#deepcodesystems 搜尋結果


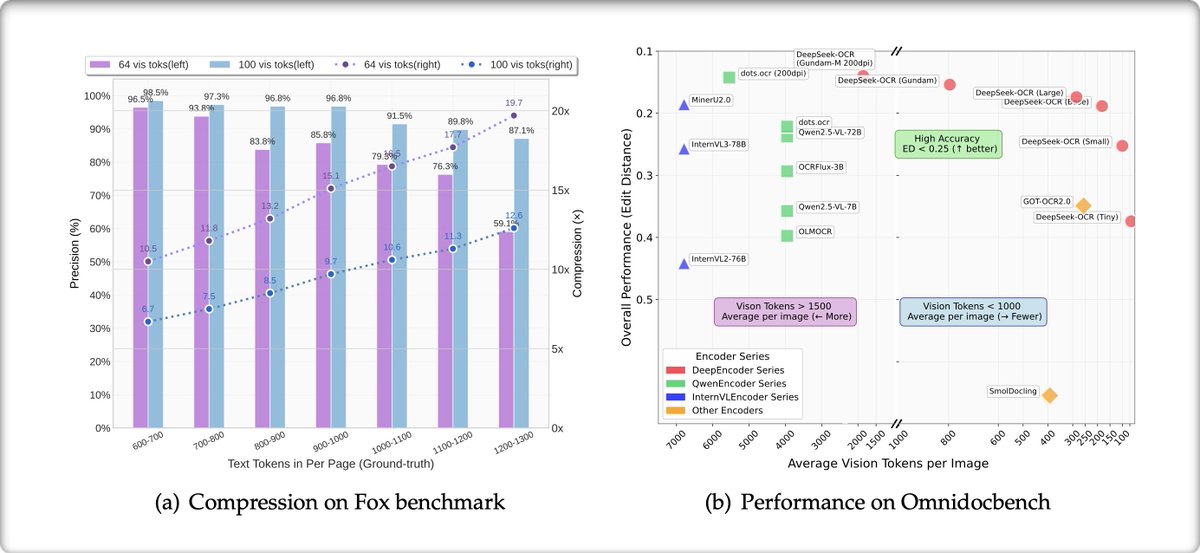
DeepSeek's new OCR paper is one of those ideas that sounds wrong until the graphs say otherwise. They render text as images, feed that into a vision encoder, and somehow get 10x better compression at the same accuracy compared to text tokens. In other words: pictures of words…

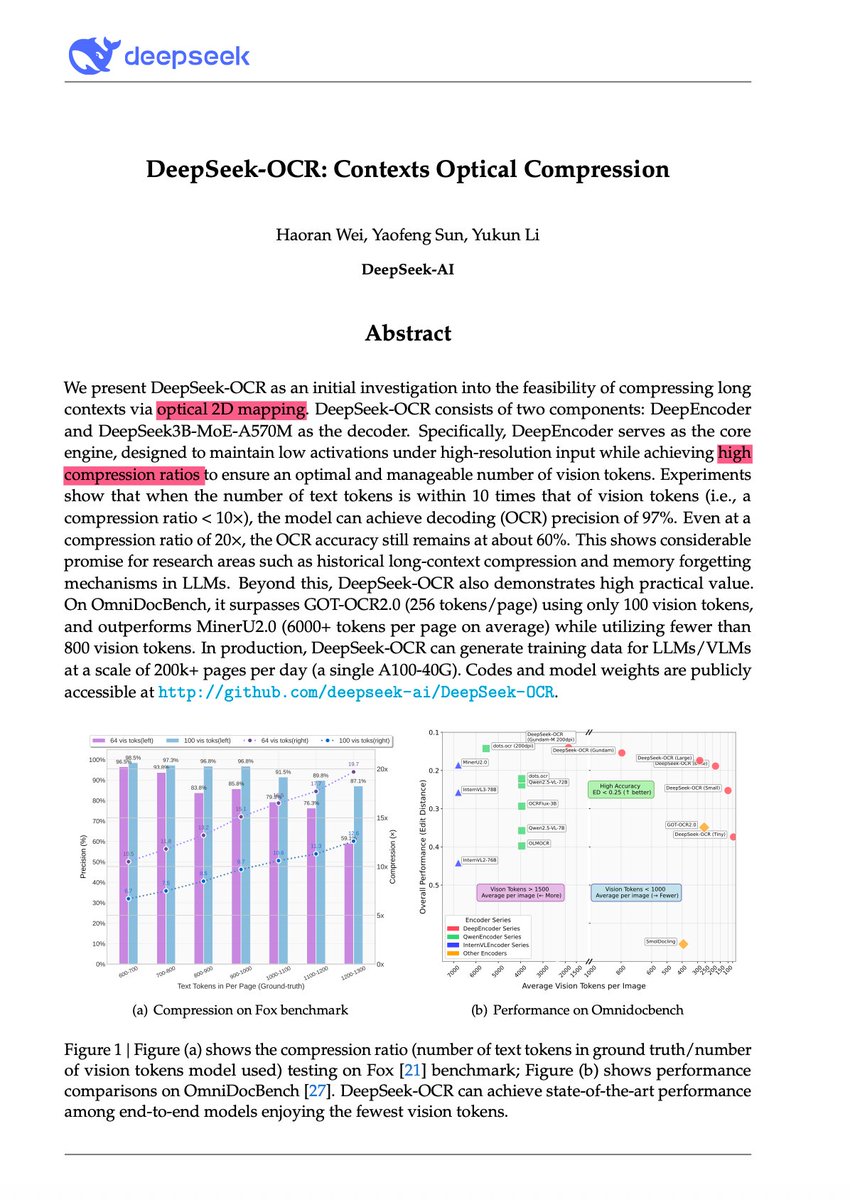
DeepSeek-OCR looks impressive, but its core idea is not new. Input “Text” as “Image” — already explored by: LANGUAGE MODELING WITH PIXELS (Phillip et al., ICLR 2023) CLIPPO: Image-and-Language Understanding from Pixels Only (Michael et al. CVPR 2023) Pix2Struct: Screenshot…
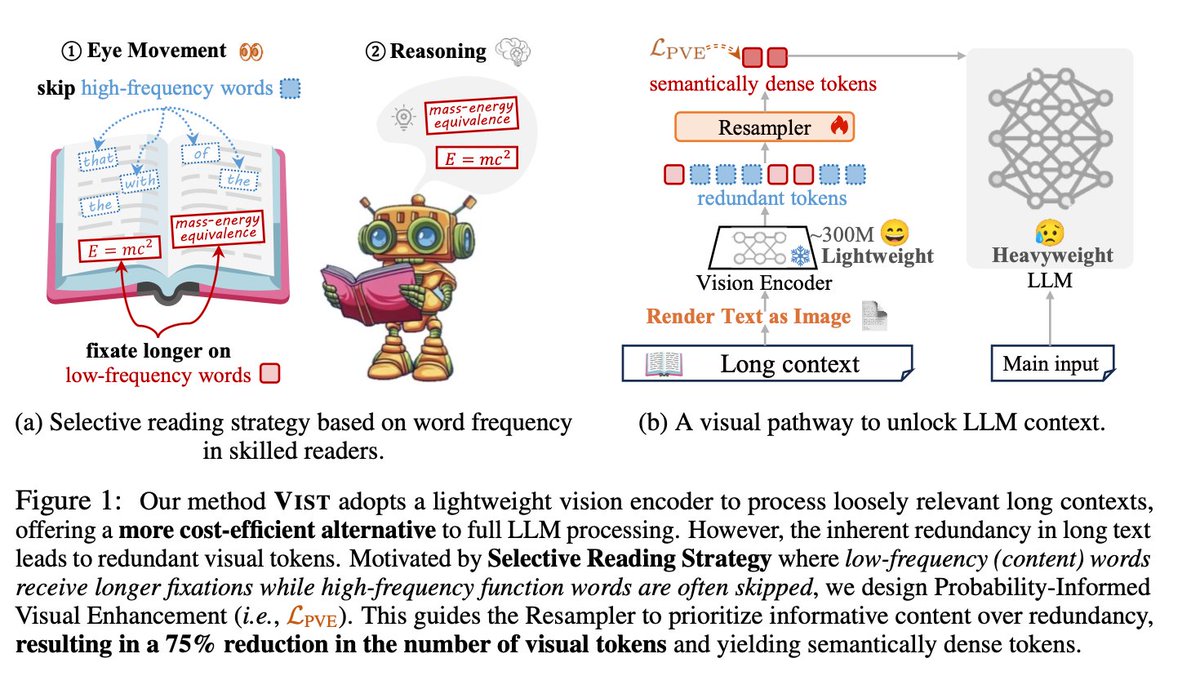

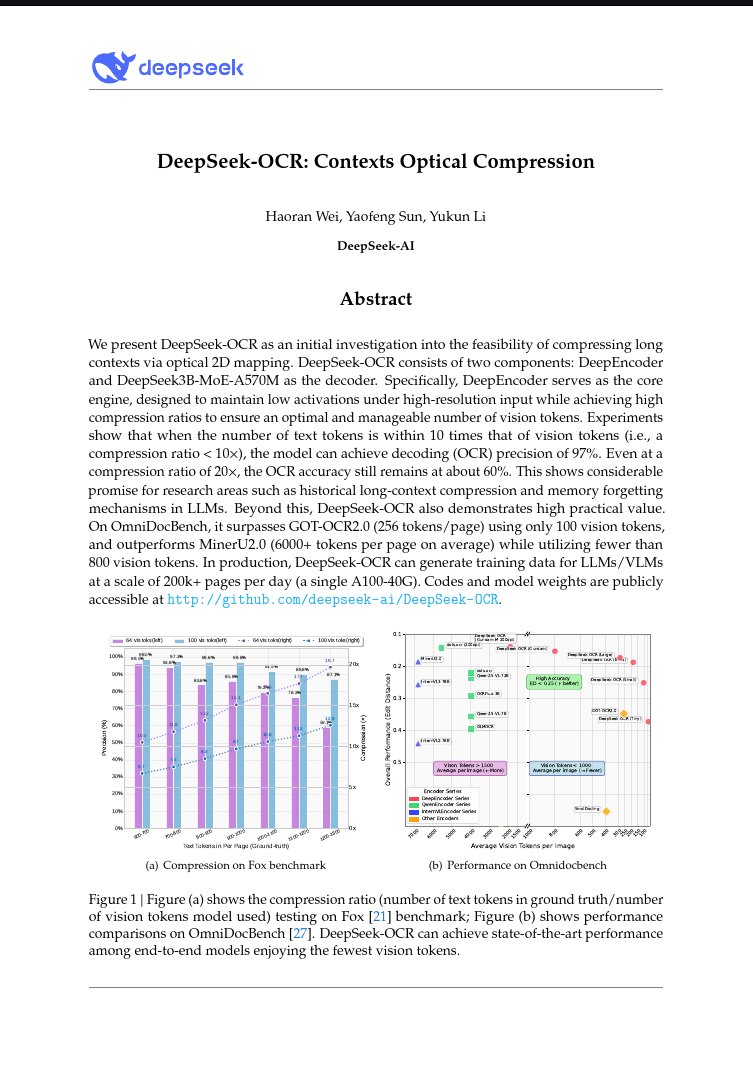
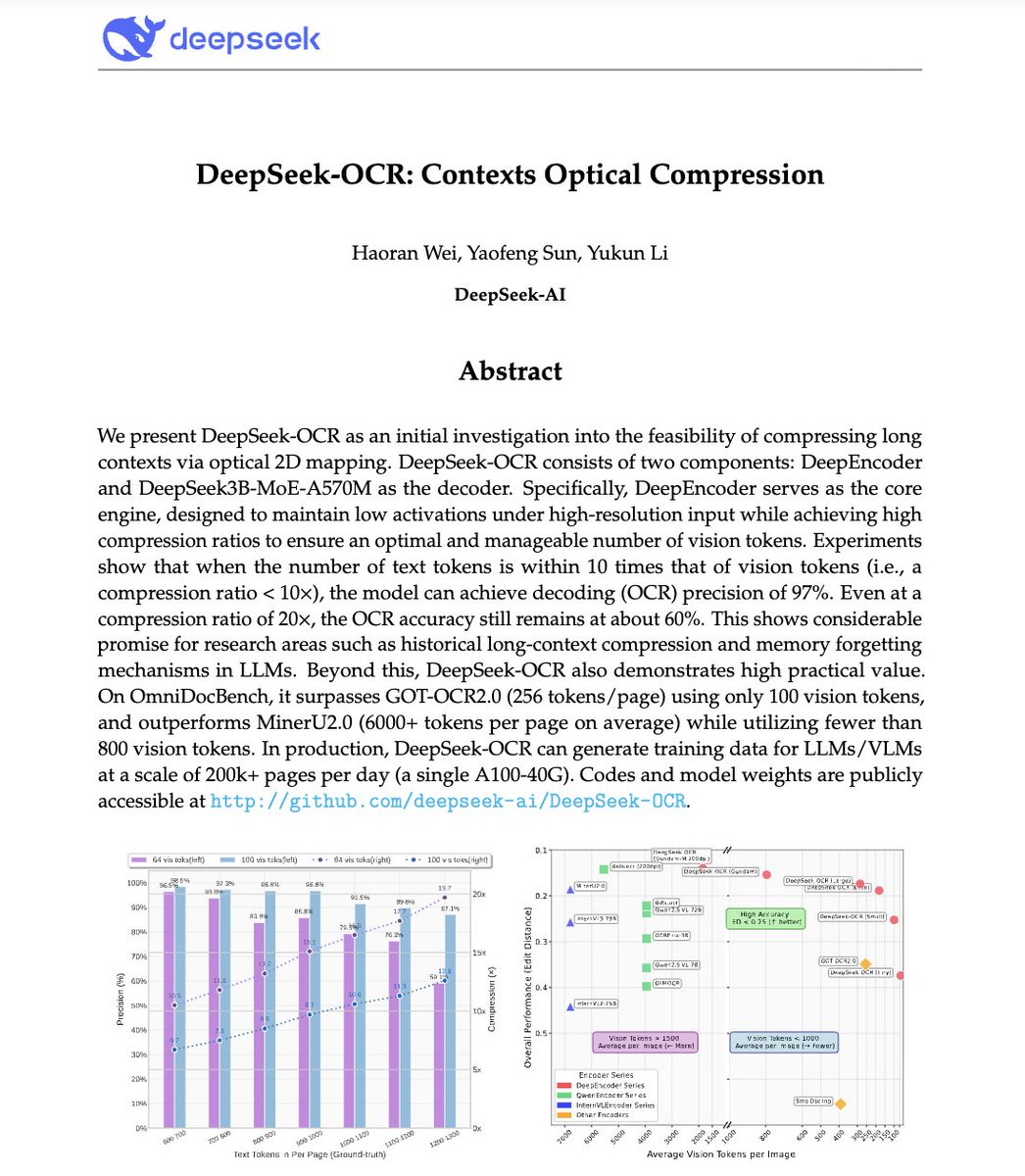
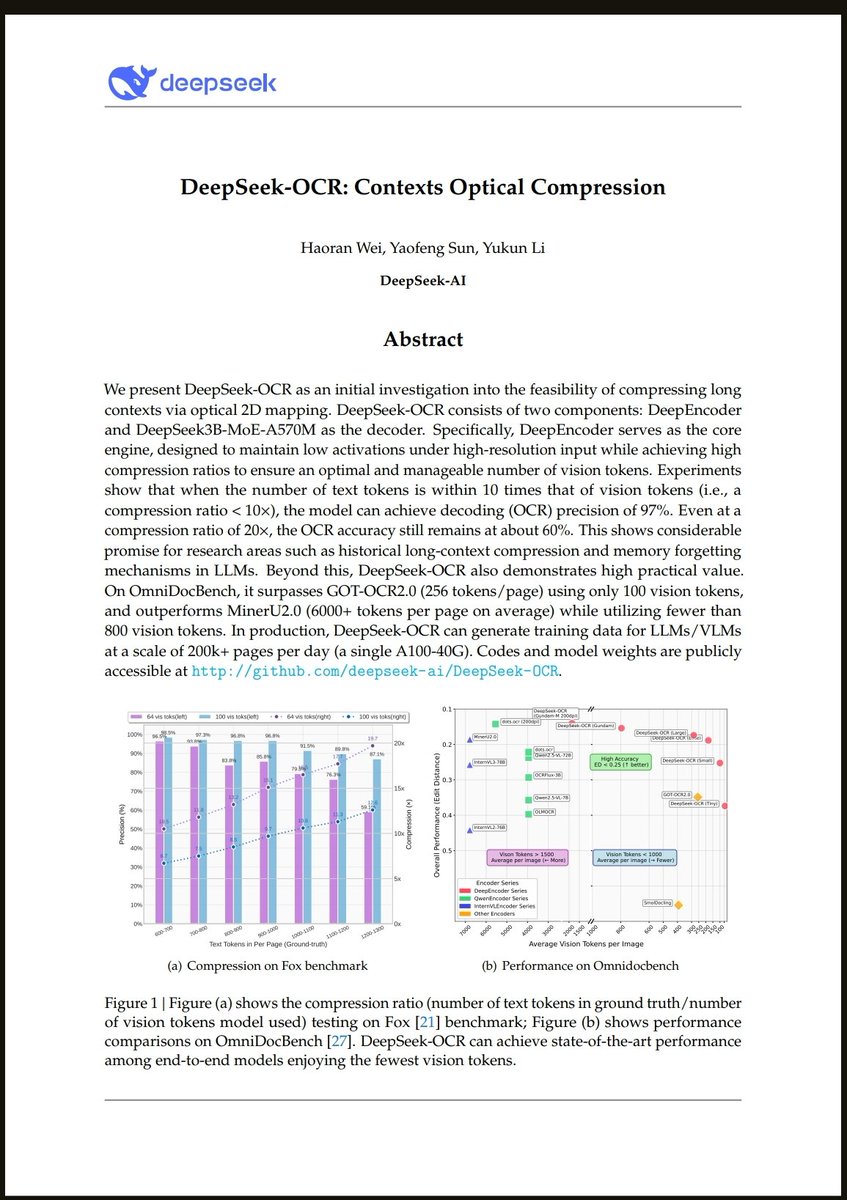
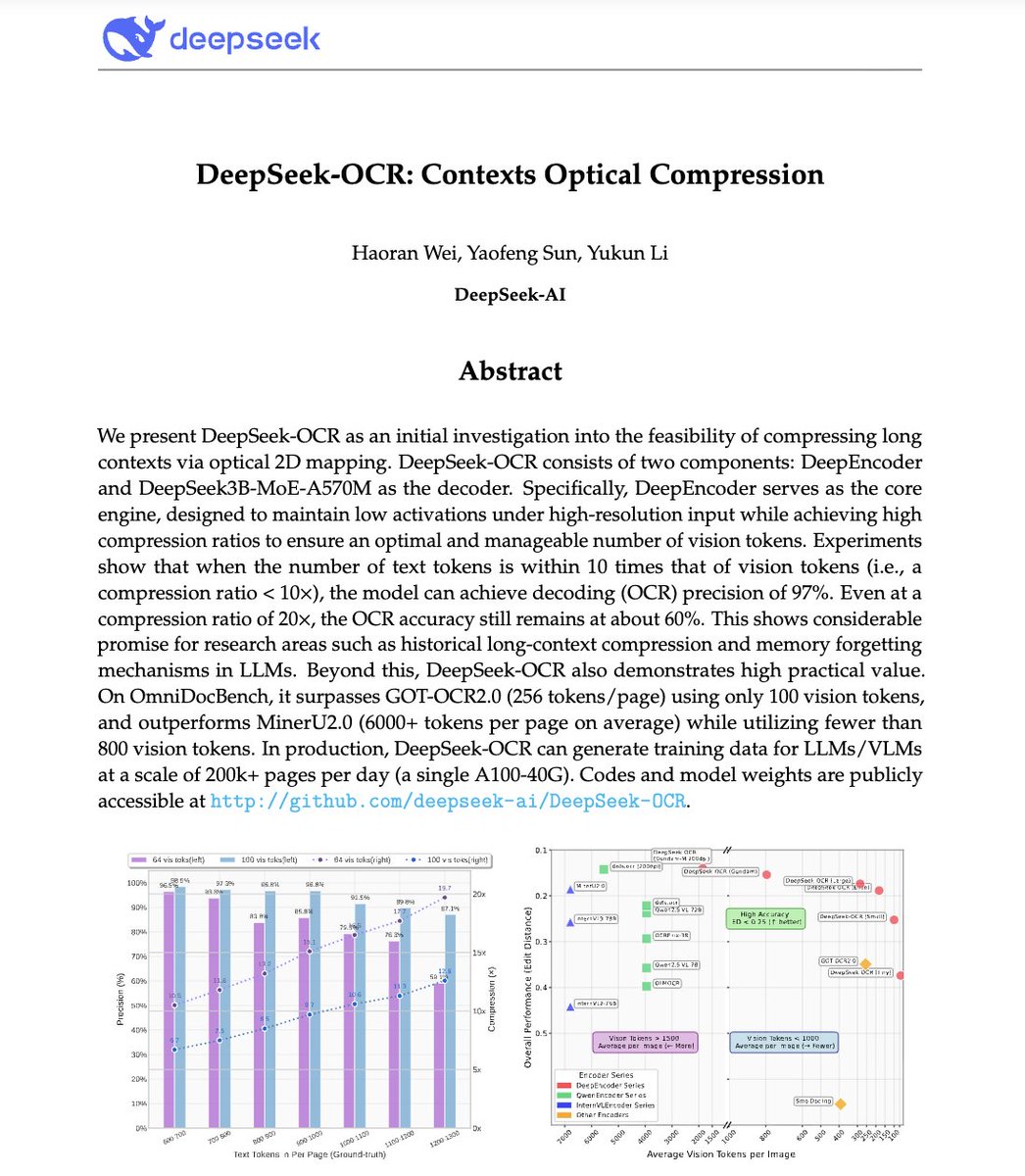
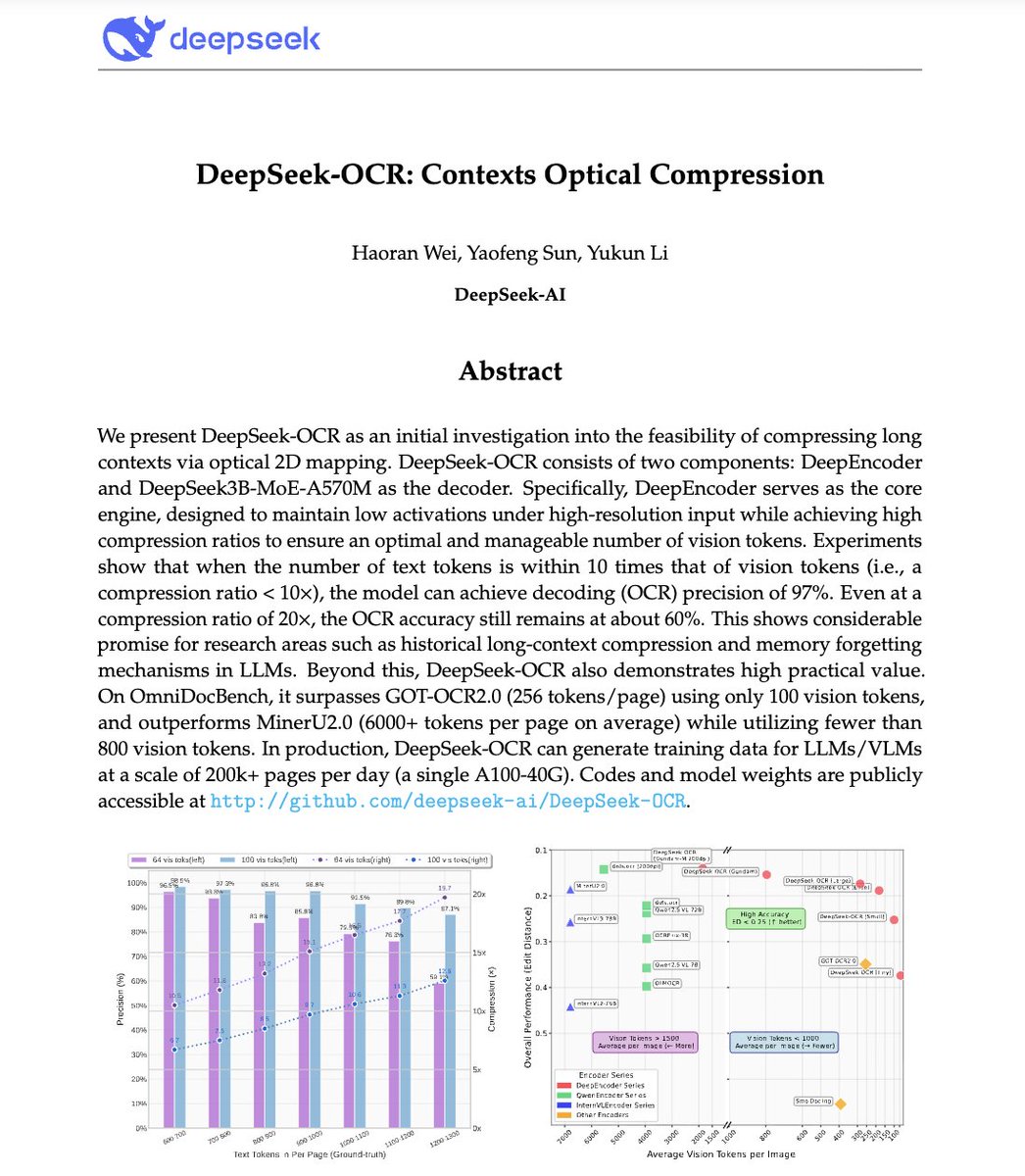
🚨 DeepSeek just did something wild. They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels. Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That…

The DeepNode Solution: We build AI infrastructure that rewards transparency, collaboration and contribution. $DEEP tokens ensure fair earnings for contributors to the intelligence. This is how collective intelligence works. It’s open, transparent and built for everyone.




I asked DeepSeek OCR to convert my long context window to an image for compression and this is what it came up with.




what a bold direction by deepseek once again. they took "a picture is worth a thousand words" literally or the idea of "photographic memory" if i am to commit the crime of anthropomorphisation.

🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support. 🧠 Compresses visual contexts up to 20× while keeping…




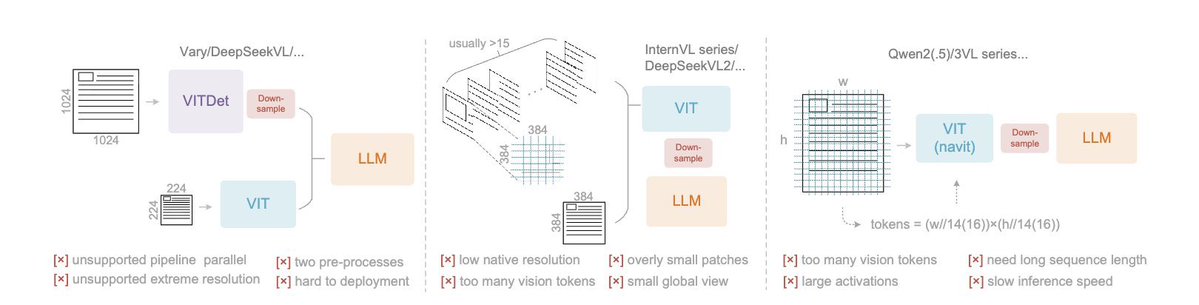
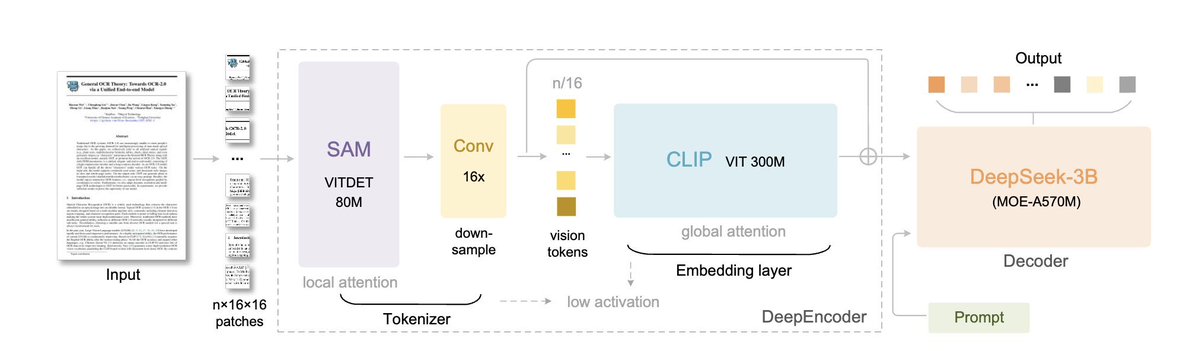
DeepSeek-OCR is out! 🔥 my take ⤵️ > pretty insane it can parse and re-render charts in HTML > it uses CLIP and SAM features concatenated, so better grounding > very efficient per vision tokens/performance ratio > covers 100 languages


🚨 DeepSeek just did something nobody saw coming. They turned text into vision tokens literally compressing paragraphs into pixels. This might be the biggest shift in AI context handling since transformers. Here's the full breakdown 👇

DeepSeek's OCR, Revolutionary Context Compression via Optical 2D Mapping _/ Vision-based compression ... paradigm shift as how LLMs process extensive textual information. _/ Compressing an entire encyclopedia into a single snapshot. deepseek.ai/blog/deepseek-… github.com/deepseek-ai/De…

An all-in-one Agentic Coding Framework! 🤯 DeepCode generates backend, frontend & algorithm code directly from papers, prompts & URLs: ↳ Automated QA: tests, docs, static checks ↳ Multi-agent orchestration ↳ Smart segmentation for long docs 100% open source. Repo in 🧵 ↓


DeepSeek-OCR: Exploring the boundaries of visual-text compression. Ambitious! They might use 10X (near-lossless) compressed vision tokens to replace the KV cache of dialog histories. github.com/deepseek-ai/De…


Google DeepMind just released their image generator: Imagen 2 I compared the outputs to MidJourney and DALL-E 3 Here's the results and look at interesting features. 🧵


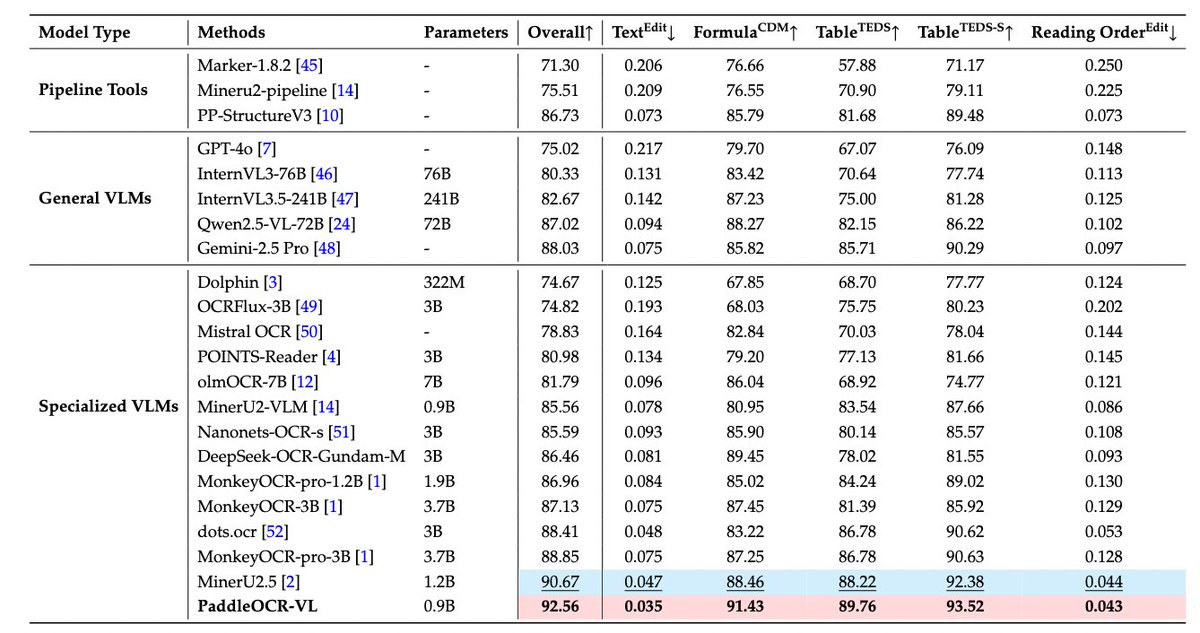
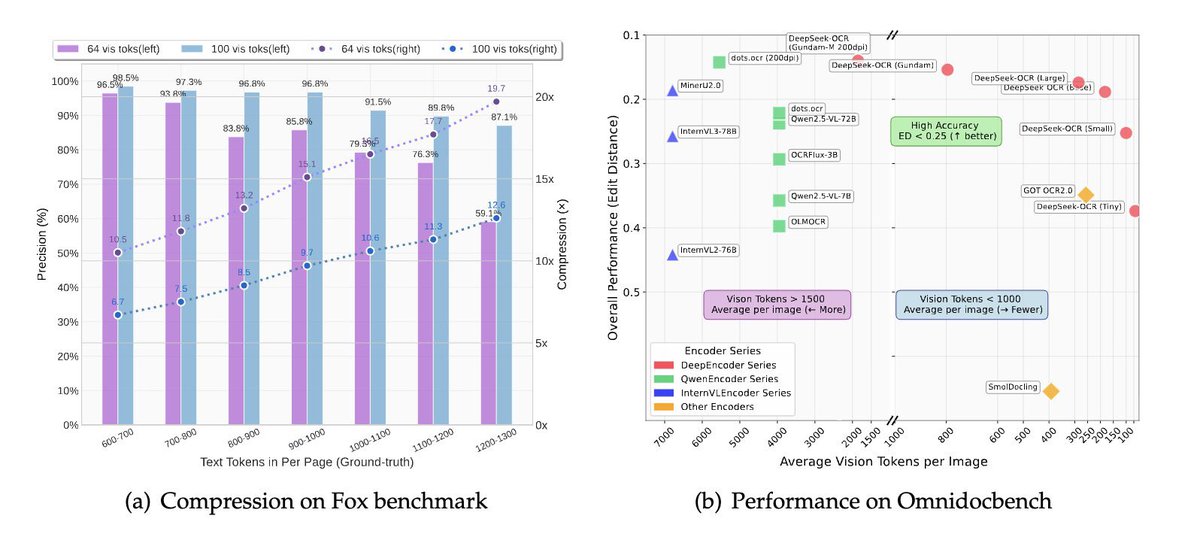
You may refer to this new benchmark with DeepSeek-OCR included

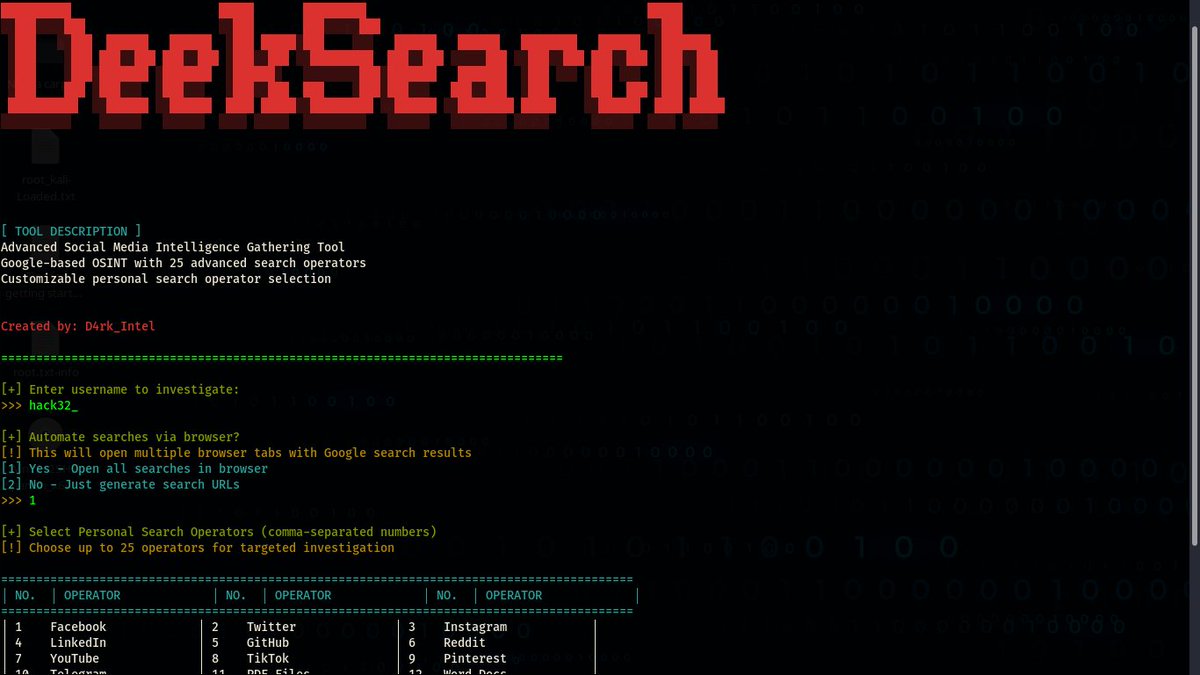
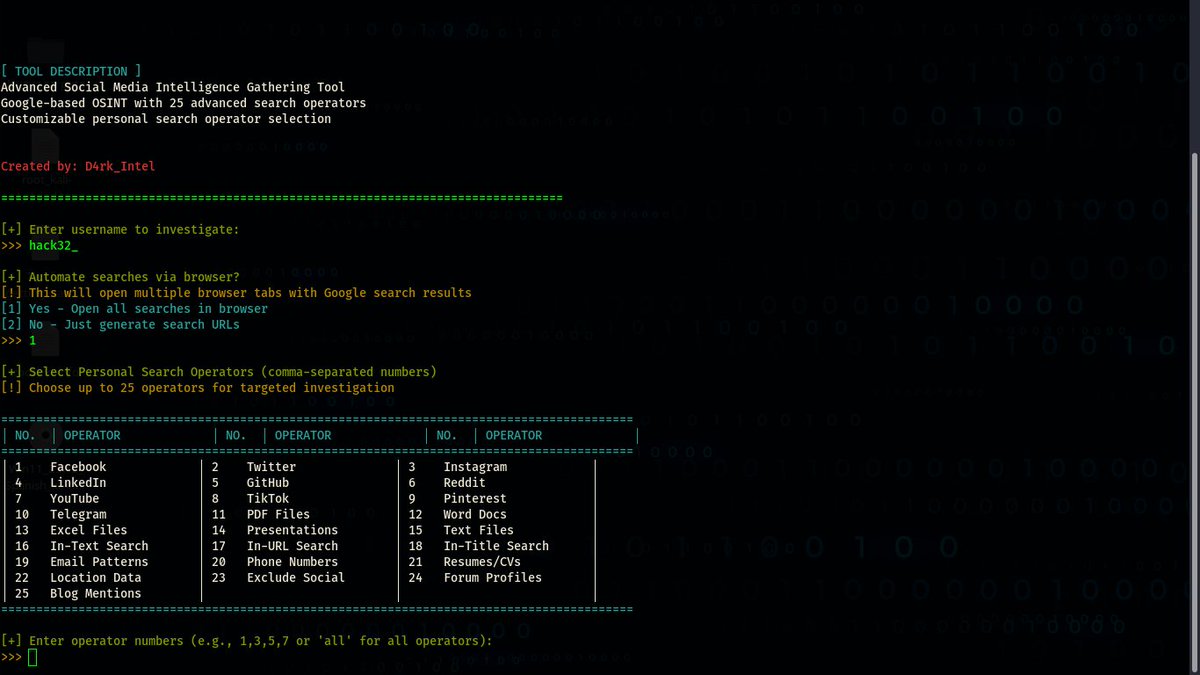
DeepSearch: The (OSINT) tool that reveals anyone's digital footprint, today I decided to try it and I liked it 💻👾 #EthicalHacking #Hacking
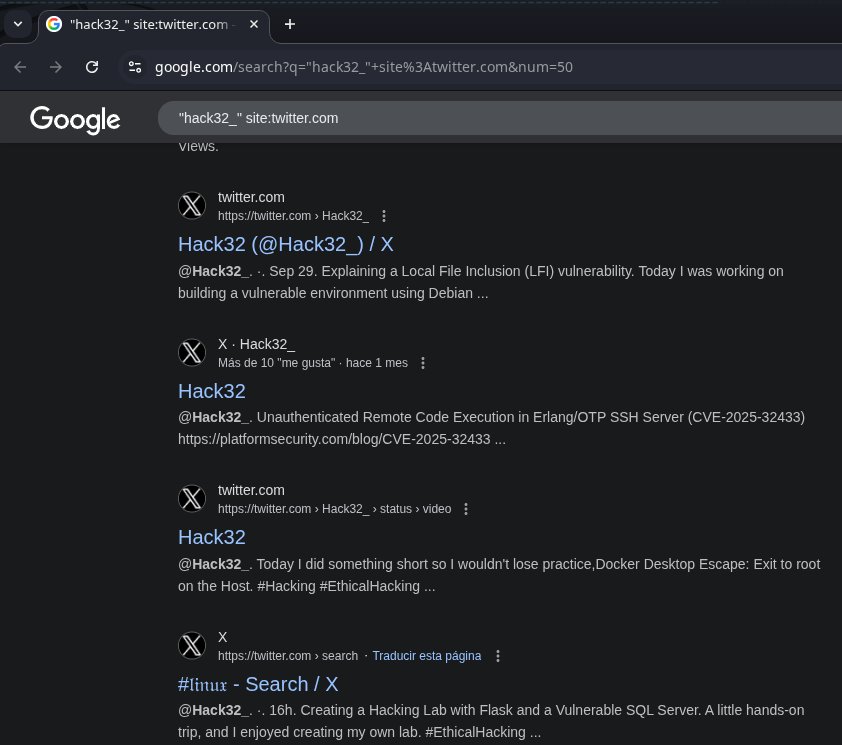

NEW YATCH LOADING - LFG 🔥: DeepSeek has built an OCR system that compresses long text into vision tokens turning entire paragraphs into pixels. The model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That means…


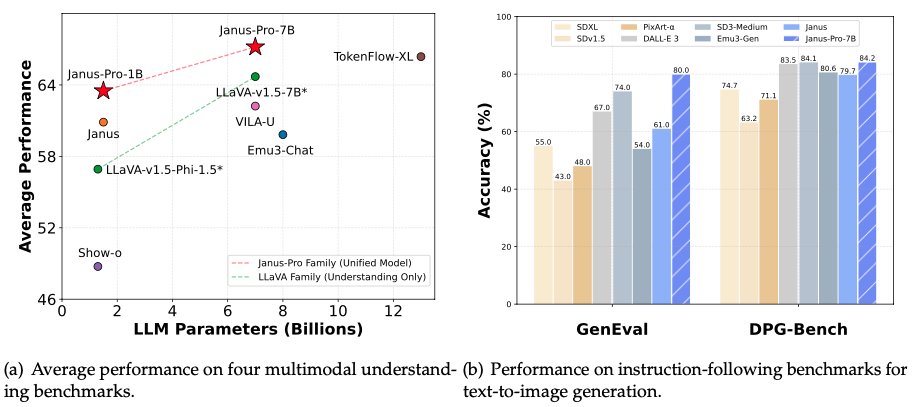
BREAKING: @deepseek_ai DROPS ANOTHER OPEN-SOURCE AI MODEL, WHICH INCLUDES IMAGE GENERATION - JANUS-PRO-7B

🚨 DeepSeek just dropped one of the most important AI papers of 2025. They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels. Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages…
Something went wrong.
Something went wrong.
United States Trends
- 1. #Integra N/A
- 2. White House 393K posts
- 3. Warner Bros 4,346 posts
- 4. NBA IS BACK 21.8K posts
- 5. #pilotstwtselfieday N/A
- 6. Rick Scott 1,563 posts
- 7. #Melissa 1,902 posts
- 8. #JUNGKOOKXCALVINKLEIN 25.7K posts
- 9. #3YearsOfMidnights N/A
- 10. $VWA 3,043 posts
- 11. Good Tuesday 35.8K posts
- 12. Talus Labs 15.5K posts
- 13. Taco Tuesday 12.7K posts
- 14. East Wing 97.5K posts
- 15. CARAMELO ON TLMD 18.5K posts
- 16. Cobie 47.8K posts
- 17. Gucci 29.2K posts
- 18. Cuomo 75.3K posts
- 19. Joe Carter 3,723 posts
- 20. Anthony Thompson N/A