#languagedata resultados de búsqueda

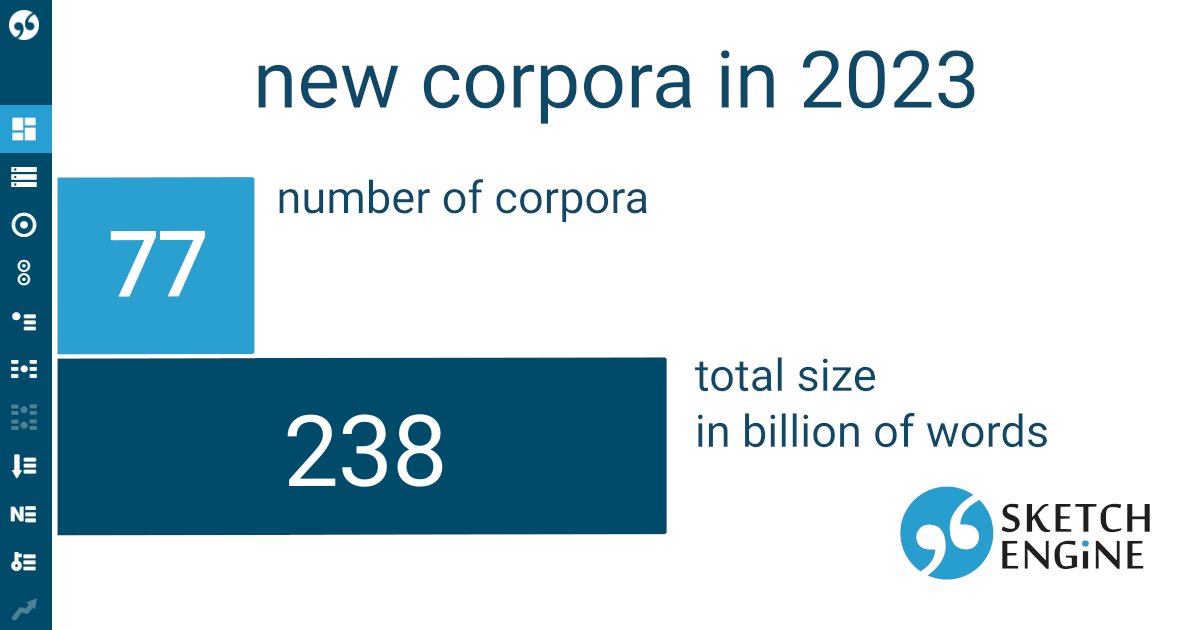
Also in 2023, we extended our list of corpora. So we're now reaching almost 800 corpora in total. The largest corpus: English Web 2021 with 52 billion words. New languages: Assamese, Bashkir, and Northern Kurdish. sketchengine.eu/corpora-and-la… #corpuslinguistics #LanguageData
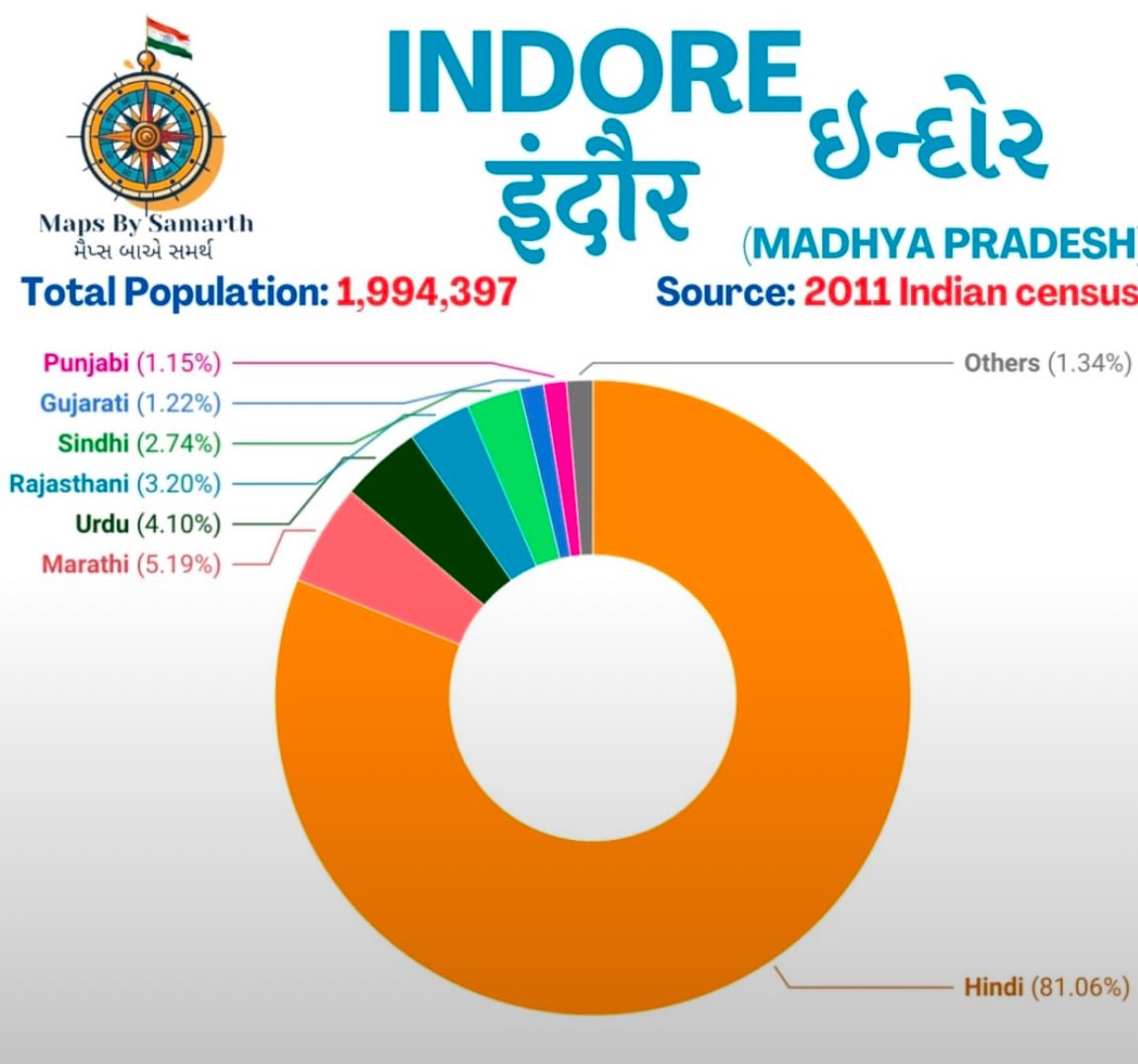
Gujarati 🇮🇳, the official language of the Indian state Gujarat, spoken by about 55 million people. Linguists and lexicographers now have a new resource annotated with PoS tags and stems (root forms of the words). 🌐 sketchengine.eu/gutenten-gujar… #corpuslinguistics #LanguageData


🔊 Join us on Dec 9 in Athens for the European Language Data Space Workshop on language data & AI for Greek! 📍 Hosted by #AthenaRC & ILSP at the Ministry of Digital Governance 🔗 Register now: bit.ly/4i4kAfp #LanguageData #GreekLLMs #ArtificialIntelligence #LDS #ILSP


🧠 Day 2 at @LDKconference 2025 packed with insight! 🎤 Invited talk by @RNavigli (Sapienza) on #semantics & #AI 💡 Plus diverse sessions on #LanguageData, #NLP & #KnowledgeGraphs #LDKconference @jor_gracia





Céard dhó a sheasann 𝗲𝗦𝗧Ó𝗥, go litriúil? 🤔 What does 𝗲𝗦𝗧Ó𝗥 stand for, literally speaking? 🔎 #gaeilge #languagetechnology #languagedata #dataprocessing


Cad is sonraí teanga ann? What is language data? ✍ 🤯 #gaeilge #languagedata #languagetechnology #lds



Cad chuige ar mhaith linn go roinnfeá do shonraí teanga? Why would we like you to share your language data? #gaeilge #languagedata #adaptcentre #LDS







🔊Join the next European @LanguageDataSpace workshop, taking place in Croatia👉language-data-space.ec.europa.eu/events/lds-cou… 🗓️17 Oct 🕤9:30 CEST 🎯Join experts from the Croatian Industry, #PublicAdministration & Research to discuss the importance of #languagedata for #LanguageTechnologies. #AItools


The Urdu ghazal, a distinct literary tradition dating back to the 17th century, remains popular today, with a canon spanning classical and contemporary works including that of renowned poets like Mirza Ghalib and Parveen Shakir. #worldurduday #languagedata #poetrytwitter

How to upload data on estor.ie Conas sonraí a uaslódáil ar ? . #gaeilge #languagetechnology #languagedata #dataprocessing


🎉 The wait is over: the main program of #LDK2025 starts today! Workshops set the tone yesterday, and now it’s time for keynotes, papers & connections. 📍Naples, Palazzo Corigliano | 🗓️ 10-11 September Let’s go! #LDKconference #LanguageData #KnowledgeGrah #NLP @jor_gracia





Organisations outside Nigeria are also participating in the @nldstc. Come and listen to Orla of @L10nLab and Amir of TAUS @T21Century on the session on community participation in #languagedata: Human, Community, and Collaboration in Human Language Project - Why get involved?


📣CLARC2023 "Language and Language Data"📣 Join us in Rijeka, Sep 28 to 30 in the discussion on the developments in the field of #language and #languagedata. CLARC is organized by CLARIN Croatia, @DariahHr and the Center for #LanguageResearch. bit.ly/3XGMdQm

🎉@LangDataSpace has just been launched, aiming to establish a European platform & marketplace for the collection, creation, sharing & re-use of multilingual/modal #LanguageData. #ILSP #AthenaRC will design & implement the LDS as a federated space. More👉bit.ly/3YeqBe9

What does eSTÓR stand for? 🤔 Céard dhó a sheasann eSTÓR? 🤔 estor.ie ⠀⠀ ⠀⠀ ⠀⠀ ⠀⠀ ⠀⠀ ⠀⠀ #gaeilge #languagetechnology #languagedata #dataprocessing



Ready to master Hindi, Tamil, Telugu, and more with data-driven insights? Try the new Live Speech Analytics on Indilingo today! indilingo.in/download
indilingo.in
Download Indilingo App | Learn Indian Languages with AI
Download the Indilingo app and explore 15+ Indian languages with AI-powered lessons, interactive quizzes, and pronunciation feedback.

✨ New OASIS Summary! ✨ ▶️How pre-service and in-service language teachers view AI's linguistic bias and its role in the curriculum oasis-database.org/details/w87kmx…
✨ New OASIS Summary! ✨ ▶️Japanese teachers’ judgments on which English words students should learn and how well oasis-database.org/details/f62z7n…
✨ New OASIS Summary! ✨ ▶️How to accurately measure the development of syntactic complexity of spoken L2 Chinese oasis-database.org/details/b3sqqe…

FYI: November 2025 Newsletter - LDC: In this newsletter: Join LDC for membership year 2026 Spring 2026 data scholarship application deadline New publications: AnnoDIFP CTS Audio and Transcripts LORELEI Ilocano Incident Language Pack… dlvr.it/TPL3vQ

In this episode, Alexandra Feeley discusses two critical data projects: - Optimizing the only monolingual Indonesian dictionary (a huge win for UX 🇮🇩). - Building a new Sensitivity data set to tell "sensitive" language ( for brand safety). Apple Podcasts:…

Vulgar Remarks Detection in Chittagonian Dialect of Bangla! #BigData #Analytics #DataScience #AI #MachineLearning #NLProc #LLM #IoT #IIoT #PyTorch #Python #RStats #TensorFlow #Java #JavaScript #ReactJS #GoLang #CloudComputing #Serverless #DataScientist #Linux #Programming #Coding…





Natural Language Processing: Turning Words Into #Data;Natural Language Processing (NLP) has long been one of the holy grails of computer #science. While we all know that computers are better tha 7wdata.be/big-data/natur… #7wData #DataStrategy

🔊 Join us on Dec 9 in Athens for the European Language Data Space Workshop on language data & AI for Greek! 📍 Hosted by #AthenaRC & ILSP at the Ministry of Digital Governance 🔗 Register now: bit.ly/4i4kAfp #LanguageData #GreekLLMs #ArtificialIntelligence #LDS #ILSP

4/4 Finally, in “Is the Development of #Vocabulary in Spanish (L2) possible after a Study Abroad Experience in a Multilingual Environment?”, Àngels Llanes & Gloria Vázquez show a reduction in non-Spanish vocabulary use post-SA 📉🗣️, with a slight rise in semantic proximity errors


Different languages measure things differently. Some languages will use body parts, while others will have completely different metric systems. Dive in here: medium.com/language-lab/t… #linguistics 🐦🐦 #language #languagelearning #writing #writingcommunity #languages #Dataviz
How are numbers viewed and expressed in different #languages. Discover how the language you speak affects how you count things. Full story here: medium.com/language-lab/t… #linguistics 🐦🐦 #language #languagelearning #writing #WritingCommunity #Languages

You'd think numbers would be universal across cultures. But different #languages use different numeral systems, have different number bases, and different grammatical for numbers. Full story here: medium.com/language-lab/t… #linguistics #language #languagelearning #writing

That’s so meta! Thinking about their lg learning journeys, my secondary multilingual learners reflect on their speaking, using tools I’ve based on the impressive @WIDA_UW language charts! Feel free to use- #esl #ml #LanguageLearning docs.google.com/document/d/1Zg…

(Multilingual Interactions with Norm-Driven Speech), a bilingual dataset comprising 31 multi-turn Mandarin-English and Spanish-English conversations. Each turn is annotated for norm category and adherence status using multi-annotator consensus, (Cont'd)

In their new piece, @HAdarkar, Senior Fellow and Sridhar Ganapathy, Principal at @Artha__Global examine why India’s linguistic diversity requires a fundamentally different approach to AI development. With 22 official languages and hundreds of dialects, India cannot depend on the…

Structural correlates for lexical efficiency and number of languages in non-native speakers of English documentsdelivered.com/source/021/793…


Also in 2023, we extended our list of corpora. So we're now reaching almost 800 corpora in total. The largest corpus: English Web 2021 with 52 billion words. New languages: Assamese, Bashkir, and Northern Kurdish. sketchengine.eu/corpora-and-la… #corpuslinguistics #LanguageData

Philippe Gelin @phgelin présente la plateforme CEF #eTranslation utilisable en ligne par les services publics des Etats membres 🇪🇺 et intégrable à leurs processus de traduction. #languagedata @translatores @LR_Coordination


How popular is your language on @Wikipedia? Jofre Espigule explores #Wolfram's #LanguageData functionality on #WolframCommunity: wolfr.am/C5FpEtU7

Gujarati 🇮🇳, the official language of the Indian state Gujarat, spoken by about 55 million people. Linguists and lexicographers now have a new resource annotated with PoS tags and stems (root forms of the words). 🌐 sketchengine.eu/gutenten-gujar… #corpuslinguistics #LanguageData


We are offering a free interactive presentation on the @OED Researcher API tomorrow. It will cover the Text Visualizer, Etymology visualization tool, and future OED Labs plans. Register here: ow.ly/4xnE50CAhTX #Research #LanguageData


Have you seen #Ethnologue's updated list of the top 200 most spoken languages in 2022? 🗣️ Check it out: ow.ly/htx650JK3F3 #LanguageData | #LanguagesMatter


I ❤️ that our @UBCLibrary data repository, Abacus, has a twitter feed (bot) @ResearchDataUBC. Check out the language datasets from the Linguistic Data Consortium that we added recently, @UBCLinguistics! #linguistics #languagedata #corpora

🧠 Day 2 at @LDKconference 2025 packed with insight! 🎤 Invited talk by @RNavigli (Sapienza) on #semantics & #AI 💡 Plus diverse sessions on #LanguageData, #NLP & #KnowledgeGraphs #LDKconference @jor_gracia
Cad is sonraí teanga ann? What is language data? ✍ 🤯 #gaeilge #languagedata #languagetechnology #lds
Céard dhó a sheasann 𝗲𝗦𝗧Ó𝗥, go litriúil? 🤔 What does 𝗲𝗦𝗧Ó𝗥 stand for, literally speaking? 🔎 #gaeilge #languagetechnology #languagedata #dataprocessing
🎉@LangDataSpace has just been launched, aiming to establish a European platform & marketplace for the collection, creation, sharing & re-use of multilingual/modal #LanguageData. #ILSP #AthenaRC will design & implement the LDS as a federated space. More👉bit.ly/3YeqBe9
📣CLARC2023 "Language and Language Data"📣 Join us in Rijeka, Sep 28 to 30 in the discussion on the developments in the field of #language and #languagedata. CLARC is organized by CLARIN Croatia, @DariahHr and the Center for #LanguageResearch. bit.ly/3XGMdQm


What do you really know about #languagedata? Do you realise that you have loads of it, floating around in space, not being used? 🪐👩🚀🚀 Come on a space mission with us - bit.ly/2XkiyQI ☄️


Insatiable Appetite for Language Data a Boon for Niche Providers bit.ly/2QaPw3N #Languages #VoiceSearch #LanguageData #LSP

Something went wrong.
Something went wrong.
United States Trends
- 1. #AEWDynamite 19K posts
- 2. #AEWCollision 7,230 posts
- 3. #CMAawards 4,676 posts
- 4. Philon N/A
- 5. #Survivor49 3,257 posts
- 6. Donovan Mitchell 3,720 posts
- 7. #cma2025 N/A
- 8. Dubon 3,286 posts
- 9. Simon Walker N/A
- 10. Nick Allen 1,960 posts
- 11. Okada 12K posts
- 12. UConn 7,716 posts
- 13. Lainey Wilson N/A
- 14. Derik Queen 1,673 posts
- 15. Bristow N/A
- 16. Cavs 8,374 posts
- 17. Arizona 31.7K posts
- 18. Morgan Wallen N/A
- 19. FEMA 53.9K posts
- 20. Andrej Stojakovic N/A