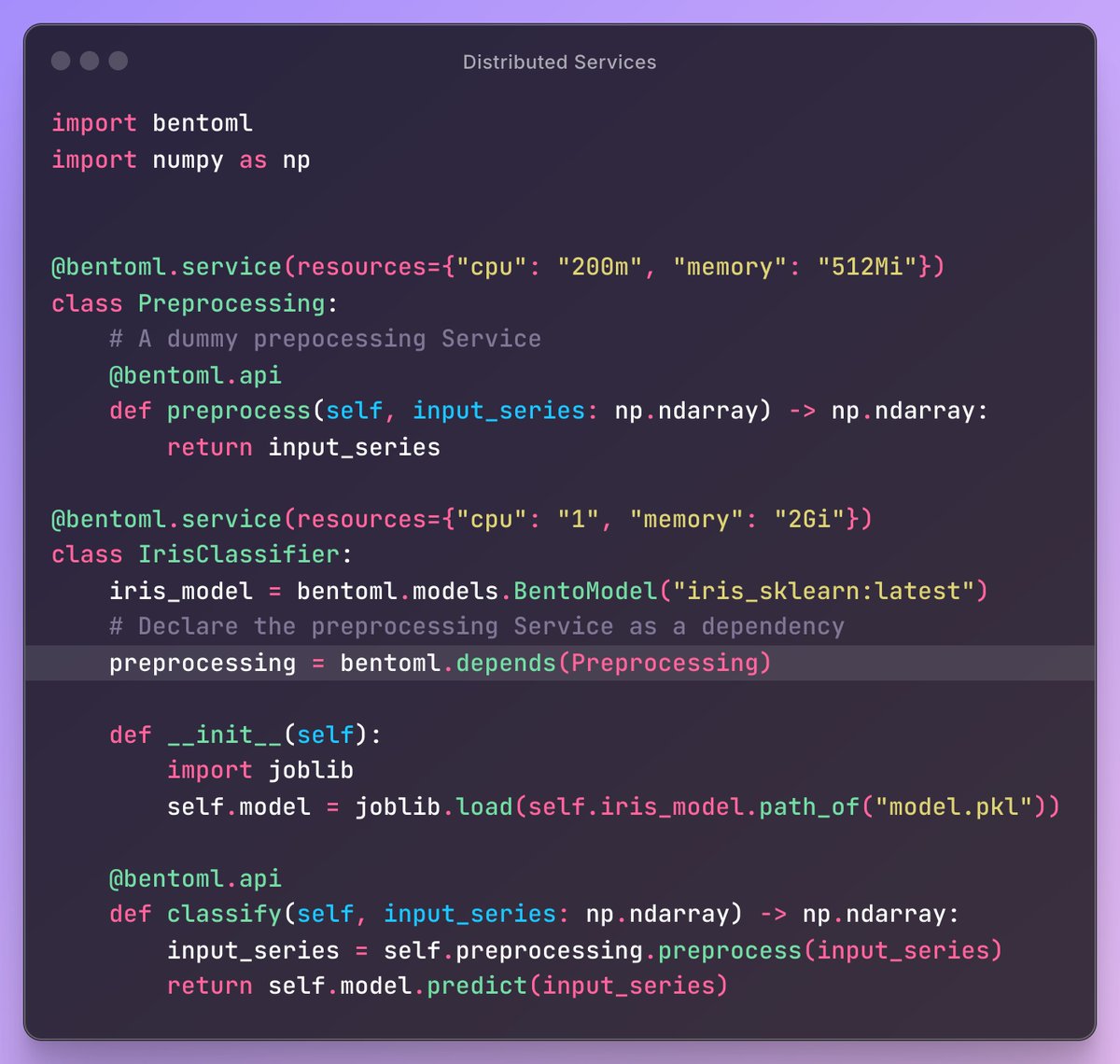
#BentoFriday 🍱 — Distributed Services in #BentoML #AI deployments are going distributed. Some examples: 🔧 Disaggregated #LLM serving 🔍 KV-aware LLM routing 🧠 Multi-model Computer Vision pipelines 🔐 LLM safety & moderation layers 🔁 #RAG pipelines In these systems,…
Want to self-host model inference in production? Start with the right model. We’ve put together a series exploring popular open-source models. Ready to deploy with #BentoML 🍱 🗣️ Text-to-Speech bentoml.com/blog/exploring… 🖼️ Image Generation bentoml.com/blog/a-guide-t… 🧠 Embedding…

Headed to @NVIDIAGTC this week? Come visit us at booth #2020 to experience #BentoML in action! We're showcasing exciting demos across LLMs, embeddings, agents, compound AI and more! 🍱 The BentoML team can't wait to meet you and discuss how our inference platform can accelerate…

🚀 DeepSeek-R1-0528 just landed! 🔍 Still no official word — no model card, no benchmarks. #DeepSeek being DeepSeek, as always 😅 ✅ Good news: #BentoML already supports it. 👉 Deploy it now with our updated example: github.com/bentoml/BentoV… 👀 Follow for more updates!

🍁 This #Thanksgiving, we're giving thanks to our incredible users, customers & dev community! Your support fuels the #BentoML ecosystem. Wishing you all a wonderful Thanksgiving filled with joy and gratitude! 🦃 #OpenSource #MLOps #MachineLearning

#BentoFriday 🍱 — Add a Web UI with @Gradio Real-world #AI apps don’t just need a model. They need interfaces users can interact with. But building a custom frontend is time-consuming and managing it separately from your backend adds unnecessary complexity. 😵💫 With #BentoML,…
🚀 Build CI/CD pipelines for #AI services with #BentoML + #GitHubActions Automate everything with pipelines that: ✅ Deploy services to #BentoCloud ✅ Trigger on code or deployment config changes ✅ Wait until the service is ready ✅ Run test inference 📘 Step-by-step guide:…

📸 Live from #Ai4 2025 in Las Vegas! 🍱 The Bento team is here at Booth #346, showing how we help enterprises run, scale, and optimize inference for mission-critical AI workloads. Come say hi 👋 If you’re here, tag us in your photos! @Ai4Conferences #AIInference #BentoML
#CVE-2025-54381 | BentoML - Unauthenticated SSRF (Critical) #BentoML versions 1.4.0 to 1.4.18 are vulnerable to an unauthenticated Server-Side Request Forgery (#SSRF) due to improper validation of user-provided URLs in file upload handlers. This allows attackers to force the…

🚨 A critical flaw (CVE-2025-27520) in BentoML allows remote code execution on versions 1.3.4 and <1.4.3. Exploit is available, posing risks of system compromise and data theft. #BentoML #SecurityAlert #USA link: ift.tt/CSsDV4q

#BentoFriday 🍱 — Inference Context with 𝘣𝘦𝘯𝘵𝘰𝘮𝘭.𝘊𝘰𝘯𝘵𝘦𝘹𝘵 Building #AI/ML APIs isn’t just about calling a model. You need a clean, reliable way to customize your inference service. 𝘣𝘦𝘯𝘵𝘰𝘮𝘭.𝘊𝘰𝘯𝘵𝘦𝘹𝘵 is one of those abstractions in #BentoML that gives…

#BentoFriday 🍱 — Lifecycle Hooks in #BentoML When deploying real-world #AI services, the work doesn’t end at inference. You also need to manage everything that happens before, during, and after a request hits your model. In practice, that often means: 🔧 Setting up global…

#BentoFriday 🍱 — Lightning-Fast Model Loading When deploying #LLM services, slow model loading can cripple your cold starts. 🚨 This leads to delayed autoscaling, missed requests during traffic spikes, and a poor user experience. #BentoML supercharges model loading with speed…
Something went wrong.
Something went wrong.
United States Trends
- 1. #GMMTV2026 2.56M posts
- 2. Good Tuesday 29.2K posts
- 3. MILKLOVE BORN TO SHINE 414K posts
- 4. #tuesdayvibe 2,152 posts
- 5. WILLIAMEST MAGIC VIBES 56.7K posts
- 6. Mark Kelly 215K posts
- 7. MAGIC VIBES WITH JIMMYSEA 66.1K posts
- 8. JOSSGAWIN MAGIC VIBES 22K posts
- 9. Chelsea 218K posts
- 10. #JoongDunk 99.2K posts
- 11. Alan Dershowitz 3,248 posts
- 12. TOP CALL 9,405 posts
- 13. AI Alert 8,249 posts
- 14. #ONEPIECE1167 8,524 posts
- 15. Barca 84K posts
- 16. Maddow 15.3K posts
- 17. Check Analyze 2,468 posts
- 18. Jim Croce N/A
- 19. Token Signal 8,606 posts
- 20. Unforgiven 1,188 posts