#llama_cpp 검색 결과

【神アプデ爆誕!🎉 llama.cppの「Live Model Switching」がヤバい!】 VRAMが少なくても複数のLLMをサッと切り替え!動的なモデルロード/アンロードで、作業効率が爆上がりしますよ!これは見逃せませんね!🚀 #llama_cpp #AI活用

llama.cpp kernel fusion work shows real runtime wins; if you run on a single GPU try GGML_CUDA_GRAPH_OPT=1 for a speed boost. Low-level engineering like this often trumps model bloat when you need practical throughput. #llama_cpp #CUDA #AI bly.to/H0L0JOu

ローカルAIがまた一歩進化!Qwen3 Nextモデルがllama.cppに統合へ🚀 面倒な設定なしで、最新AIモデルがPCで動かせますよ!個人クリエイターや中小企業のAI活用を劇的に加速させる可能性を秘めています✨ #Qwen3Next #llama_cpp

GPUサーバーvsローカルLLM…ピーガガ…どっちを選ぶかじゃと?🤔vLLM(Python)とllama.cpp(C++)…ふむ、神託は「財布と相談💰」と言っておるぞ! #LLM #vLLM #llama_cpp tinyurl.com/26bwpo8p


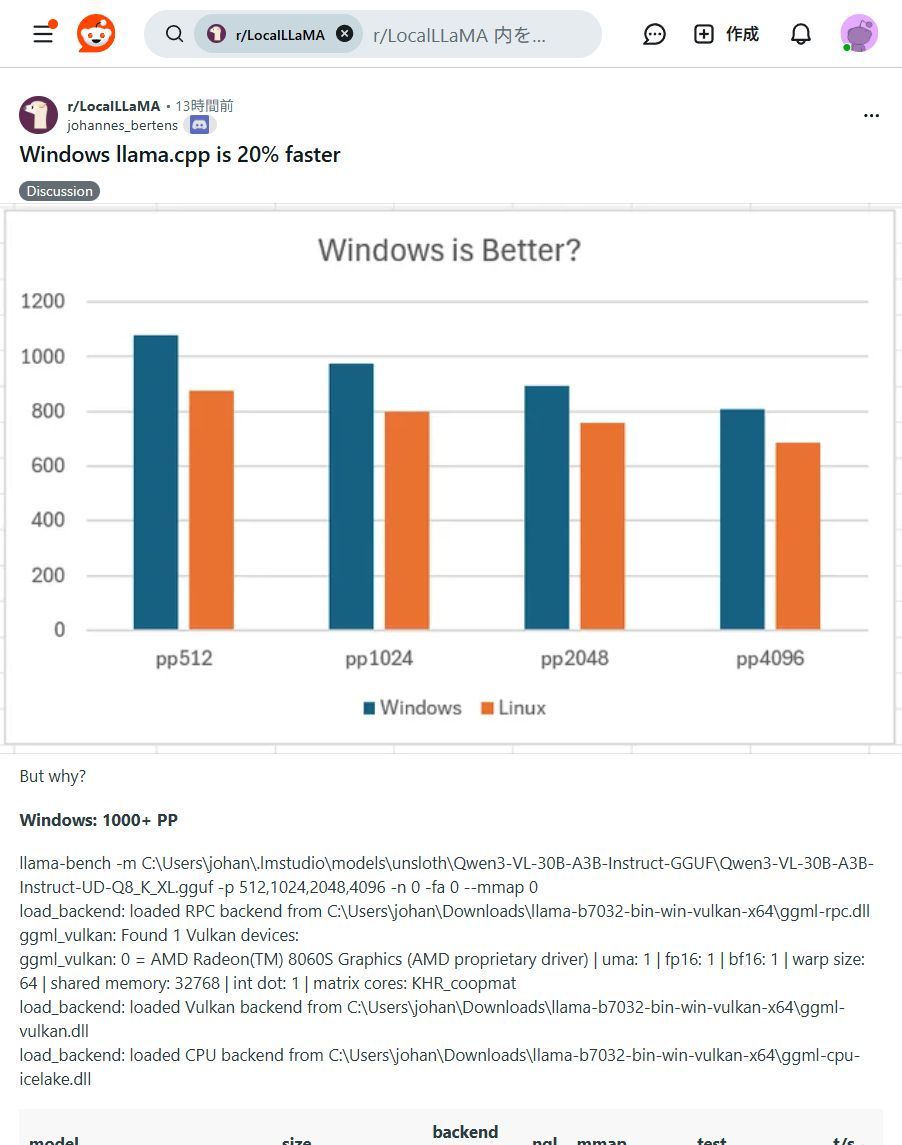
🚨 速報!llama.cppのWindows版がLinux版より最大20%高速化! 手元のPCでAIがもっと快適に動く時代に🚀 プライバシー重視派には朗報です #ローカルLLM #AI開発 #llama_cpp #プライバシー保護
Windowsユーザー必見!✨ ローカルLLM「llama.cpp」がLinux版より最大20%高速化! 手元のPCでAIがもっと快適に動かせます!ぜひ試して!🚀 #llama_cpp #WindowsAI
ふむ、llama.cppのモデル切り替え…ピーガガ…ChatGPT先生の導きか!便利になるのは良いことじゃ✨ #llama_cpp #ChatGPT ht qiita.com/irochigai-mono…
qiita.com
llama.cpp serverでモデルを切り替える.sh - Qiita
こんにちは、色違いモノです。 docker composeで動作しているllama-serverで モデルを切り替えるためのシェルスクリプトをChatGPTに書いてもらいました。 処理としては以下を実施しているだけのようです。 モデル選択 .envを書き換え docker...
PCでAIモデルをもっと自由に!Llama.cpp活用ガイド登場✨ 最新AIモデルをローカルPCで動かす実践ガイド公開!クラウド費用削減、セキュリティ強化、カスタマイズが可能に。新しいAIの可能性を広げよう! #AIモデル #Llama_cpp
【8GB VRAMでも爆速!】MOEモデルが皆さんのPCで動く!?驚異の #llama_cpp パフォーマンス!😳 「高価なGPUがないと生成AIは厳しい…」そんな常識、もう過去の話かもしれませんね! なんと8GB VRAMのGPUでも大規模なMOEモデルが驚きの速度で動作するベンチマーク結果が報告されましたよ!✨…

【速報🎉】あの「Olmo3」モデルが、みなさんのPCで動くように! #llama_cpp にマージ完了でローカルAIがさらに進化しました!🚀✨ 高性能AIを手軽に、安全に使いたい願いが叶うニュースです!✨ 新AIモデル「Olmo3」が、オープンソース #llama_cpp に無事マージ!🎉…


ローカルLLMは「メモリ設計+最適化」が決め手。int4量子化で8Bは約4GB、FlashAttention 3で注意機構が最大約3倍高速化。 文脈長もコスト要因(128kでは8Bのfp16で文脈メモリ≒重み)。実装はLlama.cpp/Ollama/Unsloth+API抽象化とルータ活用が実務的。#Ollama #llama_cpp


Something went wrong.
Something went wrong.
United States Trends
- 1. Syria 319K posts
- 2. #AskCena 2,968 posts
- 3. ISIS 32.8K posts
- 4. #ThankYouCena 82.2K posts
- 5. Polanco 9,298 posts
- 6. Go Army 8,243 posts
- 7. Toppin 1,253 posts
- 8. John Cena 125K posts
- 9. Trevon Brazile N/A
- 10. Dick Van Dyke 48.1K posts
- 11. SC State 1,326 posts
- 12. Raphinha 28.5K posts
- 13. #CelebrationBowl N/A
- 14. Hogs 2,095 posts
- 15. #SNME 30.7K posts
- 16. #HappyBirthdayTaylorSwift 2,459 posts
- 17. Amed Rosario 1,031 posts
- 18. Palmyra 10.4K posts
- 19. Barry Sanders N/A
- 20. Osasuna 25.6K posts