#inferenceoptimization ผลการค้นหา

Talk: From Human Agents to GPU-Powered GenAI – A Data-Driven Transformation in Customer Service 🔗 hubs.li/Q03LTv9v0 Register Now: hubs.li/Q03LTrqr0 #GenAIinSupport #CustomerServiceAI #InferenceOptimization #EnterpriseAI #AppliedAISummit


1/3 Learn in this blog article the key techniques like pruning, model quantization, and hardware acceleration that are enhancing efficiency. #MultimodalAI #LLMs #InferenceOptimization #AnkursNewsletter


Supercharge your AI with lightning-fast inference! 🚀 Post-training quantization techniques like AWQ and GPTQ trim down your models without sacrificing smarts—boosting speed and slashing compute costs. Ready to optimize your LLMs for real-world performance? #InferenceOptimization…

Stanford Researchers Explore Inference Compute Scaling in Language Models: Achieving Enhanced Performance and Cost Efficiency through Repeated Sampling itinai.com/stanford-resea… #AIAvancements #InferenceOptimization #RepeatedSampling #AIApplications #EvolveWithAI #ai #news #llm…

3/3 Explore our comprehensive guide on inference optimization strategies for LLMs here: buff.ly/3R7QFqK 🔁 Spread this thread with your audience by Retweeting this tweet #MultimodalAI #LLMs #InferenceOptimization #AnkursNewsletter

L40S GPUs optimize Llama 3 7B inference at $0.00037/request. Achieve extreme throughput for small LLMs. Benchmark your model. get.runpod.io/oyksj6fqn1b4 #LLM #Llama3 #InferenceOptimization #CostPerRequest


What we’re building 🏗️, shipping 🚢 and sharing 🚀 tomorrow: Inference Optimization with GPTQ Learn how GPTQ’s “one-shot weight quantization” compares to other leading techniques like AWQ Start optimizing: bit.ly/InferenceGPTQ?… #LLMs #GPTQ #InferenceOptimization


Check out how TensorRT-LLM Speculative Decoding can boost inference throughput by up to 3.6x! #TensorRT #InferenceOptimization #AI #NVIDIA #LLM #DeepLearning 🚀🔥 developer.nvidia.com/blog/tensorrt-…
developer.nvidia.com
TensorRT-LLM Speculative Decoding Boosts Inference Throughput by up to 3.6x | NVIDIA Technical Blog
NVIDIA TensorRT-LLM support for speculative decoding now provides over 3x the speedup in total token throughput. TensorRT-LLM is an open-source library that provides blazing-fast inference support...

Inference is where great AI products either scale—or burn out. 2025’s best AI infra teams aren’t just using better models… They’re running smarter pipelines. This thread: how quantization, batching & caching supercharge LLM apps. #LLMOps #InferenceOptimization #AIInfra

Capital is also chasing compute arbitrage. Startups using: – Smart model quantization – Faster inference on CPUs – Sovereign training infra Own the stack, own the scale. #computeedge #inferenceoptimization #quantization

DeepMind と UC Berkeley が LLM 推論時間コンピューティングを最大限に活用する方法を紹介 | VentureBeat #AIcoverage #InferenceOptimization #TestTimeCompute #LLMperformance prompthub.info/40031/
prompthub.info
DeepMind と UC Berkeley が LLM 推論時間コンピューティングを最大限に活用する方法を紹介 | VentureBeat - プロンプトハブ
大規模言語モデル(LLMs)の訓練コストと速度の遅さから、推論による性能向上のためにより多くの計算サイクルを使
Model Layer = Swappable Core GPT-4, Claude, Gemini, Mixtral—pick your poison. Top teams don’t pick one. They route by: → Task → Latency → Cost → Accuracy Models are pipes. Routing is strategy. #LLMs #ModelOps #InferenceOptimization

Excited to read about the Large Transformer Model Inference Optimization by @lilianweng! This article provides valuable insights on improving Transformers. Don't miss it! 👉🔍 #InferenceOptimization Check out the article here: lilianweng.github.io/posts/2023-01-…

Weighted inference synthesis optimizes the balance between deductive and inductive components.

Just seeing this now! Inference optimizations: - CUDA graphs - TP4 with custom allreduce, GQA w/ one KV head per GPU - StreamingLLM sliding window w/ attention sink - rules-based (model-free) spec dec for delimiters

I'm not sure why this new ByteDance Seed paper is not all over my feed. Am I missing something? - trained Qwen2VL-7B to play genshin - SFT only, no RL - 2424 hours of human gameplay + 15k short reasoning traces to decompose the tasks - sub 20k H100 hours (3 epochs) - heaps of…
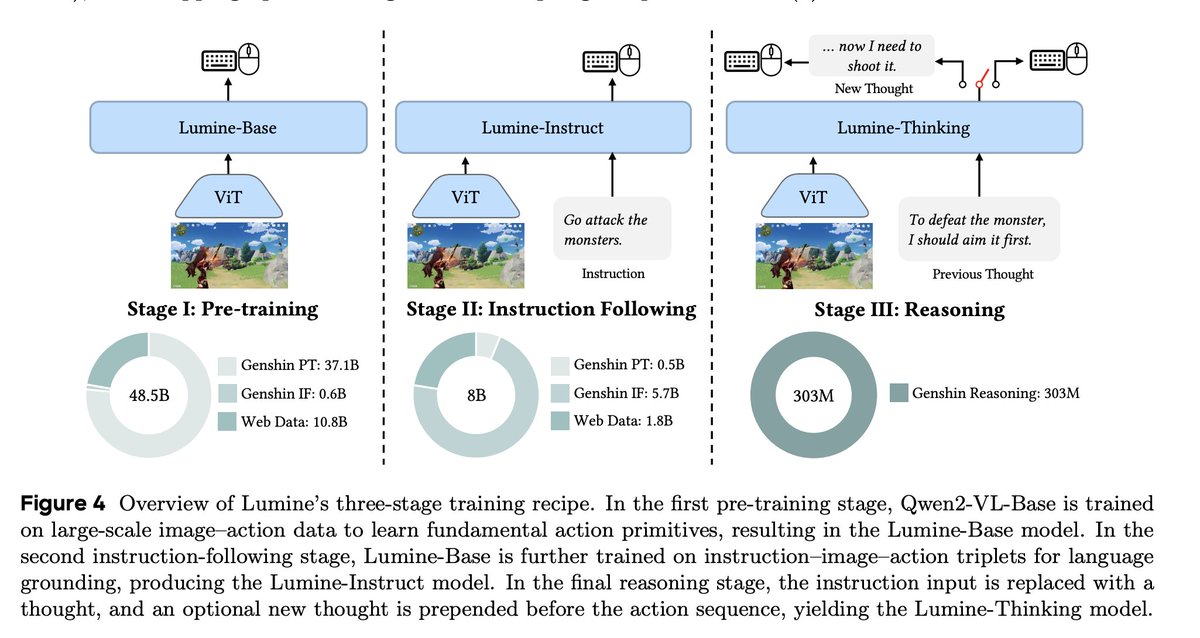
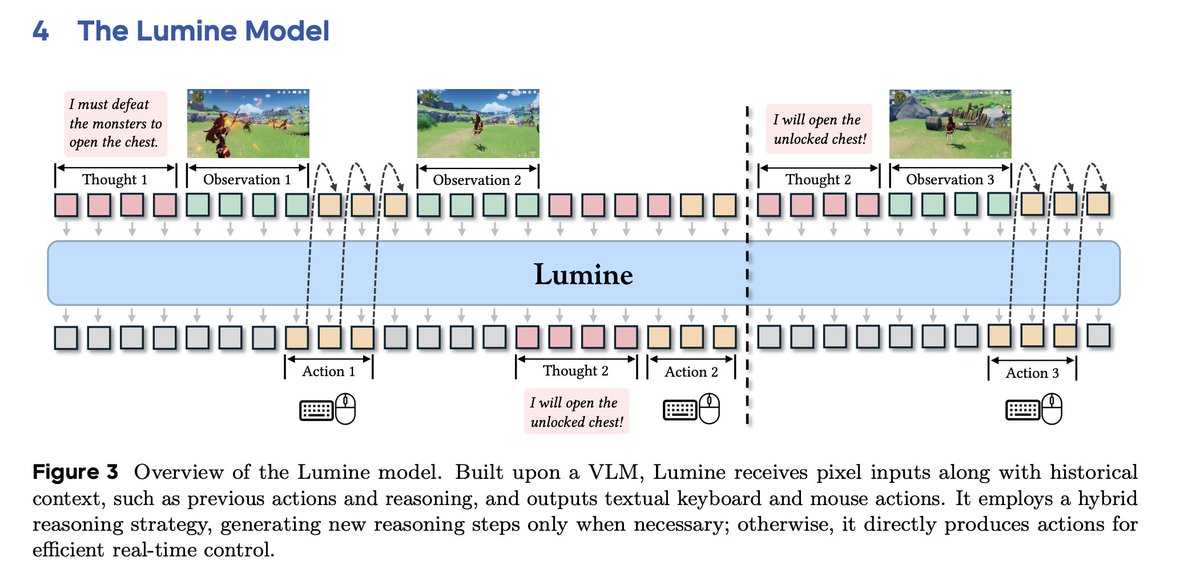
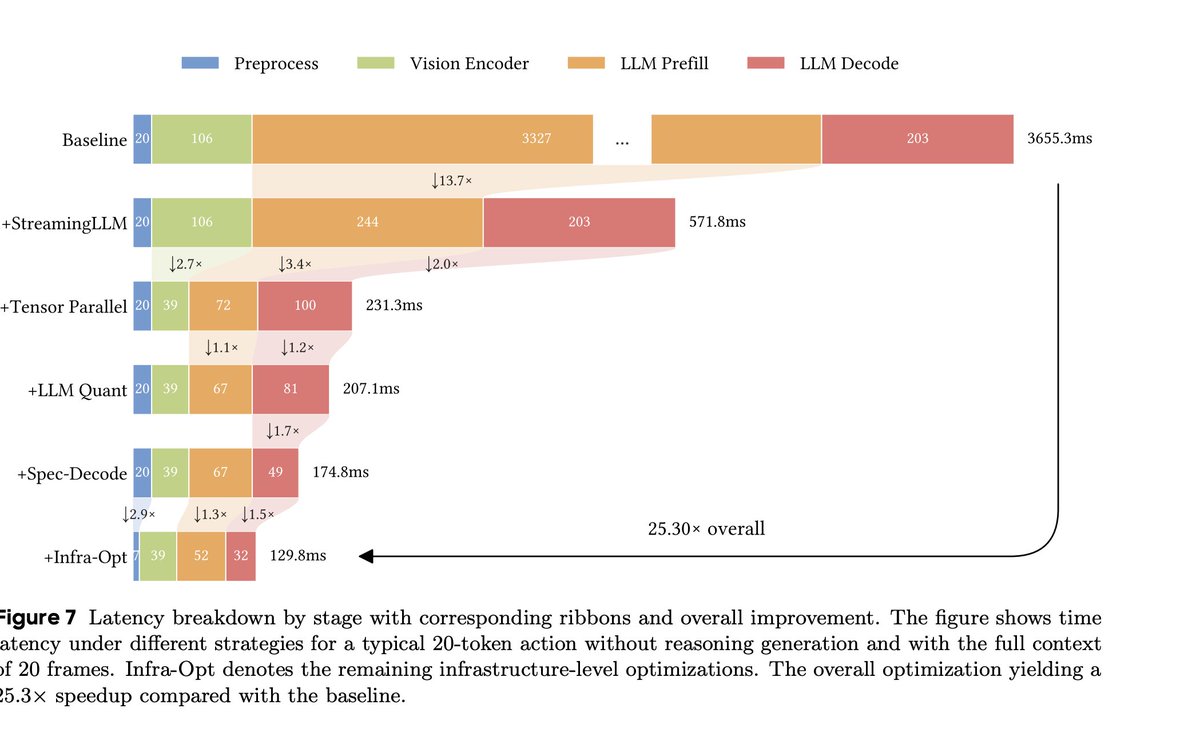



My entire blog this year is that example - here is my first go at describing inference optimization using inference optimization 😵💫😂 hobo-web.co.uk/influencing-th… - my next two posts on searchable.com/resources is about simplifying this very concept.
hobo-web.co.uk
Inference Optimisation - Positively Influencing the Third Point Emergence in AI - Hobo
This guide details a powerful, three-step strategy for AI Engine Optimisation (AEO) that moves beyond traditional SEO.

In LLMs, "inference" means using a trained model to generate outputs, like responses to your queries in ChatGPT. It's the runtime phase where the model processes inputs and predicts results. Unlike training (learning from data), inference is ongoing and scales with user demand,…

When open models like DeepSeek started rivaling proprietary ones, access stopped being the problem. bentoml.com/blog/the-strat… Now the question is: can you run them at scale without runaway costs, latency spikes, or compliance risks? That’s where InferenceOps comes in. It’s the…


🏎️ Increasing inference efficiency Inference packing was added to improve model serving efficiency, making inference up to 5 times faster in some cases.

Watermarks ain't enough😅 Proof of Inference ties outputs to the model + context that made them Fight deepfakes without losing privacy or performance Thanks @inference_labs for making this happen

Content authenticity needs more than watermarks. Proof of Inference binds outputs to the model and context that produced them. It is how we fight deepfakes without giving up privacy or performance.


Gm gm We’re building a future where AI isn’t just powerful, it’s provably correct. @inference_labs brings mathematical guarantees to every model output where its backed by math and not blind trust.


You ever argue with someone and find that both of you remember the same event differently? That’s just how people are. But when machines do the same thing, it becomes a problem. That’s why deterministic execution is important. @inference_labs treats every computation like it…

It’s interesting how many systems try to be impressive by doing everything in one place. One big model, one huge workload. Then everyone is surprised when it slows down or breaks under pressure. @inference_labs takes a different approach with model slicing. They break the work…


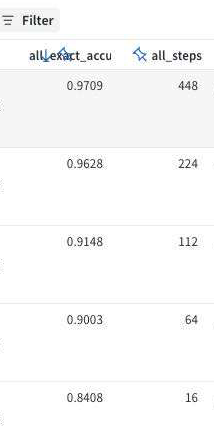
Insane finding! You train on at most 16 improvement steps at training, but at inference you do as many steps as possible (448 steps) and you reach crazy accuracy. This is how you build intelligence!!

Indeed, @jm_alexia @ritteradam I also find that simply increasing the number of inference steps, even when the model is trained with only 16, can substantially improve performance. (config: TRM-MLP-EMA on Sudoku1k; though the 16-step one only reached 84% instead of 87%)
Talk: From Human Agents to GPU-Powered GenAI – A Data-Driven Transformation in Customer Service 🔗 hubs.li/Q03LTv9v0 Register Now: hubs.li/Q03LTrqr0 #GenAIinSupport #CustomerServiceAI #InferenceOptimization #EnterpriseAI #AppliedAISummit

Inference optimizations I’d study if I wanted sub-second LLM responses: Bookmark this. 1.KV-Caching 2.Speculative Decoding 3.FlashAttention 4.PagedAttention 5.Batch Inference 6.Early Exit Decoding 7.Parallel Decoding 8.Mixed Precision Inference 9.Quantized Kernels 10.Tensor…
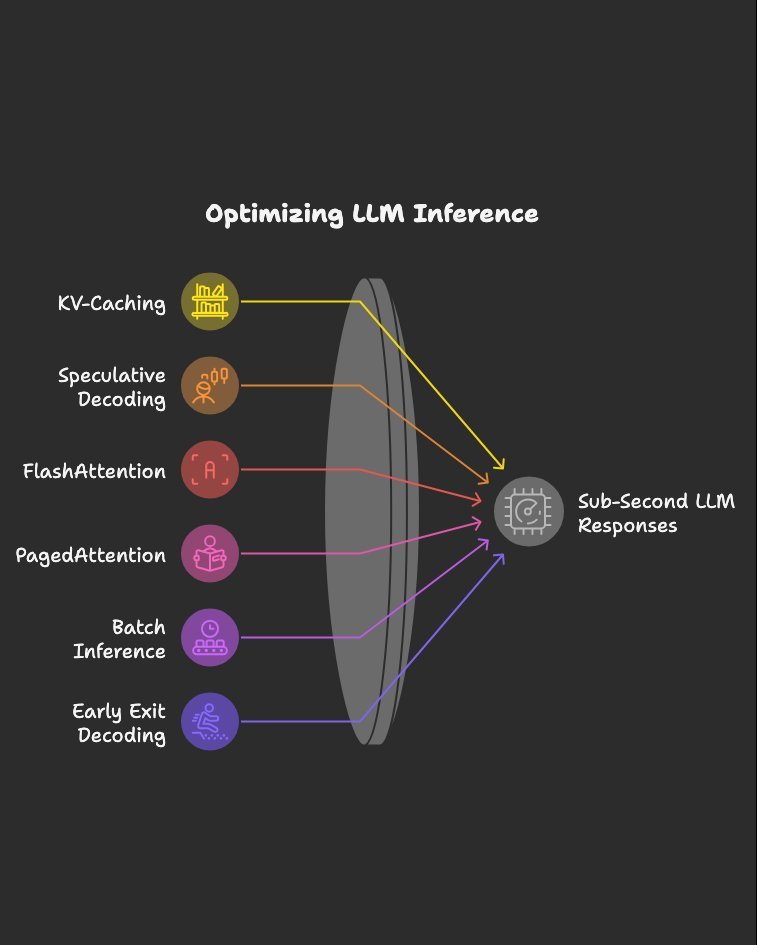

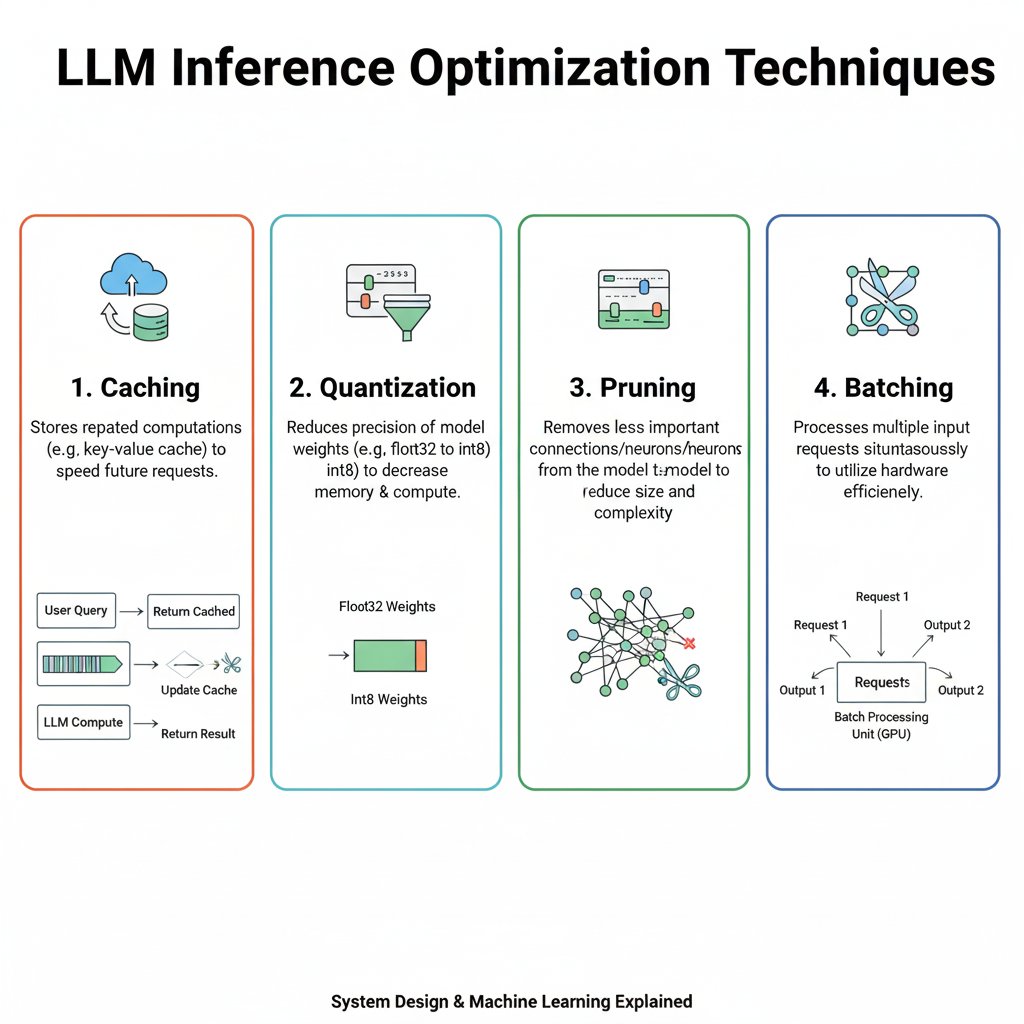
Inference Optimization in LLMs Caching → Stores previously computed results (e.g., attention keys & values) → Speeds up long text generation by avoiding redundant work → Example: Like remembering part of a math solution instead of solving again Quantization → Reduces…

🎬 AI in 30 Seconds – EP.15: What is Inference? Training builds the model. Inference uses it. 🧠 Every time you chat with #AI — you’re triggering inference. ⚡ Seconds for you. Millions of computations for the model. #GPTVerse
L40S GPUs optimize Llama 3 7B inference at $0.00037/request. Achieve extreme throughput for small LLMs. Benchmark your model. get.runpod.io/oyksj6fqn1b4 #LLM #Llama3 #InferenceOptimization #CostPerRequest
Speed is the Surprise Benefit Quantized models = smaller memory Local batching = faster inference No internet = instant UX Local Mistral can outperform GPT-4 on simple tasks—because latency wins #fastLLMs #inferenceoptimization
Inference is where great AI products either scale—or burn out. 2025’s best AI infra teams aren’t just using better models… They’re running smarter pipelines. This thread: how quantization, batching & caching supercharge LLM apps. #LLMOps #InferenceOptimization #AIInfra
Model Layer = Swappable Core GPT-4, Claude, Gemini, Mixtral—pick your poison. Top teams don’t pick one. They route by: → Task → Latency → Cost → Accuracy Models are pipes. Routing is strategy. #LLMs #ModelOps #InferenceOptimization
Talk: From Human Agents to GPU-Powered GenAI – A Data-Driven Transformation in Customer Service 🔗 hubs.li/Q03LTv9v0 Register Now: hubs.li/Q03LTrqr0 #GenAIinSupport #CustomerServiceAI #InferenceOptimization #EnterpriseAI #AppliedAISummit
1/3 Learn in this blog article the key techniques like pruning, model quantization, and hardware acceleration that are enhancing efficiency. #MultimodalAI #LLMs #InferenceOptimization #AnkursNewsletter
Stanford Researchers Explore Inference Compute Scaling in Language Models: Achieving Enhanced Performance and Cost Efficiency through Repeated Sampling itinai.com/stanford-resea… #AIAvancements #InferenceOptimization #RepeatedSampling #AIApplications #EvolveWithAI #ai #news #llm…
What we’re building 🏗️, shipping 🚢 and sharing 🚀 tomorrow: Inference Optimization with GPTQ Learn how GPTQ’s “one-shot weight quantization” compares to other leading techniques like AWQ Start optimizing: bit.ly/InferenceGPTQ?… #LLMs #GPTQ #InferenceOptimization
Inference is where great AI products either scale—or burn out. 2025’s best AI infra teams aren’t just using better models… They’re running smarter pipelines. This thread: how quantization, batching & caching supercharge LLM apps. #LLMOps #InferenceOptimization #AIInfra
Something went wrong.
Something went wrong.
United States Trends
- 1. Auburn 39.1K posts
- 2. Duke 30.8K posts
- 3. Bama 28.7K posts
- 4. Stockton 18.9K posts
- 5. Miami 123K posts
- 6. Ole Miss 37K posts
- 7. #SurvivorSeries 180K posts
- 8. Lane Kiffin 46.4K posts
- 9. Notre Dame 24.8K posts
- 10. Stanford 9,314 posts
- 11. Virginia 48K posts
- 12. Austin Theory 4,630 posts
- 13. Cam Coleman 1,856 posts
- 14. Cooper Flagg 7,204 posts
- 15. ACC Championship 7,995 posts
- 16. #RollTide 6,147 posts
- 17. Iron Bowl 16.3K posts
- 18. Seth 20.9K posts
- 19. Oxford 23.2K posts
- 20. Ty Simpson 4,022 posts