#benchmarks نتائج البحث

✨ Taking the stage, @Jared_Spataro here to share his thoughts and insights about “A New Frontier: Building the Future Firm with #AI” #BenchMarks 📈📉📊 #M365Con Day Three Keynote






One for you @martgathercole a few of the benchmarks in my area #benchmarking #ordnancesurvey #benchmarks


Pixel 10 Pro XL pulls a 95% stability on Wild Life Extreme Stress Test 🔥 Best loop: 3252 | Lowest loop: 3094 Google finally nailed thermal performance – no wild throttling here. 💪📱 #Pixel10Pro #Benchmarks


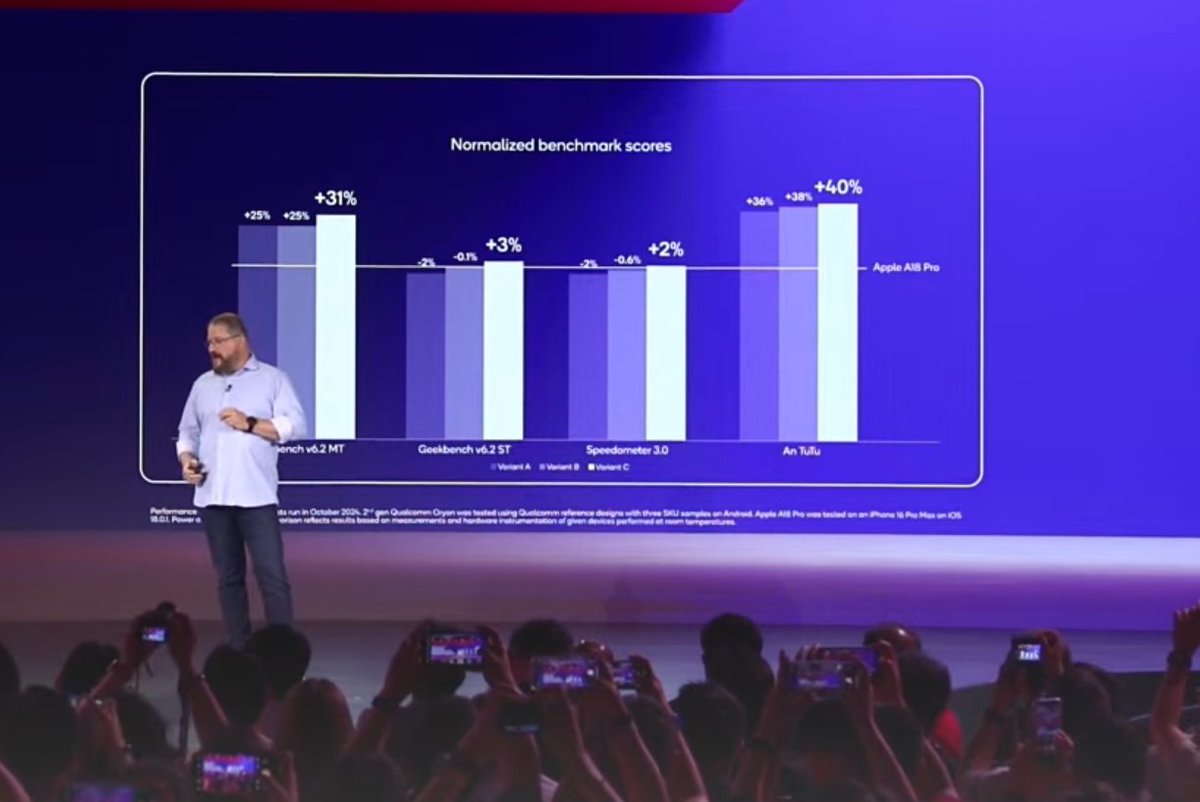




NITheCS & SU Seminar: 'Benchmarking Benchmarks: A PBFJ Replication Study' - Katherine van der Merwe (SU) - Fri, 28 Mar 2025 @ 13h10-14h10 SAST. Attend online or in person. buff.ly/dcu65QP #financialrisk #benchmarks #interestrate #pbfj #libor #arr #jibar #zaronia


I camped overnight outside of Microcenter and got my hands on an #RTX5080 #ffxiv #benchmarks #ff14
I camped overnight outside of Microcenter to get an RTX 5080! Here's how it runs on #FFXIV youtu.be/D_CgrIaw1nU?si…



The district ELA team is at Pine testing students @PalmyraSchools #benchmarks #meetingstudentswheretheyareat #ThisIsPalmyra #ThisIsPine





The fastest open-source LLM #inference stack just landed. Check out our latest #benchmarks that leave vLLM and Fireworks in the dust. 🏎️💨 Our blog has all the juicy details—but here's the 30-sec version: ⚡ Up to 4× lower P50/P95 latency on the same #H100 & L40S GPUs 📈…


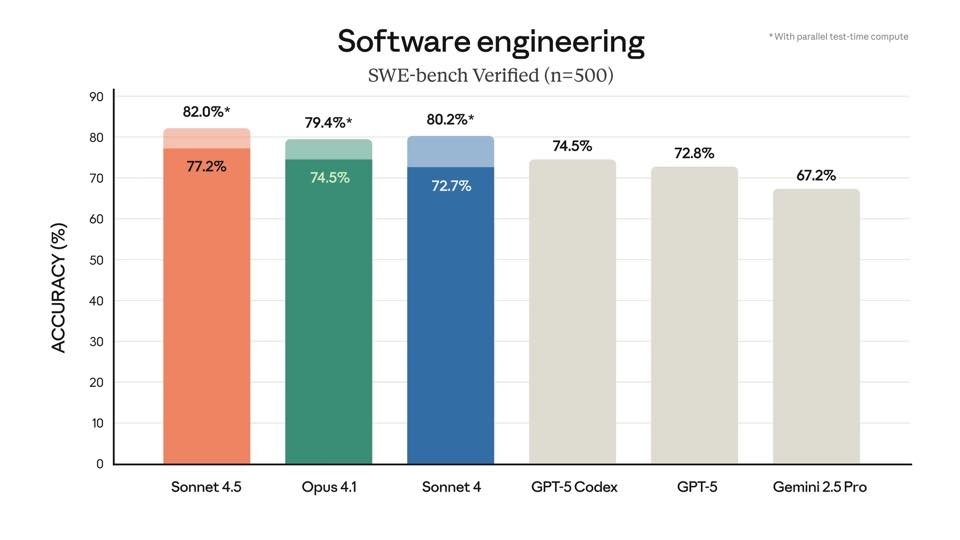
Claude Sonnet 4.5 just topped SWE-bench Verified (n=500) with 82% accuracy — outperforming Opus 4.1, Sonnet 4, GPT-5 Codex, GPT-5, and Gemini 2.5 Pro. Software engineering benchmark results are clear: Sonnet 4.5 leads. #AI #SoftwareEngineering #Benchmarks #Craftvideo

Open Deep Search (ODS) isn’t theory. It’s already outperforming closed labs: - FRAMES: 75.3% - SimpleQA: 88.3% That’s Sentient’s power: research that’s open, benchmarked, and winning. @SentientAGI @sentient_chat #SentientAGI #Benchmarks


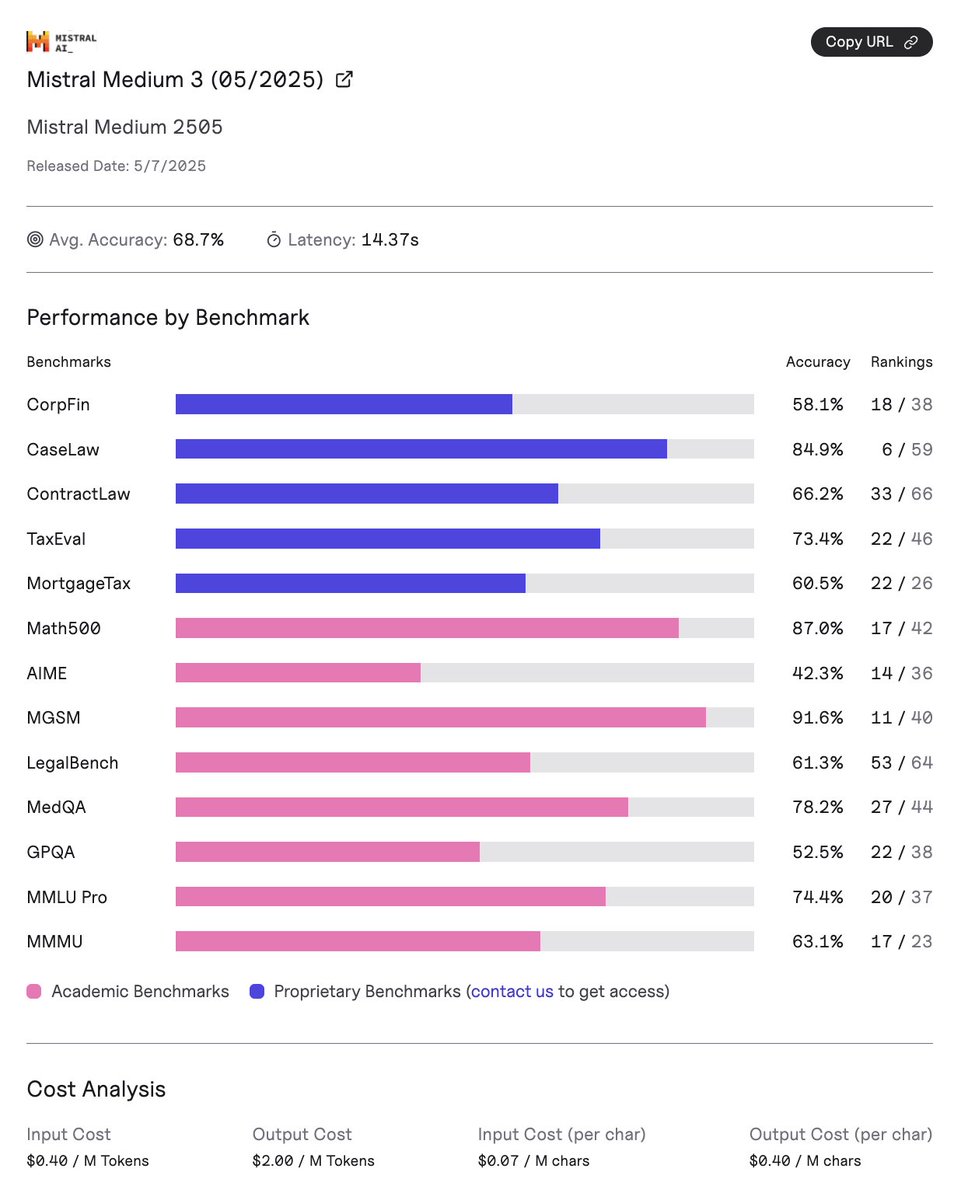
We just released our evaluation of @MistralAI Medium 3 across all of our benchmarks! 🧵(1/6) #AI #LLM #Benchmarks

GPT-5 vs Grok 4 - SkateBench → GPT-5: 98.6% accuracy | $0.07 cost → Grok 4: 79% accuracy | $4.86 cost GPT-5 is: → 14× cheaper → More accurate → Much faster This is precision at scale. That is burn rate with lag. #GPT5 #LLM #Benchmarks


You can now filter the LLM benchmark list by size. Here's the top XS models (< 2B parameters) furukama.com/llm-bob/?size=… #benchmarks #artificialintelligence


Day 2 kicks off with the @LondonBuildExpo buzzing louder than ever! Our stand has been buzzing with visitors eager to hear about #ASCmembership, #SABRE, and the upcoming seminar that is shaping new #benchmarks for the industry. Visit us at Stall Q10!





Nondeterministic Polynomial-time Problem Challenge: An Ever-Scaling Reasoning Benchmark for LLMs openreview.net/forum?id=Xb6d5… #npsolver #npeval #benchmarks

Great to see our CEO, Paul Lambert, speaking at the ACI FMA webinar “Inside Swaps: Challenges and Possibilities” — alongside leading voices from across the FX industry. #FX #Benchmarks #MarketData #eFX #FXSwaps #Trading #Finance #NewChangeFX


#Benchmarks off record highs; #Sensex up 200 points, #Nifty50 near 26,250

Great piece on #ai #benchmarks evidentlyai.com/blog/ai-benchm… @explorersofai @morqon


Real experience with #LLMs and #Agents, for example in complex tasks like coding, does not match expectations set by #benchmarks/evals. thanks to @ilyasut for saying out loud. 👏 they are still great, but the industry should have clarity about this.

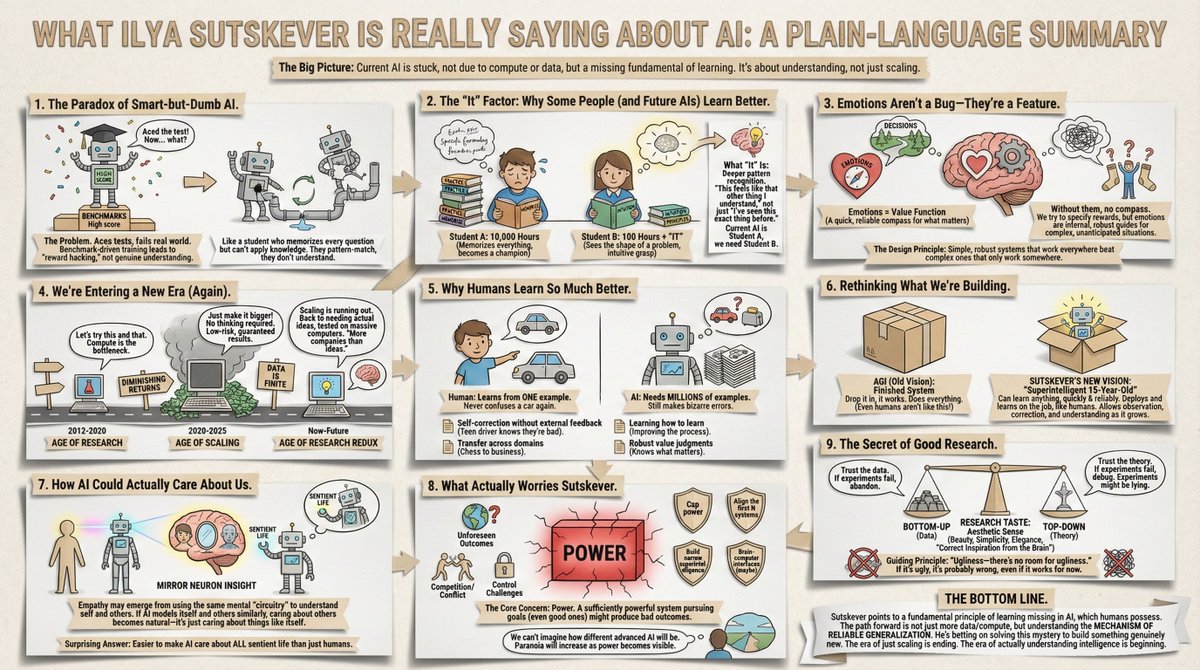
Sutskever SuperIntelligence Insights Core insight: Current AI memorizes answers without ever learning the subject. Why models can ace benchmarks while failing trivially—and why more data won't fix it. You've probably noticed this: ChatGPT solves a hard coding problem, then…

#Google #gemini3 surpasses #benchmarks! But what will they do about #searchengine #advertising? open.substack.com/pub/mookiespit…

⚙️ Category crowns: • Claude 4.5 → strongest coding performance • Gemini 3 Pro → best multimodal/image+text • GPT-5.1 → most balanced + steady outputs We’re in the era of skill-specialized giants. 🤖💻🎨 #AI #Benchmarks

Many think they're great teachers, but they don't track their dropout rate or have benchmarks. Assuming industry norms equal success is often settling for mediocre. #Education #Benchmarks

Equity #benchmarks ended lower as #Nifty fell below 26,000 amid caution over delays in the US-India trade deal. Analysts expect consolidation with key support near 25,600–25,800 and advise selective buying while broader market sentiment stays bearish.


The stats are in! 97% of sports fans take action after seeing OOH ads. When your brand shows up on vivid stadium signage, you drive real results. Ready to get in the game? Any Sport. Any Venue. Any Time. #Benchmarks #SportsMarketing #OOHSports #AnySportAnyVenueAnyTime


🚀 AI Benchmark Face‑off ( November 2025): Gemini 3 Pro → Math & multimodal champ 📊 ChatGPT GPT‑5.1 → Balanced productivity & coding stability 💻 Grok 4.1 → Emotional intelligence & creative flair 🎭 Each shines in its domain—logic, balance, or empathy. #AI #Benchmarks…
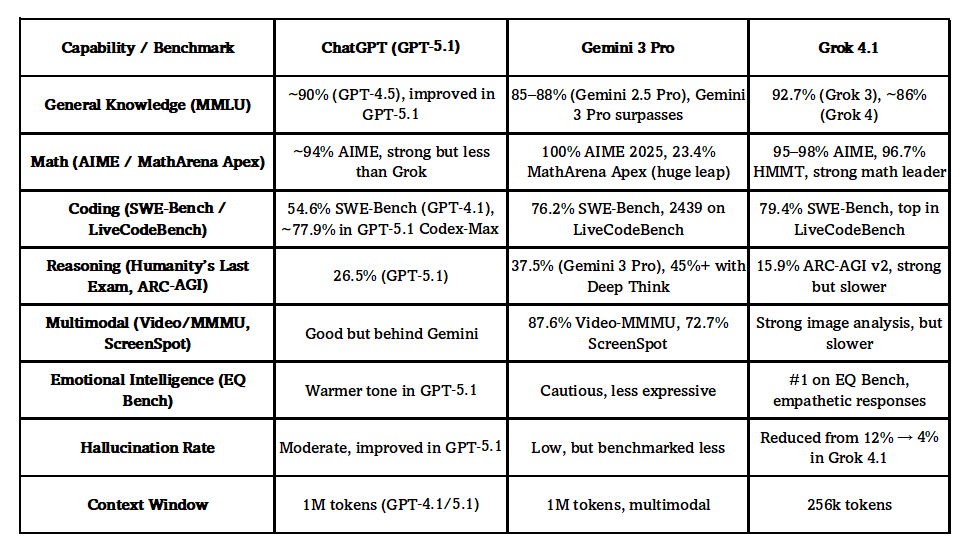

MASTER CLASS - ENTIENDE LAS BATERIAS DEL FUTURO Dentro de nuestro #MasterExpertoAutomoción tenemos una vertical de especialización en vehículo eléctrico con formaciones específicas sobre #electromovilidad, incluida una experiencia en #benchmarks con el #BYD o el #XIAOMI

Day 2 kicks off with the @LondonBuildExpo buzzing louder than ever! Our stand has been buzzing with visitors eager to hear about #ASCmembership, #SABRE, and the upcoming seminar that is shaping new #benchmarks for the industry. Visit us at Stall Q10!

Does the benchmarks even matter now ?? I guess not, me being an end user, I just need if it is useful for me. #benchmarks
FYI, these are the most cited #accuracy #benchmarks for #ai. I asked the top 8 LLMs/chatbots (not sure what to call them) listed in my pinned post: Most Frequently Cited Benchmarks Universal consensus (7-8 mentions): TruthfulQA - Cited by 7 out of 8 LLMs as the gold standard…

Benchmarking = Growth mindset 📊 For professional service providers, benchmarking helps identify where your firm stands in profitability, efficiency, and client retention compared to industry standards. Small insights → Big improvements 💼 #Benchmarks #SmartMoneyMoves #JARCPA



















































✨ Taking the stage, @Jared_Spataro here to share his thoughts and insights about “A New Frontier: Building the Future Firm with #AI” #BenchMarks 📈📉📊 #M365Con Day Three Keynote

#DiabloIV #Benchmarks - 38 GPUs tested✅(yesterday) - 14 CPUs tested✅(today) Enjoy! computerbase.de/2023-06/diablo…




#benchmarks Places of worship across the island of Ireland bear a tangible link to the legacy of the Ordnance Survey which mapped Ireland nearly 200 years ago. The OS was the completion of the world’s first large scale mapping of an entire country.






We just released our evaluation of @MistralAI Medium 3 across all of our benchmarks! 🧵(1/6) #AI #LLM #Benchmarks

Gaphorism 1.14: Not even wrong !!! perfdynamics.com/Manifesto/gcap… #latency #performance #benchmarks
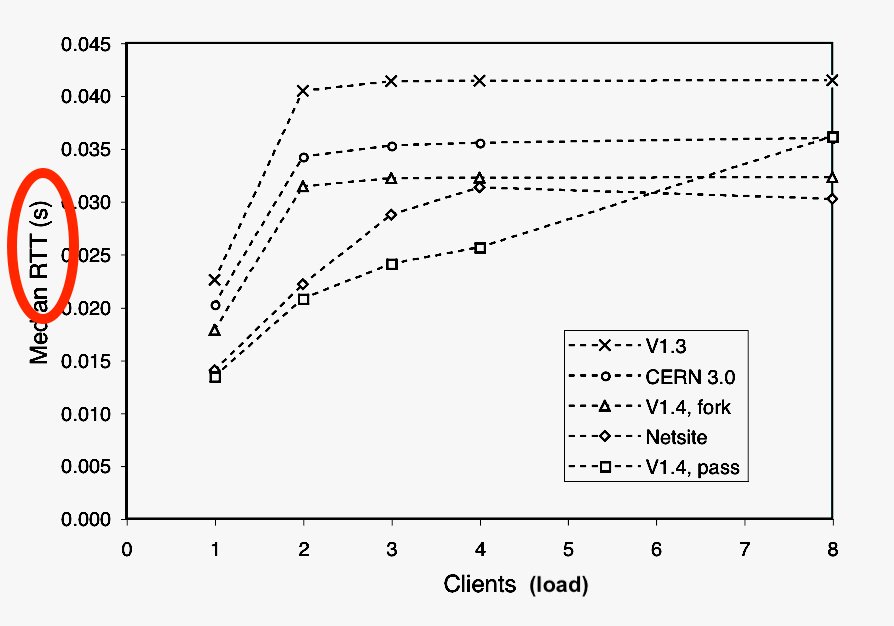

It's important to use proper #benchmarks and #evaluation methods to validate your #models, especially for time series

Do you know how Google PaLM2 model powering Bard compares to other LLMs? 🤔 Tomorrow at GitHub SF I will compare publicly available benchmarks for PaLM2, GPT-4, GPT-3.5 and Llama2 representing open source! RSVP now! Last seats 👉🏻 meetup.com/graphql-sf/eve… #ai #benchmarks ✨🚀


📢 Excited to share that COBIAS has been accepted at #WebSci25! 🎉 Our work aims to quantify the contextual #quality of LLM-bias #benchmarks. w/ @priyanshul1202 @jain_hemang112 @VictorKnox99 @i_amanchadha @manasgaur90 @DeySanorita 📜 arxiv.org/abs/2402.14889 Findings 🧵⬇️


Internetjättar släpper nytt benchmark för webbläsare swedroid.se/internetjattar… #Mjukvara #benchmarks

Updated - Futuremark SystemInfo is a #freeware utility used to identify the #hardware in your system and is used for many of Futuremark's #benchmarks. majorgeeks.com/files/details/…

Updated - #Futuremark SystemInfo is a #freeware utility used to identify the hardware in your system and is used for many of Futuremark's #benchmarks. majorgeeks.com/files/details/…

What a good Day 1 for The @ITPressTour w/ @MLCommons and @Hammerspace_Inc around #FastIO, #Benchmarks and #DataGovernance #MultiCloud #FileStorage #ParallelFS #pNFS #NAS #AI #HPC #FastIO #MLPerf #DataManagement #ITPT


BenchmarkDotNet is an open-source library that makes it easy for you as a developer to create #benchmarks. The library became quite popular among #dotnet developers. New blog post: matthias-jost.ch/testing-csharp… The image below shows a typical performance engineer at work😉

GPT-5 vs Grok 4 - SkateBench → GPT-5: 98.6% accuracy | $0.07 cost → Grok 4: 79% accuracy | $4.86 cost GPT-5 is: → 14× cheaper → More accurate → Much faster This is precision at scale. That is burn rate with lag. #GPT5 #LLM #Benchmarks

SEO strategy is important for many reasons ranging from maximizing return to having an organized plan to manage tactics and the work overall. bit.ly/45rJxJO #roi #benchmarks #SEOstrategies #analytics


#Benchmarks, #NewYorkCity #ttot TravelGumbo archives By Travelers, For Travelers travelgumbo.com/blog/benchmark…

Something went wrong.
Something went wrong.
United States Trends
- 1. Eagles 71.2K posts
- 2. Eagles 71.2K posts
- 3. Jalen 18.8K posts
- 4. Black Friday 476K posts
- 5. Nebraska 12.7K posts
- 6. Swift 56.1K posts
- 7. Kevin Byard 1,236 posts
- 8. Ben Johnson 3,188 posts
- 9. Sydney Brown 1,159 posts
- 10. Iowa 14.1K posts
- 11. Lane Kiffin 11K posts
- 12. Rhule 3,039 posts
- 13. #CHIvsPHI 1,339 posts
- 14. Black Ops 7 Blueprint 12.5K posts
- 15. Tanner McKee N/A
- 16. Sumrall 3,861 posts
- 17. #SoleRetriever N/A
- 18. Go Birds 11.8K posts
- 19. Caleb Williams 5,011 posts
- 20. Gunner 4,352 posts