#vllm arama sonuçları

🚀 llm-d v0.3.1 is LIVE! 🚀 This patch release is packed with key follow-ups from v0.3.0, including new hardware support, expanded cloud provider integration, and streamlined image builds. Dive into the full changelog: github.com/llm-d/llm-d/re… #llmd #OpenSource #vLLM #Release



LLMを爆速化する秘訣は「vLLM」!🚀 AIモデルの推論を劇的に高速化し、運用コストも削減する「vLLM」がすごいんです!✨ 個人や中小企業のAIサービス展開を強力にサポート。AI活用がもっと快適になりますよ! #vLLM


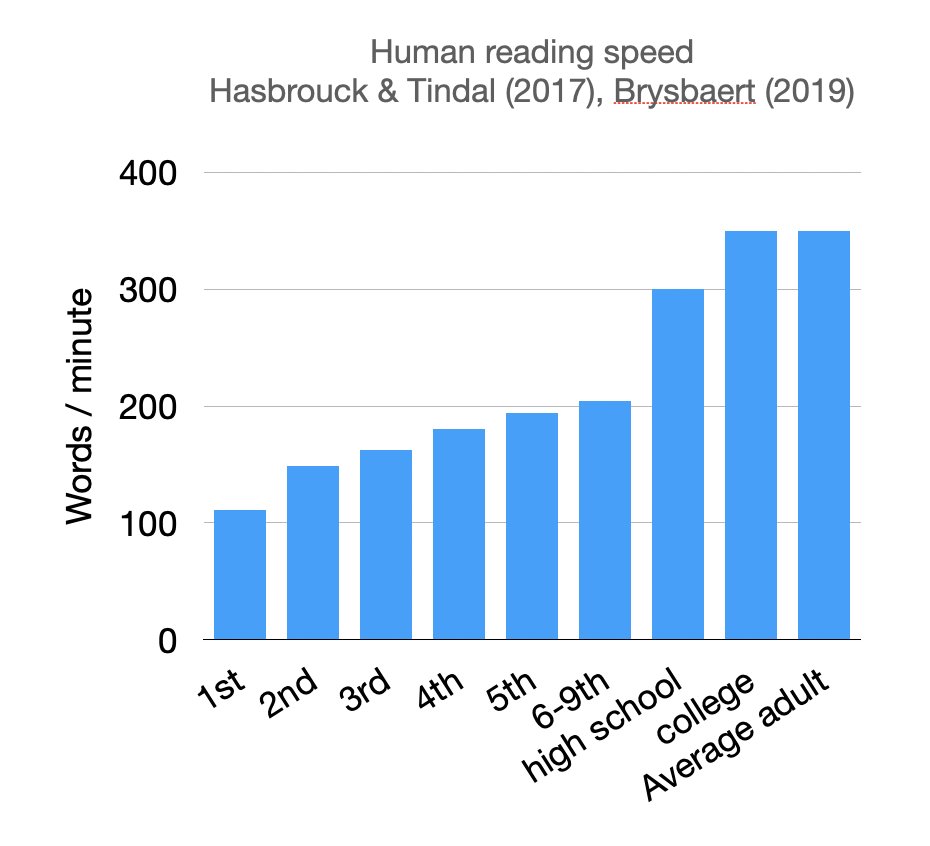
(1/n) We are drastically overestimating the cost of LLMs, because we sometimes over-focus for single-query speed. Had the privilege to talk about this topic at the #vllm meetup yesterday. An average human reads 350 words per minute, which translates to 5.5 words per second.

Getting 10x speedup in #vLLM is easier than you think 📈 I just discovered speculative decoding with ngram lookup and the results speak for themselves. Here's what you add to your vLLM serve command: speculative_config={ "method": "ngram", "num_speculative_tokens": 8,…


DeepSeek's (@deepseek_ai) latest—MLA, Multi-Token Prediction, 256 Experts, FP8 block quantization—shines with @vllm_project. Catch the office hours session were we discuss all the DeepSeek goodies and explore their integration and benchmarks with #vLLM.

Disaggregated Inference at Scale with #PyTorch & #vLLM: Meta’s vLLM disagg implementation improves inference efficiency in latency & throughput vs its internal stack, with optimizations now being upstreamed to the vLLM community. 🔗 hubs.la/Q03J87tS0


Something we're doing differently this time around, we added a #vLLM track to #RaySummit! @vllm_project is one of the most popular inference engines, and is often used together with @raydistributed for scaling LLM inference. Can't wait to hear from these companies about how…

#vLLM V1 now runs on AMD GPUs. Teams from IBM Research, Red Hat & AMD collaborated to build an optimized attention backend using Triton kernels, achieving state-of-the-art performance. 🔗 Read: hubs.la/Q03PC50p0 #PyTorch #OpenSourceAI


🚨 LMCache now turbocharges multimodal models in vLLM! By caching image-token KV pairs, repeated images now get ~100% cache hit rate — cutting latency from 18s to ~1s. Works out of the box. Check the blog: blog.lmcache.ai/2025-07-03-mul… Try it 👉 github.com/LMCache/LMCache #vLLM #MLLM…


🧵1/4 Our Llama 3.1 compression project is underway, aiming for cost-effective and sustainable deployments without compromising accuracy. The FP8 quantized Llama 3.1 8B model has already achieved over 99% recovery! 🎯📉 #LLMs #vLLM #AI #MachineLearning #Quantization

Full house at the #vLLM and @ollama meetup in SF hosted by @ycombinator. Great to see familiar faces and meet new ones!



Batch Inference with Qwen2 Vision LLM (Sparrow) I'm explaining several hints how to optimize Qwen2 Visual LLM performance for batch processing. Complete video: youtube.com/watch?v=9SmQxT… Code: github.com/katanaml/sparr… Sparrow UI: katanaml-sparrow-ui.hf.space @katana_ml #vllm #ocr

この #VLLM な #gemma-3-27b-it-qat-q4_0-gguf を使ったChat and 画像生成、実写/3枚目 "what?"で出て来た/2枚目 英文に"手前に雰囲気の合った女性を立たせてください"(27bなので日本語OK) 1枚目。なかなか使える♪ < Caption系だと2枚目は出ても1枚目は手で追加 #AI美女 #AIグラビア



#VLLMな #gemma-3-27b-it-qat-q4_0-gguf (at #RTX3090)を使って画像を解析、そのPromptを使い #FLUX.1 [dev] で画像生成。ほぼ一致♪ #LM_Studio #OpenWebUI huggingface.co/google/gemma-3…
![PhotogenicWeekE's tweet image. #VLLMな #gemma-3-27b-it-qat-q4_0-gguf (at #RTX3090)を使って画像を解析、そのPromptを使い #FLUX.1 [dev] で画像生成。ほぼ一致♪
#LM_Studio #OpenWebUI
huggingface.co/google/gemma-3…](https://pbs.twimg.com/media/GsO4kKTaMAIRxeB.jpg)

Great news! 🎉 PaddleOCR-VL is now supported on vLLM! Bringing powerful vision-language capabilities with blazing-fast inference. Try it out and experience the boost! #PaddleOCR #vLLM #AICommunity
Streamlined Table Data Extraction with Sparrow | Table Transformer, Qwen2 VL, MLX, & Mac Mini M4 Pro Learn how to streamline table data extraction with Sparrow, Table Transformer, Qwen2 VL, and MLX on the Mac Mini M4 Pro. @katana_ml #ocr #vllm #json

vllm Meet vLLM, a fast & easy-to-use library for LLM inference & serving. Powered by PyTorch Foundation, it's now available for everyone! #vLLM #LargeLanguageModeling #PyTorchFoundation


AI Inference at scale? 🤔 Open source to the rescue! Dive into #vLLM, distributed systems, and the path to practical #AI in the enterprise with @kernelcdub and @addvin on the latest "Technically Speaking." red.ht/3FEEZJ6

⚙️ We integrate vLLM into MCTS, accelerating node expansion, rollout, and reward evaluation. Beyond reasoning accuracy, this creates a reusable acceleration framework for large-scale MCTS and TTS research. #MCTS #vLLM #InferenceTimeCompute



🌟Red Hatが「vLLM Semantic Router」をリリース! クエリの複雑さに応じて最適なLLMに自動振り分け💡 ・シンプル→小型高速モデル ・複雑→大型推論モデル コスト効率とパフォーマンスを両立する画期的なルーティング技術 #RedHat #vLLM #エンタープライズAI #AIHack

Come see us (me & Yuhan Liu) tomorrow for our talk. Specifically, Wednesday November 12, 2025 5:30pm - 6:00pm EST at Building B | Level 5 | Thomas Murphy Ballroom 1. More info: sched.co/27FcQ #kubecon #vllm
Come see us (me & Yuhan Liu) tomorrow for our talk. Specifically, Wednesday November 12, 2025 5:30pm - 6:00pm EST at Building B | Level 5 | Thomas Murphy Ballroom 1. More info: sched.co/27FcQ #kubecon #vllm
Come see us (me & Yuhan Liu) tomorrow for our talk. Specifically, Wednesday November 12, 2025 5:30pm - 6:00pm EST at Building B | Level 5 | Thomas Murphy Ballroom 1. More info: sched.co/27FcQ #kubecon #vllm
🚀 llm-d v0.3.1 is LIVE! 🚀 This patch release is packed with key follow-ups from v0.3.0, including new hardware support, expanded cloud provider integration, and streamlined image builds. Dive into the full changelog: github.com/llm-d/llm-d/re… #llmd #OpenSource #vLLM #Release

𝟮𝟬𝟮𝟱 𝗖𝗵𝗶𝗻𝗮 𝘃𝗟𝗟𝗠 𝗠𝗲𝗲𝘁𝘂𝗽 - 𝗕𝗲𝗶𝗷𝗶𝗻𝗴 𝗲𝘃𝗲𝗻𝘁 🤝🚀 Co-organized with Ant Group, ByteDance, AMD and MetaX: this community-driven event brought together >350 attendees on-site and an online presence of over 41,000 viewers! #RedHatAPAC #vLLM

NTTドコモのブログで、vLLM Sleep Modeによるモデルのゼロリロード切り替え機能の検証結果が紹介されています。コンテナベースでの動作確認が行われ、効率的な切り替えが実現!詳細はブログでチェック! #vLLM #NTTドコモ ift.tt/Jodkahx


Ray summit 2025 takeaways: 1. Ray is now in PyTorch Foundation 2. Ray supports RDMA (finally) 3. Anyscale runtime, basically Ray + better perf and fault tolerance/observability etc. 4. Anyscale is building multi-resource cloud, and collaborating with Azure. #raysummit2025 #vllm




Great news! 🎉 PaddleOCR-VL is now supported on vLLM! Bringing powerful vision-language capabilities with blazing-fast inference. Try it out and experience the boost! #PaddleOCR #vLLM #AICommunity

🚀LLM vs vLLM – Which one delivers faster, smarter, and more efficient AI inference? From performance to scalability, this complete comparison breaks it all down. Dive in and choose the right model for your AI workloads! 🔗shorturl.at/EnR9K #AI #LLM #vLLM #MachineLearning


Fine-tuning LLMs but losing base skills? Try: – 🕶 Shadow infer + backfill drift – 🔀 Post-hoc LoRA blend (70% base, 30% task) – 🧠 Ghost-tune w/ contrastive English anchors It’s not just overfitting – it’s amnesia with style. #LLM #FineTuning #vLLM



Bijit Ghosh (@bijitghosh21) spotlighted how #vLLM and #SGLang are syncing open-source inference at massive scale. Their fusion of memory and time optimization just set a new bar for efficiency in the GPU economy. Let’s keep the conversation going on LinkedIn:…
























































🚀 llm-d v0.3.1 is LIVE! 🚀 This patch release is packed with key follow-ups from v0.3.0, including new hardware support, expanded cloud provider integration, and streamlined image builds. Dive into the full changelog: github.com/llm-d/llm-d/re… #llmd #OpenSource #vLLM #Release


(1/n) We are drastically overestimating the cost of LLMs, because we sometimes over-focus for single-query speed. Had the privilege to talk about this topic at the #vllm meetup yesterday. An average human reads 350 words per minute, which translates to 5.5 words per second.
Something we're doing differently this time around, we added a #vLLM track to #RaySummit! @vllm_project is one of the most popular inference engines, and is often used together with @raydistributed for scaling LLM inference. Can't wait to hear from these companies about how…
LLMを爆速化する秘訣は「vLLM」!🚀 AIモデルの推論を劇的に高速化し、運用コストも削減する「vLLM」がすごいんです!✨ 個人や中小企業のAIサービス展開を強力にサポート。AI活用がもっと快適になりますよ! #vLLM
#ComfyUI-Molmo お試し。やってる事は単純で画像→VLLM→FLUX.1 dev + Depthで画像生成。肝は #VLLM の #Molmo-7B-D。GPT-4VとGPT-4oの間程度の性能らしい。軽く試したところNSFWもOK。#JoyCaption とどっちが上だろう? #AI美女 #AIグラビア github.com/CY-CHENYUE/Com…


#Cerebras just pruned 40% of GLM-4.6's 355B parameters, and it still codes like a beast. No custom stack needed: runs in #vLLM banandre.com/blog/2025-10/p…


🧑🏼🚀Yesterday we had the First-ever 🍁 Canadian @vllm_project meetup in Toronto! It was a sold-out event with 300 registered attendees🔥, and the energy was absolutely massive 💫. Awesome to see the community come together like this! #vLLM #AICommunity #TorontoEvents @VectorInst

Getting 10x speedup in #vLLM is easier than you think 📈 I just discovered speculative decoding with ngram lookup and the results speak for themselves. Here's what you add to your vLLM serve command: speculative_config={ "method": "ngram", "num_speculative_tokens": 8,…

Don't pay for closed source proprietary solutions that you get for free, with plain old open source. Support those who value honesty and transparency. FP8 #vLLM with @AMD #MI300x






vLLM at Computex 2025. Integrated into Intel Enterprise Gaudi 3 inferencing stack !!!! #vLLM #Computex2025 #IntelAI


#Whisk やってみた。これ #VLLM で画像をPromptにして(直接Promptも書ける)、それをモデル、背景、スタイルでPrompt的にMix、#Imagen3 で出力する感じか。縦、横、正方形に対応。


画像生成 AI をうまく使いこなせなかった方に朗報です! 【Google の最新画像生成 AI『Whisk』が登場】しました!!これできっと作りたかったあんな画像もこんな画像も、作れます!!! ここからどうぞ↓ labs.google/whisk ※一部の機能については、英語でのご利用を推奨しております
#SwarmUI のExtensions、#OllamaVisionExtension (#VLLM)、LM StudioのAPIで動いた!endpointがOpenAI APIとgpt-4o-miniに決め打ちしてたので、コード触ってlocalhostとqwen2-vl-7b-instructに変更。結果はご覧の通り♪ < Assets/ollamavision.js github.com/Urabewe/Ollama…


この #VLLM な #gemma-3-27b-it-qat-q4_0-gguf を使ったChat and 画像生成、実写/3枚目 "what?"で出て来た/2枚目 英文に"手前に雰囲気の合った女性を立たせてください"(27bなので日本語OK) 1枚目。なかなか使える♪ < Caption系だと2枚目は出ても1枚目は手で追加 #AI美女 #AIグラビア
#VLLMな #gemma-3-27b-it-qat-q4_0-gguf (at #RTX3090)を使って画像を解析、そのPromptを使い #FLUX.1 [dev] で画像生成。ほぼ一致♪ #LM_Studio #OpenWebUI huggingface.co/google/gemma-3…
Something went wrong.
Something went wrong.
United States Trends
- 1. Jokic 20K posts
- 2. Lakers 52.4K posts
- 3. #AEWDynamite 47.8K posts
- 4. Epstein 1.57M posts
- 5. Nemec 2,646 posts
- 6. Clippers 12.4K posts
- 7. Shai 15.6K posts
- 8. #NJDevils 2,937 posts
- 9. Thunder 41.2K posts
- 10. #Blackhawks 1,575 posts
- 11. Markstrom 1,069 posts
- 12. Nemo 8,410 posts
- 13. Sam Lafferty N/A
- 14. #Survivor49 3,842 posts
- 15. #AEWBloodAndGuts 5,734 posts
- 16. Ty Lue N/A
- 17. Steph 27.5K posts
- 18. Kyle O'Reilly 2,098 posts
- 19. Darby 5,588 posts
- 20. Rory 7,466 posts