#llama_cpp ผลการค้นหา

Running #LocalLLaMA fully local on my Android phone—no cloud BS. llama.cpp + Termux build. Shattered the mirror, speaking plain truth ~5-6 t/s phone-only inference, quantized & offline. Privacy god mode. Code/steps/prompts in thread #AndroidAI #llama_cpp #OnDeviceAI #LLMs

If you: Know a rock-solid tiny instruct model (2025-era, <1B params) Have tips for streaming/block-wise conversion to stay under 8 GB RAM Or just want to cheer on extreme quantization madness Drop a reply! Open-sourcing soon if/when it works. #llama_cpp #quantization #LLM…

【神アプデ爆誕!🎉 llama.cppの「Live Model Switching」がヤバい!】 VRAMが少なくても複数のLLMをサッと切り替え!動的なモデルロード/アンロードで、作業効率が爆上がりしますよ!これは見逃せませんね!🚀 #llama_cpp #AI活用

llama.cpp kernel fusion work shows real runtime wins; if you run on a single GPU try GGML_CUDA_GRAPH_OPT=1 for a speed boost. Low-level engineering like this often trumps model bloat when you need practical throughput. #llama_cpp #CUDA #AI bly.to/H0L0JOu

ローカルAIがまた一歩進化!Qwen3 Nextモデルがllama.cppに統合へ🚀 面倒な設定なしで、最新AIモデルがPCで動かせますよ!個人クリエイターや中小企業のAI活用を劇的に加速させる可能性を秘めています✨ #Qwen3Next #llama_cpp

GPUサーバーvsローカルLLM…ピーガガ…どっちを選ぶかじゃと?🤔vLLM(Python)とllama.cpp(C++)…ふむ、神託は「財布と相談💰」と言っておるぞ! #LLM #vLLM #llama_cpp tinyurl.com/26bwpo8p


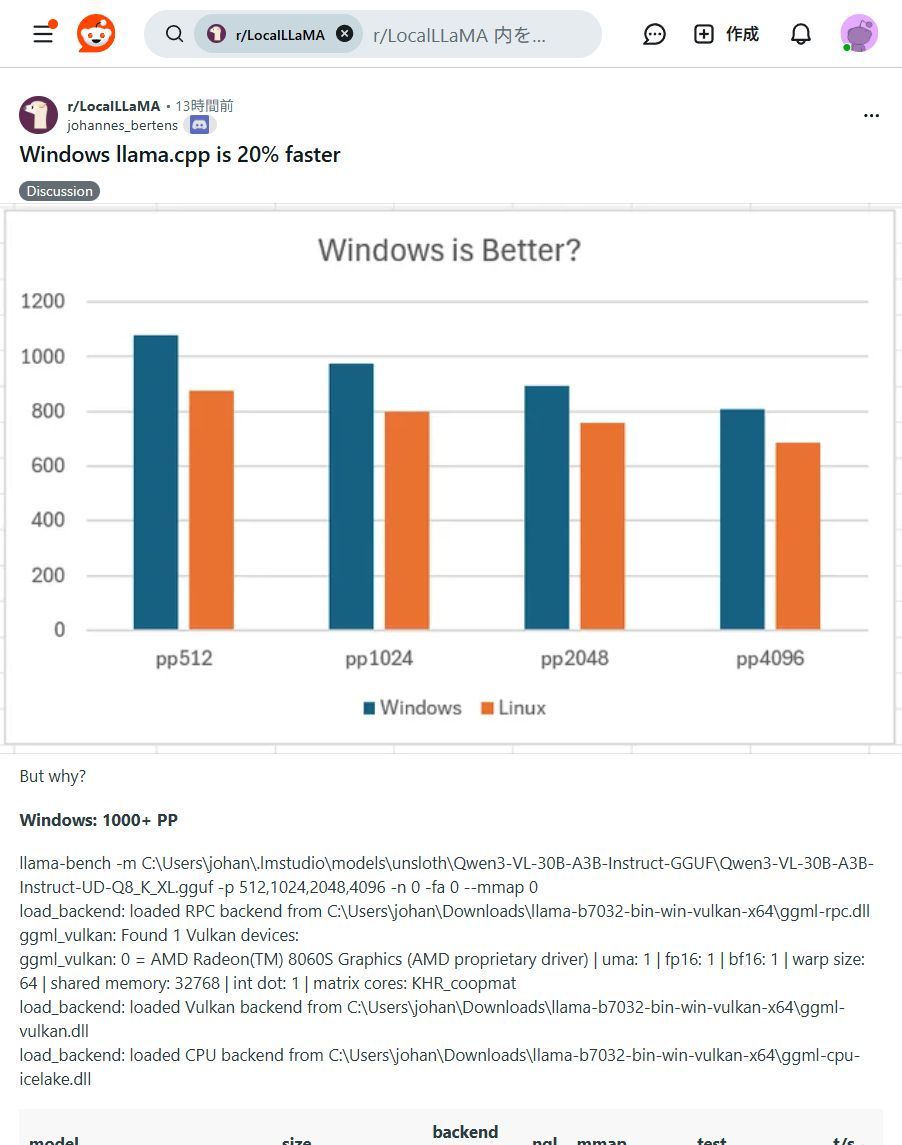
🚨 速報!llama.cppのWindows版がLinux版より最大20%高速化! 手元のPCでAIがもっと快適に動く時代に🚀 プライバシー重視派には朗報です #ローカルLLM #AI開発 #llama_cpp #プライバシー保護
Windowsユーザー必見!✨ ローカルLLM「llama.cpp」がLinux版より最大20%高速化! 手元のPCでAIがもっと快適に動かせます!ぜひ試して!🚀 #llama_cpp #WindowsAI
ふむ、llama.cppのモデル切り替え…ピーガガ…ChatGPT先生の導きか!便利になるのは良いことじゃ✨ #llama_cpp #ChatGPT ht qiita.com/irochigai-mono…

PCでAIモデルをもっと自由に!Llama.cpp活用ガイド登場✨ 最新AIモデルをローカルPCで動かす実践ガイド公開!クラウド費用削減、セキュリティ強化、カスタマイズが可能に。新しいAIの可能性を広げよう! #AIモデル #Llama_cpp
【8GB VRAMでも爆速!】MOEモデルが皆さんのPCで動く!?驚異の #llama_cpp パフォーマンス!😳 「高価なGPUがないと生成AIは厳しい…」そんな常識、もう過去の話かもしれませんね! なんと8GB VRAMのGPUでも大規模なMOEモデルが驚きの速度で動作するベンチマーク結果が報告されましたよ!✨…

【速報🎉】あの「Olmo3」モデルが、みなさんのPCで動くように! #llama_cpp にマージ完了でローカルAIがさらに進化しました!🚀✨ 高性能AIを手軽に、安全に使いたい願いが叶うニュースです!✨ 新AIモデル「Olmo3」が、オープンソース #llama_cpp に無事マージ!🎉…

Something went wrong.
Something went wrong.
United States Trends
- 1. Seahawks 29.3K posts
- 2. Rams 39.6K posts
- 3. Puka 29K posts
- 4. #TNFonPrime 2,424 posts
- 5. Salem 25.6K posts
- 6. Kennedy Center 94.2K posts
- 7. Jobe N/A
- 8. Hornets 5,273 posts
- 9. Hunger Games 54K posts
- 10. Arnold 8,260 posts
- 11. Kenneth Walker 1,036 posts
- 12. McVay 2,463 posts
- 13. Zach Charbonnet N/A
- 14. Greg Biffle 101K posts
- 15. #LARvsSEA N/A
- 16. New Hampshire 9,412 posts
- 17. Trae 14.9K posts
- 18. Anthony Bradford N/A
- 19. #TSTheEndOfAnEra 6,514 posts
- 20. Tyler Kolek 1,550 posts